动态知识图补全问题
4.19-4.23 动态信息
1.Dual Quaternion Knowledge Graph Embeddings
本文应该是静态方法,距离公式和旋转公式的一个统一框架。提出一个新的映射空间,Dual Quaternion space .感觉和极坐标那个有异曲同工之妙,不过本文算是统一了两个主要方法在一个空间的平面完成了旋转操作,在立体上完成了距离测算,两者统一就是完成了头尾实体的映射。
两种传统方法的优劣
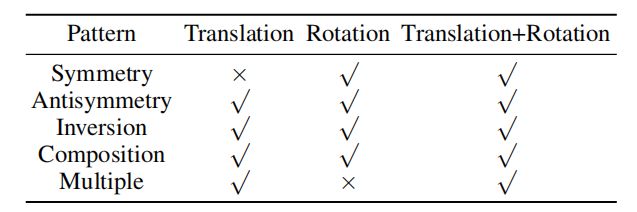
定义三种关系,记录一下
-
对称(symmertric)(反对称(abtisymmetric))
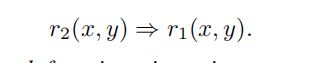
-
反转(inverse)

-
composed
-

整体模型图

2.Deriving Validity Time in Knowledge Graph
这个任务看起来比较不一样,本文的一个主要任务是预测么有时间标签的边的有效性。其实任务还是一样的。
将图谱视为带有时间戳的时序图和表述上下文的三元组
![]()
![]()
之后利用因式分解机(FM)来解决上述问题,输入 ( G t , G c ) (G_t,G_c) (Gt,Gc) 的特征向量,可以用one-hot 编码,也可以用bag-of-word表示
3.TeRo: A Time-aware Knowledge Graph Embedding via Temporal Rotation
和ATiSE同一个作者,从旋转角度上
讲时间和实体再复平面空间的embedding表示

对于特定时间点的score fuction , o t ‾ \overline{o_t} ot是 o t o_t ot的共轭

对于一个时间间隔 [ t r , t e ] [t_r,t_e] [tr,te],其score fucetion

当时间段的缺失,只有开始或者结束时间,上式退化到上上式。
loss fuction

针对不同数据集,时间粒度上进行了进一步的讨论实验
4.Towards Encoding Time in Text-Based Entity Embeddings
基于文本的实体类型嵌入.将实体和其类型concat表示.
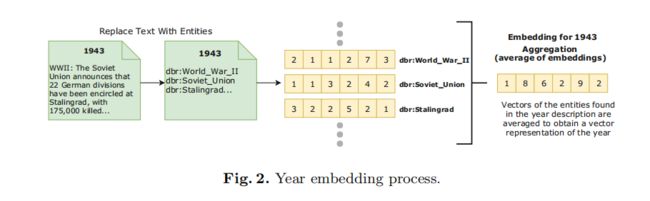

提出两个新得相似性度量方法
![]()
找到实体在时间t上的表示,用 e t e^{t} et表示 ρ ( e ) \rho(e) ρ(e)
-
time-flattened similarity

η \eta η是cos函数,度量相似度,
-
time-boosted similarity

5.Embedding Temporal Network via Neighborhood Formation
HTNE


时序网络的邻居信息嵌入.
基于 Hawkes process(霍克斯过程)的时序网络嵌入方法。
采用点过程的方式来进行链接预测可以考虑考虑,这个应该和Know-evolve这个方法有点类似。
结合霍克斯过程和注意力机制
时序网络

将图表示为 x : y 1 t 1 − > y 2 t 2 . . . − > y n t n x:y_1t_1->y_2t_2...->y_nt_n x:y1t1−>y2t2...−>yntn的序列。其中x为中心事件,y为邻居事件,所以y根据时间可以多次出现,将x,y两个事件用 e i e_i ei这个embedding表示。
强度函数

