Day267.预约系统的性能瓶颈、营销活动无缝切换秒杀活动、预约系统数据迁移方案、高流量下预约系统搭建熔断机制、预约系统redis集群主从&哨兵架构 -Redis的高并发预约抢购系统
一、预约系统的性能瓶颈
1、预约系统应对热门爆品时的缺陷
用户进行预约会涉及到两个维度的数据变更一个是用户信息,一个是SKU信息,如图↓所示:
正常来说这么搞一点问题没有,即便涉及到写数据库,但是每个sku以及用户信息,都可以通过分库分表中间件将各种不同的SKU和用户读写请求分摊到各个机器上,那么每台机器在正常情况下负载都不会很高。但是现在大家有意识的将请求集中在某几个SKU,甚至是某一个SKU这就有问题了,如图↓所示:
↑上图有一个热点爆品出现时,流量就都会聚集到某几个甚至是某一个机器上,能参与到其中分摊流量的节点少的不是一星半点,如果说擅自的改变路由策略,且不说会不会影响到之前正常的业务流转,当下时间也是非常的紧迫,从开发,测试,在上线根本不现实。
现在更严重的是,预约系统作为交易的发生源之一,也就是说预约系统是整个交易链路中比较靠前的一个环节,那么此时在预约系统这里发生了流量倾斜问题,势必也会对整个交易链路中的后续的服务节点产生影响,如图↓所示:
2、总结
可见当一个节点有了负载有压力时,作为同一根绳上的蚂蚱,其他节点也很难幸免遇难,那么在预约服务节点发生流量倾斜时,可能就会导致拉满整个服务系统的响应缓慢,可能导致整个核心交易链路的安全受到威胁,最严重可能会陆续宕机
二、营销活动如何无缝切换为秒杀活动
1、前言
上面说到由于预约系统发生了流量倾斜,极有可能导致整个核心交易链路收到影响威胁,但是事实摆在眼前,得想办法把事情解决才是啊,现在唯一的办法就是 找到一种引流的方式,将这巨额的流量迁移走 。
2、提前取消抢购活动
- 通过 导数工具
现在口罩的巨额流量还在不断地增长,并且距离这场预约活动结束还有数个小时,此时如果在不采取措施预约的人数完全有可能达到几千万。
经过和业务方的磋商,由于口罩的可供应库存已经远远小于预约人数,活动开展下去也没有什么实际意义,遂业务方同意,将活动提前取消,但是要保证已经预约口罩的用户能够正常参与抢购。
在业务方的授意下,提前停止了这一场预约活动。看着监控里的预约人数逐渐走低,悬着的心终于可以放一放了,即便如此大家也丝毫不敢懈怠,因为现在必须将现有的巨额流量进行迁移才行并且要保证这些用户能够正常的参与抢购。
这时候就必须把这些流量迁移到秒杀系统了,怎么迁移呢?简单点说就是为口罩SKU新建单独的秒杀场次并且需要将相关的预约的用户数据迁移到相关秒杀场次的数据库里。如图↓所示:
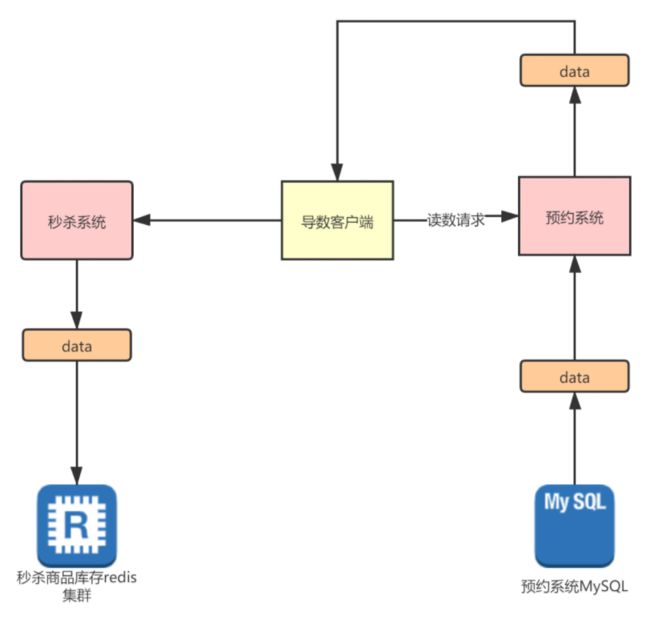
三、预约系统数据的迁移方案
1、古老的迁移方案
如何保证用户无感知迁移历史数据到秒杀系统?
