分析Threadlocal内部实现原理,并解决Threadlocal的ThreadLocalMap的hash冲突与内存泄露
前言
ThreadLocal 的经典使用场景是数据库连接、 session 管理、多线程等……
比如在Spring中,发挥着巨大的作用,在管理Request作用域中的Bean、事务管理、任务调度、AOP等模块都不同程度使用了ThreadLocal 。
Spring中绝大部分Bean,都可以声明成Singleton作用域,采用ThreadLocal进行封装,因此有状态的Bean,就能够以singleton的方式,在多线程中正常工作。
知道Threadlocal怎么用,但是不知道为什么要这样用?底层原理是什么?Threadlocal发生hashmap的hash冲突,怎么办?
threadlocal是什么?
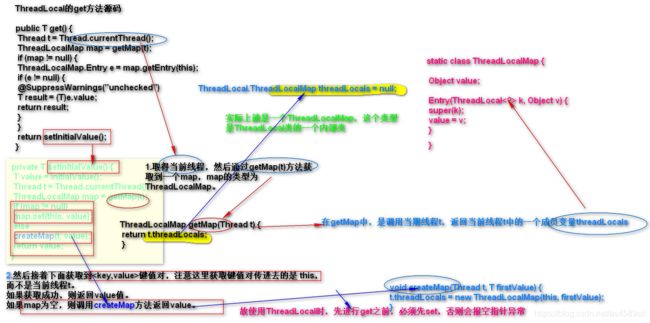
ThreadLocal提供线程局部变量。
//get()方法是用来获取ThreadLocal在当前线程中保存的变量副本
public T get() { }
//set()用来设置当前线程中变量的副本
public void set(T value) { }
//remove()用来移除当前线程中变量的副本
public void remove() { }
//initialValue()是一个protected方法,一般是用来在使用时进行重写的,它是一个延迟加载方法
protected T initialValue(){ }这些变量与普通的变量不同之处在于,每个访问这种变量的线程(通过它的get或set方法)都有自己的、独立初始化的变量副本。
ThreadLocal实例,通常是希望将状态关联到一个线程的类的私有静态字段(比如,user ID 或者 Transaction ID 等等)。
总而言之:
- ThreadLocal是一种变量类型,我们称之为“线程局部变量”。
- 每个线程访问这种变量的时候,都会创建该变量的副本,这个变量副本为线程私有。
- ThreadLocal类型的变量,一般用private static加以修饰。
例如,下面的例子中这个类为每个线程生成唯一标识。一个线程的id是它第一次调用ThreadId.get()方法指定的。
package com.azdebugit.threadlocal;
public class ThreadLocalExsample {
private static ThreadLocal longLocal = new ThreadLocal<>();
public void set() {
longLocal.set(Thread.currentThread().getId());
}
public long getLong() {
return longLocal.get();
}
public static void main(String[] args) {
ThreadLocalExsample test = new ThreadLocalExsample();
//注意:没有set之前,直接get,报null异常了
test.set();
System.out.println("-------threadLocal value-------" + test.getLong());
longLocal.remove();
}
} ThreadLocal的应用场景
注意:使用ThreadLocal时,先进行get之前,必须先set,否则会报空指针异常
数据库连接
@Component
public class ConnectionHolderUtil {
private static DataSource dataSource;
private static final Logger log = LoggerFactory.getLogger(ConnectionHolderUtil.class);
@Autowired
public void setDataSource(DataSource dataSource) {
ConnectionHolderUtil.dataSource = dataSource;
}
private static ThreadLocal connectionHolderThreadLocal = new ThreadLocal<>();
/** * 获取数据库连接 * @return Connection */
public static ConnectionHolder getConnectionHolder(boolean isNew){
ConnectionHolder connectionHolder = connectionHolderThreadLocal.get();
//如果有连接,并不需要生成新的直接返回
if(connectionHolder != null && !isNew){
return connectionHolder;
}
try {
