Flume简介及Flume部署、原理和使用介绍
Flume简介及Flume部署、原理和使用介绍
Flume概述
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
Flume最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS。

Flume架构

Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的。
Agent主要有3个部分组成,Source、Channel、Sink。
Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
Event
传输单元,Flume数据传输的基本单元,以Event的形式将数据从源头送至目的地。Event由Header和Body两部分组成,Header用来存放该event的一些属性,为K-V结构,Body用来存放该条数据,形式为字节数组。
Header(k=v)
Body(byte array)
Flume安装部署
URL链接
(1) Flume官网地址:http://flume.apache.org/
(2)文档查看地址:http://flume.apache.org/FlumeUserGuide.html
(3)下载地址:http://archive.apache.org/dist/flume/
安装部署
# 下载安装包
wangting@ops01:/home/wangting >
wangting@ops01:/home/wangting >cd /opt/software/
wangting@ops01:/opt/software >wget http://archive.apache.org/dist/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
wangting@ops01:/opt/software >ll | grep flume
-rw-r--r-- 1 wangting wangting 67938106 Apr 17 14:09 apache-flume-1.9.0-bin.tar.gz
# 解压apache-flume-1.9.0-bin.tar.gz到/opt/module/目录下
wangting@ops01:/opt/software >tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
# 将目录名字mv改名,精简目录
wangting@ops01:/opt/software >mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume
wangting@ops01:/opt/software >cd /opt/module/flume/
# 目录结构 [少部分目录是后续任务生成的,例如datas logs等,不必在意]
wangting@ops01:/opt/module/flume >ll
total 180
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 bin
-rw-rw-r-- 1 wangting wangting 85602 Nov 29 2018 CHANGELOG
drwxr-xr-x 2 wangting wangting 4096 Apr 17 16:26 conf
drwxrwxr-x 2 wangting wangting 4096 Apr 17 15:58 datas
-rw-r--r-- 1 wangting wangting 5681 Nov 16 2017 DEVNOTES
-rw-r--r-- 1 wangting wangting 2873 Nov 16 2017 doap_Flume.rdf
drwxrwxr-x 12 wangting wangting 4096 Dec 18 2018 docs
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:15 lib
-rw-rw-r-- 1 wangting wangting 43405 Dec 10 2018 LICENSE
drwxrwxr-x 2 wangting wangting 4096 Apr 17 16:28 logs
-rw-r--r-- 1 wangting wangting 249 Nov 29 2018 NOTICE
-rw-r--r-- 1 wangting wangting 2483 Nov 16 2017 README.md
-rw-rw-r-- 1 wangting wangting 1958 Dec 10 2018 RELEASE-NOTES
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 tools
# 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
wangting@ops01:/opt/module/flume >rm /opt/module/flume/lib/guava-11.0.2.jar
# 配置环境变量 [增加如下内容]
wangting@ops01:/opt/module/flume >sudo vim /etc/profile
#flume
export FLUME_HOME=/opt/module/flume
export PATH=$PATH:$FLUME_HOME/bin
wangting@ops01:/opt/module/flume >
wangting@ops01:/opt/module/flume >
# 引用/etc/profile生效
wangting@ops01:/opt/module/flume >source /etc/profile
# 验证flume-ng命令是否可用
wangting@ops01:/opt/module/flume >flume-ng version
Flume 1.9.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: d4fcab4f501d41597bc616921329a4339f73585e
Compiled by fszabo on Mon Dec 17 20:45:25 CET 2018
From source with checksum 35db629a3bda49d23e9b3690c80737f9
Flume使用案例1
场景:监控端口数据官方案例
背景需求:
使用Flume监听一个端口,收集该端口数据,并打印到控制台
- 通过编写Flume配置文件,定义一个agent任务来持续监听44444端口
- 通过netcat工具向端口44444发送文本数据,nc ip port [这里的工具仅仅是为了模拟一个应用吐数据]
- netcat向flume监听的44444推送数据,来模拟业务场景实时数据推送的日志或数据
- Flume通过source组件读取44444端口数据
- Flume将获取的数据最终通过Sink写到控制台
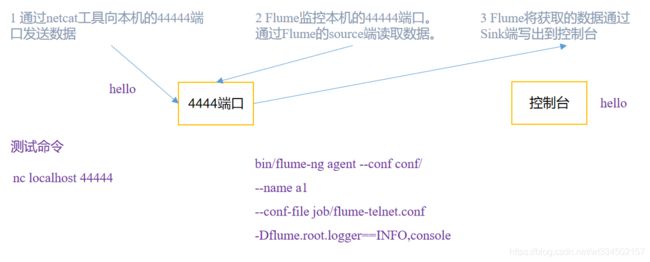
准备工作,编写配置
# # # 准备工作 # # #
wangting@ops01:/home/wangting >sudo yum install -y nc
wangting@ops01:/home/wangting >
# 判断44444端口是否被占用
wangting@ops01:/home/wangting >sudo netstat -tunlp | grep 44444
wangting@ops01:/home/wangting >cd /opt/module/flume/
# 创建目录存放定义文件
wangting@ops01:/opt/module/flume >mkdir datas
wangting@ops01:/opt/module/flume >cd datas/
# 在datas文件夹下创建netcatsource_loggersink.conf
wangting@ops01:/opt/module/flume/datas >touch netcatsource_loggersink.conf
wangting@ops01:/opt/module/flume/datas >ls
netcatsource_loggersink.conf
wangting@ops01:/opt/module/flume/datas >vim netcatsource_loggersink.conf
#bigdata是agent的名字
#定义的source,channel,sink的个数可以是多个,中间用空格隔开
#定义source
bigdata.sources = r1
#定义channel
bigdata.channels = c1
#定义sink
bigdata.sinks = k1
#声明source具体的类型和对应的一些配置
bigdata.sources.r1.type = netcat
bigdata.sources.r1.bind = ops01
bigdata.sources.r1.port = 44444
#声明channel具体的类型和对应的一些配置
bigdata.channels.c1.type = memory
#channel中event的数量
bigdata.channels.c1.capacity = 1000
#声明sink具体的类型和对应的一些配置
bigdata.sinks.k1.type = logger
#声明source,sink和channel之间的关系
bigdata.sources.r1.channels = c1
#一个sink只能对应一个channel,一个channel可以对应多个sink
bigdata.sinks.k1.channel = c1
【注意】: ops01已经在/etc/hosts文件中作了IP解析 11.8.37.50 ops01
启动agent模拟传输
# 启动agent
wangting@ops01:/opt/module/flume >cd /opt/module/flume
wangting@ops01:/opt/module/flume >flume-ng agent --name bigdata --conf conf/ --conf-file datas/netcatsource_loggersink.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata --conf-file datas/netcatsource_loggersink.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-22 16:51:44,314 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2021-04-22 16:51:44,320 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:138)] Reloading configuration file:datas/netcatsource_loggersink.conf
2021-04-22 16:51:44,326 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,327 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,328 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-22 16:51:44,329 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1117)] Added sinks: k1 Agent: bigdata
2021-04-22 16:51:44,329 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet(FlumeConfiguration.java:623)] Agent configuration for 'bigdata' has no configfilters.
2021-04-22 16:51:44,349 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:163)] Post-validation flume configuration contains configuration for agents: [bigdata]
2021-04-22 16:51:44,349 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:151)] Creating channels
2021-04-22 16:51:44,356 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c1 type memory
2021-04-22 16:51:44,363 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:205)] Created channel c1
2021-04-22 16:51:44,367 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type netcat
2021-04-22 16:51:44,374 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger
2021-04-22 16:51:44,377 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:120)] Channel c1 connected to [r1, k1]
2021-04-22 16:51:44,380 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:162)] Starting new configuration:{
sourceRunners:{
r1=EventDrivenSourceRunner: {
source:org.apache.flume.source.NetcatSource{
name:r1,state:IDLE} }} sinkRunners:{
k1=SinkRunner: {
policy:org.apache.flume.sink.DefaultSinkProcessor@42d87c9b counterGroup:{
name:null counters:{
} } }} channels:{
c1=org.apache.flume.channel.MemoryChannel{
name: c1}} }
2021-04-22 16:51:44,382 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:169)] Starting Channel c1
2021-04-22 16:51:44,442 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
2021-04-22 16:51:44,442 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c1 started
2021-04-22 16:51:44,442 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1
2021-04-22 16:51:44,443 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1
2021-04-22 16:51:44,443 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:155)] Source starting
2021-04-22 16:51:44,456 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/11.8.37.50:44444]
场景实验
另起一个会话窗口
# 查看44444端口服务状态
wangting@ops01:/home/wangting >netstat -tnlpu|grep 44444
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 11.8.37.50:44444 :::* LISTEN 53791/java
# 44444端口对应进程pid 53791 ,可以看到是flume的进程
wangting@ops01:/home/wangting >ll /proc/53791 | grep cwd
lrwxrwxrwx 1 wangting wangting 0 Apr 22 16:52 cwd -> /opt/module/flume
wangting@ops01:/home/wangting >
# 使用nc 向ops01(本机的ip解析向ops01)的44444端口发送数据,场景类似业务应用实时流数据推送
wangting@ops01:/opt/module/flume/datas >nc ops01 44444
wang
OK
ting
OK
666
OK
okokok
OK
test_sk
OK
控制台输出内容
# flume-ng agent启动的控制台会有新的输出内容
# Event: { headers:{} body: 77 61 6E 67 wang }
# Event: { headers:{} body: 74 69 6E 67 ting }
# Event: { headers:{} body: 36 36 36 666 }
# Event: { headers:{} body: 6F 6B 6F 6B 6F 6B okokok }
# Event: { headers:{} body: 74 65 73 74 5F 73 6B test_sk }
2021-04-22 17:08:22,500 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 wang }
2021-04-22 17:08:22,501 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 74 69 6E 67 ting }
2021-04-22 17:08:22,501 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 36 36 36 666 }
2021-04-22 17:08:24,966 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 6F 6B 6F 6B 6F 6B okokok }
2021-04-22 17:08:39,968 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 74 65 73 74 5F 73 6B test_sk }
结论:使用Flume监听一个端口,收集该端口数据,并打印到控制台,测试验证符合场景需求
配置服务日志
wangting@ops01:/opt/module/flume >cd /opt/module/flume/conf
# 以下几行配置更改
wangting@ops01:/opt/module/flume/conf >vim log4j.properties
#flume.root.logger=DEBUG,LOGFILE
flume.root.logger=INFO,LOGFILE
flume.log.dir=/opt/module/flume/logs
flume.log.file=flume.log
wangting@ops01:/opt/module/flume/conf >cd ..