再多年以前,互联网发展还不像如今这般迅猛,用户对网站的用户体验还没有要求如此之高,数据量也不像现在如此之大,那时通常还是服务器关机备份,如图↓所示:

但你想一下,在现在竞争环境如此惨烈的当下,用户对网站要求更多,也更为挑剔了,如图↓:
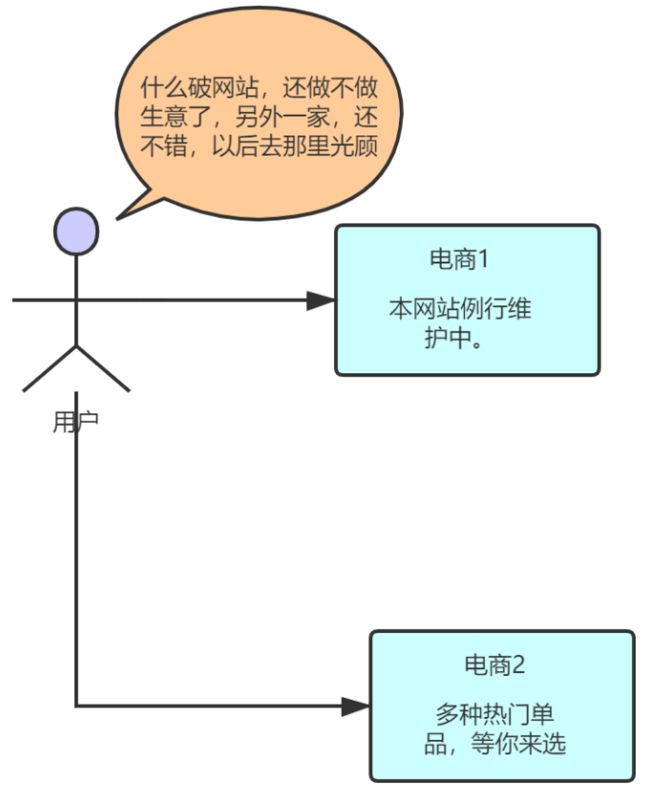
如上图↑那样,会给竞争对手以可乘之机,这也是大忌。
那么有没有什么技术手段,能够做到为用户提供服务的同时,又能进行数据迁移呢?
2、Canal是什么
Cannal : 阿里巴巴开源的一款binLog采集中间件,大致的实现原理,如图↓所示:
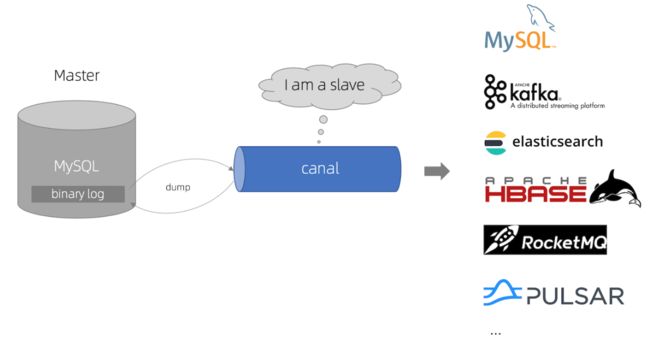
从↑上图中可以看出,它的原理非常的显而易见,就是将自己伪装成Slave,让mysql和它进行主从复制,然后通过Canal将数据同步给其他中间件数据库等
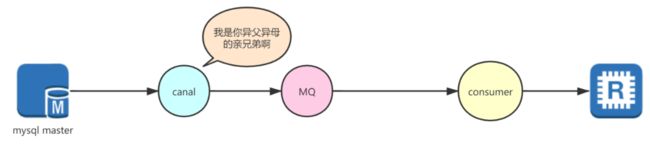
那么此时就非常明了了,因为Canal可以将数据推送给MQ我们完全可以通过自己编写Consumer进行逻辑处理,再同步给redis就行了,如图↓所示:
3、Canal相关知识小补
接下来是有关Canal的一些知识,如图↓:
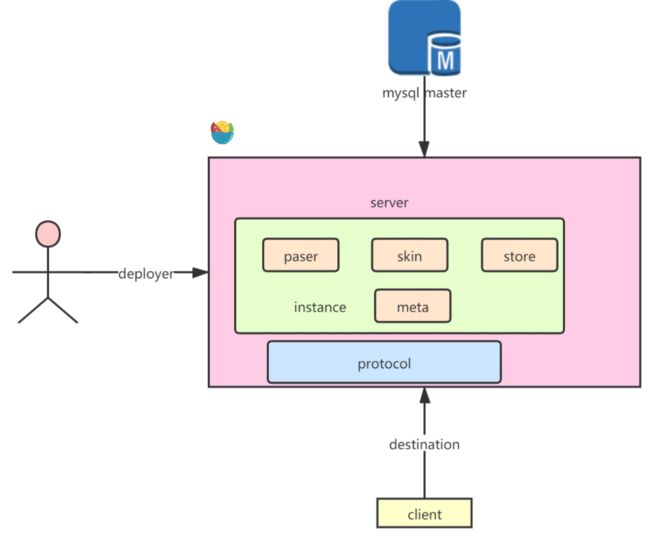
- deployer:对canal进行部署
- paser:对采集到的binlog进行解析
- skin:对解析之后的binlog进行加工转换
- store:对加工之后的数据的存储策略
- meta:源数据维护,例如binlog日志消费到的下标等等
- protocol:canal服务端与客户端的通讯协议
