Day217.项目总结 -谷粒学院
谷粒学院
项目的功能点
一、后台管理系统功能
1、登录注册功能(SpringSecurity框架)
2、权限管理功能
- 菜单管理:CRUD
- 角色管理:CRUD、批量删除、为角色分配菜单
- 用户管理:CRUD、为用户分配角色
- 表和表的关系:使用五张表【用户表、角色表、菜单表、用户角色中间表、角色菜单中间表】
3、讲师管理模块
多条件分页查询、CRUD
4、课程分类模块
- 添加课程分类
读取Excel里的课程数据,添加到数据库中,通过easyExcel
- 课程分类列表
使用树形结构显示课程分类列表
5、课程管理模块
- 课程列表功能
- 添加课程
- 添加小节时,可以上传课程视频
课程发布的流程:填写课程基本信息、添加课程大纲(章节和小节)、课程信息确认、最终发布
*课程如何判断是否已经发布?
通过给数据库设置字段status来判断他现在的状态
*课程添加过程中,中途把课程停止添加,重新去添加新的课程,如何找到之前没有发布完成的课程,继续发布呢?
到课程列表中选择未发布的课程状态,来查询,里面会有编辑看课程信息,然后去继续编辑发布完成
6、统计分析模块
- 生成统计数据
- 统计数据的图标显示
7、走马灯模块
- 添加和删除
二、前台系统功能
1、首页数据显示
- 显示走马灯功能
- 显示热门课程
- 显示名师
2、注册功能
- 获取手机验证码
3、登录功能
- 普通登录
*你项目使用的是SSO(单点登录)实现登录的吗?是怎么实现的?
我使用的是token的方式,用户登录成功后,根据相关的信息生成token,然后返回给cookie,他每次访问的时候都会从请求头中获取token的值,并解析获取用信息,判断是否已经登录
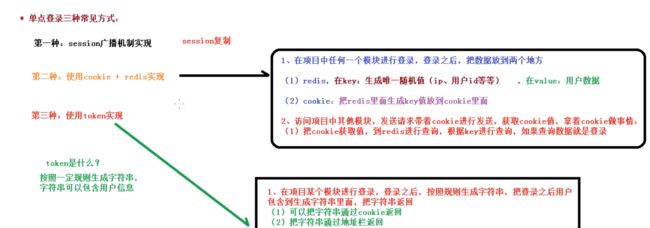
*你使用什么方式生成Token的?
使用Jwt生成token字符串
*Jwt有几部分组成,分别为什么?
三部分组成,分别为:jwt头、有效载荷(用户信息)、签名哈希(防伪标志)
*你登录功能的实现流程是什么?
调用登录的接口,会返回一个token字符串,把token字符串放到cookie中,创建前端拦截器进行判断,如果cookie里包含token字符串,把token放到header中。调用接口会从header中取值到token,根据token值获取到用户信息,然后在页面中进行显示
- 微信扫码登录
*OAuth2是什么?
只是一种解决方法,按照一种规则,但是具体是什么规则,没有规定
他是一种方案,但不是一种协议

*你是如何获取扫码人微信信息的?
扫码后,微信会返回两个值code和state;然后拿着这个code去请求微信的固定地址,获得两个值access_token访问凭证和openid每个微信的唯一表示;然后拿着这两个再去请求微信的一个固定地址获取到扫码人的信息
4、名师列表功能
5、名师详情功能
6、课程列表功能
- 多条件查询分页列表功能
7、课程详情功能
- 课程信息显示(包含基本信息、讲师信息、分类信息、大纲信息)
- 判断课程是否需要购买
8、课程详细视频在线播放功能
阿里云视频点播、阿里云播放器
9、课程支付功能
- 生成课程订单
- 生成微信支付二维码
- 微信最终支付
*你的微信支付功能的流程你说说?
