本文介绍的论文题目为《Recommendations with Negative Feedback via Pairwise Deep Reinforcement Learning》,这应该是强化学习在京东推荐中的第二篇文章了,上一篇《Deep Reinforcement Learning for List-wise Recommendations》我们在本系列的第十五篇中已经介绍过了,大家可以进行回顾:https://www.jianshu.com/p/b9113332e33e。
本文论文的下载地址为:https://arxiv.org/pdf/1802.06501.pdf
1、背景
现有的大多数推荐系统,如协同过滤、基于内容的方法,推荐过程大都是静态的,忽略了用户偏好的动态变化性。同时,大多数推荐系统的目标是最大化即时收益,如CVR、CTR等,忽略了对长期收益的考虑。
强化学习方法可以应对上述两个问题,强化学习将推荐问题视为序列决策问题,同时其目标是最大化长期受益。那么,京东是如何将强化学习应用到推荐系统中的呢?
2、问题陈述
对于一个强化学习问题来说,其主要包含五个主要因素:
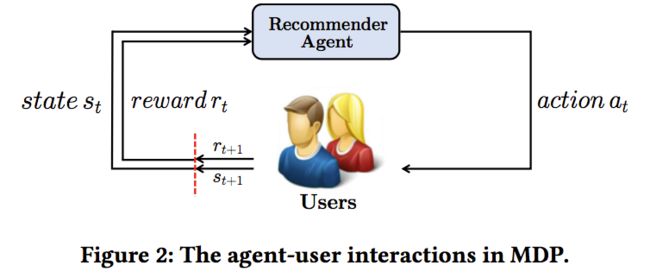
状态空间S:状态空间中的状态定义为用户之前的浏览历史,包括点击/购买过的和略过的,二者分开进行处理。同时,物品是按照先后顺序进行排序的。
动作空间A:这里,我们假设一次只给用户推荐一个物品,那么推荐的物品即动作。
即时奖励R:在给用户推荐一个物品后,用户可以选择忽略、点击甚至购买该物品,根据用户的行为将给出不同的奖励。
状态转移概率P:状态的转移主要根据推荐的物品和用户的反馈来决定的。
折扣因子r:对未来收益打一定的折扣。
下图展示了强化学习用于推荐的过程:
3、基本模型框架
由于动作空间和状态空间巨大,很难直接使用Q-table来解决问题,因此这里使用Deep Q Network(DQN)来作为基准的模型。
在基本的框架里,当前状态s和状态之间的转移关系定义如下:
当前状态s: s={i1,i2,...,iN},用户之前点击或购买过的N个物品,同时按照时间先后进行排序
s转移到s’:假设当前的推荐物品a,用户若点击或购买,则s'={i2,i3,...,iN,a},若用户略过,则s'=s 。
有了上述定义,基本的模型框架如下:
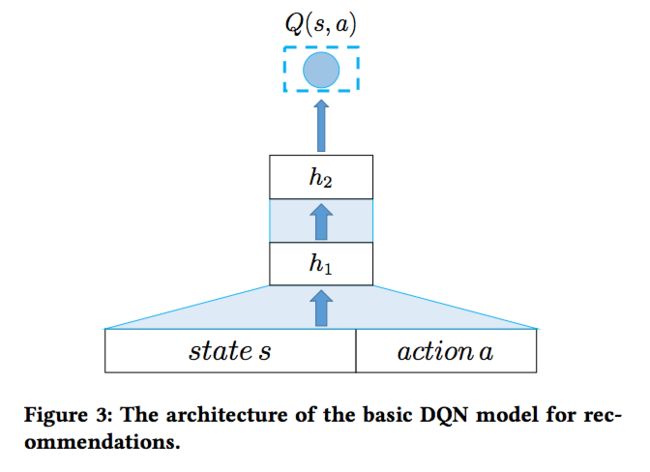
我们每次将state以及待推荐的物品作为输入,转换为embedding后经过多层神经网络得到Q(s,a)。
当然,对于DQN来说,上面的网络被称为eval-net,我们通常还有一个target-net,用于计算Q的实际值,在已知即时奖励r的情况下,实际值计算如下:
这样,DQN的损失函数定义为平方损失,下式中y是Q的实际值:
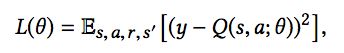
对于基本模型来说,一个明显的缺点就是,当推荐的物品被用户忽略时,状态是不会发生变化的。因此对于用户忽略过的物品,也应该被考虑在状态中。那么具体该怎么做?在下一节中我们将进行讨论。
4、考虑负反馈以及偏序关系的强化学习推荐框架
在考虑负反馈的情况下,当前状态s和状态之间的转移关系定义如下:
当前状态s: 当前状态s包含两部分s=(s+,s-),其中s+={i1,i2,...,iN},表示用户之前点击或购买过的N个物品,s-={j1,j2,...,jN},表示用户之前略过的N个物品。同时物品按照时间先后进行排序。
s转移到s’:假设当前的推荐物品a,用户若点击或购买,则s'+={i2,i3,...,iN,a},若用户略过,则s'-={j2,j3,...,jN,a} 。那么,s' = (s'+,s'-)。
在考虑负反馈的情况下,模型框架为:
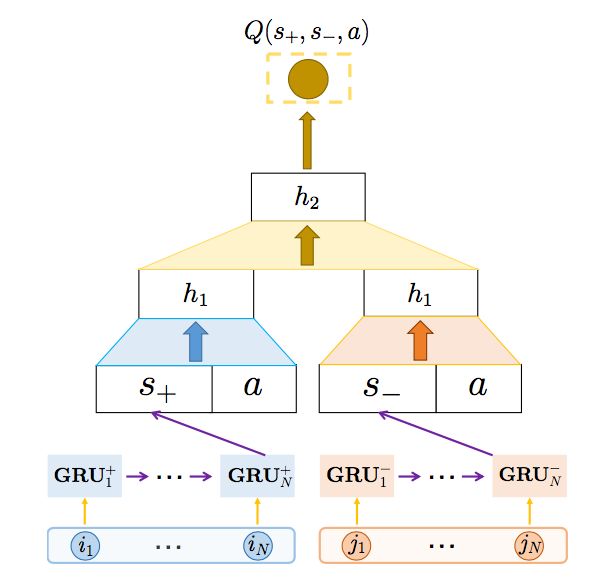
相较于基本的模型,该框架使用GRU来将s+,s-两个序列中的物品进行处理。
除考虑负反馈外,还考虑了物品之间的偏序关系,对于一个物品a,偏序对中的另一个物品我们称为aC,但只有满足三个条件,才可以称为aC。首先,aC必须与a是同一个类别的物品;其次,用户对于aC和a的反馈是不同的;最后,aC与a的推荐时间要相近。
若物品a找不到有偏序关系的物品aC,我们希望预估的Q值和实际的Q值相近,模型的损失函数为:
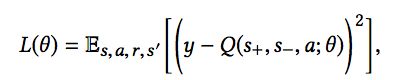
若物品a能够找到有偏序关系的物品aC,此时,我们既希望预估的Q值和实际的Q值相近,同时又希望有偏序关系的两个物品的Q值差距越大越好,因此模型的损失函数变为:
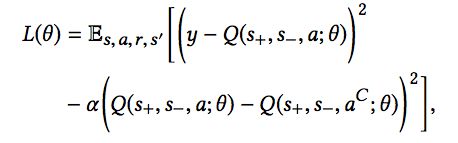
其中,y的计算如下:
至此,模型部分的介绍就结束了,当然,论文中还有关于模型训练和测试部分的内容,感兴趣的同学可以翻看一下论文!