CNN卷积神经网络之SENet及代码
CNN卷积神经网络之SENet
-
-
-
- 个人成果,禁止以任何形式转载或抄袭!
-
-
- 一、前言
- 二、SE block细节
-
- SE block的运用实例
- 模型的复杂度
- 三、消融实验
-
- 1.降维系数r
- 2.Squeeze操作
- 3.Excitation操作
- 4.不同的stage
- 5.集成策略
- 四、SE block作用的分析
-
- 1.Effect of Squeeze
- 2.Role of Excitation
- 五、总结
- SENET-154的一些细节*
- 六、pytorch代码
个人成果,禁止以任何形式转载或抄袭!
一、前言
《Squeeze-and-Excitation Networks》
论文地址:https://arxiv.org/abs/1709.01507.
SENet以极大的优势获得了最后一届ILSVRC 2017年竞赛图像分类任务的冠军,并在2017年发表 于CVPR上,整篇论文还是清晰易懂的。
卷积神经网络(CNNs)的中心构建块是卷积算子,它使网络能够通过在每个层的局部视野中融合空间和信道信息来构造特征。在本工作中,将重点放在信道关系上,并提出了一种新的体系结构单元,我们将其命名为“Squeeze-and-Excitation” (SE) block,通过显式建模**信道之间的相互依赖关系,自适应地重新校准信道方向的重要性。**如果说之前的Inception网络是在空间方向上增加注意力机制,那么,SENet则是在通道方向增加注意力机制。
二、SE block细节
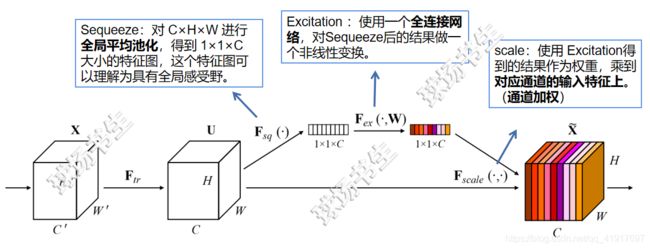
Squeeze: Global Information Embedding。 选择了最简单的聚合技术——global average pooling,注意到这里也可以使用更复杂的策略。
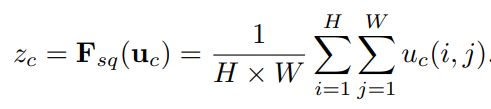
Excitation: Adaptive Recalibration(自适应调整)。为了实现这个功能,需要没满足以下两个条件,
1)它必须灵活(特别是,它必须有能力学习渠道之间的非线性相互作用)
2)它必须学会一种非互斥的关系,因为我们希望确保允许强调多个渠道(而不是强制执行一个one-hot activation)。
因此,选择了sigmoid形式的gating机制:
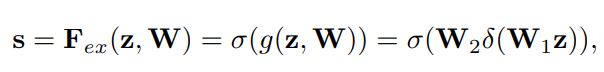
“a bottleneck with two fully-connected (FC) layers around”
为了降低模型复杂度以及提升泛化能力,这里采用包含两个全连接层的bottleneck结构,其中第一个FC层起到降维的作用,降维系数为r是个超参数,然后采用ReLU激活。最后的FC层恢复原始的维度。后面消融实验会有更多介绍,也查看原论文Section 6.1。
rescaling: 将学习到的各个channel的激活值(sigmoid激活,值0~1)乘以U上的原始特征。
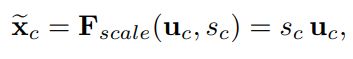
SE block的运用实例
SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以Inception和ResNet为例。对于Inception网络,没有残差结构,这里对整个Inception模块应用SE模块。对于ResNet,SE模块嵌入到残差结构中的残差学习分支中。具体如下图所示:
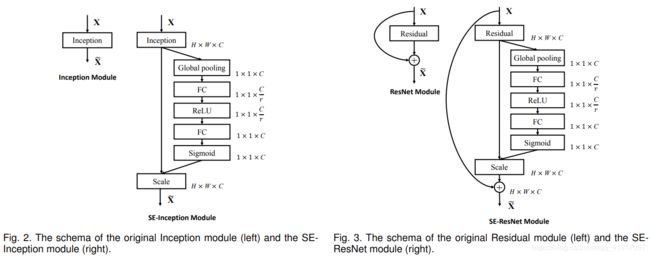
同样地,SE模块也可以应用在其它网络结构, ResNeXt, Inception-ResNet, MobileNet and ShuffleNet等。如下表所示:
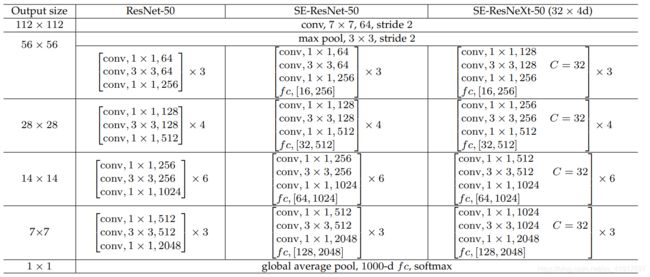
其中,fc后面的[16,256]内表示SE模块中两个全连接层的输出尺寸。
模型的复杂度
SENet构造非常简单,而且很容易被部署,那么,再来看看添加了SE block后,模型的参数到底增加了多少。参照下面的公式:
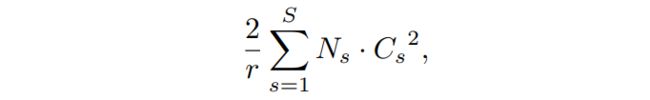
其中r为降维系数,S表示stage数量,Cs为第s个stage的通道数,Ns为第s个stage的重复block量。增加的参数主要来自两个全连接层,两个全连接层的维度都是Cs/rCs ,那么这两个全连接层的参数量就是2Cs^2/r。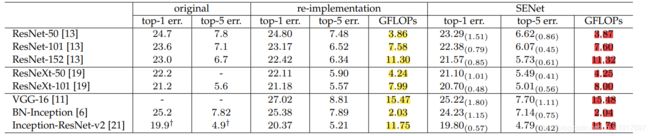

可以看见,参数量会增加一点,计算量增加很少,但网络效果却有很大提升。(图像分类的数据增强以及模型训练过程可以参见原论文Section 5.1)
同时还由此看出,SE的增益效果不仅仅局限于某些特殊的网络结构,它具有很强的泛化性。
三、消融实验
所有消融实验都是在一台机器上的 ImageNet 数据集上进行的(有 8 个 GPU)。 采用 ResNet-50作为骨干架构。根据经验发现,在ResNet架构中,在Excitation操作中去掉FC层的biases,有助于信道依赖关系的建模,并在接下来的实验中使用此配置。
1.降维系数r
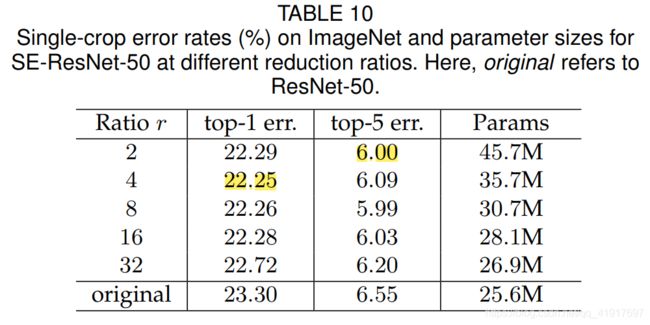
r是一个超参数,它允许我们改变网络中SE block的参数量和计算成本。 为了研究如何权衡性能和计算成本,用SE-ResNet-50对一系列不同的r值进行了实验。表10表明,改变r大小,性能还是比较稳定的。增加的复杂性并不能单调地提高性能,而较小的比率则会显著增加模型的参数大小。设置 r=16 在准确性和复杂性之间取得了很好的平衡。 在实践中,在整个网络中使用相同的比率可能不是最优的(由于不同层扮演着不同角色),因此可以通过调整比率来实现进一步的改进。
2.Squeeze操作
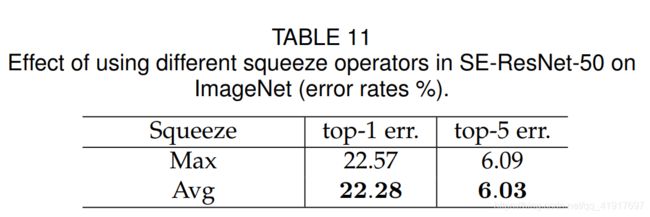
我们研究了使用全局平均池而不是全局最大池作为我们Squeeze操作(由于表现较好,我们没有考虑更复杂的替代方案)。 结果见表 11。 虽然最大池化和平均池化都是有效的,但平均池化的性能略好。 然而,我们注意到SE block的性能对特定Squeeze操作的选择相当健壮。
3.Excitation操作
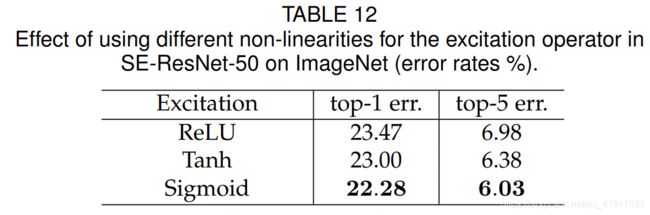
接下来,我们评估了激活函数的选择。 我们考虑两个进一步的选择:ReLU和tanh,并尝试用这些代替sigmoid。 结果见表12。 我们看到,将sigmoid替换为tanh稍微恶化了性能,而使用ReLU则急剧恶化,能够导致SE-ResNet-50 的性能下降到 ResNet-50 基线以下。 这表明,为了使SE block有效,仔细构造Excitation是很重要的。