如果课程是收费课程,点击立即购买,生成课程订单;点击订单页面中的去支付,生成微信支付二维码;使用微信区扫秒二维码实现支付;支付之后,每个3秒查询支付状态(是否支付成功),如果没有支付成功就等待,如果支付成功之后,修改订单状态,向支付表中添加记录
项目的技术点
一、前后端分离开发
后端写接口,前端调后端接口得到数据并显示
二、项目使用【前端】技术
1、vue
-
基本语法
-
指令:
- v-bind 简写
: - v-model
- v-for
- v-if
- v-html
- v-bind 简写
-
生命周期:
- created(),页面渲染之前
- mounted(),页面渲染之后
-
绑定事件:
-v-on 简写@ -
ES6规范,通过babel转成ES5,框架自带
2、Element-UI
3、Nodejs
Js运行环境,不需要浏览器直接运行代码,模拟服务器效果
4、NPM
包管理工具,类似Maven
- npm命令
- npm init初始化
- npm install 依赖名
5、Babel
转码器,ES6转换ES5代码
6、前端模块化
通过一个页面或js去调用另外一个页面的js文件的方法
ES6语法不能在nodejs中直接使用,需要通过babel编译成ES5再执行
7、后台系统用vue-admin-templete
基于vue、Element-ui、9528端口
8、前台系统用Nuxt
基于vue、3000端口
服务器渲染技术
9、Echarts
图标工具
百度捐给aprch
*你能做全栈吗?
不要直接回答能或不能;
说:项目中有80%的后端都是我写的,前端都是cv的,对于前端技术有所了解
三、项目使用【后端】技术【1】
1、微服务架构
将项目拆分为独立的模块,每个模块都有其端口号,模块与模块之间没有关系,是通过远程调用实现
2、SpringBoot
*SpringBoot是什么东西?
SpringBoot本质就是spring,只是快速构建Spring工程的脚手架
-
细节:
- 启动类包扫描机制
从外往里扫,也可以设置扫描机制,通过
@ComponentScan(包路径)- 配置类
-
SpringBoot配置文件类型
- properties
- yaml
-
配置文件加载机制
- 先bootstrap
- 再properties或yaml
- 再对应的环境如:dev、test、prod
3、SpringCloud
- 是很多框架的总称,基于springboot实现
- 组成的框架由:
- eureka服务注册,nacos
- OpenFeign服务调用
- Hystrix熔断器
- Gateway网关
- Config配置中心,nacos
- Bus消息总线,nacos
- 项目中,使用阿里巴巴nacos,代替springcloud一些组件
- Nacos
- 注册中心
- 配置中心
- Feign
- 服务调用,一个微服务调用另外一个微服务,实现远程调用
- 熔断器
- Gateway网关,之前是zuul
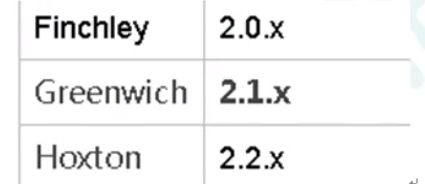
- 版本
4、MyBatisPlus
- MyBatisPlus就是对MyBatis的增强,本身并没改变
- 自动填充
- 乐观锁
- 逻辑删除
- 代码生成器
5、EasyExcel
- 阿里巴巴提供操作Excel工具,效率高,代码简洁
*为什么他效率高,代码简洁?
因为他封装了poi进行封装,采用SAX方法(一行一行操作)进行解析
Dom:一次将所有数据放进内存中来
- 项目应用在添加课程分类,读取excel数据
三、项目使用【后端】技术【2】
1、SpringSecurity
-
项目整合框架实现权限管理功能
-
框架组成:
- 认证(登录)
- 授权(对用户授予权限)
- 登录认证过程
*说一说SpringSecurity的登录认证过程?