wangting@ops01:/opt/module/flume >mkdir logs
wangting@ops01:/opt/module/flume >touch logs/flume.log
wangting@ops01:/opt/module/flume >flume-ng agent --name bigdata --conf conf/ --conf-file datas/netcatsource_loggersink.conf
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata --conf-file datas/netcatsource_loggersink.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
另起一个会话
wangting@ops01:/opt/module/flume/ >
wangting@ops01:/opt/module/flume/ >nc ops01 44444
aaa
OK
bbb
OK
ccc
OK
结束agent并查看日志文件
wangting@ops01:/opt/module/flume/logs >cat flume.log
22 Apr 2021 18:10:53,011 INFO [lifecycleSupervisor-1-0] (org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start:62) - Configuration provider starting
22 Apr 2021 18:10:53,017 INFO [conf-file-poller-0] (org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run:138) - Reloading configuration file:datas/netcatsource_loggersink.conf
22 Apr 2021 18:10:53,024 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,025 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,025 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:k1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:c1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:k1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:c1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,026 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig:1203) - Processing:r1
22 Apr 2021 18:10:53,027 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty:1117) - Added sinks: k1 Agent: bigdata
22 Apr 2021 18:10:53,027 WARN [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet:623) - Agent configuration for 'bigdata' has no configfilters.
22 Apr 2021 18:10:53,048 INFO [conf-file-poller-0] (org.apache.flume.conf.FlumeConfiguration.validateConfiguration:163) - Post-validation flume configuration contains configuration for agents: [bigdata]
22 Apr 2021 18:10:53,048 INFO [conf-file-poller-0] (org.apache.flume.node.AbstractConfigurationProvider.loadChannels:151) - Creating channels
22 Apr 2021 18:10:53,056 INFO [conf-file-poller-0] (org.apache.flume.channel.DefaultChannelFactory.create:42) - Creating instance of channel c1 type memory
22 Apr 2021 18:10:53,061 INFO [conf-file-poller-0] (org.apache.flume.node.AbstractConfigurationProvider.loadChannels:205) - Created channel c1
22 Apr 2021 18:10:53,064 INFO [conf-file-poller-0] (org.apache.flume.source.DefaultSourceFactory.create:41) - Creating instance of source r1, type netcat
22 Apr 2021 18:10:53,071 INFO [conf-file-poller-0] (org.apache.flume.sink.DefaultSinkFactory.create:42) - Creating instance of sink: k1, type: logger
22 Apr 2021 18:10:53,074 INFO [conf-file-poller-0] (org.apache.flume.node.AbstractConfigurationProvider.getConfiguration:120) - Channel c1 connected to [r1, k1]
22 Apr 2021 18:10:53,078 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:162) - Starting new configuration:{
sourceRunners:{
r1=EventDrivenSourceRunner: {
source:org.apache.flume.source.NetcatSource{
name:r1,state:IDLE} }} sinkRunners:{
k1=SinkRunner: {
policy:org.apache.flume.sink.DefaultSinkProcessor@56079908 counterGroup:{
name:null counters:{
} } }} channels:{
c1=org.apache.flume.channel.MemoryChannel{
name: c1}} }
22 Apr 2021 18:10:53,080 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:169) - Starting Channel c1
22 Apr 2021 18:10:53,134 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.register:119) - Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
22 Apr 2021 18:10:53,135 INFO [lifecycleSupervisor-1-0] (org.apache.flume.instrumentation.MonitoredCounterGroup.start:95) - Component type: CHANNEL, name: c1 started
22 Apr 2021 18:10:53,135 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:196) - Starting Sink k1
22 Apr 2021 18:10:53,135 INFO [conf-file-poller-0] (org.apache.flume.node.Application.startAllComponents:207) - Starting Source r1
22 Apr 2021 18:10:53,136 INFO [lifecycleSupervisor-1-0] (org.apache.flume.source.NetcatSource.start:155) - Source starting
22 Apr 2021 18:10:53,146 INFO [lifecycleSupervisor-1-0] (org.apache.flume.source.NetcatSource.start:166) - Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/11.8.37.50:44444]
22 Apr 2021 18:11:03,355 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) - Event: {
headers:{
} body: 61 61 61 aaa }
22 Apr 2021 18:11:10,021 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) - Event: {
headers:{
} body: 62 62 62 bbb }
22 Apr 2021 18:11:11,101 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.LoggerSink.process:95) - Event: {
headers:{
} body: 63 63 63 ccc }
22 Apr 2021 18:11:15,901 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:125) - Shutting down configuration: {
sourceRunners:{
r1=EventDrivenSourceRunner: {
source:org.apache.flume.source.NetcatSource{
name:r1,state:START} }} sinkRunners:{
k1=SinkRunner: {
policy:org.apache.flume.sink.DefaultSinkProcessor@56079908 counterGroup:{
name:null counters:{
runner.backoffs.consecutive=1, runner.backoffs=4} } }} channels:{
c1=org.apache.flume.channel.MemoryChannel{
name: c1}} }
22 Apr 2021 18:11:15,902 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:129) - Stopping Source r1
22 Apr 2021 18:11:15,902 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.unsupervise:169) - Stopping component: EventDrivenSourceRunner: {
source:org.apache.flume.source.NetcatSource{
name:r1,state:START} }
22 Apr 2021 18:11:15,902 INFO [agent-shutdown-hook] (org.apache.flume.source.NetcatSource.stop:197) - Source stopping
22 Apr 2021 18:11:16,403 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:139) - Stopping Sink k1
22 Apr 2021 18:11:16,404 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.unsupervise:169) - Stopping component: SinkRunner: {
policy:org.apache.flume.sink.DefaultSinkProcessor@56079908 counterGroup:{
name:null counters:{
runner.backoffs.consecutive=1, runner.backoffs=4} } }
22 Apr 2021 18:11:16,404 INFO [agent-shutdown-hook] (org.apache.flume.node.Application.stopAllComponents:149) - Stopping Channel c1
22 Apr 2021 18:11:16,404 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.unsupervise:169) - Stopping component: org.apache.flume.channel.MemoryChannel{
name: c1}
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:149) - Component type: CHANNEL, name: c1 stopped
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:155) - Shutdown Metric for type: CHANNEL, name: c1. channel.start.time == 1619086253135
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:161) - Shutdown Metric for type: CHANNEL, name: c1. channel.stop.time == 1619086276405
22 Apr 2021 18:11:16,405 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.capacity == 1000
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.current.size == 0
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.put.attempt == 3
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.put.success == 3
22 Apr 2021 18:11:16,406 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.take.attempt == 8
22 Apr 2021 18:11:16,407 INFO [agent-shutdown-hook] (org.apache.flume.instrumentation.MonitoredCounterGroup.stop:177) - Shutdown Metric for type: CHANNEL, name: c1. channel.event.take.success == 3
22 Apr 2021 18:11:16,407 INFO [agent-shutdown-hook] (org.apache.flume.lifecycle.LifecycleSupervisor.stop:78) - Stopping lifecycle supervisor 12
22 Apr 2021 18:11:16,411 INFO [agent-shutdown-hook] (org.apache.flume.node.PollingPropertiesFileConfigurationProvider.stop:84) - Configuration provider stopping
Flume使用案例2
场景:实时监控单个追加文件
背景需求:
实时监控应用Hive日志,当Hive日志中有新内容时,同步上传到HDFS中
- 创建符合条件的flume配置文件
- 执行flume-ng配置文件,开启监控
- 开启Hive,查看Hive日志文件路径 /opt/module/hive/logs/hiveServer2.log,用于监控
- 查看验证HDFS上数据
【注意】: 测试默认已经具备了Hadoop集群部署以及hive服务等环境条件;
准备工作,编写配置
在/opt/module/flume/datas目录下编写配置文件,flume-file-hdfs.conf
wangting@ops01:/opt/module/flume/datas >vim flume-file-hdfs.conf
# Name the components on this agent
bigdata.sources = r2
bigdata.sinks = k2
bigdata.channels = c2
# Describe/configure the source
bigdata.sources.r2.type = exec
# 注意路径和日志名根据实际情况配置
bigdata.sources.r2.command = tail -F /opt/module/hive/logs/hiveServer2.log
bigdata.sources.r2.shell = /bin/bash -c
# Describe the sink
bigdata.sinks.k2.type = hdfs
# 注意hdfs根据真实情况配置
bigdata.sinks.k2.hdfs.path = hdfs://ops01:8020/flume/%Y%m%d/%H
#上传文件的前缀
bigdata.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
bigdata.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
bigdata.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
bigdata.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
bigdata.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
bigdata.sinks.k2.hdfs.batchSize = 100
#设置文件类型,可支持压缩
bigdata.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
bigdata.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
bigdata.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
bigdata.sinks.k2.hdfs.rollCount = 0
# Use a channel which buffers events in memory
bigdata.channels.c2.type = memory
bigdata.channels.c2.capacity = 1000
bigdata.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata.sources.r2.channels = c2
bigdata.sinks.k2.channel = c2
启动agent
切入到/opt/module/flume应用目录下,启动agent
wangting@ops01:/opt/module/flume >flume-ng agent --name bigdata --conf datas/ --conf-file datas/flume-file-hdfs.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/datas:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata --conf-file datas/flume-file-hdfs.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-23 11:18:31,268 INFO [lifecycleSupervisor-1-0] node.PollingPropertiesFileConfigurationProvider (PollingPropertiesFileConfigurationProvider.java:start(62)) - Configuration provider starting
2021-04-23 11:18:31,275 INFO [conf-file-poller-0] node.PollingPropertiesFileConfigurationProvider (PollingPropertiesFileConfigurationProvider.java:run(138)) - Reloading configuration file:datas/flume-file-hdfs.conf
2021-04-23 11:18:31,282 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:c2
2021-04-23 11:18:31,283 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:r2
2021-04-23 11:18:31,283 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:r2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addProperty(1117)) - Added sinks: k2 Agent: bigdata
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:c2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,284 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:c2
2021-04-23 11:18:31,288 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,288 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:addComponentConfig(1203)) - Processing:k2
2021-04-23 11:18:31,288 WARN [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:validateConfigFilterSet(623)) - Agent configuration for 'bigdata' has no configfilters.