- instance:一个canal服务可以对多台mysql binlog日志进行采集,每一台mysql主实例,都对应一个instance
- destination:决定用哪一个instance为客户端提供服务的核心参数
四、高流量情况下,预约系统如何快速搭建熔断机制?
1、方案的确立
导致这次事件的根本原因是 预约口罩的人数远远大于口罩的可供应库存 ,所以导致了大量无意的流量涌入,并且在已经确认巨额流量继续涌入已无意义的时候,服务窗口仍然继续为用户提供服务,这明显是非常不合理的。
那么问题已经明确了,当口罩的预约人数和口罩库存达到一定的比例范围,就自动结束预约状态
这样把参与抢购的人数控制在一个核心交易链路可以承受的负载范围内,也避免大量占用秒杀系统的资源。
所以经过磋商,现在的业务流程大致如图↓所示:

五、预约系统涉及缓存数据结构
1、前言
上面讲了加入熔断机制,就是给单个预约场景的SKU加上预约人数限制,当到达一定的程度,就直接停止接受预约,本场预约活动就进入了待抢购状态。
2、预约系统的缓存架构
起初以为风险已经过去了,可没想到,预约系统熔断机制上线之后,用户的行为发生了很大的变化。
——因为此时大家都知道如果不及时参与预约的话,就一定参与不了抢购了。
所以当预约活动一开始,广大用户就在第一时间,同时点下预约按钮,流量都是在同一时刻向预约系统袭来,即我们避免了用户在进行口罩抢购时对交易链路的巨大冲击,但是却给预约系统成倍增加了压力。
接下来先看看预约系统的缓存架构,毕竟缓存架构的设计是抗高并发的关键所在。
3、预约系统会涉及哪些需要缓存的数据
首先当用户点击添加预约的时候我们要记录下用户预约之后参与抢购的预约权限,所以在高并发读写的情况下这些数据不能直接写mysql,而是要写进redis中,那么该用什么样的数据结构存储呢?