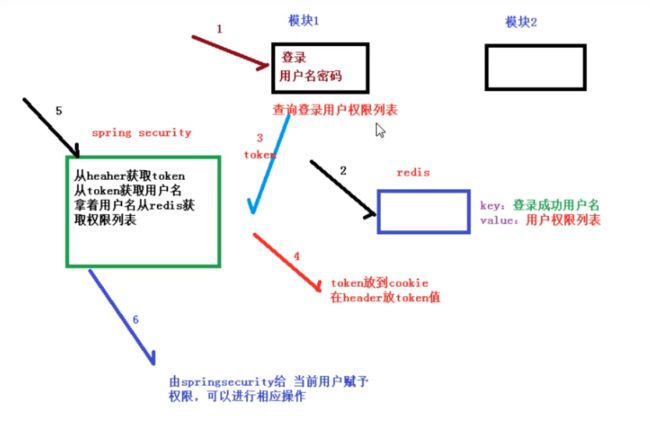
-
代码执行过程
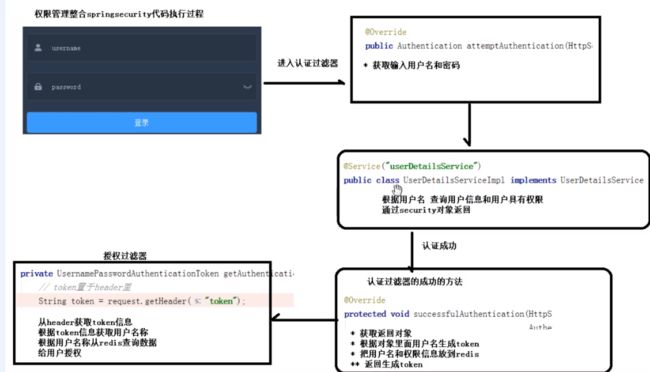
2、Redis
- 首页数据通过Redis做缓存
- Redis数据类型:
- Set
- List
- Hash
- String
- zset
*Redis做缓存,什么样的数据适合使用Redis做缓存?
经常访问,但不经常修改的数据;如主页
3、Nginx
- 方向代理服务器
- 请求转发、负载均衡、动静分离
4、OAuth2+JWT
- 针对特定问题的解决方案
- Jwt制定一种规则生成字符串,包括:三部分
- JWT头
- 有效载荷(用户信息)
- 防伪标志
5、HttpClient
- 模拟浏览器,请发请求响应的工具
- 项目中应用场景:微信登录获取扫描人信息,微信支付查询支付状态
6、Cookie
- 特点:
- 客户端技术,存储在浏览器、客户端中
- 每次发送请求,都会带着cookie
- cookie有默认有效时长,默认关闭浏览器就不存在了,也可以设置时长,会话级别
7、微信登录
上面有讲了
8、微信支付
上面有讲了
9、阿里云OSS
- 文件存储
- 添加讲师,上次讲师头像
10、阿里云视频点播
- 视频上传、视频删除、视频播放
- 整合阿里云视频播放器播放
- 使用视频播放凭证播放
11、阿里云短信服务
- 注册时,发送手机验证码,存储到redis中校验
12、Git
- 代码提交到远程的Git仓库中
13、Docker+Jenkins
- 手动打包
- idea工具打包
- 自动化部署过程
项目遇到的问题
1、前端问题—路由切换问题
- 多次路由跳转到同一个页面,created()只执行一次
- 解决方案:通过vue监听机制解决

2、前端问题—ES6模块化运行问题
- 使用Babel把ES6代码转换为ES5的代码运行
3、MyBatisPlus生成19位id值问题
- mp生成的ip值为19位,js处理数据类型值时,只处理16位
- 解决方案:将Long改为String类型
4、跨域问题
- 访问协议+ip地址+端口号,三者有任何一个不一样,就会产生跨域问题
- 解决方案:
- 在controller添加注解@CrossOrigin
- 通过Gateway网关解决,写一个配置类
- 上面只能使用一个,不然会失效
5、413问题
- 上传视频时,nginx有上传视频大小限制,如果超过,就会出现413错误
- 413描述:请求体过大
- 解决方案:在Nginx里配置客户端提交文件大小
- 响应状态码:413、跨域403、重定向302
6、Maven加载问题
- Maven加载项目时,不会加载src-java文件夹里面的xml类型文件
- 解决方案:
- 1、复制xml文件到target目录
- 2、在maven中配置,与properties配置文件中指定xml文件夹
项目面试总结
1、项目描述



2、这是一个项目还是一个产品
是一个产品;项目是从0开始搭建的
3、测试要求
首页和视频详情页qps单机qps要求 2000+
经常用每秒查询率来衡量域名系统服务器的机器的性能,其即为QPS
QPS = 并发量 / 平均响应时间
4、企业中的项目(产品)开发流程

5、系统中都有那些角色?数据库是怎么设计的?
