原文:https://herbertograca.com/2018/07/07/more-than-concentric-layers/
这篇文章是软件架构编年史(译)的一部分,这部编年史由一系列关于软件架构的文章组成。在这一系列文章中,我将写下我对软件架构的学习和思考,以及我是如何运用这些知识的。如果你阅读了这个系列中之前的文章,本篇文章的的内容将更有意义。
在我之前的这篇系列文章(译)中,我发表了一幅信息图,展示了用来理解代码单元类型之间联系的心智地图。
然而,我始终觉得有一部分内容并没有得到很好的体现,但我不知道应该如何更好地将它展示出来。这个部分就是共享内核。
而且,我还发现了一些新内容,在这篇博客中我将记录下所有的内容。
观察上一篇博客中发表的信息图,我们发现共享内核位于图的中心,看起来好像在领域层内部,叠在代表领域上下文的同心圆之上。
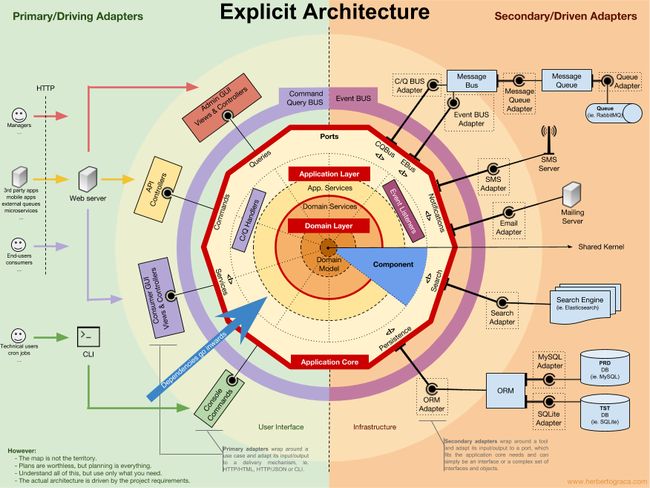
尽管将共享内核放在这个位置,但我要表达的并不是共享内核会依赖其余部分的代码,它也不是领域层内部的另一个层次。
什么是共享内核?!
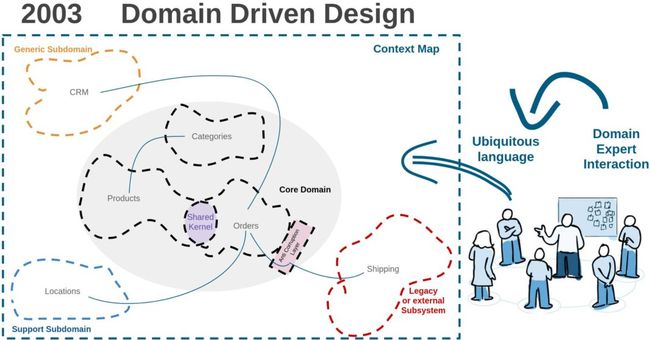
共享内核由 DDD 之父 Eric Evans 定义,它是多个限界上下文之间共享的代码,由开发团队决定:
[...] 两个团队同意共享的领域模型的子集。当然,和模型子集一起共享还包括代码的子集,还有和这部分模型有关的数据库设计。这部分明确要共享的内容有着特殊的状态,而且在没有和其他团队达成一致的情况下不应该修改。
Shared Kernel, Ward Cunningham 的 DDD wiki
所以基本上,它可能是任何类型的代码:领域层代码、应用层代码、库,随便什么代码。
然而,在我的这份心智地图里,我将它当做一些特定类型的代码的子集。在我的心智地图里,共享内核包含的是领域层和应用层的代码,这些代码会在限界上下文之间共享,让这些上下文可以互相通信。
这意味着,例如,一个或多个限界上下文触发的事件可以在其它的限界上下文里被监听到。需要和这些事件一起共享的还有它们用到的所有数据类型,例如:实体 ID、值对象、枚举,等等。事件不应该直接使用像实体这样的复杂对象,因为将它们序列化到队列中或是从队列中反序列化时都会遇到一些问题,所以共享的代码不应该太宽泛。
当然,如果我们手中的是一个由不同语言开发的微服务组成的多语言系统,共享内核必须是描述性的语言,格式是 json、xml、yaml 或者其它,这样所有的微服务都能理解。
因此,共享内核就完全和其余的代码以及组件完全解耦了。这样很好,因为这意味着尽管组件耦合了共享内核,但组件之间不再耦合。共享代码可以被清晰地识别出来,并轻松地提取到一个独立的库中。
如果我们决定将一个限界上下文从单体中分离出来并提取成一个微服务,这也会很方便。我对共享代码了然于心,可以轻松地将共享内核提取到一个库中。而这个库即可以安装到单体中,也可以安装到微服务中。
所以回顾一下,在我的心智地图中,应用核心依赖共享内核,共享内核包括了在限界上下文之间共享的领域层和应用层代码。
当语言不够用时…
这样,我们得到了包含同心圆层次的应用代码,而应用核心依赖着支撑所有这些代码的共享内核。
我们还可以说所有代码都依赖它们所使用的编程语言,但我们对这样显而易见的事实熟视无睹。
然而我要抛出这个事实,原因是还有一个问题“当语言结构不够用时我们该怎么办?!”。显然我们会自己创造语言结构,来填补这些语言的瑕疵。随后我会提出下一个重要的问题“我们如何传递这些代码之所以存在地背后原理?我们把它放在哪里?我们如何清晰地表达使用它的时机?使用方法?”
