YOLOV2-源代码详细解析(逐语句进行解释)
前言:一直以来想接触下图像检测和识别,但是苦于没有机会进行练手,最近终于腾出时间看看yolo,你可以从github上找到一大堆yolo的项目,但是你难道仅仅满足于调用作者封装好的接口进行调用么,或者你想训练自己数据集,仅仅是将分好的img和annotation放到对应的文件夹就行了么?下面就拿一个github上的一个yolo v2项目的源码进行解析,大多数的yolo代码大同小异,懂了一个其余的也便可以懂了,希望会对你有帮助。
github地址:https://github.com/mjDelta/yolo2-keras
1、项目结构剖析
首先看一下项目文件夹中都包含什么?(其中有一些是我自己建立的)
其中RBC_datasets是项目的训练集,其中包括训练用的img和每张img对应的annotations(包括图像的尺寸,boxs的信息等),下面对应程序介绍时会展示annotation的内容。
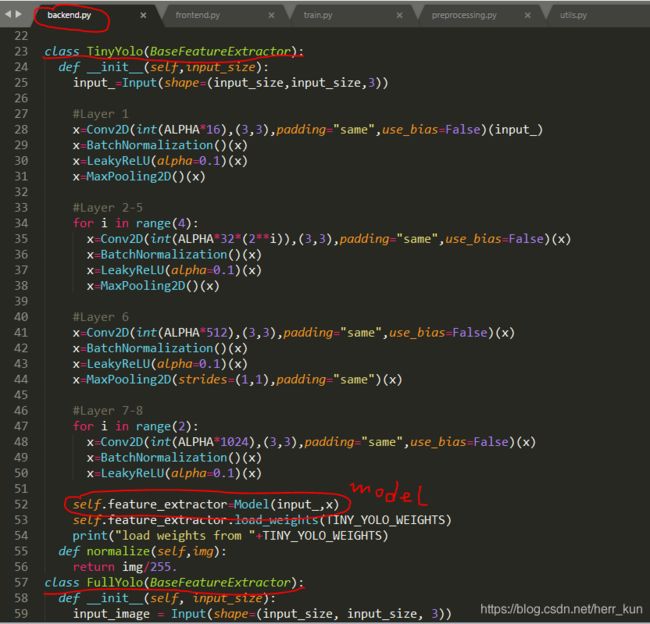
backend.py里面包含了yolo的基础架构,在里面主要是定义了tiny_yolo和full_yolo的网络结构,与之相对应的是frontend.py这个文件,根据字面意思可以知道,一个后端(backend),一个前端(frontend),所以这个文件就是建立在backend.py的基础上的,一般会在frontend文件中进一步定义我们的网络,同时也会定义损失函数等训练网络必须的函数。
backend.py文件:(frontend.py文件可以自行看)
processing.py文件主要的功能有两部分,从文件名就可以看出是进行处理的程序,主要是对数据进行处理。第一是解析注释文件,将img和annotations文件结合起来,第二是生成响应的batch作为网络的输入。
utils.py文件主要是对网络的输出数据进行处理,包括计算iou,画框等功能
train.py文件是对数据进行训练,在train中调用了上述所有的文件,所以接下来的流程是从train中主要展开的。
test.py和load_model.ipynb文件就是对训练的网络进行测试。
2、代码解读
从train开始,按照流程开始走。
#导入所需的库
import argparse
import os
import json
from preprocessing import parse_annotation # 文件夹中的文件,一定要cd到当前文件夹
#或者设置sys.path定位到当前的路径下
import numpy as np
from frontend import YOLO
from matplotlib import pyplot as plt
# 设置just use cpu
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]=""
# 应该了解的argparse参数解析模块,比如linux命令中的 list -a ,其中a就是这样被传递进来的
#这里我们将config配置文件这样传递进来
argparser=argparse.ArgumentParser()
argparser.add_argument("-c","--conf",help="configuration file path")
# train文件中唯一定义的一个函数
def parse_config(args):
config_path=args.conf
with open(config_path) as config_buffer: # 读取 config.json文件,json.loads为反序列化
config=json.loads(config_buffer.read())
# os.environ["CUDA_VISIBLE_DEVICES"]=config["env"]["gpu"]
# gpus=max(1,len(config["env"]["gpu"].split(",")))
#调用 procrssing.py文件中的parse_annotation方法
imgs,labels=parse_annotation(config["train"]["train_annot_folder"],
config["train"]["train_image_folder"],config["model"]["labels"])
#############################
'''
# 调用该函数得到类似这样的结构:
imgs[0]:{'object': [{'name': 'RBC',
'xmin': 81,
'ymin': 88,
'xmax': 522,
'ymax': 408}],
'filename': 'xxxxxxxxx/images/RBC1.jpg',
'width': 650,
'height': 417}
# 讲每张图像的地址信息,框信息,label信息等都进行封装
def parse_annotation(anno_dir,img_dir,labels):
all_imgs=[]
seen_labels={}
#解析.xml文件,也就是annotations文件夹下的文件