2021-04-23 11:18:31,309 INFO [conf-file-poller-0] conf.FlumeConfiguration (FlumeConfiguration.java:validateConfiguration(163)) - Post-validation flume configuration contains configuration for agents: [bigdata]
2021-04-23 11:18:31,310 INFO [conf-file-poller-0] node.AbstractConfigurationProvider (AbstractConfigurationProvider.java:loadChannels(151)) - Creating channels
2021-04-23 11:18:31,317 INFO [conf-file-poller-0] channel.DefaultChannelFactory (DefaultChannelFactory.java:create(42)) - Creating instance of channel c2 type memory
2021-04-23 11:18:31,324 INFO [conf-file-poller-0] node.AbstractConfigurationProvider (AbstractConfigurationProvider.java:loadChannels(205)) - Created channel c2
2021-04-23 11:18:31,326 INFO [conf-file-poller-0] source.DefaultSourceFactory (DefaultSourceFactory.java:create(41)) - Creating instance of source r2, type exec
2021-04-23 11:18:31,333 INFO [conf-file-poller-0] sink.DefaultSinkFactory (DefaultSinkFactory.java:create(42)) - Creating instance of sink: k2, type: hdfs
2021-04-23 11:18:31,343 INFO [conf-file-poller-0] node.AbstractConfigurationProvider (AbstractConfigurationProvider.java:getConfiguration(120)) - Channel c2 connected to [r2, k2]
2021-04-23 11:18:31,346 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(162)) - Starting new configuration:{
sourceRunners:{
r2=EventDrivenSourceRunner: {
source:org.apache.flume.source.ExecSource{
name:r2,state:IDLE} }} sinkRunners:{
k2=SinkRunner: {
policy:org.apache.flume.sink.DefaultSinkProcessor@3a74bd67 counterGroup:{
name:null counters:{
} } }} channels:{
c2=org.apache.flume.channel.MemoryChannel{
name: c2}} }
2021-04-23 11:18:31,348 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(169)) - Starting Channel c2
2021-04-23 11:18:31,406 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:register(119)) - Monitored counter group for type: CHANNEL, name: c2: Successfully registered new MBean.
2021-04-23 11:18:31,406 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:start(95)) - Component type: CHANNEL, name: c2 started
2021-04-23 11:18:31,406 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(196)) - Starting Sink k2
2021-04-23 11:18:31,407 INFO [conf-file-poller-0] node.Application (Application.java:startAllComponents(207)) - Starting Source r2
2021-04-23 11:18:31,408 INFO [lifecycleSupervisor-1-1] source.ExecSource (ExecSource.java:start(170)) - Exec source starting with command: tail -F /opt/module/hive/logs/hiveServer2.log
2021-04-23 11:18:31,408 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:register(119)) - Monitored counter group for type: SINK, name: k2: Successfully registered new MBean.
2021-04-23 11:18:31,408 INFO [lifecycleSupervisor-1-0] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:start(95)) - Component type: SINK, name: k2 started
2021-04-23 11:18:31,409 INFO [lifecycleSupervisor-1-1] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:register(119)) - Monitored counter group for type: SOURCE, name: r2: Successfully registered new MBean.
2021-04-23 11:18:31,409 INFO [lifecycleSupervisor-1-1] instrumentation.MonitoredCounterGroup (MonitoredCounterGroup.java:start(95)) - Component type: SOURCE, name: r2 started
2021-04-23 11:18:35,425 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.HDFSDataStream (HDFSDataStream.java:configure(57)) - Serializer = TEXT, UseRawLocalFileSystem = false
2021-04-23 11:18:35,536 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.BucketWriter (BucketWriter.java:open(246)) - Creating hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426.tmp
2021-04-23 11:18:35,873 INFO [hdfs-k2-call-runner-0] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-23 11:18:39,736 INFO [Thread-9] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-04-23 11:19:36,698 INFO [hdfs-k2-roll-timer-0] hdfs.HDFSEventSink (HDFSEventSink.java:run(393)) - Writer callback called.
2021-04-23 11:19:36,698 INFO [hdfs-k2-roll-timer-0] hdfs.BucketWriter (BucketWriter.java:doClose(438)) - Closing hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426.tmp
2021-04-23 11:19:36,722 INFO [hdfs-k2-call-runner-8] hdfs.BucketWriter (BucketWriter.java:call(681)) - Renaming hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426.tmp to hdfs://ops01:8020/flume/20210423/11/logs-.1619147915426
2021-04-23 11:20:03,947 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.HDFSDataStream (HDFSDataStream.java:configure(57)) - Serializer = TEXT, UseRawLocalFileSystem = false
2021-04-23 11:20:03,963 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] hdfs.BucketWriter (BucketWriter.java:open(246)) - Creating hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947.tmp
2021-04-23 11:20:06,991 INFO [Thread-15] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-04-23 11:21:03,984 INFO [hdfs-k2-roll-timer-0] hdfs.HDFSEventSink (HDFSEventSink.java:run(393)) - Writer callback called.
2021-04-23 11:21:03,985 INFO [hdfs-k2-roll-timer-0] hdfs.BucketWriter (BucketWriter.java:doClose(438)) - Closing hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947.tmp
2021-04-23 11:21:03,998 INFO [hdfs-k2-call-runner-2] hdfs.BucketWriter (BucketWriter.java:call(681)) - Renaming hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947.tmp to hdfs://ops01:8020/flume/20210423/11/logs-.1619148003947
【注意】: 环境默认已经开启了hdfs、hive、yarn等集群服务;这里不再细说各组件的部署搭建
场景实验
登录Hive交互命令行
# 登录hive
wangting@ops01:/opt/module/hive >beeline -u jdbc:hive2://ops01:10000 -n wangting
# 执行个正确的命令
0: jdbc:hive2://ops01:10000> show tables;
INFO : Compiling command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4): show tables
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4); Time taken: 0.02 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=wangting_20210423111858_a9428a9d-ee27-48b7-8235-3b0ed75982b4); Time taken: 0.004 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------------------------+
| tab_name |
+-------------------------------------+
| dept |
| emp |
| f_dmcp_n013_judicative_doc_content |
| stu_partition |
| test |
| test2 |
+-------------------------------------+
6 rows selected (0.037 seconds)
# 执行个错误命令,抛出错误cannot recognize input near 'show' 'tablesssssss'
0: jdbc:hive2://ops01:10000> show tablesssssss;
Error: Error while compiling statement: FAILED: ParseException line 1:5 cannot recognize input near 'show' 'tablesssssss' '' in ddl statement (state=42000,code=40000)
# 再执行一个命令案例
0: jdbc:hive2://ops01:10000> select count(*) from emp;
INFO : Compiling command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea): select count(*) from emp
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea); Time taken: 0.119 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea): select count(*) from emp
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1615531413182_0098
INFO : Executing with tokens: []
INFO : The url to track the job: http://ops02:8088/proxy/application_1615531413182_0098/
INFO : Starting Job = job_1615531413182_0098, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0098/
INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0098
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2021-04-23 11:20:12,466 Stage-1 map = 0%, reduce = 0%
INFO : 2021-04-23 11:20:20,663 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.53 sec
INFO : 2021-04-23 11:20:28,849 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.4 sec
INFO : MapReduce Total cumulative CPU time: 5 seconds 400 msec
INFO : Ended Job = job_1615531413182_0098
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.4 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS
INFO : Total MapReduce CPU Time Spent: 5 seconds 400 msec
INFO : Completed executing command(queryId=wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea); Time taken: 25.956 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------+
| _c0 |
+------+
| 14 |
+------+
1 row selected (26.095 seconds)
# # 同样再执行错误命令,抛出错误Table not found 'empaaaaa'
0: jdbc:hive2://ops01:10000> select count(*) from empaaaaa;
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'empaaaaa' (state=42S02,code=10001)
0: jdbc:hive2://ops01:10000>
# 退出ctrl+c
如果以上操作没有出现问题,那么可以查看一下hdfs上是否有预期的log文件,查看hdfs来验证
wangting@ops01:/home/wangting >
# 查看hdfs根目录下是否存在flume目录
wangting@ops01:/home/wangting >hdfs dfs -ls /
2021-04-23 11:24:55,647 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 9 items
drwxr-xr-x - wangting supergroup 0 2021-03-17 11:44 /20210317
drwxr-xr-x - wangting supergroup 0 2021-03-19 10:51 /20210319
drwxr-xr-x - wangting supergroup 0 2021-04-23 11:18 /flume
-rw-r--r-- 3 wangting supergroup 338075860 2021-03-12 11:50 /hadoop-3.1.3.tar.gz
drwxr-xr-x - wangting supergroup 0 2021-04-04 11:07 /test.db
drwxr-xr-x - wangting supergroup 0 2021-03-19 11:14 /testgetmerge
drwxr-xr-x - wangting supergroup 0 2021-04-10 16:23 /tez
drwx------ - wangting supergroup 0 2021-04-02 15:14 /tmp
drwxr-xr-x - wangting supergroup 0 2021-04-02 15:25 /user
# 查看/flume目录下是否按照flume-file-hdfs.conf配置中定义的有日期目录和小时目录
wangting@ops01:/home/wangting >hdfs dfs -ls /flume
2021-04-23 11:25:05,199 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 1 items
drwxr-xr-x - wangting supergroup 0 2021-04-23 11:18 /flume/20210423
wangting@ops01:/home/wangting >hdfs dfs -ls /flume/20210423/
2021-04-23 11:25:14,685 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 1 items
drwxr-xr-x - wangting supergroup 0 2021-04-23 11:21 /flume/20210423/11
wangting@ops01:/home/wangting >hdfs dfs -ls /flume/20210423/11
2021-04-23 11:25:19,814 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 2 items
-rw-r--r-- 3 wangting supergroup 4949 2021-04-23 11:19 /flume/20210423/11/logs-.1619147915426
-rw-r--r-- 3 wangting supergroup 1297 2021-04-23 11:21 /flume/20210423/11/logs-.1619148003947
# 查看小时目录11时下的log文件logs-.1619147915426,可以看到有cannot recognize input near 'show' 'tablesssssss'的相关报错
wangting@ops01:/home/wangting >hdfs dfs -cat /flume/20210423/11/logs-.1619147915426