我见过做法的是,我自己也是这样做的,将代码放在一个名为 Utils 或 Commons 的包里。但它最终会变成一个筐子,当我们不知道代码该放在哪儿时,就会一股脑儿全扔进这个筐子里!不同类型的代码,不同用途的代码,还有不同用法(包装在适配器里使用,或是直接使用...)的代码最后都被扔在这里,这个包没有概念性的含义,没有一致性,没有内聚性,一点也不明确,到处充斥着歧义。
我想抛弃 Utils 和 Commons 包!
每一个包都必须在概念上内聚!何时使用包以及如何使用包必须是明确的!不能有任何歧义!
因此,举个例子,如果我们的应用有一些特殊的和 CLI 交互的方式,我们可以把相关代码放在“Acme/App/Infrastructure/Cli/SpecialCli”命名空间下,而不是放在“Acme/Util/SpecialCli”命名空间下。前一个名字告诉我们这个包和 CLI 有关,它是“Acme”公司的应用“App”的“Infrastructure”(基础设施)的一部分。既然它是应用基础设施的一部分,也就是说应用核心中还应该有一个端口,它必须遵循这个端口。
另一种情况是,如果我们发现包是这种语言自己应该/能够具备的一些东西,我们可以把它放在可以体现出这层含义的命名空间之下,比如“Acme/PhpExtension/SpecialCli”。这个名字告诉我们这个包应该被看作是语言自身的一部分,因此其中的代码应该被其它代码像语言结构一样直接使用。但是,如果其它公司依赖这个包时,显然不会傻傻地直接依赖它,而是为它创建端口/适配器,这是更妥善的处理方法,这样他们可以换掉它。然而,如果这个包是我们自己来负责,我们就可以决定把它当成语言的一部分来对待,因为出现寻找替代品的风险的几率要小得多。这里总有一些权衡。
另一个我们可以认为是语言的一部分的例子是 PHP 中的 UUID。我可以不把它想成是语言的一部分,因为每隔一段时间就会有一个新版本并造成一些维护的负担;但它却是一个通用、广泛和一致的概念,足以成为语言的一部分。
所以,为什么不创建一个 UUID 的实现,把它当成 PHP 自身的一部分来使用呢?就像我们使用 DateTime 对象一样?只要实现还在我们的掌控之中,我觉得没有什么坏处。
那么 Doctrine Query Language (DQL) 呢? (Doctrine 是 Hibernate 在 PHP 中的移植) 我们能把 DQL 当成 SQL、Elasticsearch QL 或 Mongo QL 吗?
总结
所以总结一下,我在宏观层面发现了四种主要的代码类型,而且我认为在代码组织中将它们清晰地展现出来,是我们避免最终形成大泥球的关键。

于我而言,不能质疑的真相是架构就在那里,唯一的问题是:它在不在我们掌控之中?!。
因此,让我们清晰地组织好代码,来帮助我们表达架构,全盘或者部分遵循我的心智地图,遵循你自己的心智地图,或者遵循其他人的心智地图都可以,但是请使用一致的推理思路来组织代码,让项目可以使用结构和代码组织来清晰地表达架构。