4.不同的stage
我们通过将 SE block集成到 ResNet-50 中,一次只加入到一个stage中,探讨SE block在不同阶段的影响。具体来说,我们将 SE block添加到中间阶段:stage_2、stage_3 和 stage_4,并在表 13 中报告结果。我们观察到,SE block在体系结构的每个阶段引入时都会带来性能提升。 此外,SE block在不同阶段产生的收益是互补的,因为它们可以有效地结合起来,以进一步提高网络性能。
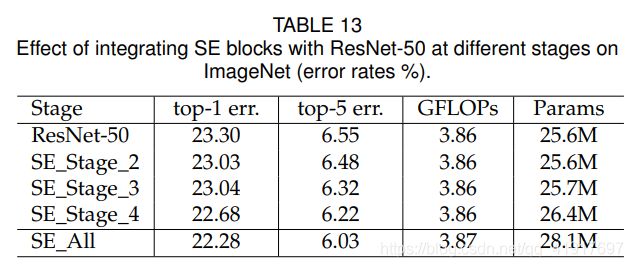
个人感觉看起来越到高层,效果越好,这个有待更多实验。
5.集成策略
最后,我们进行了一项消融研究,以评估 SE block集成到现有体系结构时位置的影响。 除了所提出的 SE 设计外,我们还考虑了三个变体:
1)SE-PRE block
2)SE-POST block
3)SE-Identity block
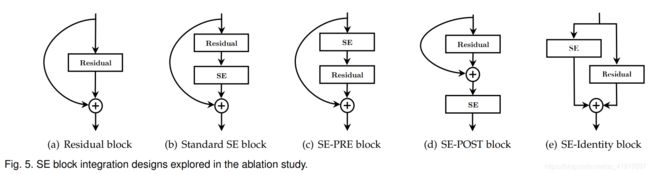
每个变体的性能见表14。 我们观察到,SE-PRE、SE-Identity 和所提出的 SE block在使用时表现得同样好。在 SE-POST block中,性能会下降。 该实验表明,SE 单元产生的性能改进对它们的位置相当稳健,只要它们在分支聚合之前应用。
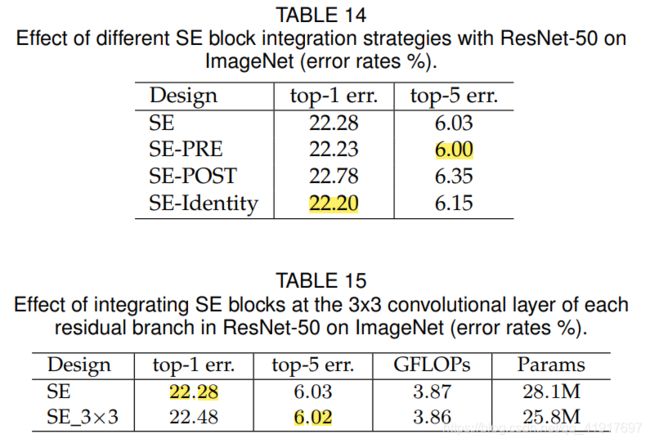
在上述实验中,我们还构造了一个变体,它将 SE block移动到残差单元内,直接放置在 3x3 卷积层之后。 由于3x3 卷积层具有较少的信道,相应的 SE block引入的参数也减少了。 表15 表明,SE_3x3 变体比标准 SE block具有更少的参数,达到了相当的分类精度。 可以预计,通过为特定体系结构定制 SE block的使用,将可以实现进一步的效率增益。
四、SE block作用的分析
对深度神经网络进行严格的理论分析仍然具有挑战性,因此,作者采取一种经验方法来检查 SE block所起的作用,目的是至少对其实际功能有一个基本的理解。
1.Effect of Squeeze
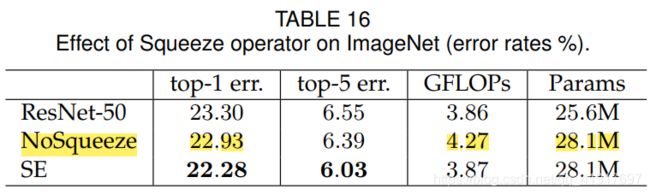
为了评估Squeeze产生的全局信息是否在性能中起着重要作用,我们实验了 SE block的一个变体,它添加了相同数量的参数,但不执行全局平均池。 具体来说,删除了池化,并将两个FC层替换为相应的 1x1 卷积,具有相同的信道尺寸。在实践中,深度网络的后期层通常具有(理论)全局性。可以观察到,全局信息的使用对模型的性能有显著的影响,强调了Squeeze操作的重要性。此外,与无Squeeze设计相比,SE block计算量还小一点。
2.Role of Excitation
这里主要是为了了解excitations在不同类的图像,以及在一个类的图像之间如何变化的。
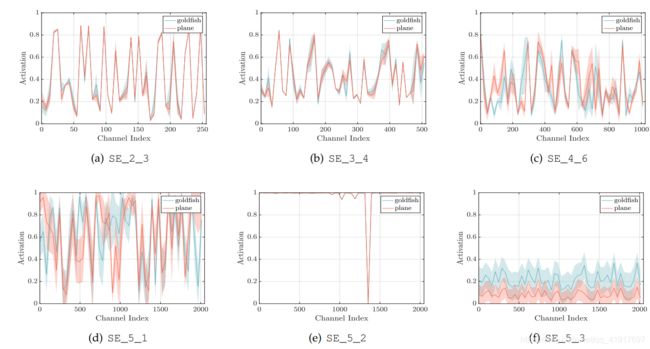
1)不同类之间的分布在网络的早期层非常相似,例如SE_2_3。这表明,在早期阶段,feature channels 可能会被不同的类别所共享。
2)随着深度的增加,不同的类别对特征的鉴别值表现出不同的偏好,每个通道的值会变得更加特定于类别,例如SE_4_6和SE_5_1。这些观察结果与之前的研究结果一致,即较早的层次特征通常更普遍,而较晚的层次特征则表现出更高层次的特异性。