for ann in sorted(os.listdir(anno_dir)):
img={"object":[]}
tree=ET.parse(anno_dir+ann)
#接下来就是根据key定位到相应的地方,并取值 赋值
for elem in tree.iter():
if "filename" in elem.tag:
img["filename"]=img_dir+elem.text+".jpg"
# print(img["filename"])
if "width" in elem.tag:
img["width"]=int(elem.text)
# print(img["width"])
if "height" in elem.tag:
img["height"]=int(elem.text)
# print(img["height"])
if "object" in elem.tag or "part" in elem.tag:
obj={}
for attr in list(elem):
if "name" in attr.tag:
obj["name"]=attr.text
if obj["name"] in seen_labels:
seen_labels[obj["name"]]+=1
else:
seen_labels[obj["name"]]=1
if len(labels)>0 and obj["name"] not in labels:
break
else:
img["object"]+=[obj]
if "bndbox" in attr.tag:
for dim in list(attr):
if "xmin" in dim.tag:
obj["xmin"]=int(round(float(dim.text)))
if "ymin" in dim.tag:
obj["ymin"]=int(round(float(dim.text)))
if "xmax" in dim.tag:
obj["xmax"]=int(round(float(dim.text)))
if "ymax" in dim.tag:
obj["ymax"]=int(round(float(dim.text)))
if len(img["object"])>0:
all_imgs+=[img]
return all_imgs,seen_labels
'''
#############################
#划分 训练集和验证集
train_valid_split=int(0.8*len(imgs))
np.random.shuffle(imgs)
valid_imgs=imgs[train_valid_split:]
train_imgs=imgs[:train_valid_split]
# set的intersection方法用于返回两个集合中都有的元素
overlap_labels=set(config["model"]["labels"]).intersection(set(labels.keys()))
print("Seen labels: "+str(labels))
print("Given labels: "+str(config["model"]["labels"]))
print("Overelap labels: "+str(overlap_labels))
if len(overlap_labels)YOLO网络分析:
class YOLO(object):
#构造函数,创建yolo对象的时候会自动运行
def __init__(self,architecture,
input_size,
labels,
max_box_per_img,
anchors,
gpus=0):
self.input_size=input_size
self.labels=list(labels)
self.nb_class=len(self.labels)
self.nb_box=5
self.class_wt=np.ones(self.nb_class,dtype="float32")
self.anchors=anchors
self.gpus=gpus
self.max_box_per_img=max_box_per_img
##Define model with cpu
with tf.device("/cpu:0"):
input_=Input(shape=(self.input_size,self.input_size,3))
self.true_boxes=Input(shape=(1,1,1,self.max_box_per_img,4))
#此处使用的为Tiny Yolo--base model
if architecture=="Tiny Yolo":
self.feature_extractor=TinyYolo(self.input_size)
elif architecture=="Full Yolo":
self.feature_extractor=FullYolo(self.input_size)
else:
raise Exception("Architecture not found...")
