一、Lambda表达式
Lambda表达式又被称之为匿名函数
格式
lambda 参数列表:函数体
def add(x,y): return x+y print(add(3,4)) #上面的函数可以写成Lambda函数 add_lambda=lambda x,y:x+y add_lambda(3,4)
二、map函数
函数就是有输入和输出,map的输入和输出对应关系如下图所示:
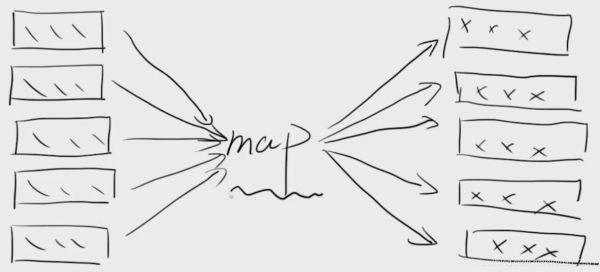
就是要把一个可迭代的对象按某个规则映射到新的对象上。
因此map函数要有两个参数,一个是映射规则,一个是可迭代对象。
list1=[1,2,3,4,5] r=map(lambda x:x+x,list) print(list1(r))
结果:[2,4,6,8,10]
m1=map(lambda x,y:x*x+y,[1,2,3,4,5],[1,2,3,4,5]) print(list(ml))
结果:[2,6,12,20,30]
三、filter函数
filter的输入和输出对应关系如下图所示:
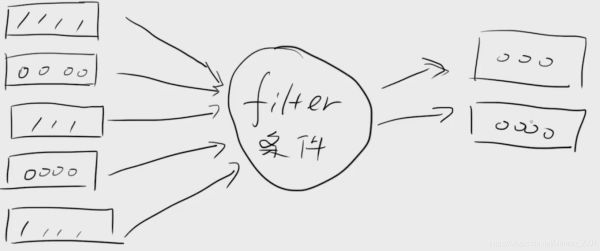
def is_not_none(s): return s and len(s.strip())>0 list2=['','','hello','xxxx', None,'ai'] result=filter(is_not_none, list2) print(list(result))
结果:[‘hello',‘xxxx',‘ai']
四、reduce函数

from functools import reduce f=lambda x,y:x+y x=reduce(f,[1,2,3,4,5]) print(r)
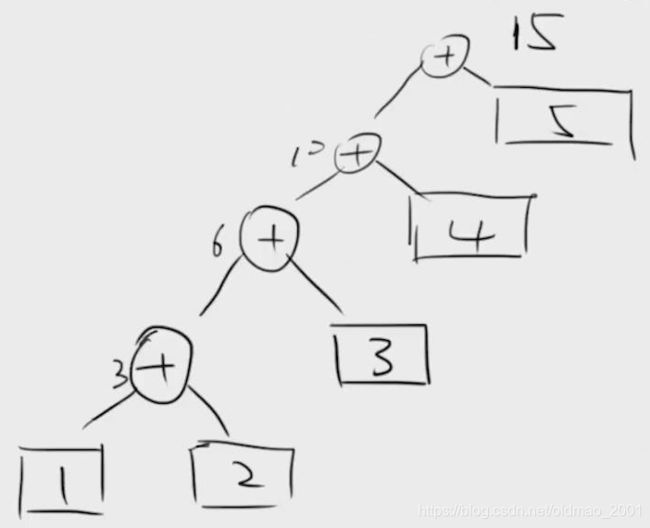
结果:15=1+2+3+4+5
相当于每一次计算都是基于前一次计算的结果:
还可以为reduce计算添加初始值:
from functools import reduce f=lambda x,y:x+y x=reduce(f,[1,2,3,4,5],10) print(r)
结果:25=10+1+2+3+4+5
五、三大推导式
5.1 列表推导式
list1=[1,2,3,4,5,6] f=map(lambda x:x+x,list1) print(list(f)) list2=[i+i for i in list1] print(list2) list3=[i**3 for i in list1] print(list3) #筛选列表的例子 list4=[i*4 for i in list1 if i>3] print(list4) #结果 [2,4,6,8,10,12] [2,4,6,8,10,12] [1,8,27,64,125,216] [16,25,36]
5.2 集合推导式
直接把上面代码copy下来,然后把列表改成集合
list1={1,2,3,4,5,6}
list2={i+i for i in list1}
print(list2)
list3={i**3 for i in list1}
print(list3)
#筛选列表的例子
list4={i*4 for i in list1 if i>3}
print(list4)
#结果
{2, 4, 6, 8, 10, 12}
{64, 1, 8, 216, 27, 125}#这里是乱序的
{16, 24, 20}
5.3 字典推导式
s={
"zhangsan":20,
"lisi":15,
"wangwu":31
}
#拿出所有的key,并变成列表
s_key=[ key for key, value in s.items()]
print(s_key)
#结果
['zhangsan','lisi','wangwu']
# 交换key和value位置,注意冒号的位置
s1={ value: key for key, value in s.items()}
print(s1)
#结果
{20:'zhangsan',15:'1isi',31:'wangwu'}
s2={ key: value for key, value in s.items() if key=="1isi"}
print(s2)
#结果
{"lisi":15}
六、闭包
闭包:一个返回值是函数的函数
import time def runtime(): def now_time(): print(time.time()) return now_time #返回值是函数名字 f=runtime()#f就被赋值为一个函数now_time()了 f()#运行f相当于运行now_time()