2021-04-23 11:25:37,024 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-23 11:25:37,749 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1542)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
FAILED: ParseException line 1:5 cannot recognize input near 'show' 'tablessss' '' in ddl statement
OK
OK
NoViableAltException(24@[917:1: ddlStatement : ( createDatabaseStatement | switchDatabaseStatement | dropDatabaseStatement | createTableStatement | dropTableStatement | truncateTableStatement | alterStatement | descStatement | showStatement | metastoreCheck | createViewStatement | createMaterializedViewStatement | dropViewStatement | dropMaterializedViewStatement | createFunctionStatement | createMacroStatement | dropFunctionStatement | reloadFunctionStatement | dropMacroStatement | analyzeStatement | lockStatement | unlockStatement | lockDatabase | unlockDatabase | createRoleStatement | dropRoleStatement | ( grantPrivileges )=> grantPrivileges | ( revokePrivileges )=> revokePrivileges | showGrants | showRoleGrants | showRolePrincipals | showRoles | grantRole | revokeRole | setRole | showCurrentRole | abortTransactionStatement | killQueryStatement | resourcePlanDdlStatements );])
at org.antlr.runtime.DFA.noViableAlt(DFA.java:158)
at org.antlr.runtime.DFA.predict(DFA.java:144)
at org.apache.hadoop.hive.ql.parse.HiveParser.ddlStatement(HiveParser.java:4244)
at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:2494)
at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1420)
at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:220)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:74)
at org.apache.hadoop.hive.ql.parse.ParseUtils.parse(ParseUtils.java:67)
at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:616)
at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1826)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1773)
at org.apache.hadoop.hive.ql.Driver.compileAndRespond(Driver.java:1768)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.compileAndRespond(ReExecDriver.java:126)
at org.apache.hive.service.cli.operation.SQLOperation.prepare(SQLOperation.java:197)
at org.apache.hive.service.cli.operation.SQLOperation.runInternal(SQLOperation.java:260)
at org.apache.hive.service.cli.operation.Operation.run(Operation.java:247)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementInternal(HiveSessionImpl.java:541)
at org.apache.hive.service.cli.session.HiveSessionImpl.executeStatementAsync(HiveSessionImpl.java:527)
at sun.reflect.GeneratedMethodAccessor43.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:78)
at org.apache.hive.service.cli.session.HiveSessionProxy.access$000(HiveSessionProxy.java:36)
at org.apache.hive.service.cli.session.HiveSessionProxy$1.run(HiveSessionProxy.java:63)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hive.service.cli.session.HiveSessionProxy.invoke(HiveSessionProxy.java:59)
at com.sun.proxy.$Proxy37.executeStatementAsync(Unknown Source)
at org.apache.hive.service.cli.CLIService.executeStatementAsync(CLIService.java:312)
at org.apache.hive.service.cli.thrift.ThriftCLIService.ExecuteStatement(ThriftCLIService.java:562)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1557)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1542)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.hive.service.auth.TSetIpAddressProcessor.process(TSetIpAddressProcessor.java:56)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
FAILED: ParseException line 1:5 cannot recognize input near 'show' 'tablesssssss' '' in ddl statement
# 查看小时目录11时下的log文件logs-.1619148003947,可以看到有Table not found 'empaaaaa'的相关报错
wangting@ops01:/home/wangting >hdfs dfs -cat /flume/20210423/11/logs-.1619148003947
2021-04-23 11:25:50,566 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-23 11:25:51,293 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Query ID = wangting_20210423112003_794bd7fd-f4bc-4179-ad34-06e64aee66ea
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1615531413182_0098, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0098/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0098
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-04-23 11:20:12,466 Stage-1 map = 0%, reduce = 0%
2021-04-23 11:20:20,663 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.53 sec
2021-04-23 11:20:28,849 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.4 sec
MapReduce Total cumulative CPU time: 5 seconds 400 msec
Ended Job = job_1615531413182_0098
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.4 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 400 msec
OK
FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'empaaaaa'
结论:实时监控应用Hive日志,当Hive日志中有新内容时,内容同步上传到HDFS中,测试验证符合场景需求
Flume使用案例3
场景:实时监控目录下多个新文件
案例2单个文件采用exec,案例3多个文件采用spooldir
背景需求:
使用Flume监听服务器某个路径下整个目录的文件变化,并上传至HDFS
- 创建符合条件的flume配置文件
- 执行flume-ng配置文件,开启监控
- 向upload目录中添加文件,被监控的目录/opt/module/flume/upload/
- 查看验证HDFS上数据
- 查看/opt/module/flume/upload目录中上传的文件是否已经标记为.COMPLETED结尾;.tmp后缀结尾文件没有上传。
准备工作,编写配置
在/opt/module/flume/datas目录下编写配置文件,flume-dir-hdfs.conf
wangting@ops01:/opt/module/flume >ls
bin CHANGELOG conf datas DEVNOTES doap_Flume.rdf docs lib LICENSE logs NOTICE README.md RELEASE-NOTES tools
wangting@ops01:/opt/module/flume >mkdir upload
wangting@ops01:/opt/module/flume >cd datas/
wangting@ops01:/opt/module/flume/datas >ls
flume-file-hdfs.conf netcatsource_loggersink.conf
wangting@ops01:/opt/module/flume/datas >vim flume-dir-hdfs.conf
# source/channel/sink
bigdata.sources = r3
bigdata.sinks = k3
bigdata.channels = c3
# Describe/configure the source
bigdata.sources.r3.type = spooldir
bigdata.sources.r3.spoolDir = /opt/module/flume/upload
bigdata.sources.r3.fileSuffix = .COMPLETED
bigdata.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
bigdata.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
bigdata.sinks.k3.type = hdfs
bigdata.sinks.k3.hdfs.path = hdfs://ops01:8020/flume/upload/%Y%m%d/%H
#上传文件的前缀
bigdata.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
bigdata.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
bigdata.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
bigdata.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
bigdata.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
bigdata.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
bigdata.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
bigdata.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
bigdata.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
bigdata.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
bigdata.channels.c3.type = memory
bigdata.channels.c3.capacity = 1000
bigdata.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata.sources.r3.channels = c3
bigdata.sinks.k3.channel = c3
启动agent
wangting@ops01:/opt/module/flume >ll upload/
total 0
wangting@ops01:/opt/module/flume >flume-ng agent -c conf/ -n bigdata -f datas/flume-dir-hdfs.conf
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application -n bigdata -f datas/flume-dir-hdfs.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
【注意1】
flume-ng agent -c conf/ -n bigdata -f datas/flume-dir-hdfs.conf
-c 是 --conf 缩写
-f 是 --conf-file 缩写
-n 是 --name 缩写
相当于flume-ng agent --conf conf/ --name bigdata --conf-file datas/flume-dir-hdfs.conf
【注意2】
这里监控的是dir,维度是目录级别的,并且是新文件;也就是监控被监控目录下的文件新增变化;所以在使用Spooling Directory Source时,不要在监控目录中upload创建后又持续修改文件;上传完成的文件会以.COMPLETED结尾;被监控文件夹每500毫秒扫描一次文件变动。
场景实验
wangting@ops01:/home/wangting >cd /opt/module/flume/upload/
# 当前目录为空
wangting@ops01:/opt/module/flume/upload >ll
total 0
# 模拟一个.txt结尾文件
wangting@ops01:/opt/module/flume/upload >touch wang.txt
# 模拟一个.tmp结尾文件
wangting@ops01:/opt/module/flume/upload >touch ting.tmp
# # 模拟一个.log结尾文件
wangting@ops01:/opt/module/flume/upload >touch ting.log
# 模拟一个带.tmp但其它内容结尾的文件
wangting@ops01:/opt/module/flume/upload >touch bigdata.tmp_bak
# 创建完毕后,ls -l 查看验证
# 配置文件中定义了忽略所有以.tmp结尾的文件,不上传 配置bigdata.sources.r3.ignorePattern = ([^ ]*\.tmp)
wangting@ops01:/opt/module/flume/upload >ll
total 0
-rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 bigdata.tmp_bak.COMPLETED
-rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 ting.log.COMPLETED
-rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 ting.tmp
-rw-rw-r-- 1 wangting wangting 0 Apr 24 14:11 wang.txt.COMPLETED
# 所以结果是.tmp结尾的不读取,其它读取;查看日志
wangting@ops01:/opt/module/flume/upload >cd /opt/module/flume/logs/
wangting@ops01:/opt/module/flume/logs >ll
total 20
-rw-rw-r-- 1 wangting wangting 19333 Apr 24 14:12 flume.log
wangting@ops01:/opt/module/flume/logs >tail -f flume.log
24 Apr 2021 14:11:05,980 INFO [pool-5-thread-1] (org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile:497) - Preparing to move file /opt/module/flume/upload/wang.txt to /opt/module/flume/upload/wang.txt.COMPLETED
24 Apr 2021 14:11:07,984 INFO [pool-5-thread-1] (org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents:384) - Last read took us just up to a file boundary. Rolling to the next file, if there is one.
24 Apr 2021 14:11:07,985 INFO [pool-5-thread-1] (org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile:497) - Preparing to move file /opt/module/flume/upload/bigdata.tmp_bak to /opt/module/flume/upload/bigdata.tmp_bak.COMPLETED
24 Apr 2021 14:11:10,677 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.HDFSDataStream.configure:57) - Serializer = TEXT, UseRawLocalFileSystem = false
24 Apr 2021 14:11:10,860 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.BucketWriter.open:246) - Creating hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678.tmp
24 Apr 2021 14:11:11,200 INFO [hdfs-k3-call-runner-0] (org.apache.hadoop.conf.Configuration.logDeprecation:1395) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
24 Apr 2021 14:11:15,019 INFO [Thread-8] (org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend:239) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
24 Apr 2021 14:12:11,989 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.HDFSEventSink$1.run:393) - Writer callback called.
