7-6 scikit-learn中的PCA、寻找合适的维度
未降维时
scikit-learn 中的PCA¶
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
digits = datasets.load_digits()
X = digits.data
y = digits.target
from sklearn.model_selection import
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=666)
X_train.shape
输出:(1347, 64)
X_test.shape
输出:(450, 64)
%%time
from sklearn.neighbors import KNeighborsClassifier
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train,y_train)
输出:Wall time: 134 ms
KNeighborsClassifier()
knn_clf.score(X_test,y_test)#得到的识别率很高
输出:0.9866666666666667
将数据降到2维
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
%%time
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)
输出:
Wall time: 3 ms
KNeighborsClassifier()
knn_clf.score(X_test_reduction,y_test)#由64维降成2维以后识别精度大大降低了
输出:0.6066666666666667
scikit-learn中自带的解释现有数据解释了多少原数据方差的方法
pca.explained_variance_ratio_
pca.explained_variance_ratio_
"""表示每个轴可以解释百分之多少原数据的方差,
结果表明我们的两个维度仅涵盖了原数据百分之28的方差,
其它的方差信息都丢失了"""
array([0.14566817, 0.13735469])
pca = PCA(n_components = X_train.shape[1])
pca.fit(X_train)
pca.explained_variance_ratio_#每一个主成分可解释的方差分别为多少,也可表示每一个轴的重要程度
array([1.45668166e-01, 1.37354688e-01, 1.17777287e-01, 8.49968861e-02,
5.86018996e-02, 5.11542945e-02, 4.26605279e-02, 3.60119663e-02,
3.41105814e-02, 3.05407804e-02, 2.42337671e-02, 2.28700570e-02,
1.80304649e-02, 1.79346003e-02, 1.45798298e-02, 1.42044841e-02,
1.29961033e-02, 1.26617002e-02, 1.01728635e-02, 9.09314698e-03,
8.85220461e-03, 7.73828332e-03, 7.60516219e-03, 7.11864860e-03,
6.85977267e-03, 5.76411920e-03, 5.71688020e-03, 5.08255707e-03,
4.89020776e-03, 4.34888085e-03, 3.72917505e-03, 3.57755036e-03,
3.26989470e-03, 3.14917937e-03, 3.09269839e-03, 2.87619649e-03,
2.50362666e-03, 2.25417403e-03, 2.20030857e-03, 1.98028746e-03,
1.88195578e-03, 1.52769283e-03, 1.42823692e-03, 1.38003340e-03,
1.17572392e-03, 1.07377463e-03, 9.55152460e-04, 9.00017642e-04,
5.79162563e-04, 3.82793717e-04, 2.38328586e-04, 8.40132221e-05,
5.60545588e-05, 5.48538930e-05, 1.08077650e-05, 4.01354717e-06,
1.23186515e-06, 1.05783059e-06, 6.06659094e-07, 5.86686040e-07,
1.71368535e-33, 7.44075955e-34, 7.44075955e-34, 7.15189459e-34])
绘图:横轴表示第几维,纵轴表示前几维的可解释方差之和,根据图片可以决定数据降到多少维比较合适
plt.plot([i for i in range(X_train.shape[1])],[np.sum(pca.explained_variance_ratio_[:i+1]) for i in range(X_train.shape[1])])
plt.show()
输出图片: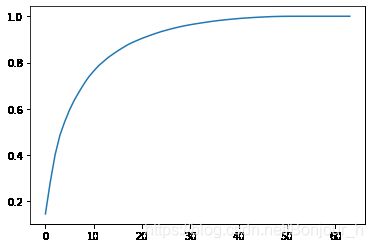
pca = PCA(0.95)
pca.fit(X_train)
PCA(n_components=0.95)
pca.n_components_#(得到的结果表示得到95%以上的方差需要降到多少维合适)
输出:28
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
%%time
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train_reduction,y_train)
输出:
Wall time: 11 ms
KNeighborsClassifier()
#比起用全样本训练来说,精度有所丢失,但是时间加快了很多
knn_clf.score(X_test_reduction,y_test)
输出:0.98
虽然我们可以用该方法确定数据降到几维比较合适,虽然降到二维的时候精确度比较低,但是这并不意味将数据降到二维没有意义。因为有的数据在二维的时候就有清晰的特征,可以将其和与其不同类型的数据区分开来