//获取新连接
Connection connection = dataSource.getConnection();
//关闭自动提交
connection.setAutoCommit(false);
connectionHolder = new ConnectionHolder(connection);
connectionHolderThreadLocal.set(connectionHolder);
//绑定连接
TransactionSynchronizationManager.bindResource(dataSource,connectionHolder);
return connectionHolder;
} catch (SQLException e) {
log.error("数据库连接获取失败",e);
return null;
}
}
/** * 提交事务 */
public static void commit(){
ConnectionHolder connectionHolder = connectionHolderThreadLocal.get();
if(connectionHolder == null){
return;
}
try {
connectionHolder.getConnection().commit();
} catch (SQLException e) {
log.error("提交失败",e);
}
}
/** * 事务回滚 */
public static void rollback(){
ConnectionHolder connectionHolder = connectionHolderThreadLocal.get();
if(connectionHolder == null){
return;
}
try {
connectionHolder.getConnection().rollback();
} catch (SQLException e) {
log.error("回滚失败",e);
}
}
/** * 关闭连接 */
public static void close(){
ConnectionHolder connectionHolder = connectionHolderThreadLocal.get();
if(connectionHolder == null){
return;
}
Connection connection = connectionHolder.getConnection();
try {
connection.close();
} catch (SQLException e) {
log.error("数据库连接关闭失败",e);
}
}
/** * 恢复挂起的事务 */
public static void resume(Object susPend){
TransactionSynchronizationManager.unbindResource(dataSource);
TransactionSynchronizationManager.bindResource(dataSource,susPend);
connectionHolderThreadLocal.set((ConnectionHolder) susPend);
}
/** * 挂起当前事务 */
public static Object hangTrasaction(){
return TransactionSynchronizationManager.unbindResource(dataSource);
}
/** * 判断当前连接是否已经关闭 * @return */
public static boolean isClose(){
if(connectionHolderThreadLocal.get() == null){
return true;
}
try {
return connectionHolderThreadLocal.get().getConnection().isClosed();
} catch (SQLException e) {
log.error("获取连接状态失败");
}
return true;
}
} Session管理
@SuppressWarnings("unchecked")
public class UserSession {
private static final ThreadLocal SESSION_MAP = new ThreadLocal();
protected UserSession() {
}
public static Object get(String attribute) {
Map map = (Map) SESSION_MAP.get();
return map.get(attribute);
}
public static T get(String attribute, Class clazz) {