24 Apr 2021 14:12:11,990 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.BucketWriter.doClose:438) - Closing hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678.tmp
24 Apr 2021 14:12:12,015 INFO [hdfs-k3-call-runner-6] (org.apache.flume.sink.hdfs.BucketWriter$7.call:681) - Renaming hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678.tmp to hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678
# 获取到hdfs相关内容信息hdfs://ops01:8020/flume/upload/20210424/14/upload-.1619244670678
查看hdfs信息
wangting@ops01:/opt/module/flume/upload >hdfs dfs -ls /flume/upload/20210424/
2021-04-24 14:13:20,594 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 1 items
drwxr-xr-x - wangting supergroup 0 2021-04-24 14:12 /flume/upload/20210424/14
wangting@ops01:/opt/module/flume/upload >hdfs dfs -ls /flume/upload/20210424/14
2021-04-24 14:13:27,463 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 1 items
-rw-r--r-- 3 wangting supergroup 3 2021-04-24 14:12 /flume/upload/20210424/14/upload-.1619244670678
wangting@ops01:/opt/module/flume/upload >
Flume使用案例4
场景:实时监控目录下的多个追加文件
背景需求
- 创建符合条件的flume配置文件
- 执行配置文件,开启agent监控目录下文件状态变化\
- 向监控文件追加内容
echo wang >> download/file1.txt
echo ting >> download/file2.txt - 被监控文件路径 /opt/module/flume/download
- 查看HDFS上数据
准备工作,编写配置
在/opt/module/flume/datas目录下编写配置文件,flume-taildir-hdfs.conf
wangting@ops01:/opt/module/flume >mkdir download
wangting@ops01:/opt/module/flume >cd datas/
wangting@ops01:/opt/module/flume/datas >ll
total 12
-rw-rw-r-- 1 wangting wangting 1533 Apr 24 14:05 flume-dir-hdfs.conf
-rw-rw-r-- 1 wangting wangting 1405 Apr 23 11:13 flume-file-hdfs.conf
-rw-rw-r-- 1 wangting wangting 787 Apr 17 15:58 netcatsource_loggersink.conf
wangting@ops01:/opt/module/flume/datas >vim flume-taildir-hdfs.conf
bigdata.sources = r3
bigdata.sinks = k3
bigdata.channels = c3
# Describe/configure the source
bigdata.sources.r3.type = TAILDIR
bigdata.sources.r3.positionFile = /opt/module/flume/tail_dir.json
bigdata.sources.r3.filegroups = f1 f2
bigdata.sources.r3.filegroups.f1 = /opt/module/flume/download/.*file.*
bigdata.sources.r3.filegroups.f2 = /opt/module/flume/download/.*log.*
# Describe the sink
bigdata.sinks.k3.type = hdfs
bigdata.sinks.k3.hdfs.path = hdfs://ops01:8020/flume/download/%Y%m%d/%H
#上传文件的前缀
bigdata.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
bigdata.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
bigdata.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
bigdata.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
bigdata.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
bigdata.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
bigdata.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
bigdata.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
bigdata.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
bigdata.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memorytail
bigdata.channels.c3.type = memory
bigdata.channels.c3.capacity = 1000
bigdata.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata.sources.r3.channels = c3
bigdata.sinks.k3.channel = c3
启动agent
wangting@ops01:/opt/module/flume >flume-ng agent -c conf/ -n bigdata -f datas/flume-taildir-hdfs.conf
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application -n bigdata -f datas/flume-taildir-hdfs.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
场景实验
wangting@ops01:/opt/module/flume >ll
total 188
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 bin
-rw-rw-r-- 1 wangting wangting 85602 Nov 29 2018 CHANGELOG
drwxr-xr-x 2 wangting wangting 4096 Apr 22 18:18 conf
drwxrwxr-x 2 wangting wangting 4096 Apr 24 14:59 datas
-rw-r--r-- 1 wangting wangting 5681 Nov 16 2017 DEVNOTES
-rw-r--r-- 1 wangting wangting 2873 Nov 16 2017 doap_Flume.rdf
drwxrwxr-x 12 wangting wangting 4096 Dec 18 2018 docs
drwxrwxr-x 2 wangting wangting 4096 Apr 24 14:56 download
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:15 lib
-rw-rw-r-- 1 wangting wangting 43405 Dec 10 2018 LICENSE
drwxrwxr-x 2 wangting wangting 4096 Apr 22 18:11 logs
-rw-r--r-- 1 wangting wangting 249 Nov 29 2018 NOTICE
-rw-r--r-- 1 wangting wangting 2483 Nov 16 2017 README.md
-rw-rw-r-- 1 wangting wangting 1958 Dec 10 2018 RELEASE-NOTES
-rw-rw-r-- 1 wangting wangting 0 Apr 24 15:02 tail_dir.json
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 tools
drwxrwxr-x 3 wangting wangting 4096 Apr 24 14:11 upload
wangting@ops01:/opt/module/flume >pwd
/opt/module/flume
wangting@ops01:/opt/module/flume >echo wang >> download/file1.txt
wangting@ops01:/opt/module/flume >echo ting >> download/file2.txt
wangting@ops01:/opt/module/flume >ll download/
total 8
-rw-rw-r-- 1 wangting wangting 5 Apr 24 15:02 file1.txt
-rw-rw-r-- 1 wangting wangting 5 Apr 24 15:02 file2.txt
wangting@ops01:/opt/module/flume >ll
total 192
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 bin
-rw-rw-r-- 1 wangting wangting 85602 Nov 29 2018 CHANGELOG
drwxr-xr-x 2 wangting wangting 4096 Apr 22 18:18 conf
drwxrwxr-x 2 wangting wangting 4096 Apr 24 14:59 datas
-rw-r--r-- 1 wangting wangting 5681 Nov 16 2017 DEVNOTES
-rw-r--r-- 1 wangting wangting 2873 Nov 16 2017 doap_Flume.rdf
drwxrwxr-x 12 wangting wangting 4096 Dec 18 2018 docs
drwxrwxr-x 2 wangting wangting 4096 Apr 24 15:02 download
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:15 lib
-rw-rw-r-- 1 wangting wangting 43405 Dec 10 2018 LICENSE
drwxrwxr-x 2 wangting wangting 4096 Apr 22 18:11 logs
-rw-r--r-- 1 wangting wangting 249 Nov 29 2018 NOTICE
-rw-r--r-- 1 wangting wangting 2483 Nov 16 2017 README.md
-rw-rw-r-- 1 wangting wangting 1958 Dec 10 2018 RELEASE-NOTES
-rw-rw-r-- 1 wangting wangting 145 Apr 24 15:03 tail_dir.json
drwxr-xr-x 2 wangting wangting 4096 Apr 17 14:14 tools
drwxrwxr-x 3 wangting wangting 4096 Apr 24 14:11 upload
wangting@ops01:/opt/module/flume >cat tail_dir.json
[{
"inode":4203350,"pos":5,"file":"/opt/module/flume/download/file1.txt"},{
"inode":4203351,"pos":5,"file":"/opt/module/flume/download/file2.txt"}]
wangting@ops01:/opt/module/flume >echo wang222 >> download/file1.txt
wangting@ops01:/opt/module/flume >echo ting222 >> download/file2.txt
wangting@ops01:/opt/module/flume >
wangting@ops01:/opt/module/flume >cat tail_dir.json
[{
"inode":4203350,"pos":13,"file":"/opt/module/flume/download/file1.txt"},{
"inode":4203351,"pos":13,"file":"/opt/module/flume/download/file2.txt"}]
wangting@ops01:/opt/module/flume >
# 注意pos的值变化,这里相当于记录位置的指针
# 查看日志信息
wangting@ops01:/opt/module/flume >
wangting@ops01:/opt/module/flume >tail -f /opt/module/flume/logs/flume.log
24 Apr 2021 15:03:00,395 INFO [Thread-9] (org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend:239) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
24 Apr 2021 15:03:57,359 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.HDFSEventSink$1.run:393) - Writer callback called.
24 Apr 2021 15:03:57,360 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.BucketWriter.doClose:438) - Closing hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247776033.tmp
24 Apr 2021 15:03:57,381 INFO [hdfs-k3-call-runner-5] (org.apache.flume.sink.hdfs.BucketWriter$7.call:681) - Renaming hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247776033.tmp to hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247776033
24 Apr 2021 15:04:26,502 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.HDFSDataStream.configure:57) - Serializer = TEXT, UseRawLocalFileSystem = false
24 Apr 2021 15:04:26,515 INFO [SinkRunner-PollingRunner-DefaultSinkProcessor] (org.apache.flume.sink.hdfs.BucketWriter.open:246) - Creating hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503.tmp
24 Apr 2021 15:04:29,545 INFO [Thread-15] (org.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient.checkTrustAndSend:239) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
24 Apr 2021 15:05:26,536 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.HDFSEventSink$1.run:393) - Writer callback called.
