- 初期学习速度慢的问题
此系列文章一中算法规则3可已看出,在模型学习的过程中。修正取决于s与对误差的学习(a - y),然采用二次损失函数,学习误差需要乘以一个输出层S函数对节点带权输入敏感度向量,而这个数取值(0-1)的一个s类型的函数!这是导致在误差比较大的时候(训练的初期)学习比较慢的原因。
- 解决办法
- 采用交叉信息熵损失函数, 在求导的过程中可以约掉s函数对z的偏倒, 即不需要乘以一个输出层S函数对节点带权输入敏感度向量。下面是针对一个样本求解,多个加和除以样本数n即可:
crossEntropy = - (y * log(a) + (1 - y) * log(1 - a))
- 对输出层做出改变采用softmax作为输出层节点函数,同时采用似然函数作为损失函数,这里不进一步将,后面章节会继续探讨。
下面code使用交叉信息熵作为损害函数,并在前面的代码基础上做了一些小幅度的更改。增加模型训练的准确率以及损失函数的变化趋势图, 为下面探讨模型的过度拟合做一个铺垫。
code
# encoding: utf-8
"""
@version: python3.5.2
@author: kaenlee @contact: [email protected]
@software: PyCharm Community Edition
@time: 2017/8/13 20:38
purpose:过度拟合规划优化
"""
# 相对于前面的章节,这里采用交叉信息熵函数作为损失函数,好处是解决训练初期速度慢的问题。类似还有采用输出层为softmax与对数似然函
# 数结合解决这一问题
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import random
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mp
mp.style.use('ggplot')
mnist = input_data.read_data_sets(r'D:\PycharmProjects\HandWritingRecognition\TF\data', one_hot=True)
training_data = list(zip(mnist.train.images, mnist.train.labels))
test_data = list(zip(mnist.test.images, mnist.test.labels))
# 定义s函数以及偏倒
def Sigmod(z):
return 1 / (1 + np.exp(-z))
def SigmodPrime(z):
"""对S函数求导"""
return Sigmod(z) * (1 - Sigmod(z))
# 下面采用更加pythonic的写法,从训练数据和测试数据准确率以及损失函数来检验模型是否过度拟合
## 先定义二次损失函数和信息熵损失函数
class QuadraticLossFunc:
@staticmethod # 不需要实例化即可调用
def loss(a, y):
# 对于单个样本的输出a和真实y的误差向量a-y取二次范数,然后平方除2
return 1 / 2 * np.linalg.norm(a - y) ** 2
@staticmethod
def delta(a, y, z):
"""
计算输出层L的误差向量delta
:param a: L的输出
:param y: 真实
:param z: L的带权输入
:return:
"""
return (a - y) * SigmodPrime(z)
class CrossEntropyLossFunc:
@staticmethod
def loss(a, y):
# 对log函数可能会取到负无穷,nan_to_num, nan-0, (-)inf-(-)sys.maxsize
return np.nan_to_num(-(y * np.log(a) + (1 - y) * np.log(1 - a)))
@staticmethod
def delta(a, y, z):
# L的误差向量即偏倒(C-b)
return a - y
class NetWorks:
# 定义一个神经网络,也就是定义每一层的权重以及偏置
def __init__(self, size, lossFunc):
"""
给出每层的节点数量,包含输出输出层
:param size: list
"""
self.size = size
self.Layers = len(size)
self.initializeWeightBias()
self.lossFunc = lossFunc
def initializeWeightBias(self):
# 普通的初始化权重方法, 后面会给出更好的
self.bias = [np.random.randn(num) for num in self.size[1:]] # 输入层没有bias
# 每层的权重取决于row取决于该层的节点数量,从来取决于前面一层的输出即节点数
self.weight = [np.random.randn(row, col) for row, col in zip(self.size[1:], self.size[:-1])]
def Feedward(self, a):
"""
对网络给定输入,输出对应的输出
:param a:@iterable给定的输入向量
:return:
"""
a = np.array([i for i in a]) # 输入向量
for b, w in zip(self.bias, self.weight):
z = w.dot(a) + b # 带全输入信号
a = Sigmod(z) # 输出信号
return a
def SGD(self, training_data, epochs, minibatch_size, eta, test_data=None, isplot=False):
"""
随机梯度下降法
:param training_data:输入模型训练数据@[(input, output),...]