再来看一个带参数的例子:
假设有一个csv文件,内容有三行,具体如下:
a,b,c,d,e
1,2,3,4,5
6,7,8,9,10
def make_filter(keep):# keep=8
def the_filter(file_name):
file=open(file name)#打开文件
lines=file.readlines()#按行读取文件
file.close()#关闭文件
filter_doc=[i for i in lines if keep in i]#过滤文件内容
return filter_doc
return the_filter
filter1=make_filter("8")#这一行调用了make_filter函数,且把8做为参数传给了keep,接受了the_filter函数作为返回值
#这里的filter1等于函数the_filter
filter_result=filter1("data.csv")#把文件名data.csv作为参数传给了函数the_filter
print(filter_result)
#结果
['6,7,8,9,10']
七、装饰器、语法糖、注解
# 这是获取函数开始运行时间的函数
import time
def runtime(func):
def get_time():
print(time.time())
func()# run被调用
return get_time
@runtime
def run()
print('student run')
#运行
run()
#结果
当前时间
student run
由于有装饰器@runtime的存在,会把run这个函数作为参数丢到runtime(func)里面去,如果调整打印时间代码的位置会有不同结果:
# 这是获取函数结束运行时间的函数
import time
def runtime(func):
def get_time():
func()# run被调用
print(time.time())
return get_time
@runtime
def run()
print('student run')
#运行
run()
#结果
student run
当前时间
这里还要注意,这里还用到了闭包的概念,在运行run函数的时候,调用的实际上是get_time函数。
对于多个参数的函数如何调用,看下面例子
#有一个参数
import time
def runtime(func):
def get_time(i):
func(i)# run被调用
print(time.time())
return get_time
@runtime
def run(i)
print('student run')
#运行
run(1)
#有两个参数
import time
def runtime(func):
def get_time(i,j):
func(i,j)# run被调用
print(time.time())
return get_time
@runtime
def run(i,j)
print('student run')
#运行
run(1,2)
可以发现,这样写对于函数的多态不是很好,因此可以写为:
#自动适配参数
import time
def runtime(func):
def get_time(*arg):
func(*arg)# run被调用
print(time.time())
return get_time
@runtime
def run(i)
print('student1 run')
@runtime
def run(i,j)
print('student2 run')
#运行
run(1)
run(1,2)
再次进行扩展,更为普适的写法,可以解决传入类似i=4的关键字参数写法:
#自动适配参数
import time
def runtime(func):
def get_time(*arg,**kwarg):
func(*arg,**kwarg)# run被调用
print(time.time())
return get_time
@runtime
def run(i)
print('student1 run')
@runtime
def run(*arg,**kwarg)
print('student2 run')
@runtime
def run()
print('no param run')
#运行
run(1)
run(1,2,j=4)
run()
到此这篇关于Python进阶之高级用法详细总结的文章就介绍到这了,更多相关Python高级用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!