24 Apr 2021 15:05:26,536 INFO [hdfs-k3-roll-timer-0] (org.apache.flume.sink.hdfs.BucketWriter.doClose:438) - Closing hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503.tmp
24 Apr 2021 15:05:26,550 INFO [hdfs-k3-call-runner-2] (org.apache.flume.sink.hdfs.BucketWriter$7.call:681) - Renaming hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503.tmp to hdfs://ops01:8020/flume/download/20210424/15/upload-.1619247866503
# 查看hdfs信息
wangting@ops01:/opt/module/flume >hdfs dfs -ls /flume/download/20210424/15/
2021-04-24 15:07:19,138 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 2 items
-rw-r--r-- 3 wangting supergroup 10 2021-04-24 15:03 /flume/download/20210424/15/upload-.1619247776033
-rw-r--r-- 3 wangting supergroup 16 2021-04-24 15:05 /flume/download/20210424/15/upload-.1619247866503
wangting@ops01:/opt/module/flume >hdfs dfs -cat /flume/download/20210424/15/upload-.1619247776033
2021-04-24 15:07:37,749 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-24 15:07:38,472 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
wang
ting
wangting@ops01:/opt/module/flume >hdfs dfs -cat /flume/download/20210424/15/upload-.1619247866503
2021-04-24 15:07:51,807 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-24 15:07:52,533 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
wang222
ting222
【注意1】
Taildir Source维护了一个.json格式的position File,其会定期的往position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File的格式如下:
[{“inode”:4203350,“pos”:13,“file”:"/opt/module/flume/download/file1.txt"},
{“inode”:4203351,“pos”:13,“file”:"/opt/module/flume/download/file2.txt"}]
【注意2】
Linux中储存文件元数据的区域就叫做inode,每个inode都有一个号码,操作系统用inode号码来识别不同的文件,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。这样inode + pos 就可以定位到指针位置,再关联file的文件名
Flume进阶
Flume事务

Put事务流程
doPut:将批数据先写入临时缓冲区putList
doCommit:检查channel内存队列是否足够合并。
doRollback:channel内存队列空间不足,回滚数据
Take事务
doTake:将数据取到临时缓冲区takeList,并将数据发送到HDFS
doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列。
Flume Agent内部原理

重要组件:
ChannelSelector
ChannelSelector的作用就是选出Event将要被发往哪个Channel。其共有两种类型,分别是Replicating(复制)和Multiplexing(多路复用)。
ReplicatingSelector会将同一个Event发往所有的Channel,Multiplexing会根据相应的原则,将不同的Event发往不同的Channel。
SinkProcessor
SinkProcessor共有三种类型,分别是DefaultSinkProcessor、LoadBalancingSinkProcessor和FailoverSinkProcessor
DefaultSinkProcessor对应的是单个的Sink,LoadBalancingSinkProcessor和FailoverSinkProcessor对应的是Sink Group,LoadBalancingSinkProcessor可以实现负载均衡的功能,FailoverSinkProcessor可以错误恢复的功能。
Flume拓扑结构
简单串联
这种模式是将多个flume顺序连接起来了,从最初的source开始到最终sink传送的目的存储系统。此模式不建议桥接过多的flume数量, flume数量过多不仅会影响传输速率,而且一旦传输过程中某个节点flume宕机,会影响整个传输系统。

复制和多路复用
Flume支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel中,或者将不同数据分发到不同的channel中,sink可以选择传送到不同的目的地。

负载均衡和故障转移
Flume支持使用将多个sink逻辑上分到一个sink组,sink组配合不同的SinkProcessor可以实现负载均衡和错误恢复的功能。

聚合
这种模式是我们最常见的,也非常实用,日常web应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用flume的这种组合方式能很好的解决这一问题,每台服务器部署一个flume采集日志,传送到一个集中收集日志的flume,再由此flume上传到hdfs、hive、hbase等,进行日志分析。

Flume使用案例5
场景:复制和多路复用案例
背景需求
使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3负责输出到Local FileSystem,相当于有3个agent协作。

准备工作,编写配置
编写配置 /opt/module/flume/datas/05-flume-file-flume.conf
【注意】路径日志/opt/module/hive/logs/hiveServer2.log根据实际情况配置
wangting@ops01:/opt/module/flume/datas >vim 05-flume-file-flume.conf
# Name the components on this agent
bigdata01.sources = r1
bigdata01.sinks = k1 k2
bigdata01.channels = c1 c2
# 将数据流复制给所有channel
bigdata01.sources.r1.selector.type = replicating
# Describe/configure the source
bigdata01.sources.r1.type = exec
bigdata01.sources.r1.command = tail -F /opt/module/hive/logs/hiveServer2.log
bigdata01.sources.r1.shell = /bin/bash -c
# Describe the sink
# sink端的avro是一个数据发送者
bigdata01.sinks.k1.type = avro
bigdata01.sinks.k1.hostname = ops01
bigdata01.sinks.k1.port = 44441
bigdata01.sinks.k2.type = avro
bigdata01.sinks.k2.hostname = ops01
bigdata01.sinks.k2.port = 44442
# Describe the channel
bigdata01.channels.c1.type = memory
bigdata01.channels.c1.capacity = 1000
bigdata01.channels.c1.transactionCapacity = 100
bigdata01.channels.c2.type = memory
bigdata01.channels.c2.capacity = 1000
bigdata01.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata01.sources.r1.channels = c1 c2
bigdata01.sinks.k1.channel = c1
bigdata01.sinks.k2.channel = c2
编写配置 /opt/module/flume/datas/05-flume-flume-hdfs.conf
【注意】bigdata02.sources.r1.port = 44441需要和上面bigdata01.sinks.k1.port = 44441端口一致
# Name the components on this agent
bigdata02.sources = r1
bigdata02.sinks = k1
bigdata02.channels = c1
# Describe/configure the source
# source端的avro是一个数据接收服务
bigdata02.sources.r1.type = avro
bigdata02.sources.r1.bind = ops01
bigdata02.sources.r1.port = 44441
# Describe the sink
bigdata02.sinks.k1.type = hdfs
bigdata02.sinks.k1.hdfs.path = hdfs://ops01:8020/flume/%Y%m%d/%H
#上传文件的前缀
bigdata02.sinks.k1.hdfs.filePrefix = flume-
#是否按照时间滚动文件夹
bigdata02.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
bigdata02.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
bigdata02.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
bigdata02.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
bigdata02.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
bigdata02.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
bigdata02.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
bigdata02.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
bigdata02.sinks.k1.hdfs.rollCount = 0
# Describe the channel
bigdata02.channels.c1.type = memory
bigdata02.channels.c1.capacity = 1000
bigdata02.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata02.sources.r1.channels = c1
bigdata02.sinks.k1.channel = c1
编写配置 /opt/module/flume/datas/05-flume-flume-dir.conf
【注意】bigdata03.sources.r1.port = 44442 需要和上面bigdata01.sinks.k2.port = 44442端口一致
【注意】/opt/module/flume/job目录需要提前mkdir创建好,agent任务不会自动创建对应配置中的目录
# Name the components on this agent
bigdata03.sources = r1
bigdata03.sinks = k1
bigdata03.channels = c2
# Describe/configure the source
bigdata03.sources.r1.type = avro
bigdata03.sources.r1.bind = ops01
bigdata03.sources.r1.port = 44442
# Describe the sink
bigdata03.sinks.k1.type = file_roll
bigdata03.sinks.k1.sink.directory = /opt/module/flume/job
# Describe the channel
bigdata03.channels.c2.type = memory
bigdata03.channels.c2.capacity = 1000
bigdata03.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata03.sources.r1.channels = c2
bigdata03.sinks.k1.channel = c2
启动agent
【注意】需要启动多个agent,需要开多个会话窗,需要保持多个agent都在持续运行
agent-1
flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/05-flume-flume-dir.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/05-flume-flume-dir.conf
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata03 --conf-file datas/05-flume-flume-dir.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
agent-2
flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/05-flume-flume-hdfs.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/05-flume-flume-hdfs.conf
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata02 --conf-file datas/05-flume-flume-hdfs.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
agent-3
flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/05-flume-file-flume.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/05-flume-file-flume.conf
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata01 --conf-file datas/05-flume-file-flume.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
# 查看已创建配置
wangting@ops01:/opt/module/flume/datas >ll
total 28
-rw-rw-r-- 1 wangting wangting 1057 Apr 24 17:01 05-flume-file-flume.conf
-rw-rw-r-- 1 wangting wangting 609 Apr 24 17:03 05-flume-flume-dir.conf
-rw-rw-r-- 1 wangting wangting 1437 Apr 24 17:02 05-flume-flume-hdfs.conf
-rw-rw-r-- 1 wangting wangting 1533 Apr 24 14:05 flume-dir-hdfs.conf
-rw-rw-r-- 1 wangting wangting 1405 Apr 23 11:13 flume-file-hdfs.conf
-rw-rw-r-- 1 wangting wangting 1526 Apr 24 14:59 flume-taildir-hdfs.conf
-rw-rw-r-- 1 wangting wangting 787 Apr 17 15:58 netcatsource_loggersink.conf
# 查看/opt/module/flume/job目录是否创建
wangting@ops01:/opt/module/flume/datas >ll /opt/module/flume/job
total 0
场景实验
开启Hive进行操作,产生操作日志
# 进入Hive命令行
wangting@ops01:/opt/module/hive/conf >beeline -u jdbc:hive2://ops01:10000 -n wangting
Connecting to jdbc:hive2://ops01:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
# 随意查询一个表
0: jdbc:hive2://ops01:10000> select * from emp;
INFO : Compiling command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02): select * from emp
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:emp.empno, type:int, comment:null), FieldSchema(name:emp.ename, type:string, comment:null), FieldSchema(name:emp.job, type:string, comment:null), FieldSchema(name:emp.mgr, type:int, comment:null), FieldSchema(name:emp.hiredate, type:string, comment:null), FieldSchema(name:emp.sal, type:double, comment:null), FieldSchema(name:emp.comm, type:double, comment:null), FieldSchema(name:emp.deptno, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02); Time taken: 0.134 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02): select * from emp
INFO : Completed executing command(queryId=wangting_20210424170631_54655d42-8542-49fb-ac6f-03ed302e4c02); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+
14 rows selected (0.247 seconds)
# 调用MapReduce查询
0: jdbc:hive2://ops01:10000> select count(*) from emp;
INFO : Compiling command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6): select count(*) from emp
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6); Time taken: 0.117 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6): select count(*) from emp
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1615531413182_0102
INFO : Executing with tokens: []
INFO : The url to track the job: http://ops02:8088/proxy/application_1615531413182_0102/
INFO : Starting Job = job_1615531413182_0102, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0102/
INFO : Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0102
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2021-04-24 17:07:01,947 Stage-1 map = 0%, reduce = 0%
INFO : 2021-04-24 17:07:09,112 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.22 sec
INFO : 2021-04-24 17:07:16,256 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.26 sec
INFO : MapReduce Total cumulative CPU time: 5 seconds 260 msec
INFO : Ended Job = job_1615531413182_0102
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.26 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS
INFO : Total MapReduce CPU Time Spent: 5 seconds 260 msec
INFO : Completed executing command(queryId=wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6); Time taken: 23.796 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------+
| _c0 |
+------+
| 14 |
+------+
1 row selected (23.933 seconds)
# 查询不存在的表,制造异常
0: jdbc:hive2://ops01:10000> select count(*) from emppppppppppppppp;
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp' (state=42S02,code=10001)
0: jdbc:hive2://ops01:10000> select count(*) from emppppppppppppppp;
Error: Error while compiling statement: FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp' (state=42S02,code=10001)
验证flume-dir方式,可以看到在/opt/module/flume/job目录下会同步生成相关文件
wangting@ops01:/opt/module/flume/job >ll
total 16
-rw-rw-r-- 1 wangting wangting 0 Apr 24 17:05 1619255120463-1
-rw-rw-r-- 1 wangting wangting 575 Apr 24 17:05 1619255120463-2
-rw-rw-r-- 1 wangting wangting 3 Apr 24 17:06 1619255120463-3
-rw-rw-r-- 1 wangting wangting 863 Apr 24 17:07 1619255120463-4