相似度度量
![]()
使用sigmoid转为正数

加入注意力机制

通过使用多变量霍克斯过程对邻居生成序列建模,我们可以根据条件强度推断出当前邻居生成事件。从而给出节点x在时间t之前的邻居生成序列,用Hs(t)表示,在t时刻下,x与目标邻居y之间生成链接的概率可以通过条件强度被推断如下。
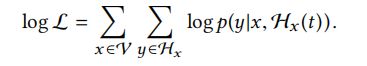
log似然函数

f负采样

本文最后的实验都是用回归的方式刻画节点分类和链接预测,其实他就是node embedding。这个图和知识图谱的r的关系有点不大一样,图谱的r是由确切定义的,这个的边感觉只是有交互关系。
点过程很适合建模金融方面预测!
4.28-5.30动态网络
1.Temporal Network Representation Learning via Historical Neighborhoods Aggregation
node embedding,使用了历史邻居聚合,和注意力机制,是个深度方法

首先使用时序随机游走识别和目标节点x的相关节点,之后使用两级聚合方法来提取特征信息,,第一级聚合使用,使用节点 级别的时序注意力机制,来捕捉信息;第二级聚合在特征向量中诱导walk-level 时序信息,来聚合目标节点的聚合embedding是联合节点x的表示以及邻居节点的信息。
-
时序随机游走
找到定义2说的相关节点,对于边(x,y),节点可以直接或者间接的到达x或者y
时序随机游走可以捕捉多级路径,example:当已经游走了(u,v),v继续游走到w,则非归一化转换概率为

d是u到w距离
-
node-level 注意力和聚合
上文中的第一级聚合,聚合的节点信息是出现在同一游走节点的信息,而不是出现在历史邻域中所有节点。
每个随机游走都视作句子,使用lstm单元作为聚合器。
引入注意力机制以此更新输入


-
walk-level 注意力和聚合
第二级中的聚合,目的是合并第一级中的信息。和第一层方法很类似

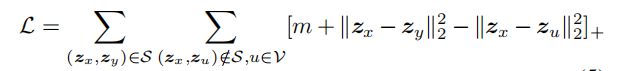
-
优化
使用欧几里得距离,满足三角不等式
loss function

计算量过大,使用负采样,负采样使用得噪声分布如下 P n ( v ) d v 0.75 P_n(v)~d_v^{0.75} Pn(v) dv0.75
2.ChronoR: Rotation Based Temporal Knowledge Graph Embedding
旋转方法

对于true facts存在 Q r , τ ( h ) = t Q_{r,\tau}(h)=t Qr,τ(h)=t,在k维空间上一个一个线性变换群的子集,由旋转和尺度组成,通过时间和关系参数化。Q是k维空间的线性操作。
受限于高维向量,不适合用欧几里得距离度量相似性。
定义:A,B维度为n*k的矩阵
![]()
根据上述定义得到得分函数

取 Q r , τ = [ r ∣ τ ] Q_{r,\tau}=[r|\tau] Qr,τ=[r∣τ],直接concat且两个维度分别为n1k,n2k,n1+n2=n,在加上附加 R 2 R_2 R2来更表示静态事实。得分函数就表示为下式