#######################
# Tiny Yolo的网络结构
'''
class TinyYolo(BaseFeatureExtractor):
#也是构造函数
def __init__(self,input_size):
input_=Input(shape=(input_size,input_size,3))
#Layer 1
x=Conv2D(int(ALPHA*16),(3,3),padding="same",use_bias=False)(input_)
x=BatchNormalization()(x)
x=LeakyReLU(alpha=0.1)(x)
x=MaxPooling2D()(x)
#Layer 2-5
for i in range(4):
x=Conv2D(int(ALPHA*32*(2**i)),(3,3),padding="same",use_bias=False)(x)
x=BatchNormalization()(x)
x=LeakyReLU(alpha=0.1)(x)
x=MaxPooling2D()(x)
#Layer 6
x=Conv2D(int(ALPHA*512),(3,3),padding="same",use_bias=False)(x)
x=BatchNormalization()(x)
x=LeakyReLU(alpha=0.1)(x)
x=MaxPooling2D(strides=(1,1),padding="same")(x)
#Layer 7-8
for i in range(2):
x=Conv2D(int(ALPHA*1024),(3,3),padding="same",use_bias=False)(x)
x=BatchNormalization()(x)
x=LeakyReLU(alpha=0.1)(x)
# Model定义完成
self.feature_extractor=Model(input_,x)
self.feature_extractor.load_weights(TINY_YOLO_WEIGHTS)
print("load weights from "+TINY_YOLO_WEIGHTS)
'''
#######################
self.grid_h,self.grid_w=self.feature_extractor.get_output_shape()
features=self.feature_extractor.extract(input_)
# 在TinyYolo基础上增加新的卷基层
output=Conv2D(self.nb_box*(4+1+self.nb_class),(1,1),strides= (1,1),padding="same")(features)
output=BatchNormalization()(output)
output=Activation("relu")(output)
output=Reshape((self.grid_h,self.grid_w,self.nb_box,4+1+self.nb_class))(output)
#这句话的意思,其实就是把output作为最终的输出,因为args:args[0]
#如果变为args:args[1],那就是输出self.true_boxes
#为什么加上这句话,就是因为之前定义了true_boxes,这里如果不使用(或者说注册下),model无法编译
output=Lambda(lambda args:args[0])([output,self.true_boxes])
# 最终的model,两个输入,其实true_boxes没什么用,可以去除,yolov3有的网络就将其去掉了
self.orgmodel=Model([input_,self.true_boxes],output)
# 初始化权重,权重的初始化很重要,一般选用正态分布的权重
layer=self.orgmodel.layers[-6]
weights=layer.get_weights()
new_kernel=np.random.normal(size=weights[0].shape)/(self.grid_h*self.grid_w)
new_bias=np.random.normal(size=weights[1].shape)/(self.grid_h*self.grid_w)
layer.set_weights([new_kernel,new_bias])
if gpus>1:
self.model=multi_gpu_model(self.orgmodel,self.gpus)
else:
self.model=self.orgmodel最终的网络构造如下:第一个None表示batch的大小,也就是样本数量的多少。
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 416, 416, 3) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 416, 416, 1) 27 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 416, 416, 1) 4 conv2d_1[0][0]
__________________________________________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 416, 416, 1) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 208, 208, 1) 0 leaky_re_lu_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 208, 208, 3) 27 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 208, 208, 3) 12 conv2d_2[0][0]
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 208, 208, 3) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 104, 104, 3) 0 leaky_re_lu_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 104, 104, 6) 162 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 104, 104, 6) 24 conv2d_3[0][0]
__________________________________________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 104, 104, 6) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, 52, 52, 6) 0 leaky_re_lu_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 52, 52, 12) 648 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 52, 52, 12) 48 conv2d_4[0][0]
__________________________________________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 52, 52, 12) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
max_pooling2d_4 (MaxPooling2D) (None, 26, 26, 12) 0 leaky_re_lu_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 26, 26, 25) 2700 max_pooling2d_4[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 26, 26, 25) 100 conv2d_5[0][0]