-rw-rw-r-- 1 wangting wangting 445 Apr 24 17:07 1619255120463-5
wangting@ops01:/opt/module/flume/job >cat 1619255120463-2
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-04-24 16:18:20,663 Stage-1 map = 0%, reduce = 0%
2021-04-24 16:18:25,827 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2021-04-24 16:18:31,975 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.19 sec
MapReduce Total cumulative CPU time: 6 seconds 190 msec
Ended Job = job_1615531413182_0101
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.19 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 190 msec
OK
wangting@ops01:/opt/module/flume/job >cat 1619255120463-3
OK
wangting@ops01:/opt/module/flume/job >cat 1619255120463-4
Query ID = wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1615531413182_0102, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0102/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0102
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-04-24 17:07:01,947 Stage-1 map = 0%, reduce = 0%
2021-04-24 17:07:09,112 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.22 sec
wangting@ops01:/opt/module/flume/job >cat 1619255120463-5
2021-04-24 17:07:16,256 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.26 sec
MapReduce Total cumulative CPU time: 5 seconds 260 msec
Ended Job = job_1615531413182_0102
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.26 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 260 msec
OK
FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp'
FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp'
验证hdfs方式,可以看到hdfs同步也同步生成了hive对应日志
# 查看对应目录
wangting@ops01:/opt/module/flume/job >hdfs dfs -ls /flume/20210424/17
2021-04-24 17:12:46,127 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
Found 1 items
-rw-r--r-- 3 wangting supergroup 575 2021-04-24 17:05 /flume/20210424/17/flume-.1619255148002.tmp
# 查看生成文件写入内容
wangting@ops01:/opt/module/flume/job >hdfs dfs -cat /flume/20210424/17/flume-.1619255148002.tmp
2021-04-24 17:13:17,766 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-04-24 17:13:18,648 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-04-24 16:18:20,663 Stage-1 map = 0%, reduce = 0%
2021-04-24 16:18:25,827 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2021-04-24 16:18:31,975 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 6.19 sec
MapReduce Total cumulative CPU time: 6 seconds 190 msec
Ended Job = job_1615531413182_0101
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 6.19 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 190 msec
OK
OK
Query ID = wangting_20210424170653_1addfc8b-e2ed-4ba5-bb06-22b2573d30c6
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1615531413182_0102, Tracking URL = http://ops02:8088/proxy/application_1615531413182_0102/
Kill Command = /opt/module/hadoop-3.1.3/bin/mapred job -kill job_1615531413182_0102
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-04-24 17:07:01,947 Stage-1 map = 0%, reduce = 0%
2021-04-24 17:07:09,112 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.22 sec
2021-04-24 17:07:16,256 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.26 sec
MapReduce Total cumulative CPU time: 5 seconds 260 msec
Ended Job = job_1615531413182_0102
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.26 sec HDFS Read: 14007 HDFS Write: 102 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 260 msec
OK
FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp'
FAILED: SemanticException [Error 10001]: Line 1:21 Table not found 'emppppppppppppppp'
Flume使用案例6
场景:负载均衡和故障转移
背景需求
使用Flume1监控一个端口,其sink组中的sink分别对接Flume2和Flume3,采用FailoverSinkProcessor,实现故障转移的功能。

准备工作,编写配置
对应3个配置文件
编写配置 /opt/module/flume/datas/06-flume-netcat-flume.conf
【注意】:
source 数据源输入用netcat来模拟内容输入,直观易理解
sink 写出对应2个sink,也就是后面再用2个agent中的source来接数据
wangting@ops01:/opt/module/flume/datas >vim 06-flume-netcat-flume.conf
# Name the components on this agent
bigdata01.sources = r1
bigdata01.channels = c1
bigdata01.sinkgroups = g1
bigdata01.sinks = k1 k2
# Describe/configure the source
bigdata01.sources.r1.type = netcat
bigdata01.sources.r1.bind = localhost
bigdata01.sources.r1.port = 44444
bigdata01.sinkgroups.g1.processor.type = failover
bigdata01.sinkgroups.g1.processor.priority.k1 = 5
bigdata01.sinkgroups.g1.processor.priority.k2 = 10
bigdata01.sinkgroups.g1.processor.maxpenalty = 10000
# Describe the sink
bigdata01.sinks.k1.type = avro
bigdata01.sinks.k1.hostname = ops01
bigdata01.sinks.k1.port = 44441
bigdata01.sinks.k2.type = avro
bigdata01.sinks.k2.hostname = ops01
bigdata01.sinks.k2.port = 44442
# Describe the channel
bigdata01.channels.c1.type = memory
bigdata01.channels.c1.capacity = 1000
bigdata01.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata01.sources.r1.channels = c1
bigdata01.sinkgroups.g1.sinks = k1 k2
bigdata01.sinks.k1.channel = c1
bigdata01.sinks.k2.channel = c1
编写配置 /opt/module/flume/datas/06-flume-flume-console1.conf
wangting@ops01:/opt/module/flume/datas >vim 06-flume-flume-console1.conf
# Name the components on this agent
bigdata02.sources = r1
bigdata02.sinks = k1
bigdata02.channels = c1
# Describe/configure the source
bigdata02.sources.r1.type = avro
bigdata02.sources.r1.bind = ops01
bigdata02.sources.r1.port = 44441
# Describe the sink
bigdata02.sinks.k1.type = logger
# Describe the channel
bigdata02.channels.c1.type = memory
bigdata02.channels.c1.capacity = 1000
bigdata02.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata02.sources.r1.channels = c1
bigdata02.sinks.k1.channel = c1
编写配置 /opt/module/flume/datas/06-flume-flume-console2.conf
wangting@ops01:/opt/module/flume/datas >vim 06-flume-flume-console2.conf
# Name the components on this agent
bigdata03.sources = r1
bigdata03.sinks = k1
bigdata03.channels = c2
# Describe/configure the source
bigdata03.sources.r1.type = avro
bigdata03.sources.r1.bind = ops01
bigdata03.sources.r1.port = 44442
# Describe the sink
bigdata03.sinks.k1.type = logger
# Describe the channel
bigdata03.channels.c2.type = memory
bigdata03.channels.c2.capacity = 1000
bigdata03.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata03.sources.r1.channels = c2
bigdata03.sinks.k1.channel = c2
【注意】:
bigdata01 -> 监听44444端口,netcat发来的数据;
bigdata02 -> 监听44441端口,bigdata01发来的数据
bigdata03 -> 监听44442端口,bigdata01发来的数据
bigdata02和bigdata03 只会有一个能接收到,当接收到的那个服务异常,另一个才会接到数据;目的是测试是否能自动成功跳转到新的端口上继续接收
启动agent
【注意】:启动多个会话窗口,让每个agent持续运行。
agent-bigdata03
flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/06-flume-flume-console2.conf -Dflume.root.logger=INFO,console
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/06-flume-flume-console2.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata03 --conf-file datas/06-flume-flume-console2.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-25 09:42:05,310 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2021-04-25 09:42:05,315 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:138)] Reloading configuration file:datas/06-flume-flume-console2.conf
2021-04-25 09:42:05,322 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,323 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,323 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,323 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1117)] Added sinks: k1 Agent: bigdata03
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c2
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c2
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c2
2021-04-25 09:42:05,324 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:05,325 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet(FlumeConfiguration.java:623)] Agent configuration for 'bigdata03' has no configfilters.
2021-04-25 09:42:05,345 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:163)] Post-validation flume configuration contains configuration for agents: [bigdata03]
2021-04-25 09:42:05,345 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:151)] Creating channels
2021-04-25 09:42:05,352 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c2 type memory
2021-04-25 09:42:05,360 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:205)] Created channel c2
2021-04-25 09:42:05,362 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type avro
2021-04-25 09:42:05,374 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger
2021-04-25 09:42:05,377 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:120)] Channel c2 connected to [r1, k1]
2021-04-25 09:42:05,381 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:162)] Starting new configuration:{
sourceRunners:{
r1=EventDrivenSourceRunner: {
source:Avro source r1: {
bindAddress: ops01, port: 44442 } }} sinkRunners:{
k1=SinkRunner: {
policy:org.apache.flume.sink.DefaultSinkProcessor@502edef6 counterGroup:{
name:null counters:{
} } }} channels:{
c2=org.apache.flume.channel.MemoryChannel{
name: c2}} }
2021-04-25 09:42:05,383 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:169)] Starting Channel c2
2021-04-25 09:42:05,441 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c2: Successfully registered new MBean.
2021-04-25 09:42:05,441 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c2 started
2021-04-25 09:42:05,441 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1
2021-04-25 09:42:05,442 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1
2021-04-25 09:42:05,442 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:193)] Starting Avro source r1: {
bindAddress: ops01, port: 44442 }...
2021-04-25 09:42:05,776 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
2021-04-25 09:42:05,776 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: r1 started
2021-04-25 09:42:05,778 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:219)] Avro source r1 started.
2021-04-25 09:43:33,977 (New I/O server boss #17) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x168ca9eb, /11.8.37.50:50586 => /11.8.37.50:44442] OPEN
2021-04-25 09:43:33,978 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x168ca9eb, /11.8.37.50:50586 => /11.8.37.50:44442] BOUND: /11.8.37.50:44442
2021-04-25 09:43:33,978 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x168ca9eb, /11.8.37.50:50586 => /11.8.37.50:44442] CONNECTED: /11.8.37.50:50586
agent-bigdata02
flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/06-flume-flume-console1.conf -Dflume.root.logger=INFO,console
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/06-flume-flume-console1.conf -Dflume.root.logger=INFO,console
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata02 --conf-file datas/06-flume-flume-console1.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2021-04-25 09:42:28,068 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting
2021-04-25 09:42:28,074 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:138)] Reloading configuration file:datas/06-flume-flume-console1.conf
2021-04-25 09:42:28,081 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-25 09:42:28,082 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:c1
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:k1
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1117)] Added sinks: k1 Agent: bigdata02
2021-04-25 09:42:28,083 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addComponentConfig(FlumeConfiguration.java:1203)] Processing:r1
2021-04-25 09:42:28,083 (conf-file-poller-0) [WARN - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.validateConfigFilterSet(FlumeConfiguration.java:623)] Agent configuration for 'bigdata02' has no configfilters.