-
优化
求解模型参数

头实体相似,之后采用negative log-likelihood

θ \theta θ是模型的所有参数表示。不需要生成负样本
-
正则化
损失(目标)函数如下

使用了两个正则化来防止过拟合,一个是tensor nuclear norm,直接视作四阶张量

第二个正则是时间正则:
根据捕获实体随时间的推进的平滑特性
3.DynGEM: Deep Embedding Method for Dynamic Graphs
深度方法
核心采用一个深度自动编码器,生成高度非线性嵌入
增量嵌入-从t-1时间的快照学习到时间t的快照嵌入。
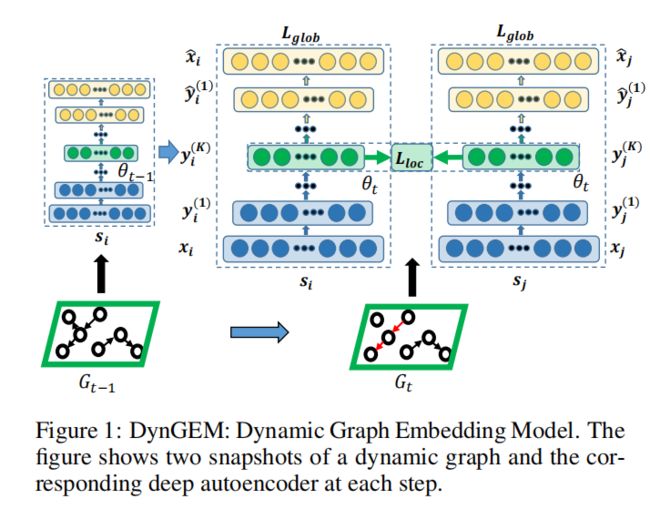
所谓自编码有降维重构的作用,数据应该需要和预训练数据结构类似,上图模型,左侧就是时间t-1的构造,整个模型,下半部分为encoder输入数据,上半部分decoder重构数据对比来调整逐层参数
模型输入:用 s i ∈ R n s_i \in R^n si∈Rn表示节点 v i v_i vi的邻居,节点对i,j使用他们的邻居作为输入,如模型图所示 x i = s i , x j = s j x_i=s_i,x_j=s_j xi=si,xj=sj
模型输出:通过编码和解码器生成重构数据 x ^ i , x ^ j \hat x_i, \hat x_j x^i,x^j,从中间的embedding y i , y j y_i,y_j yi,yj中
key issue:随着节点的增加。隐藏层数量和隐藏单元该如何增长?
一个启发式的PropSize,在encoder层计算每对连续层的宽度,从输入层 l 1 = x l_1=x l1=x开始直到每个连续层满足 s i z e ( l k + 1 ) ≥ ρ × s i z e ( l k ) , s t . 0 < ρ < 1 size(l_{k+1}) \geq \rho \times size(l_k),st.0<\rho<1 size(lk+1)≥ρ×size(lk),st.0<ρ<1,如果k+1层不满足则增加数量,第k层的size为 l k = d l_k=d lk=d,在嵌入层和倒数第二层之间不满足该规则,则引入更多的层,直到满足该规则。
该规则同样适用于decoder,但是是从输出开始往回数
使用Net2WiderNet和Net2DeeperNet实现上述规则,前者拓宽层数,后者实现增加层数
loss function

其中后面三个都是超参数,第二个局部损失,是在embedding层的第第一阶近似,和图的局部结构性相关
L l o c = ∑ i , j n s i j ∥ y i − y j ∥ 2 2 L_{loc} = \sum_{i, j}^{n} s_{i j}\left\|\boldsymbol{y}_{i}-\boldsymbol{y}_{\boldsymbol{j}}\right\|_{2}^{2} Lloc=i,j∑nsij∥∥yi−yj∥∥22
第二阶近似是全局性的,就是对重构数据和输入数据的对比更新
KaTeX parse error: Undefined control sequence: \ at position 56: …{k}_{i}-\right.\̲ ̲\left.x_{i}\rig…
偏置在 s i j = 0 s_{ij}=0 sij=0时为q,其余时候为 β > 1 \beta>1 β>1,这个偏置惩罚了重构错误的边
最后两个L惩罚项分别为
L 1 = ∑ k = 1 K ( ∥ W ( k ) ∥ 1 + ∥ W ^ ( k ) ∥ 1 ) L_{1}=\sum_{k=1}^{K}\left(\left\|W^{(k)}\right\|_{1}+\left\|\hat{W}^{(k)}\right\|_{1}\right) L1=k=1∑K(∥∥∥W(k)∥∥∥1+∥∥∥W^(k)∥∥∥1)
L 2 = ∑ k = 1 K ( ∥ W ( k ) ∥ F 2 + ∥ W ^ ( k ) ∥ F 2 ) L_2=\sum_{k=1}^{K}\left(\left\|W^{(k)}\right\|_{F}^{2}+\left\|\hat{W}^{(k)}\right\|_{F}^{2}\right) L2=k=1∑K(∥∥∥W(k)∥∥∥F2+∥∥∥W^(k)∥∥∥F2)
以此增加网络权重的稀疏性

这是每个snapshot的算法步骤,对每个snapshot可以重复调用上述算法