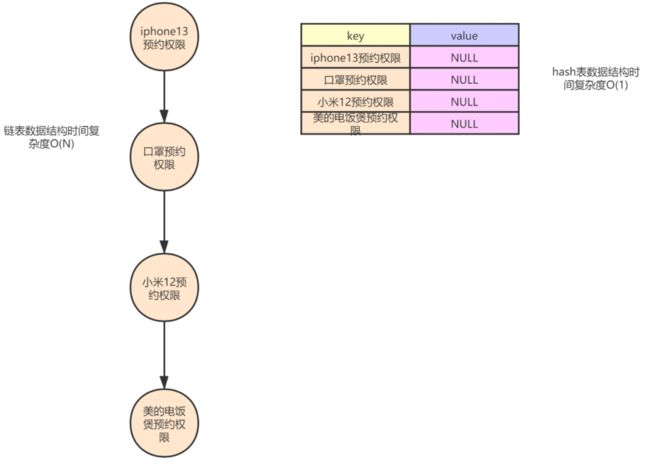
答案是 hash表 ,因为用户的权限只要被记录下来就好,关于权限记录并不关注先来后到的顺序,只需要判断有没有这个元素就好,用hash表查找权限的效率是O(1),而如果用量表则查找效率变为了O(N) 如图↓:
接着在看图↓:
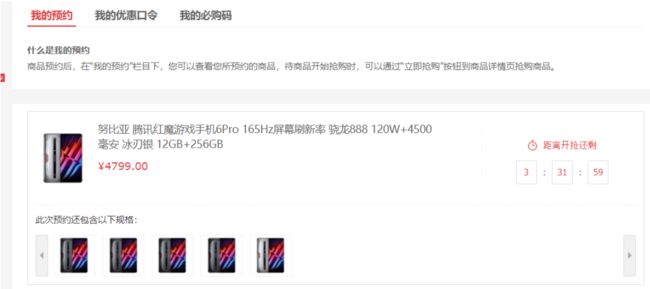
大家看一下这张图,这个用户在“我的预约”里面看到的内容,也就是说当一个用户点击预约后相关的用户预约信息列表里需要看到相关预约信息,按照正常情况是需要在预约用户关系表中维护起来。
多对多关系,多个用户可以预约一个商品,多个商品可以被一个用户预约
但现在由于是一个超级爆品是绝对不能让mysql去进行维护的,那么此时为了不影响参与口罩预约的用户对“我的预约”菜单的浏览,只得在用户对口罩进行预约的时候,将它相关的预约列表也加入到缓存之中:
以hash的数据结构形式,hash名为用户,里面的key对应商品,value对应商品的信息,商品名然后将口罩的预约信息加入到这个预约列表里即可,这个时候就要问了?
那么加载用户的预约信息到缓存之中,不走mysql数据库吗?
