爬虫笔记14:bs4简介、bs4的快速入门、find()和find_all()方法
一、bs4简介
1、基本概念
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的网页信息提取库。
2、有什么作用?
解析和提取网页中的数据
3、有什么意义?
随着网站的种类增多,去寻找最适合解决这个网站的技术。
正则表达式有的时候不太好写,容易出错;
xpath 记住一些语法://*[@id=“content”]/div[2]/div/div/p[2]/span
bs4的特点:只需要记住一些方法就可以了。
二、bs4源码分析(github下载源码)
源码当中有一些小图标:
c :Class 类
m :Method 方法
f :Field 字段
p :Property 装饰器
v :Variable 变量
三、bs4的快速入门
1 、安装
先:pip install lxml
再:pip install bs4
2、 导入
from bs4 import BeautifulSoup
3 、创建soup对象
soup = BeautifulSoup(tag)
4、 可以使用对象当中的方法
例如: find() 、find_all()
案例:
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
结果:

UserWarning:没有明确指定解析器,所以我使用这个系统的最佳HTML解析器(“lxml”)。这通常不是问题,但如果您在另一个系统或不同的虚拟环境中运行此代码,它可能使用不同的解析器,行为也可能不同。
由此,我们指定解析器为‘lxml’。即:
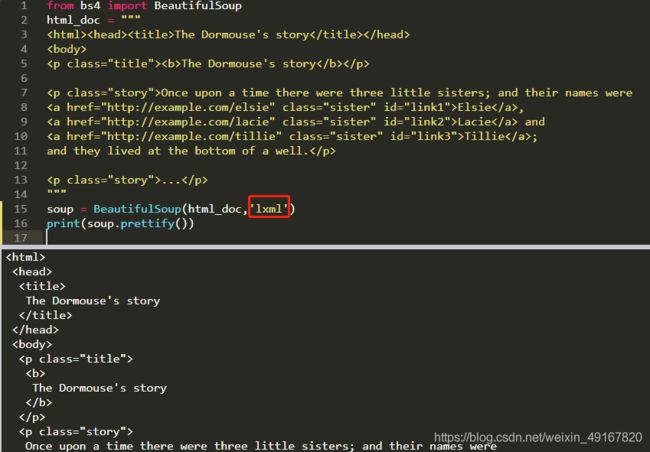
prettify中文意思是,美化、修饰。
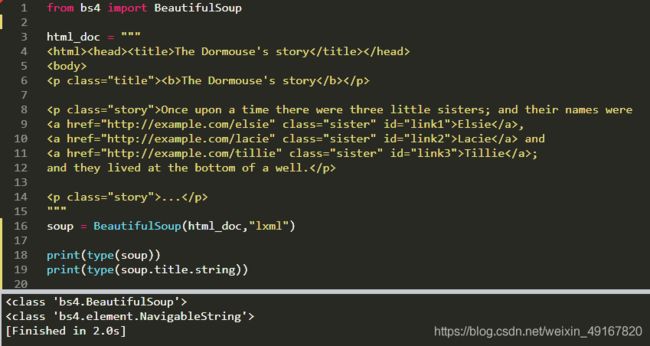
需求1:爬取title标签里面的文本数据 The Dormouse’s story
解决方法:通过标签来定位数据,然后再解析数据。
(string获取标签里面的内容)