:param epochs: 迭代的期数@ int
:param minibatch_size: 每次计算梯度向量的取样数量
:param eta: 学习速率
:param test_data: 训练数据
:return:
"""
if test_data:
n_test = len(test_data)
n = len(training_data)
accuracy_train = []
accuracy_test = []
cost_train = []
cost_test = []
for e in range(epochs):
# 每个迭代器抽样前先打乱数据的顺序
random.shuffle(training_data)
# 将训练数据分解成多个mini_batch:???,这里讲个样本分批计算了和整体计算区别在哪???
mini_batches = [training_data[k:(k + minibatch_size)] for k in range(0, n, minibatch_size)]
for batch in mini_batches:
# print('bias', self.bias)
self.Update_miniBatchs(batch, eta)
if test_data:
totall_predRight = self.Evalueate(test_data)
print('Epoch {0}: {1}/{2}'.format(e, totall_predRight, n_test))
if isplot:
accuracy_test.append(totall_predRight / n_test)
# 计算测试数据c
c = 0
for x, y in test_data:
c += self.lossFunc.loss(self.Feedward(x), y)
cost_test.append(c / n_test)
if isplot:
accuracy_train.append(self.Evalueate(training_data) / n)
# 计算训练数据的cost 即loss
c = 0 # 计算每个样本的加总
for x, y in training_data:
c += self.lossFunc.loss(self.Feedward(x), y)
cost_train.append(c / n)
if isplot:
plt.plot(np.arange(1, epochs + 1), accuracy_train, label='train')
plt.plot(np.arange(1, epochs + 1), accuracy_test, label='test')
plt.xlabel('epoch')
plt.legend()
plt.savefig('accuracy.png')
plt.plot(np.arange(1, epochs + 1), cost_train, label='train')
plt.plot(np.arange(1, epochs + 1), cost_test, label='test')
plt.xlabel('epoch')
plt.legend()
plt.savefig('cost.png')
def Update_miniBatchs(self, mini_batch, eta):
"""
对mini_batch采用梯度下降法,对网络的权重进行更新
:param mini_batch:
:param eta:
:return:
"""
# 用来保存一个计算把周期的权重变换和
B_change = [np.zeros(b.shape) for b in self.bias]
W_change = [np.zeros(w.shape) for w in self.weight]
for x, y in mini_batch:
Cprime_bs, Cprime_ws = self.BackProd(x, y)
B_change = [i + j for i, j in zip(B_change, Cprime_bs)]
W_change = [i + j for i, j in zip(W_change, Cprime_ws)]
# 改变, 原始权重减去改变权重的均值
n = len(mini_batch)
# print('change bias', B_change)
self.bias = [bias - eta / n * change for bias, change in zip(self.bias, B_change)]
self.weight = [weight - eta / n * change for weight, change in zip(self.weight, W_change)]