return (T) get(attribute);
}
public static void set(String attribute, Object value) {
Map map = (Map) SESSION_MAP.get();
if (map == null) {
map = new HashMap();
SESSION_MAP.set(map);
}
map.put(attribute, value);
}
} 多线程
package com.azdebugit.threadlocal;
import java.util.concurrent.atomic.AtomicInteger;
public class ThreadLocalExsampl {
/**
* 创建了一个MyRunnable实例,并将该实例作为参数传递给两个线程。两个线程分别执行run()方法,
* 并且都在ThreadLocal实例上保存了不同的值。如果它们访问的不是ThreadLocal对象并且调用的set()方法被同步了,
* 则第二个线程会覆盖掉第一个线程设置的值。但是,由于它们访问的是一个ThreadLocal对象,
* 因此这两个线程都无法看到对方保存的值。也就是说,它们存取的是两个不同的值。
*/
public static class MyRunnable implements Runnable {
/**
* 例化了一个ThreadLocal对象。我们只需要实例化对象一次,并且也不需要知道它是被哪个线程实例化。
* 虽然所有的线程都能访问到这个ThreadLocal实例,但是每个线程却只能访问到自己通过调用ThreadLocal的
* set()方法设置的值。即使是两个不同的线程在同一个ThreadLocal对象上设置了不同的值,
* 他们仍然无法访问到对方的值。
*/
private static ThreadLocal threadLocal = new ThreadLocal();
@Override
public void run() {
//一旦创建了一个ThreadLocal变量,你可以通过如下代码设置某个需要保存的值
AtomicInteger atomicInteger = new AtomicInteger();
int threadLo = (int) (Math.random() * 100D);
System.out.println("-------"+atomicInteger.incrementAndGet()+"-------" + threadLo);
threadLocal.set(threadLo);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
//可以通过下面方法读取保存在ThreadLocal变量中的值
System.out.println("-------"+atomicInteger.incrementAndGet()+"-------"+threadLocal.get());
threadLocal.remove();
}
}
public static void main(String[] args) {
MyRunnable sharedRunnableInstance = new MyRunnable();
for (int i = 0; i < 5; i++) {
Thread thread1 = new Thread(sharedRunnableInstance);
Thread thread2 = new Thread(sharedRunnableInstance);
thread1.start();
thread2.start();
}
}
}
hashmap的hash冲突
hash冲突--源码分析
HashMap 采用一种所谓的“Hash 算法”来决定每个元素的存储位置。
当程序执行 map.put(String,Obect)方法 时,系统将调用String的 hashCode() 方法,得到其 hashCode 值(每个 Java 对象都有 hashCode() 方法,都可通过该方法获得它的 hashCode 值)。

得到这个对象的 hashCode 值之后,系统会根据该 hashCode 值来决定该元素的存储位置。源码如下:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
//判断当前确定的索引位置是否存在相同hashcode和相同key的元素,如果存在相同的hashcode和相同的key的元素,那么新值覆盖原来的旧值,并返回旧值。
//如果存在相同的hashcode,那么他们确定的索引位置就相同,这时判断他们的key是否相同,如果不相同,这时就是产生了hash冲突。
//Hash冲突后,那么HashMap的单个bucket里存储的不是一个 Entry,而是一个 Entry 链。