说的没错,但大家要清楚一点,就是用户的预约列表信息,其实正常来说是非常少的。因为只要相关的预约场次,一旦到了抢购时间,就会从用户预约列表里删除,这个数据量不会很大,而且又可以通过用户Id区分度很高可以hash分发到多个数据库上,所以这一点压力不会很大,重点是不让mysql承担因预约口罩所进行的写操作。将压力分担到了中间件上,如图↓:
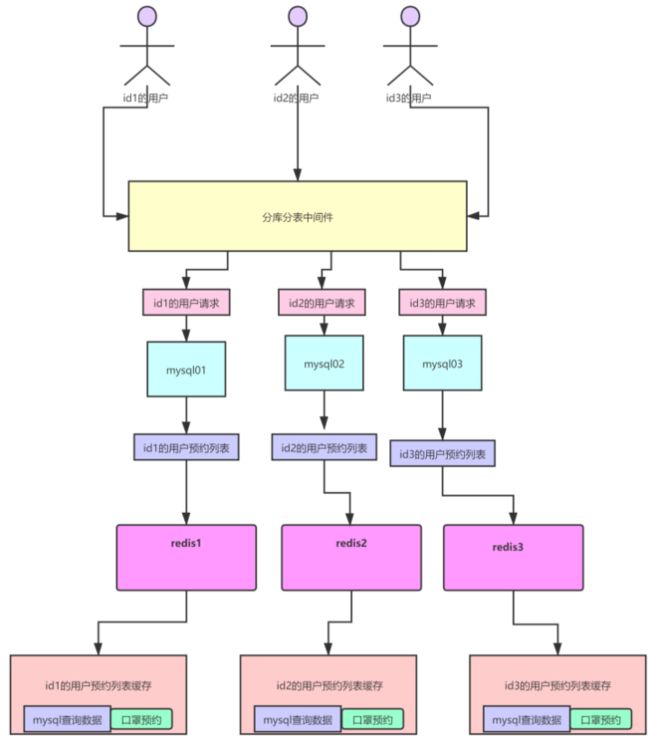
当我们进行预约的时候,一定会进行数据的累加
4、预约系统的关键
所以现在我们就清楚了,关于口罩预约我们最关键的是要对3个数据进行缓存:
- 关于
用户的口罩预约权限进行缓存,用于抢购时的权限检验 - 为了不影响参与口罩预约的用户查看预约列表的体验,同时为了避免因为要进行预约给mysql带来的写压力,所以要将
参与口罩预约用户的预约记录写入缓存 - 因为用户进行预约时,要对
预约人数进行累加,可想而知这个写并发会有多大,而且并发之高,已超越以往任何时候所以一定要缓存。
六、预约系统redis集群主从+哨兵架构
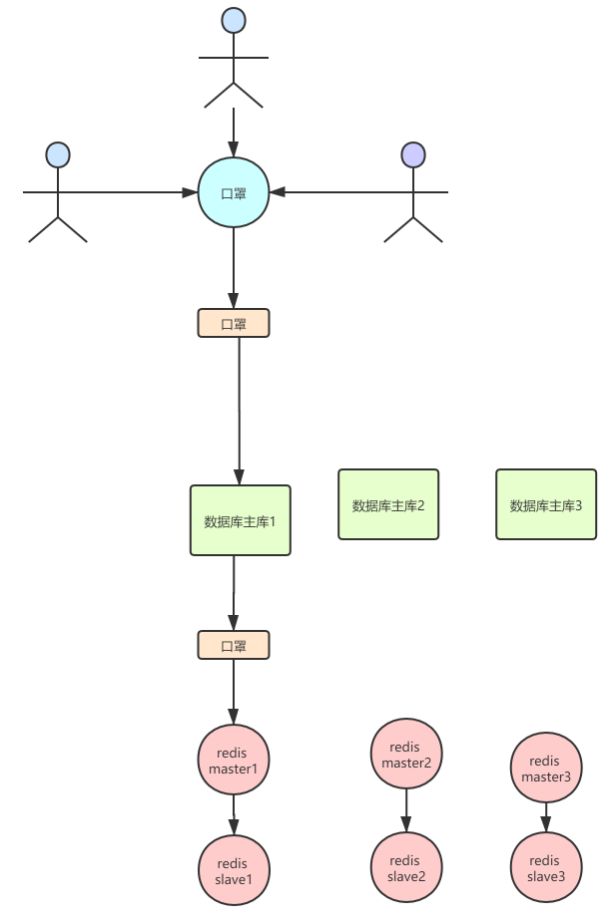
1、集中请求量