2021-04-25 09:42:28,104 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:163)] Post-validation flume configuration contains configuration for agents: [bigdata02]
2021-04-25 09:42:28,105 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:151)] Creating channels
2021-04-25 09:42:28,113 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c1 type memory
2021-04-25 09:42:28,121 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:205)] Created channel c1
2021-04-25 09:42:28,123 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type avro
2021-04-25 09:42:28,135 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger
2021-04-25 09:42:28,138 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:120)] Channel c1 connected to [r1, k1]
2021-04-25 09:42:28,142 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:162)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:Avro source r1: { bindAddress: ops01, port: 44441 } }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@550c3c8e counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} }
2021-04-25 09:42:28,143 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:169)] Starting Channel c1
2021-04-25 09:42:28,201 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean.
2021-04-25 09:42:28,202 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: CHANNEL, name: c1 started
2021-04-25 09:42:28,202 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:196)] Starting Sink k1
2021-04-25 09:42:28,202 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:207)] Starting Source r1
2021-04-25 09:42:28,203 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:193)] Starting Avro source r1: { bindAddress: ops01, port: 44441 }...
2021-04-25 09:42:28,544 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean.
2021-04-25 09:42:28,544 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: r1 started
2021-04-25 09:42:28,546 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:219)] Avro source r1 started.
2021-04-25 09:43:33,777 (New I/O server boss #17) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xc58d6c06, /11.8.37.50:45068 => /11.8.37.50:44441] OPEN
2021-04-25 09:43:33,778 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xc58d6c06, /11.8.37.50:45068 => /11.8.37.50:44441] BOUND: /11.8.37.50:44441
2021-04-25 09:43:33,778 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0xc58d6c06, /11.8.37.50:45068 => /11.8.37.50:44441] CONNECTED: /11.8.37.50:45068
agent-bigdata01
flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/06-flume-netcat-flume.conf
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/06-flume-netcat-flume.conf
Info: Including Hadoop libraries found via (/opt/module/hadoop-3.1.3/bin/hadoop) for HDFS access
Info: Including Hive libraries found via (/opt/module/hive) for Hive access
+ exec /usr/jdk1.8.0_131/bin/java -Xmx20m -cp '/opt/module/flume/conf:/opt/module/flume/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*:/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/tez/*:/opt/module/tez/lib/*:/opt/module/hive/lib/*' -Djava.library.path=:/opt/module/hadoop-3.1.3/lib/native org.apache.flume.node.Application --name bigdata01 --conf-file datas/06-flume-netcat-flume.conf
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flume/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
场景实验
# 查看44444端口已经运行,bigdata01的agent正常
wangting@ops01:/opt/module/flume >netstat -tnlpu|grep 44444
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 127.0.0.1:44444 :::* LISTEN 6498/java
wangting@ops01:/opt/module/flume >
wangting@ops01:/opt/module/flume >nc localhost 44444
wang
OK # 看到ok后可以在控制台查看当前是哪一个bigdata的agent接收到了数据,可以看到03接收到了Event
Only one rev
OK # 继续发送消息,依然是03接收到Event
now is 44442
OK # bigdata03 agent运行正常会持续接收
44442 bigdata03
OK # 发完这条 44442 bigdata03 后 把03的agent停掉
new info
OK # 查看new info 是否被bigdata02成功接收
now is 44441
OK # 验证成功,成功转移
44441 bigdata02
OK
bigdata03 (port 44442) 控制台:
2021-04-25 09:45:23,459 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 wang }
2021-04-25 09:47:54,107 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 4F 6E 6C 79 20 6F 6E 65 20 72 65 76 Only one rev }
2021-04-25 09:48:40,111 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 6E 6F 77 20 69 73 20 34 34 34 34 32 now is 44442 }
2021-04-25 09:49:57,121 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 34 34 34 34 32 20 62 69 67 64 61 74 61 30 33 44442 bigdata03 }
stopping # 停03
wangting@ops01:/opt/module/flume >netstat -tnlpu|grep 44442
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
wangting@ops01:/opt/module/flume >netstat -tnlpu|grep 44441
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 11.8.37.50:44441 :::* LISTEN 5988/java
wangting@ops01:/opt/module/flume >
# 现在只有44441端口在
bigdata02 (port 44441) 控制台:
2021-04-25 09:51:30,235 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 6E 65 77 20 69 6E 66 6F new info }
2021-04-25 09:51:46,004 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 6E 6F 77 20 69 73 20 34 34 34 34 31 now is 44441 }
2021-04-25 09:52:24,006 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 34 34 34 34 31 20 62 69 67 64 61 74 61 30 32 44441 bigdata02 }
最终,03异常的情况下,02可以正常的接收到数据
Flume使用案例7
场景:聚合
背景需求
- ops01上的Flume-1监控文件/opt/module/group.log文件内容变化。
- ops02上的Flume-2监控某一个44444端口的数据流。
- Flume-1与Flume-2将数据都发送给ops03上的Flume-3,Flume-3将最终数据打印到控制台。

【注意1】:
需要3台机器; 都已经部署了flume,例如ops01 / ops02 / ops03 指的是分别在3台服务器部署了flume
【注意2】:
部署好flume,需要在/etc/hosts 都配置hosts解析
例如:tail -5 /etc/hosts
11.8.37.50 ops01
11.8.36.63 ops02
11.8.36.76 ops03
【注意3】:
现在配置文件和之前案例不一样,在哪个机器启动agent需要在哪个对应服务器上对应路径编写配置
准备工作,编写配置
ops01 /opt/module/flume/datas/
vim 07-flume1-logger-flume.conf
# Name the components on this agent
bigdata01.sources = r1
bigdata01.sinks = k1
bigdata01.channels = c1
# Describe/configure the source
bigdata01.sources.r1.type = exec
bigdata01.sources.r1.command = tail -F /opt/module/group.log
bigdata01.sources.r1.shell = /bin/bash -c
# Describe the sink
bigdata01.sinks.k1.type = avro
bigdata01.sinks.k1.hostname = ops03
bigdata01.sinks.k1.port = 44441
# Describe the channel
bigdata01.channels.c1.type = memory
bigdata01.channels.c1.capacity = 1000
bigdata01.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata01.sources.r1.channels = c1
bigdata01.sinks.k1.channel = c1
ops02 /opt/module/flume/datas/
vim 07-flume2-netcat-flume.conf
# Name the components on this agent
bigdata02.sources = r1
bigdata02.sinks = k1
bigdata02.channels = c1
# Describe/configure the source
bigdata02.sources.r1.type = netcat
bigdata02.sources.r1.bind = ops02
bigdata02.sources.r1.port = 44444
# Describe the sink
bigdata02.sinks.k1.type = avro
bigdata02.sinks.k1.hostname = ops03
bigdata02.sinks.k1.port = 44441
# Use a channel which buffers events in memory
bigdata02.channels.c1.type = memory
bigdata02.channels.c1.capacity = 1000
bigdata02.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata02.sources.r1.channels = c1
bigdata02.sinks.k1.channel = c1
ops03 /opt/module/flume/datas/
vim 07-flume3-flume-logger.conf
# Name the components on this agent
bigdata03.sources = r1
bigdata03.sinks = k1
bigdata03.channels = c1
# Describe/configure the source
bigdata03.sources.r1.type = avro
bigdata03.sources.r1.bind = ops03
bigdata03.sources.r1.port = 44441
# Describe the sink
# Describe the sink
bigdata03.sinks.k1.type = logger
# Describe the channel
bigdata03.channels.c1.type = memory
bigdata03.channels.c1.capacity = 1000
bigdata03.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
bigdata03.sources.r1.channels = c1
bigdata03.sinks.k1.channel = c1
启动agent
启动顺序一般都是从后到前,接收方先启动;示例较多,这里就只贴命令省去info输出了
# ops03服务器,bigdata03,需要看最终展示效果,增加-Dflume.root.logger=INFO,console
wangting@ops03:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata03 --conf-file datas/07-flume3-flume-logger.conf -Dflume.root.logger=INFO,console
# ops01服务器,bigdata01 ,对应测试路径下文件内容变化
wangting@ops01:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata01 --conf-file datas/07-flume1-logger-flume.conf
# ops02服务器,bigdata02,对应测试某端口流数据变化
wangting@ops02:/opt/module/flume >flume-ng agent --conf conf/ --name bigdata02 --conf-file datas/07-flume2-netcat-flume.conf
场景实验
# ops01,再打开一个会话窗口
wangting@ops01:/opt/module >cd /opt/module
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
wangting@ops01:/opt/module >echo 'wangt' >> group.log
# 对应查看ops03 agent控制台输出
2021-04-25 11:33:28,745 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,746 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,746 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,746 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 74 wangt }
2021-04-25 11:33:32,747 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 74 wangt }
# ops02,再打开一个会话窗口
wangting@ops02:/opt/module >netstat -tnlpu|grep 44444
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 11.8.36.63:44444 :::* LISTEN 62200/java
wangting@ops02:/opt/module >telnet ops02 44444
Trying 11.8.36.63...
Connected to ops02.
Escape character is '^]'.
wangt
OK
ops02
OK
66666
OK
telnet test
OK
# 对应查看ops03 agent控制台输出
2021-04-25 11:34:19,491 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 77 61 6E 67 74 0D wangt. }
2021-04-25 11:34:26,318 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 6F 70 73 30 32 0D ops02. }
2021-04-25 11:34:35,320 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 36 36 36 36 36 0D 66666. }
2021-04-25 11:34:46,523 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: {
headers:{
} body: 74 65 6C 6E 65 74 20 74 65 73 74 0D telnet test. }
最终,数据成功聚合到07-flume3-flume-logger.conf 定义的bigdata03上。