//系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止——如果恰好要搜索的 Entry 位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),
//那系统必须循环到最后才能找到该元素。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
当系统决定存储 HashMap 中的 key-value 对时,完全没有考虑 Entry 中的 value,仅仅只是根据 key 来计算,并决定每个 Entry 的存储位置。这也说明了前面的结论:我们完全可以把 Map 集合中的 value 当成 key 的附属,当系统决定了 key 的存储位置之后,value 随之保存在那里即可。
链式地址法--解决散列值的冲突
Hashmap里面的bucket,出现了单链表的形式,散列表要解决的一个问题,就是散列值的冲突问题,通常是两种方法:链表地址法和开放地址法。
- 链表法,就是将相同hash值的对象,组织成一个链表,放在hash值对应的槽位;
- 开放地址法,是通过一个探测算法,当某个槽位已经被占据的情况下,继续查找下一个可以使用的 槽位。
java.util.HashMap采用的链表法的方式,链表是单向链表。形成单链表的核心代码如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
} 上面方法的代码很简单,但其中包含了一个设计:系统总是将新添加的 Entry 对象,放入 table 数组的 bucketIndex 索引处。
- 如果 bucketIndex 索引处,已经有了一个 Entry 对象,那新添加的 Entry 对象,指向原有的 Entry 对象(产生一个 Entry 链)。
- 如果 bucketIndex 索引处没有 Entry 对象,也就是上面程序代码的 e 变量是 null,也就是新放入的 Entry 对象指向 null,也就是没有产生 Entry 链。
- HashMap里面没有出现hash冲突时,没有形成单链表时,hashmap查找元素很快,get()方法能够直接定位到元素。
- 但是出现单链表后,单 个bucket 里存储的不是一个 Entry,而是一个 Entry 链,系统只能必须按顺序遍历每个 Entry,直到找到想搜索的 Entry 为止。
- 如果恰好要搜索的 Entry ,位于该 Entry 链的最末端(该 Entry 是最早放入该 bucket 中),那系统必须循环到最后才能找到该元素。
当创建 HashMap 时,有一个默认的负载因子(load factor),其默认值为 0.75,这是时间和空间成本上一种折衷:
- 增大负载因子,可以减少 Hash 表(就是那个 Entry 数组)所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的的操作(HashMap 的 get() 与 put() 方法都要用到查询);
- 减小负载因子会提高数据查询的性能,但会增加 Hash 表所占用的内存空间。
解决Threadlocal的hashmap的hash冲突
Threadlocal如何2层kv的map
每个线程都各自有一张独立的散列表,以ThreadLocal对象作为散列表的key,set方法中的值作为value(第一次调用get方法时,以initialValue方法的返回值作为value)。
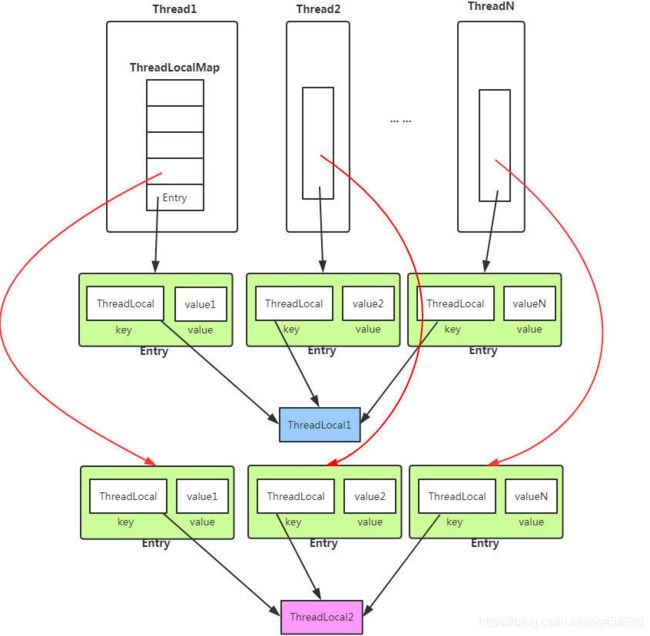
如上图,可以ThreadLocal类用两层HashMap的kv,进行对象存储。
外面的HashMap的Key是ThreadID,Value是内层的ThreadLocalMap的维护的Entry(ThreadLocal k, Object v)数组。
内层的HashMap的Key是当前ThreadLocal对象,Value是当前ThreadLocal的值。
所以在Threadlocal中,一个线程中,可能会拥有多个ThreadLocal成员变量,所以内层ThreadLocalMap是为了保存同一个线程中的不同ThreadLocal变量。
ThreadLocal造成的内存泄露和相应解决办法

ThreadLocalMap中用内部静态类Entry表示了散列表中的每一个条目,下面是它的代码
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
} 可以看出Entry类继承了WeakRefrence类,所以一个条目,就是一个弱引用类型的对象(要搞清楚,持有weakRefrence对象的引用是个强引用),那么这个weakRefrence对象,保存了谁的弱引用呢?
我们看到构造函数中有个supe(k),k是ThreadLocal类型对象,super表示是调用父类(weakRefrence)的构造函数,所以说一个entry对象中,存储了ThreadLocal对象的弱引用和这个ThreadLocal对应的value对象的强引用。

那Entry中为什么保存的是key的弱引用呢?