3)在网络的最后阶段观察到一个有点不同的现象。SE_5_2表现出一种有趣的趋向于饱和状态的趋势,在这种状态下,大多数的激活都接近于1。当所有激活的值都为1时,SE block将简化为identity。在 SE_5_3 中的网络结束时(紧接在分类器之前的全局池),在不同的类上出现了类似的模式,只不过在规模scale上略有变化。该结果表明,通过去除最后阶段的SE block,只会导致性能的边际损失,可以显著降低附加参数计数。
五、总结
SE block虽然带来少量(真的比较少)的参数量和计算量,却让性能提升不少。Squeeze操作需要全局信息效果才好,值得仔细构造Excitation(这里用sigmoid效果较好)。降维系数r可以微调,不是严格的单调。SE block要放在在分支聚合之前,同时在体系结构的每个阶段引入时都会带来性能提升。
SENET-154的一些细节*
SENet-154的构建是将SE块合并到64×4d ResNeXt-152的修改版本中,该版本采用ResNet-152的块堆叠策略,扩展了原来的ResNeXt-101。
其他差异(除了使用SE块)如下:
(a)每个bottleneck building block的前1 × 1个卷积通道的数量减半,以降低模型的计算成本,同时性能下降最小。
(b)将第一个7×7卷积层替换为3个连续的3 × 3卷积层。
© 用stride=2 3×3 卷积代替stride=2 1×1的下采样,以保存信息。
(d)为了减少过拟合,在分类层之前插入一个dropout layer (dropout ratio为0.2)。
(e)在训练过程中使用了标签平滑正则化。
(f)所有BN层的参数都在前几个训练周期进行了冻结,以确保训练和测试之间的一致性。
(g)训练是在8台服务器(64个gpu)并行执行的,以启用大批处理大小(2048)。初始学习率设置为1.0。
六、pytorch代码
class SEModule(nn.Module):
def __init__(self, channels, reduction=16, act_layer=nn.ReLU, min_channels=8, reduction_channels=None,
gate_layer='sigmoid'):
super(SEModule, self).__init__()
reduction_channels = reduction_channels or max(channels // reduction, min_channels)
self.fc1 = nn.Conv2d(channels, reduction_channels, kernel_size=1, bias=True)
self.act = act_layer(inplace=True)
self.fc2 = nn.Conv2d(reduction_channels, channels, kernel_size=1, bias=True)
#self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
x_se = self.fc1(x_se)
x_se = self.act(x_se)
x_se = self.fc2(x_se)
x_se = x_se.sigmoid()
return x * x_se
上一篇:CNN卷积神经网络之DenseNet.
下一篇:CNN卷积神经网络之ResNeXt
个人成果,收藏即可,禁止以任何形式转载!