需求2: 找到所有的p段落

解决方法:find_all返回的是一个列表。

需求3:找到a标签当中的href链接
(观察html_doc知道:href是a标签的属性;所以这个需求就是怎样拿到a标签的属性值)
解决方法:get()
解决步骤:通过标签来定位数据,然后再解析数据。
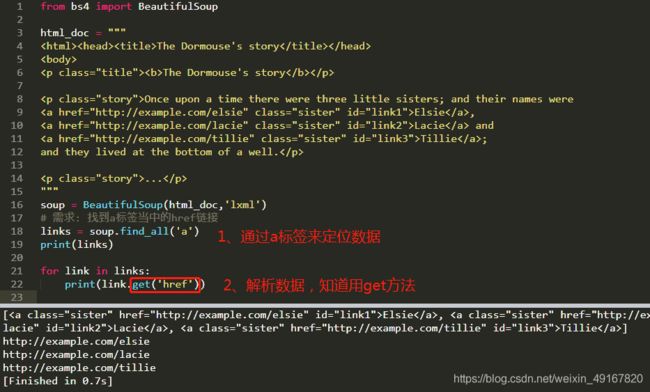
也可以用:link[‘href’],即:link.get(‘href’)或link[‘href’]
总结:
soup = BeautifulSoup(html_doc,‘lxml’)
r= soup.find_all(‘p’) 通过标签名定位到数据段,再用for循环或者列表位置索引得到具体数据,如下
The Dormouse's story
要得到p标签的内容即The Dormouse’s story,用string方法;
要得到p标签的属性值,即class属性值为"title",用get方法。

四、bs4的种类
tag : 标签
NavigableString : 可导航的字符串
BeautifulSoup : soup对象
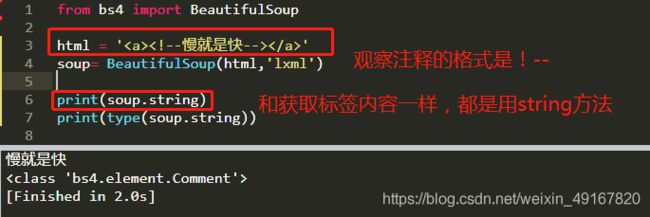
Comment : 注释
1、标签

2、soup对象、可导航的字符串
3、注释
五、遍历文档树
contents 返回的是一个所有子节点的列表;
children 返回的是一个子节点的迭代器,所以可以用for循环来显示;
descendants 返回的是一个生成器遍历子子孙孙
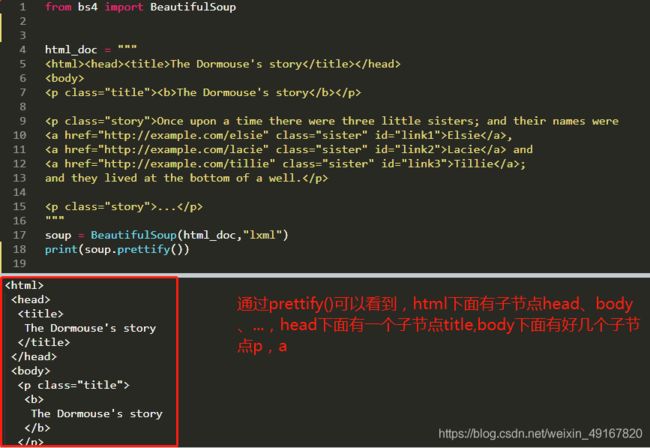
由此:

1、观察children的结果

2、观察descendants的结果

六、string、strings、stripped_strings
string:获取标签里面的内容
strings :返回是一个生成器对象用来获取多个标签内容
stripped_strings :和strings基本一致,但是它可以把多余的空格去掉
1、string

2、strings

注意:soup.html.strings和soup.html.string的不同

3、stripped_strings

结果中,没有了前后的空白。
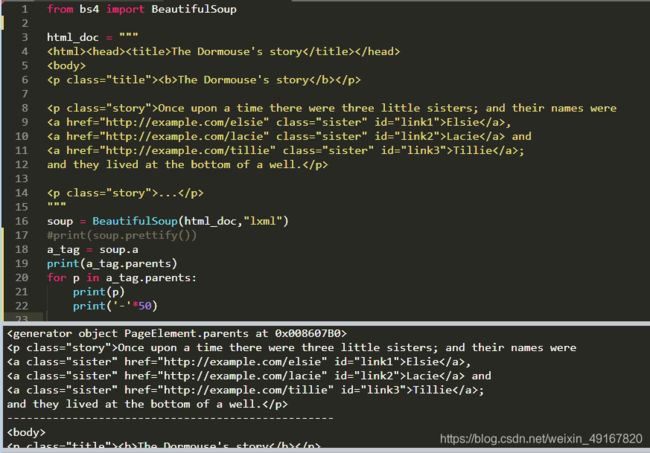
七、parent、parents
parent:获得父节点
parents:返回一个生成器,以获取所有的父节点
1、parent