其实这是为了最大程度上减少内存泄露,副作用是同时减少哈希表中的冲突。
当ThreadLocal对象被回收时,对应entry中的key就自动变成null(entry对象本身不为null)。
线程池中的线程是重复使用的,意味着这个线程的ThreadLocalMap对象也是重复使用的,如果我们不手动调用remove方法,那么后面的线程,就有可能获取到上个线程遗留下来的value值,造成bug。
ThreadLocal-hash冲突及解决方案--线性探测
ThreadLocal对于不同的线程,每次获取副本值时,别的线程并不能获取到当前线程的副本值,形成了副本的隔离,互不干扰。
ThreadLocalMap是ThreadLocal的内部类,没有实现Map接口,用独立的方式实现了Map的功能,其内部的Entry也独立实现。
Entry便是ThreadLocalMap里定义的节点,它继承了WeakReference类,定义了一个类型为Object的value,用于存放塞到ThreadLocal里的值。
在ThreadLocalMap中,也是用Entry来保存K-V结构数据的。但是Entry中key,只能是ThreadLocal对象,这点被Entry的构造方法已经限定死了。
static class Entry extends WeakReference {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
} Entry继承自WeakReference(弱引用,生命周期只能存活到下次GC前),但只有Key是弱引用类型的,Value并非弱引用。
和HashMap的最大的不同在于,ThreadLocalMap结构非常简单,没有next引用,也就是说ThreadLocalMap中解决Hash冲突的方式,并非链表的方式,而是采用线性探测的方式(开放地址法)。
所谓线性探测,就是根据初始key的hashcode值,确定元素在table数组中的位置,如果发现这个位置上,已经有其他key值的元素被占用,则利用固定的算法,寻找一定步长的下个位置,依次判断,直至找到能够存放的位置。
核心:由于ThreadLocalMap使用线性探测法,来解决散列冲突,所以实际上Entry[]数组在程序逻辑上,是作为一个环形存在的。
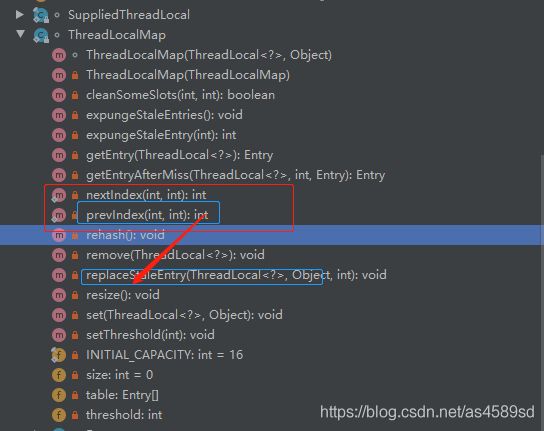
ThreadLocalMap解决Hash冲突的方式,就是简单的步长加1或减1,寻找下一个相邻的位置。
线性探测法:直接使用数组来存储数据。可以想象成一个停车问题。若当前车位已经有车,则你就继续往前开,直到找到下一个为空的车位。
/**
* Increment i modulo len.
*/
private static int nextIndex(int i, int len) {
return ((i + 1 < len) ? i + 1 : 0);
}
/**
* Decrement i modulo len.
*/
private static int prevIndex(int i, int len) {
return ((i - 1 >= 0) ? i - 1 : len - 1);
}实现步骤:
- 得到 key
- 计算得 hashValue
- 若不冲突,则直接填入数组
- 若冲突,则使 hashValue++ ,也就是往后找,直到找到第一个 data[hashValue] 为空的情况,则填入。若到了尾部可循环到前面。
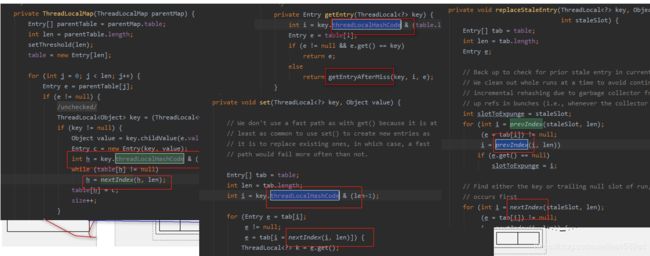
显然ThreadLocalMap采用线性探测的方式,解决Hash冲突的效率很低,如果有大量不同的ThreadLocal对象放入map中时发送冲突,或者发生二次冲突,则效率很低。
所以这里引出的良好建议是:
每个线程只存一个变量,这样所有的线程,存放到map中的Key,都是相同的ThreadLocal,如果一个线程,要保存多个变量,就需要创建多个ThreadLocal,多个ThreadLocal放入Map中时,会极大的增加Hash冲突的可能。