__________________________________________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 26, 26, 25) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
max_pooling2d_5 (MaxPooling2D) (None, 13, 13, 25) 0 leaky_re_lu_5[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 13, 13, 51) 11475 max_pooling2d_5[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 13, 13, 51) 204 conv2d_6[0][0]
__________________________________________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 13, 13, 51) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
max_pooling2d_6 (MaxPooling2D) (None, 13, 13, 51) 0 leaky_re_lu_6[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 13, 13, 102) 46818 max_pooling2d_6[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 13, 13, 102) 408 conv2d_7[0][0]
__________________________________________________________________________________________________
leaky_re_lu_7 (LeakyReLU) (None, 13, 13, 102) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 13, 13, 102) 93636 leaky_re_lu_7[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, 13, 13, 102) 408 conv2d_8[0][0]
__________________________________________________________________________________________________
leaky_re_lu_8 (LeakyReLU) (None, 13, 13, 102) 0 batch_normalization_8[0][0]
__________________________________________________________________________________________________
next_begin (Conv2D) (None, 13, 13, 30) 3090 leaky_re_lu_8[0][0]
__________________________________________________________________________________________________
batch_normalization_13 (BatchNo (None, 13, 13, 30) 120 next_begin[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 13, 13, 30) 0 batch_normalization_13[0][0]
__________________________________________________________________________________________________
reshape_5 (Reshape) (None, 13, 13, 5, 6) 0 activation_5[0][0]
__________________________________________________________________________________________________
input_6 (InputLayer) (None, 1, 1, 1, 20, 0
__________________________________________________________________________________________________
lambda_5 (Lambda) (None, 13, 13, 5, 6) 0 reshape_5[0][0]
input_6[0][0]
==================================================================================================
Total params: 159,911
Trainable params: 159,247
Non-trainable params: 664
__________________________________________________________________________________________________最终13*13*5×6表示原始416*416大小的图像变为13*13的大小,5表示每个cell(一共13*13个cell)预测的框的个数,也可以说是每个cell中最多预测的物体数。6表示(4+1+1,4:坐标x y and 长宽,1:预测概率,1:类别个数,此处只有一个类别)
def train(self,train_imgs,
valid_imgs,
train_times,
valid_times,
nb_epochs,
learning_rate,
batch_size,
warmup_epochs,
object_scale,
no_object_scale,
coord_scale,
class_scale,
saved_weights_name="best_weights.h5",
train=True):
self.batch_size=batch_size
self.object_scale=object_scale
self.no_object_scale=no_object_scale
self.coord_scale=coord_scale
self.class_scale=class_scale
generator_config={
"IMAGE_H":self.input_size,
"IMAGE_W":self.input_size,
"GRID_H":self.grid_h,
"GRID_W":self.grid_w,
"BOX":self.nb_box,
"LABELS":self.labels,
"CLASS":len(self.labels),
"ANCHORS":self.anchors,
"BATCH_SIZE":self.batch_size,
"TRUE_BOX_BUFFER":self.max_box_per_img
}
# d调用processing.py中的 BatchGenerator方法
# 生成一个个batch,然后根据BatchGenerator的idx参数更换batch
train_generator=BatchGenerator(train_imgs,generator_config,norm=self.feature_extractor.normalize)
##############################
'''
class BatchGenerator(Sequence):
def __init__(self,imgs,
config,
norm=None):
self.generator=None
self.imgs=imgs
self.config=config
self.norm=norm
self.counter=0
self.anchors=[BndBox(0,0,config["ANCHORS"][2*i],config["ANCHORS"][2*i+1]) for i in range(len(config["ANCHORS"])//2)]
self.aug_pipe=iaa.Sequential([iaa.SomeOf((0, 5),
[
