《Recurrent Chunking Mechanisms for Long-Text Machine Reading Comprehension》--论文分享
作者:Sjw
时间:2021年4月30日
今天要分享的是来自ACL2020的一篇论文,作者是:Hongyu Gong, Yelong Shen, Dian Yu,Jianshu Chen, Dong Yu
目录
1.解决的问题
2.方法
2.1循环机制
2.2基于强化学习的分段策略
3.实验
1.解决的问题
现在的机器阅读理解模型大多数都是使用预训练模型(例如BERT)对文档和问题的联合上下文信息进行编码。但是这些基于transformer架构的模型只能采用固定长度(例如512,文本长度不足会进行填充)的文本作为输入。 需要处理更长的文本输入时,以前的方法通常将它们分成等距的段(比如通过设置滑窗大小为128),并根据每个段独立地预测答案,而不考虑其他段的信息。就像下图这种情况:
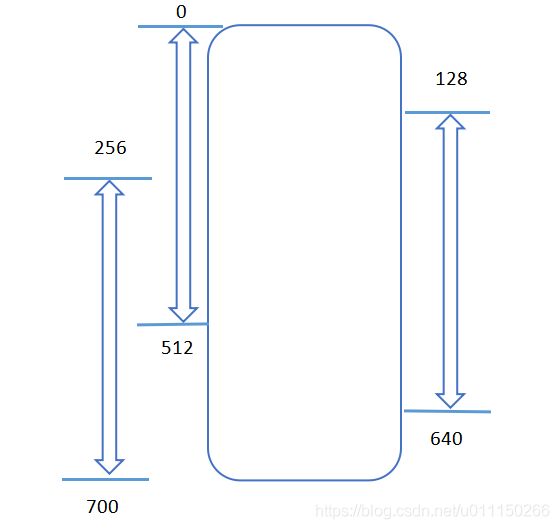
设滑窗长度为128,最大句长为512,那么长度为700的本文经过处理后会被切分为3段,第一段为0-512,第二段为128-640,第三段为256-700。
这种情况下,会产生需要预测的答案处在被分割的边界位置,导致丢失用于推理答案的上下文信息,而且片段与片段之间缺乏交互,又丢失了一部分信息。
为了说明上下文信息对答案预测的影响,作者还展示了答案片段的中心位置与文章的中心位置距离对F1值的影响:

可以看到,随着答案片段的中心位置与文章的中心位置的距离增大,F1值有着明显的下降。
2.方法
于是乎,作者就提出了一种更加科学的长文本分段方法,也就是本文要讲的: RCM(recurrent chunking mechanisms)通过强化学习的方式学习分段长度,并使用一种循环机制让片段之间得到交互,为真实答案的预测提供更多的上下文信息。
2.1循环机制
由于该工作是基于BERT等transformer架构的模型进行的,作者取出了每个段落中的[CLS]位置向量作为该段落的语义向量![]() ,并在循环机制中进行交互,得到最终生成的向量
,并在循环机制中进行交互,得到最终生成的向量 ![]() 。其中
。其中![]() 可以为Gated recurrence(GRU)或者LSTM,公式如下:
可以为Gated recurrence(GRU)或者LSTM,公式如下:
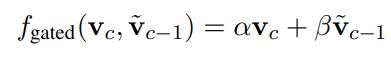
![]()
最后,不管以何种方式,最终都会得到经过不同段交互后的段落语义向量![]() 。获取到
。获取到![]() 后就可以计算对该段落是否正确答案的概率估计值
后就可以计算对该段落是否正确答案的概率估计值![]() ,其计算公式如下:
,其计算公式如下:
![]()
2.2基于强化学习的分段策略
首先简单的介绍一下强化学习。
“强化学习是用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题......强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。”
那对应在本文中,强化学习的环境就是我们的深度学习模型结构,状态 是已被分好的段落,动作
是已被分好的段落,动作![]() 则为分段时的步长大小和方向。在状态下执行
则为分段时的步长大小和方向。在状态下执行![]() 动作的概率为:
动作的概率为:

针对状态和动作![]() 产生的奖励值为
产生的奖励值为![]() ,其公式如下。
,其公式如下。![]() 是下一段的奖励值,
是下一段的奖励值,![]() 是之前得出的模型根据段落语义向量
是之前得出的模型根据段落语义向量![]() 得出的对该段落是否正确答案的概率估计值。式子中的第一项
得出的对该段落是否正确答案的概率估计值。式子中的第一项![]() 是从该段落中提取出正确答案的奖励值。考虑一下,在所有段落中只有一段包含答案,在计算奖励时,不仅要在分对具有答案的段落时进行奖励,还要奖励分对不包含答案的段落,所以要添加后边的一项。通过最大化奖励值,就可以训练分段方法啦。
是从该段落中提取出正确答案的奖励值。考虑一下,在所有段落中只有一段包含答案,在计算奖励时,不仅要在分对具有答案的段落时进行奖励,还要奖励分对不包含答案的段落,所以要添加后边的一项。通过最大化奖励值,就可以训练分段方法啦。

其中![]() 的取值是根据当前段落
的取值是根据当前段落 提取出答案的可能性,其公式如下。可以从公式中看出,
提取出答案的可能性,其公式如下。可以从公式中看出,![]() 的取值是根据模型预测出的真实答案位置概率值计算所得。
的取值是根据模型预测出的真实答案位置概率值计算所得。
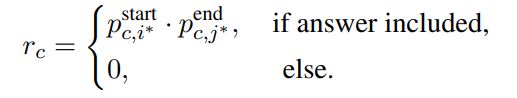
最后,将两种方法总结起来,算法整体的结构见下图所示:
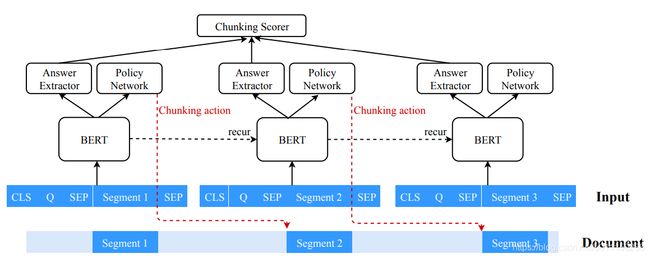
分出的段落送入BERT当中经过段落之间的交互后得到![]() ,用于Answer Extractor 和 Policy Network。Answer Extractor最终得出评分
,用于Answer Extractor 和 Policy Network。Answer Extractor最终得出评分![]() 。Policy Network得出执行动作
。Policy Network得出执行动作![]() 的概率
的概率![]() 。
。
3.实验
最后,作者在 CoQA 、 QuAC 和TriviaQA上进行了实验,三个数据集的统计数据如下图所示。

实验的结果如下,可以看到,该方法在较短输入长度上的准确率有着比较大的提升,而在512长度上提升较小。因为CoQA与QuAC的平均长度接近或小于512,大部分文本可能不需要再次分段。而在文本较长的TriviaQA数据集上具有更好的效果。

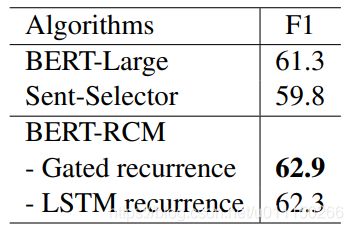 TriviaQA数据集上的结果
TriviaQA数据集上的结果
最后附上该论文的代码:
https://github.com/HongyuGong/RCM-Question-Answering.git
论文链接:
https://www.aclweb.org/anthology/2020.acl-main.603/