首先现在当用户知道如果手速慢了,会导致无法参与抢购,这势必会导致在某一段时间内的请求非常密集,但是按常理来说,有着完备的redis集群按理说不会出现这样的事情,但是大家想想redisCluster是通过访问的key,计与固定的hashSlot的值进行计算,将请求打到不同的机器上,如图↓所示:
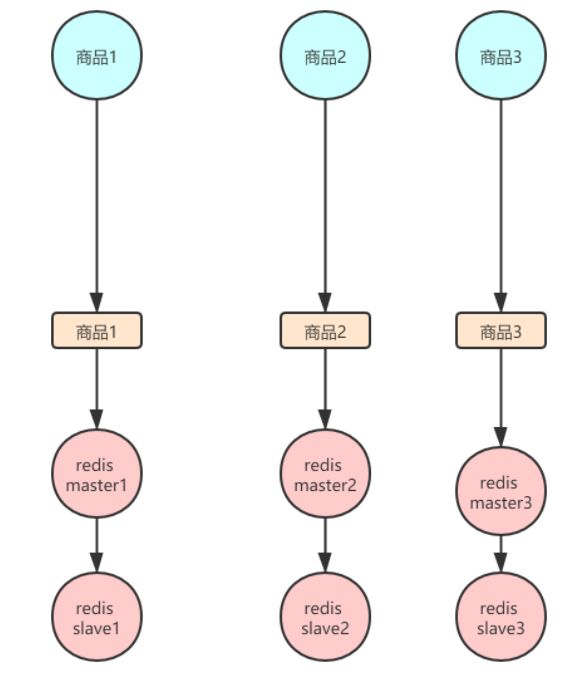
但是大家想一想现在大家 大量的用户的预约目标都是一致的
在这种redis的集群架构下,等于只有一台redis去抗下所有的读和写,slave只是一个单纯的备份而已,此时起不到任何分担压力的作用这是一件非常尴尬的事情,如图↓所示:
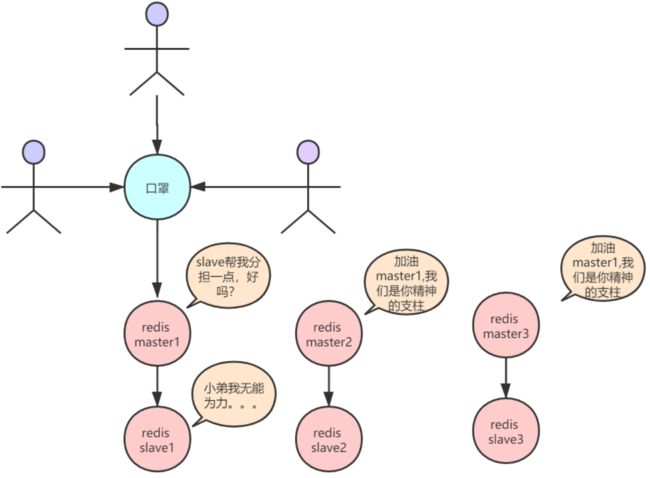
也就是说redisCluster并不能满足我们的需求,那就必须采用一主多从的架构了。
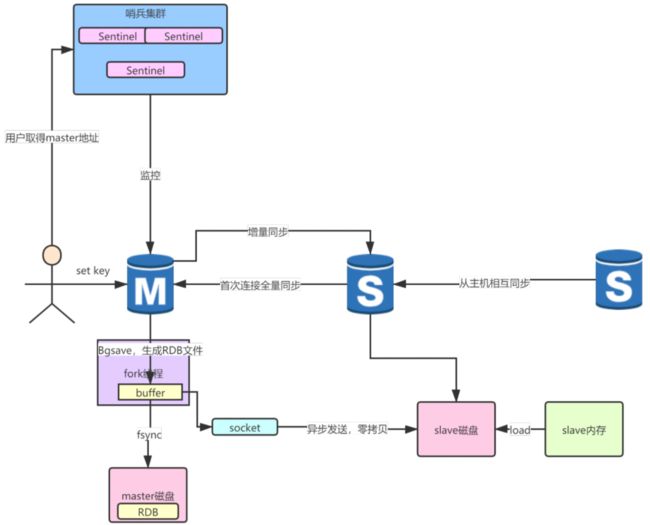
2、redis主从架构知识点
回顾下redis主从架构的内容,如图↓:

从↑上图中可以当slave与master进行主从同步时,首先会进行一个全量同步,这是比较耗时的,然后slave将读取到的全量信息首先写入磁盘,写入磁盘完毕后再将磁盘里全量的RDB文件载入内存。