def BackProd(self, x, y):
"""
反向算法
:param x: iterable,
:param y: iterable
:return:
"""
x = np.array(x)
y = np.array(y)
# 获取没层的加权输入
zs = [] # 每层的加权输入向量, 第一层没有(输入层)
activations = [x] # 每层的输出信号,第一层为x本身
for b, w in zip(self.bias, self.weight):
# print(w.shape)
# print("z", activations[-1])
z = w.dot(activations[-1]) + b
zs.append(z) # 从第二层开始保存带权输入,size-1个
activations.append(Sigmod(z)) # 输出信号a
# print('a', Sigmod(z))
# print(zs)
# print(activations)
# 计算输出层L每个节点的delta
'''学习速度初期过慢由于SigmodPrime函数导致, 通过采用交叉信息熵作为损失函数,可以完美的约掉它'''
delta_L = self.lossFunc.delta(activations[-1], y, zs[-1]) # 每个节点输出与y之差 乘 S 在z的偏导数
# 输出成L的c对b偏倒等于delta_L
Cprime_bs = [delta_L]
# c对w的骗到等于前一层的输出信号装置乘当前层的误差
Cprime_ws = [np.array(np.mat(delta_L).T * np.mat(activations[-2]))]
# 计算所有的层的误差
temp = delta_L
# 最后一层向前推
for i in range(1, self.Layers - 1):
# 仅仅需要计算到第二层(且最后一层已知),当前层的delta即b可以用下一层的w、delta表示和当前z表示
# 从倒数第二层开始求解
'''向前递推计算输出层前面层的delta时,还会乘上S函数对z 的偏倒'''
x1 = (self.weight[-i]).T.dot(temp) # 下一层的权重的装置乘下一层的delta
x2 = SigmodPrime(zs[-i - 1]) # 当前层的带权输入
delta_now = x1 * x2
Cprime_bs.append(delta_now)
Cprime_ws.append(np.array(np.mat(delta_now).T * np.mat(activations[-i - 2])))
temp = delta_now
# 改变输出的顺序
Cprime_bs.reverse()
Cprime_ws.reverse()
return (Cprime_bs, Cprime_ws)
def Evalueate(self, test_data):
"""
评估模型
:param test_data:
:return:返回预测正确的数量@int
"""
# 最大数字位置相对应记为正确
res_pred = [np.argmax(self.Feedward(x)) == np.argmax(y) for x, y in test_data]
return sum(res_pred)
if __name__ == '__main__':
net = NetWorks([784, 20, 10], CrossEntropyLossFunc)
# print(net.Feedward([1, 1, 1]))
# print(net.BackProd([1, 1, 1], [1, 0]))
# net.Update_miniBatchs([([1, 1, 1], [1, 0]), ([0, 0, 0], [0, 1])], 0.1)
net.SGD(training_data, 30, 10, 3, test_data, True)
- 过度拟合问题
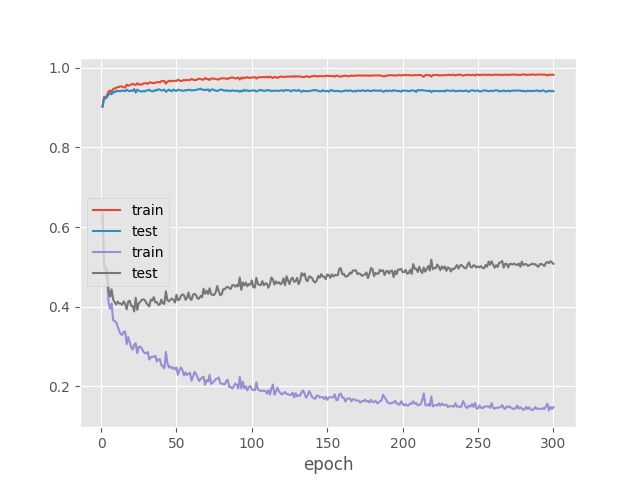
cost.png
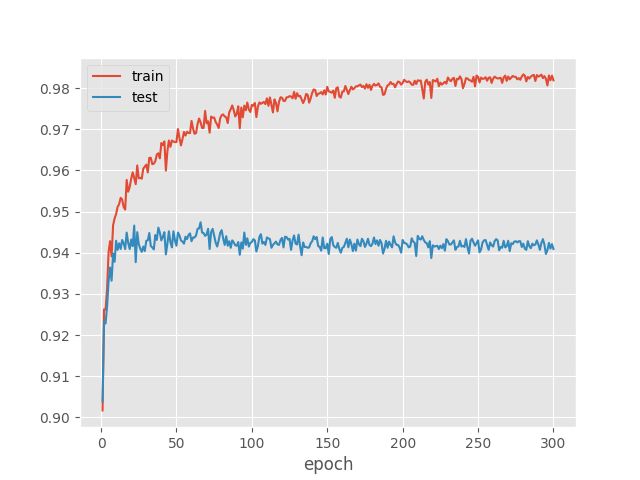
上面两条曲线为准确率的变换情况,下面面loss函数变换情况。图中accuracy和cost的变换趋势都反映了模型虽则迭代期数变换。就训练数据而言,accuracy和cost均在近似相同的期数收敛到最佳(存在不一一致的情况以accuracy为准,模型很快就收敛!!!)。相对训练数据,训练数据模型在测试达到最优化后还在缓慢的优化,识别率接近99.5%。结论:模型训练数据存在过度拟合的情况。
下面放大accuracy的效果图。
accuracy.png