iaa.OneOf([
iaa.GaussianBlur((0, 3.0)), # blur images with a sigma between 0 and 3.0
iaa.AverageBlur(k=(2, 7)), # blur image using local means with kernel sizes between 2 and 7
iaa.MedianBlur(k=(3, 11)), # blur image using local medians with kernel sizes between 2 and 7
]),
iaa.Sharpen(alpha=(0, 1.0), lightness=(0.75, 1.5)), # sharpen images
iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.05*255), per_channel=0.5), # add gaussian noise to images
iaa.OneOf([
iaa.Dropout((0.01, 0.1), per_channel=0.5), # randomly remove up to 10% of the pixels
]),
iaa.Add((-10, 10), per_channel=0.5), # change brightness of images (by -10 to 10 of original value)
iaa.Multiply((0.5, 1.5), per_channel=0.5), # change brightness of images (50-150% of original value)
iaa.ContrastNormalization((0.5, 2.0), per_channel=0.5), # improve or worsen the contrast
],random_order=True)
],random_order=True)
np.random.shuffle(self.imgs)
def __len__(self):
return int(np.ceil(len(self.imgs)/self.config["BATCH_SIZE"]))
# python 类的魔法方法,使用key方法时会自动调用
def __getitem__(self,idx):
l_bound=idx*self.config["BATCH_SIZE"]
r_bound=(idx+1)*self.config["BATCH_SIZE"]
if r_bound>len(self.imgs):
r_bound=len(self.imgs)
l_bound=len(self.imgs)-self.config["BATCH_SIZE"]
instance_count=0
x_batch=np.zeros((r_bound-l_bound,self.config["IMAGE_H"],self.config["IMAGE_W"],3))
b_batch=np.zeros((r_bound-l_bound,1,1,1,self.config["TRUE_BOX_BUFFER"],4))
y_batch=np.zeros((r_bound-l_bound,self.config["GRID_H"],self.config["GRID_W"],self.config["BOX"],4+1+len(self.config["LABELS"])))
for train_instance in self.imgs[l_bound:r_bound]:
img,all_objs=self.aug_img(train_instance)
true_box_index=0
for obj in all_objs:
center_x=0.5*(obj["xmin"]+obj["xmax"])
center_x=center_x/(float(self.config["IMAGE_W"])/self.config["GRID_W"])
center_y=0.5*(obj["ymin"]+obj["ymax"])
center_y=center_y/(float(self.config["IMAGE_H"])/self.config["GRID_H"])
grid_x=int(np.floor(center_x))
grid_y=int(np.floor(center_y))
obj_index=self.config["LABELS"].index(obj["name"])
center_w=(obj["xmax"]-obj["xmin"])/(float(self.config["IMAGE_W"])/self.config["GRID_W"])
center_h=(obj["ymax"]-obj["ymin"])/(float(self.config["IMAGE_H"])/self.config["GRID_H"])
box=[center_x,center_y,center_w,center_h]
best_anchor=-1
max_iou=-1
shifted_box=BndBox(0,0,center_w,center_h)
for i in range(len(self.anchors)):
anchor=self.anchors[i]
iou=bbox_iou(shifted_box,anchor)
if max_iou
再加上一些个人的理解,后续持续更新,自己理解还好,但是写起来太不好写了
yolo的损失函数是多方的加和,因为类别要比坐标误差更重要些,因此设置了不同的权重参数,还有就是网络的输出,网络的输出就是S*S*(B*5 + C)维向量,其中有划分的格点数,种类以及其他的,并且loss也是根据输出向量来计算的,参考这个博客
https://www.cnblogs.com/demian/p/9252038.html 其中缩写 gt 指的应该是ground truth
最后的predict,因为有可能一个物体会在不同的格子里面检测到,因此最后还需要进行NMS进行最后的输出,
yolo网络的输入有两部分,这点需要注意,一个是图像img,另一个是box的集合,里面是坐标。输出y是S*S*(B*5 + C)的矩阵,
keras网络的输入为一个tuple,系统会 自动 将第一项识别为输入,第二项识别为输出,同理,对于keras的loss也一样,系统会自动的讲网络的输出识别为y_pre,将输入y识别为y_true, 这两个参数就是loss默认的参数,当然你也可以手动的指定,这都是在默认的情况下进行的,大多数情况下都是这么使用。
yolo中常常提到的frontend 和 backend 其实对应的是两个文件或者说两种说法概念,其中backend更多的指的是yolo底层网络的定义和实现,比如我在backend中定义了两种网络tiny_yolo and full_yolo两种,那么在frontend中我就可以任意的调用这两种网络,搭建我的上层网络,其次在frontend中还可以定义loss等,从而更好的封装我们的函数,使得在最终的程序会特别简洁。
为什么在有的yolo网络中会有两个权重,一个yolo_backend, 一个yolo_xx.h5 ,这是因为就像上面说的在backend中会有一个基础的网络,这个技术的网络有一个权重,然后在此基础之上还有一个网络,整个网络在进行训练,然后这整个网络的权重保存在yolo_xx.h5中,所以可以说这是为了进行迁移学习。
为什么会有true_boxes这个输入,可以参考这个github上的解释(small hack to allow true_boxes to be registered when Keras build the model)https://github.com/keras-team/keras/issues/2790,因为要注册该输入,但是在真正的网络中该输入没有用到,只是为了编译模型好用而已。(比如就在yolov3中就没有这个输入)
这篇博客https://www.cnblogs.com/makefile/p/YOLOv3.html讲了三种yolo模型之间的区别和联系,讲的挺不错,坐下记录写在blog里面。里面提到的多尺度间进行融合这个处理的方法需要进行理解,很巧妙,但是确实进行了融合。但是有的见到的yolov3(yolo9000)的代码直接输出三个尺度的特征作为输出,并没有做最后的融合。
其中nb_box指的是每个cell最多有几个物体存在,从某一层的con2d的filter参数中可以知道。
true_boxes是每张图多可以标注的物体数量。