2、parents
八、next_sibling、previous_sibling、next_siblings、previous_siblings
next_sibling :下一个兄弟结点
previous_sibling: 上一个兄弟结点
next_siblings :下一个所有兄弟结点
previous_siblings:上一个所有兄弟结点

九、重点掌握:find()和find_all()方法
1、字符串过滤器

从结果可以看出来,find只找第一个;而find_all是找全部,并以列表的形式返回。(soup.find(‘a’)和soup.a效果一样,都是找第一个)
2、列表过滤器(同时找多个标签)

3、获取所有class等于even的tr标签
trs = soup.find_all('tr',class_='even') #class被Python团队所使用了 class_ 等价于class
for tr in trs:
print(tr)
或者:
trs = soup.find_all('tr',attrs={'class':'even'})
for tr in trs:
print(tr)
4、获取id等于test; class等于test的a标签的数据
lst = soup.find_all('a',id='test',class_='test')
for a in lst:
print(a)
或者
lst = soup.find_all('a',attrs={'id':'test','class':'test'})
for a in lst:
print(a)
结果:
![]()
补充代码:
from bs4 import BeautifulSoup
html = """
职位名称
职位类别
人数
地点
发布时间
22989-金融云区块链高级研发工程师(深圳)
技术类
1
深圳
2017-11-25
22989-金融云高级后台开发
技术类
2
深圳
2017-11-25
SNG16-腾讯音乐运营开发工程师(深圳)
技术类
2
深圳
2017-11-25
SNG16-腾讯音乐业务运维工程师(深圳)
技术类
1
深圳
2017-11-25
TEG03-高级研发工程师(深圳)
技术类
1
深圳
2017-11-24
TEG03-高级图像算法研发工程师(深圳)
技术类
1
深圳
2017-11-24
TEG11-高级AI开发工程师(深圳)
技术类
4
深圳
2017-11-24
15851-后台开发工程师
技术类
1
深圳
2017-11-24
15851-后台开发工程师
技术类
1
深圳
2017-11-24
SNG11-高级业务运维工程师(深圳)
技术类
1
深圳
2017-11-24
"""
soup = BeautifulSoup(html,"lxml")
# 1 获取所有的tr标签
# trs = soup.find_all('tr')
# for tr in trs:
# print(tr)
# print('*'*80)
# 2 获取第二个tr标签的内容
# tr = soup.find_all('tr')[1]
# print(tr)
# 3 获取所有class等于even的tr标签
# trs = soup.find_all('tr',class_='even') #class被Python团队所使用了 class_ 等价于class
# for tr in trs:
# print(tr)
# print('*' * 80)
#或者
# trs = soup.find_all('tr',attrs={'class':'even'})
# for tr in trs:
# print(tr)
# print('*' * 80)
# 4 获取id等于test class等于test的a标签的数据
# lst = soup.find_all('a',id='test',class_='test')
# for a in lst:
# print(a)
#或者
# lst = soup.find_all('a',attrs={'id':'test','class':'test'})
# for a in lst:
# print(a)
# 5 获取所有a 标签的href属性
# a_lst = soup.find_all('a')
# for a in a_lst:
# href = a.get('href')
# print(href)
# for a in a_lst:
# href = a['href']
# print(href)
# 6 获取所有的职位信息
# trs = soup.find_all('tr')[1:]
# for tr in trs:
# tds = tr.find_all('td')
# job_name = tds[0].string
# print(job_name)