前台:会员(学员)
后台:系统管理员、运营人员
后台分库,每个微服务一个独立的数据库,使用了分布式id生成器
6、视频点播是怎么实现的(流媒体你们是怎么实现的)
我们直接接入了阿里云的云视频点播。云平台上的功能包括视频上传、转码、加密、智能审核、监控统计等。
还包括视频播放功能,阿里云还提供了一个视频播放器。
7、前后端联调经常遇到的问题:
1、请求方式post、get
2、json、x-wwww-form-urlencoded混乱的错误
3、后台必要的参数,前端省略了
4、数据类型不匹配
5、空指针异常
6、分布式系统中分布式id生成器生成的id 长度过大(19个字符长度的整数),js无法解析(js智能解析16个长度:2的53次幂)id策略改成 ID_WORKER_STR
8、前后端分离项目中的跨域问题是如何解决的
后端服务器配置:我们的项目中是通过Spring注解解决跨域的 @CrossOrigin
也可以使用nginx反向代理、httpClient、网关
9、说说你做了哪个部分、遇到了什么问题、怎么解决的
问题1:
分布式id生成器在前端无法处理,总是在后三位进行四舍五入。
分布式id生成器生成的id是19个字符的长度,前端javascript脚本对整数的处理能力只有2的53次方,也就是最多只能处理16个字符解决的方案是把id在程序中设置成了字符串的性质
问题2:
项目迁移到Spring-Cloud的时候,经过网关时,前端传递的cookie后端一只获取不了,看了cloud中zuul的源码,发现向下游传递数据的时候,zull默认过滤了敏感信息,将cookie过滤掉了解决的方案是在配置文件中将请求头的过滤清除掉,使cookie可以向下游传递
问题3…
10、分布式系统的id生成策略
https://www.cnblogs.com/haoxinyue/p/5208136.html
11、项目组有多少人,人员如何组成?
不要太教条,说说人一任职务
12、分布式系统的CAP原理
CAP定理:
指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(所有节点在同一时间的数据完全一致,越多节点,数据同步越耗时)
可用性(A):负载过大后,集群整体是否还能响应客户端的读写请求。(服务一直可用,而且是正常响应时间)
分区容错性(P):分区容错性,就是高可用性,一个节点崩了,并不影响其它的节点(100个节点,挂了几个,不影响服务,越多机器越好)
CA 满足的情况下,P不能满足的原因:
数据同步©需要时间,也要正常的时间内响应(A),那么机器数量就要少,所以P就不满足
CP 满足的情况下,A不能满足的原因:
数据同步©需要时间, 机器数量也多§,但是同步数据需要时间,所以不能再正常时间内响应,所以A就不满足AP 满足的情况下,C不能满足的原因:
机器数量也多§,正常的时间内响应(A),那么数据就不能及时同步到其他节点,所以C不满足注册中心选择的原则:
Zookeeper:CP设计,保证了一致性,集群搭建的时候,某个节点失效,则会进行选举行的leader,或者半数以上节点不可用,则无法提供服务,因此可用性没法满足Eureka:AP原则,无主从节点,一个节点挂了,自动切换其他节点可以使用,去中心化
结论:
分布式系统中P,肯定要满足,所以我们只能在一致性和可用性之间进行权衡
如果要求一致性,则选择zookeeper,如金融行业
如果要求可用性,则Eureka,如教育、电商系统
没有最好的选择,最好的选择是根据业务场景来进行架构设计
13、前端渲染和后端渲染有什么区别
前端渲染是返回 json 给前端,通过 javascript 将数据绑定到页面上
后端渲染是在服务器端将页面生成直接发送给服务器,有利于 SEO 的优化
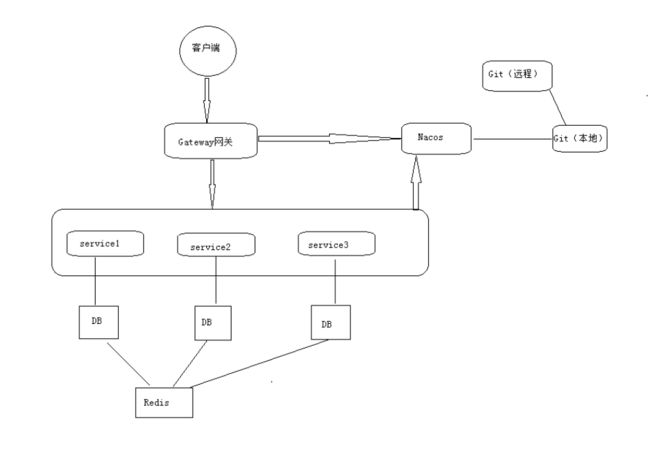
14、能画一下系统架构图吗