利用官方案例进行训练自己的目标检测模型
准备工作
请参考上篇
https://github.com/tensorflow/models

标注工具
https://github.com/tzutalin/labelImg

安装对应模块,调试环境即可
利用标注工具制作自己的数据集,并生成xml文件
生成csv
# -*- coding:utf-8 -*-
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
import random
def xml_to_csv(path):
xml_list = []
xml_list_test = []
rate = 0.8
i = 0
img_file = glob.glob(path + '/*.xml')
print (img_file)
random.shuffle(img_file)
for xml_file in img_file:
i = i + 1
num_of_train = int(len(glob.glob(path + '/*.xml')) * rate)
tree = ET.parse(xml_file)
root = tree.getroot()
if i <= num_of_train:
for member in root.findall('object'):
value = (
"dataset/pic/"+root.find('filename').text+".jpg",
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[1].text,
int(member[5][0].text),
int(member[5][1].text),
int(member[5][2].text),
int(member[5][3].text)
)
print(value)
xml_list.append(value)
else:
for member in root.findall('object'):
value = (
"dataset/pic/"+root.find('filename').text+".jpg",
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[1].text,
int(member[5][0].text),
int(member[5][1].text),
int(member[5][2].text),
int(member[5][3].text)
)
print(value)
xml_list_test.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
xml_df_test = pd.DataFrame(xml_list_test, columns=column_name)
return xml_df, xml_df_test
def main():
image_path = 'train_xml/'
csv_save_path = 'train_labels.csv'
csv_save_path_test = 'test_labels.csv'
xml_df, xml_df_test = xml_to_csv(image_path)
xml_df.to_csv(csv_save_path, index=None)
xml_df_test.to_csv(csv_save_path_test, index=None)
main()
csv图片路径必须是绝对路径,否则报错。
生成record文件
gennrate_tfrecord_.py --csv_input=dataset/train_labels.csv --output_path=train.record --imahe_dir=dataset/pic
gennrate_tfrecord_.py --csv_input=dataset/test_labels.csv --output_path=test.record --imahe_dir=dataset/pic

gennrate_tfrecord_.py
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
try:
import tensorflow as tf
ecaept:
import tensorflow.compat.v1 as tf
import sys
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', default='/home/hanqing/SSD-Tensorflow-master/VOC2019/ImageSets/Main/csv/sj_train1.csv',help='')
flags.DEFINE_string('output_path', default='/home/hanqing/SSD-Tensorflow-master/tfrecords_/sj_train.record',help='')
flags.DEFINE_string('image_dir', default='/home/hanqing/SSD-Tensorflow-master/VOC2019/JPEGImages/sj_data/',help='')
FLAGS = flags.FLAGS
def class_text_to_int(row_label):
if row_label == "animation_person":
return 1
elif row_label == 'women':
return 2
else:
return 0
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(str(row['class']).encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(FLAGS.image_dir)
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
切换到工程目录在进行操作
下载模型
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf1_detection_zoo.md
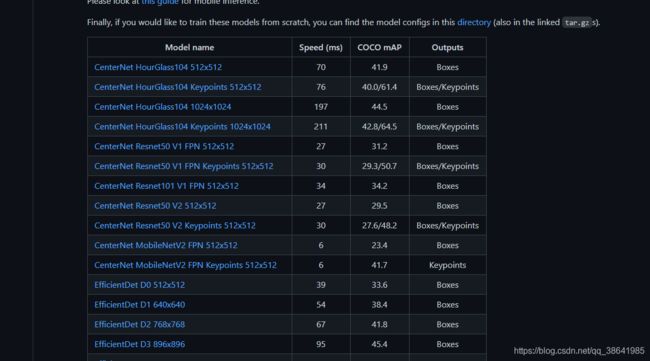
解压放到model目录,并将三个文件放入training目录

修改label_map.pbtxt
如果找不到自己手写也可以

修改配置文件
在object_detection\samples\configs找到下载对应模型的配置文件修改信息
ssd_mobilenet_v2_coco.config

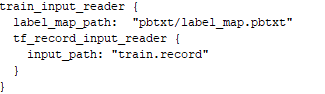


根据情况批处理这个可以改小一点
输入训练命令
model_main.py --pipeline_config_path=config/ssd_mobilenet_v2_coco.config --model_dir=training --alsologtostder
![]()
最后来了句这个,有知道怎么解决的请指教。
说明,切换文tf1.4 ctype相关错误,tf2.4 版本不对应。
全部使用tf2进行
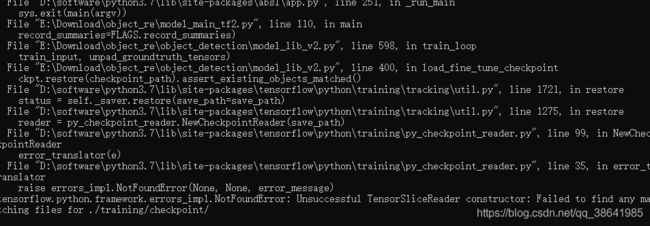
阿来,error
解决方案
参考,https://www.youtube.com/watch?v=oqd54apcgGE