提醒下redis的主从同步实质上是最终一致性的体现,如果传输过程中受到网络的影响是会导致数据丢失的,如图↓:
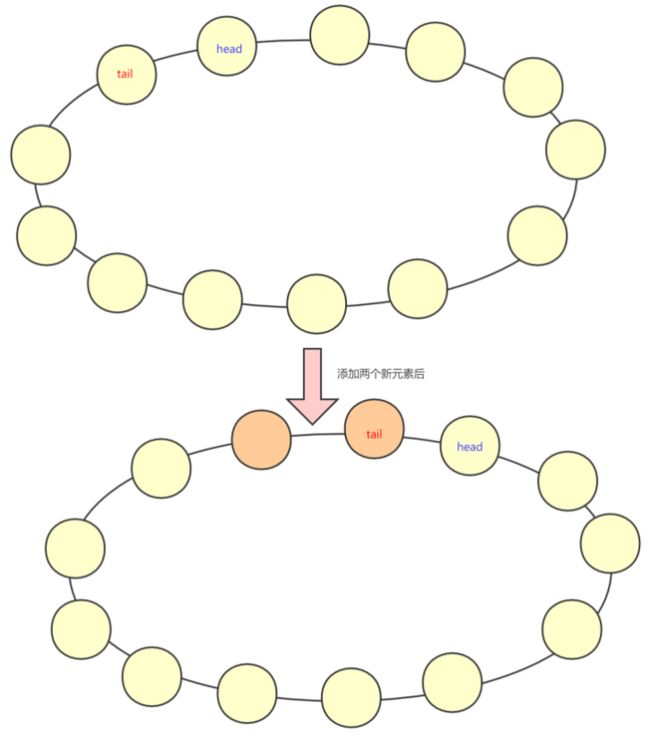
如上图↑,redis存放数据的内存结构是一个环形数组,也就是说如果发现数组空间写满的话,是会将原有的数据覆盖的,如果slave没能及时同步很有可能导致数据的丢失。
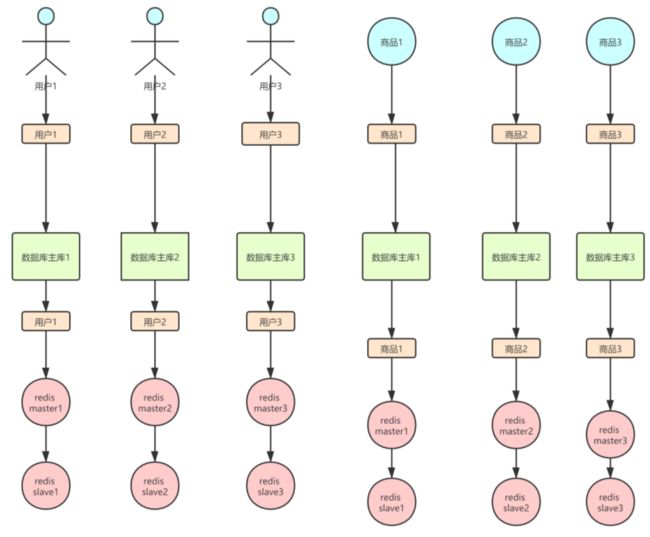
3、预约系统使用redis哪种架构?
过了主从架构的内容,那如果现在用这套redis架构又会如何呢?咱们先来看一下添加预约的主流程,如图↓:

只要一进来都会对口罩的预约信息进行查询,那么在启用了主从架构后SKU的redis集群大致是这样的如图↓所示:
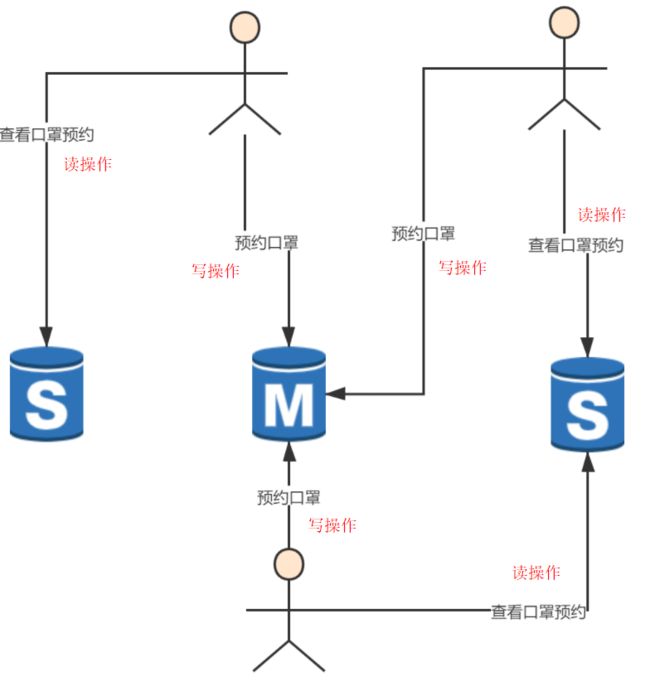
看上图↑,若在一主二从的情况下,可以清楚的看到在启用了主从架构之后,假设6个请求有三个写请求会打到master,读请求被两个slave均摊掉了。
也就是说主机所面临的请求压力十分巨大。虽然是相对读少一些的写请求
但这巨额的写流量也是不敢让人小觑的,所以必须要部署“哨兵”来确保master的安全,如图↓: