第八届泰迪杯优秀论文B题(基于Mask R-CNN 及Yolov4 的电力巡检中绝缘子缺陷研究)
目录
一、 绪论 1
1.1研究背景 1
1.2国内研究现状 1
1.3研究目标及流程 1
二、 数据预处理 3
2.1图像分割 3
2.2图像金字塔 4
2.3数据增强 4
2.4归一化图像大小 5
三、 绝缘子串珠图像分割 6
3.1Mask R-CNN 神经网络结构 6
3.2训练样本的制作及标注 6
3.3Mask R-CNN 训练过程 8
3.3.1部分训练参数设置 8
3.3.2训练过程 9
3.4Mask R-CNN 训练结果分析 9
3.4.1检测及分割过程 9
四、 绝缘子自爆区域识别与定位 11
4.1数据集制作 11
4.2样本标记及分类 11
4.3基于 Yolo-v3 的自爆区域识别与定位 13
4.3.1Yolo-v3 网络结构 13
4.3.2Yolo-v3 训练过程可视化分析 14
4.3.3Yolo-v3 训练结果分析 15
4.4基于 Yolo-v4 的自爆区域识别与定位 17
4.4.1Yolo-v4 网络结构 17
4.4.2Yolo-v4 训练可视化分析 18
4.4.3Yolo-v4 训练结果分析 20
4.5Yolo-v3 与 Yolo-v4 的结果对照 22
4.6小目标预测策略 23
4.6.1高分辨率图像直接预测 23
4.6.2 等比例分割 24
4.6.3 滑动窗口以及 NMS 26
五、 总结与展望 31
参考文献 33
一、绪论
1.1研究背景
架空线路巡检是长期以来,绝缘子串珠经受极其恶劣的天气条件,难免会出现缺陷。为保障我国输配电网正常运行,架空线路巡检是保障人们电路网正常的必要手短。传统的巡线缺陷检测方式为人工巡视,但架空线路巡检常常需要在高处巡检故障区域,工作量多,需要定期打扫脏污的绝缘子,任务强度大,且十分危险。
随着我国科学技术不断发展,无人机技术得到越来越广泛的应用。用无人机配置高分辨率相机获取航拍图像代替人工巡线,可以大大降低了电力巡视的强度,大大提高了恶劣环境下巡检的质量和效率,有效的避免了人工巡视中存在的危险。
1.2国内研究现状
近年来国内针对绝缘子串珠的识别与分割的研究也有不少,基于传统图像识别方法有,黄新波等人[1]提出了基于改进色差法的复合绝缘子图像分割,基于图像颜色特征,将绝缘子不同环境下的图形学颜色进行色度的分割。基于深度学习方法识别分割绝缘子的有,吕易航等人[2]的航拍图像中绝缘子串检测、分割与自爆识别,通过 Faster R-CNN 分割出绝缘子串,通过改进算法的 Faster R-CNN 网络实现绝缘子自爆区域的识别。
1.3研究目标及流程
本文同样以绝缘子为研究对象,采用 2018 年Kaiming He 等人[3]Mask R-CNN v3 神经网络模型作为分割绝缘子串珠主要研究方法,采用堪称yolo 之父的Joseph Redmon 的 Yolo-v3[4]神经网络模型以及 Alexey Bochkovski 最新的 Yolo-v4[5]作为绝缘子自爆区域识别的对比方案。利用现有的 40 张无人机航拍高分辨率原图, 拟解决以下问题:
(1)分割出绝缘子串珠图像,包括玻璃绝缘子、复合绝缘子等类别,获取其掩膜图像。
(2)识别定位绝缘子自爆区域,包括玻璃绝缘子、复合绝缘子等类别,获取其 Boundbox。
针对于任务一,具体研究流程如图 1.1 所示。本文主要研究过程分为三部分。
(1)数据的预处理。包括 40 张图片中不同的绝缘子类型进行划分,通过数据增强提高数据集的数量,通过图像分割优化模型对小目标的识别,并利用 via 2.08 和 Labelme 图像标注工具标记为“insulator”,生成 via 格式的 json 文件, 最终制作标签并对所有数据集按 8:2 比例划分训练和测试集。

==图 1.1 绝缘子串珠分割的研究流程图 ==
(2)绝缘子串珠分割,通过 via2.08 标注好绝缘子串后生成 json 文件,放进 Mask R-CNN 神经网络模型中迭代训练,训练过程中不断的调整参数,如学习率,训练至 loss 函数收敛。
(3)分析与评价。对比预测结果与标准的掩模图,分析改进。利用 Dire 系数进行评价。
针对于任务二,绝缘子自爆区域的具体研究流程如图 1.2 所示。主要研究流程分为三部分。
(1)数据预处理。包含了对原始航拍照片的绝缘子类型的分类,对各个类绝缘子的数量统计,原始图像进行分割或剪裁,图像的数据增强,统一尺寸,用labelme 图像标记工具生成 xml 文件,按 8:2 比例划分训练集和测试集,制作标签。
(2)绝缘子自爆点识别模型训练。通过 labellmg 对绝缘子自爆区域标注为“defect”后生成的 xml 文件,制作 VOC2007 格式,生成标签 label,分别放进
Yolo-v3 和 Yolo-v4 神经网络模型中进行训练,训练过程中观看 loss 函数,不断调整训练参数,如学习率,训练至 loss 函数收敛,且低于 0.06。

图 1.2 绝缘子自爆区域的研究流程图
(3)分析与评价。对比不同方案的测试结果,分别计算出训练中 loss 和 iou 损失变化并画出 loss 和 IOU 损失函数变化曲线,计算测试数据的 map,对比模型识别的精度。利用 IOU 交叠率对绝缘子自爆区域进行评价,对比模型 IOU 定位的准确度。分析比较,得出最好的训练模型。
二、数据预处理
原始图像由 40 张无人机航拍高分辨率图像构成,尺寸多为 7360×4912,由于本文采用 Mask R-CNN 或者 Yolo 神经网络模型训练,都要求图片不能太大, 否则将增加运算的时间消耗,甚至由于显存不足而导致训练中断。
因此需要对数据进行预处理操作。本文采用预处理有图像分割、图像金字塔、数据增强等方法。
2.1图像分割
对于识别的目标占原始图像比例较小的高分辨率图像,采用分割算法,将原始图片等额分割,直至分割后的目标占图片比例适中。如图 2.1 所示为某张原始图片进行 2×2 分割。
==图 2.1 图像 2×2 分割 ==
2.2图像金字塔
对于识别目标占原始图像比例较大的高分辨率图像,采用图像金字塔[6],有效降低图像分辨率。
图像金字塔即将图像比喻成金字塔,层级越高,则图像越小,如图 2.2 所示, 常用的图像金字塔算法有拉普拉斯金字塔和高斯金字塔,拉普拉斯金字塔常用来上采样,即向金字塔的底层图像重建上层图像,预测残差;高斯金字塔常用来下采样,即向金字塔的顶层缩小。
 图 2.2 图像金字塔
图 2.2 图像金字塔
当要从金字塔第 i 层生成第 i+1 层,即向下采样图像时,先用高斯核对进行卷积,删除所有偶数行偶数列,新的图像面积变为原来四分之一。通过调用Opencv 的 PryDown()函数可以不断的进行下采样,直到目标占图片比例适中。
2.3数据增强
本文采用神经网络模型,其实质上训练神经网络模型就是一个不断调参的过程,使之模型能够将具体输入(如图像)映射为输出(标签)。而我们所需要的就是使模型的损失函数尽可能的降低。优秀的神经网络模型需要大量的参数,当我们有大量的参数,就可以提高模型的泛化能力,因此需要提高样本的数据集。本文采用的数据增强方式有水平垂直镜像、随机剪裁、随机旋转、随机改变色度、饱和、明度(HSV)、随机 gamma 变换、随机增加高斯噪声等[7]。如图 2.3 所示。
图 2.3 数据增强
2.4归一化图像大小
由于后续工作需要对数据增强后的图像大小进行标注,若不经剪裁,由于原始图片经数据增强后分辨率大,标注框太小,框内的特征经过网络处理后,会和背景上的杂质斑点相同,不能很好区分,因此需要归一化图像大小。
具体步骤如下,对数据增强后的图片统一调用 Opencv 中 resize 函数,统一为 1024×1024 数据增强后归一化大小如图 2.4 所示,将含有特征区域的图像保留,将含有无特征区域的图片舍弃。

==图 2.4 数据增强后的特征区域 ==
三、绝缘子串珠图像分割
3.1 Mask R-CNN 神经网络结构
Mask R-CNN 总体框架如下图 3.1 所示
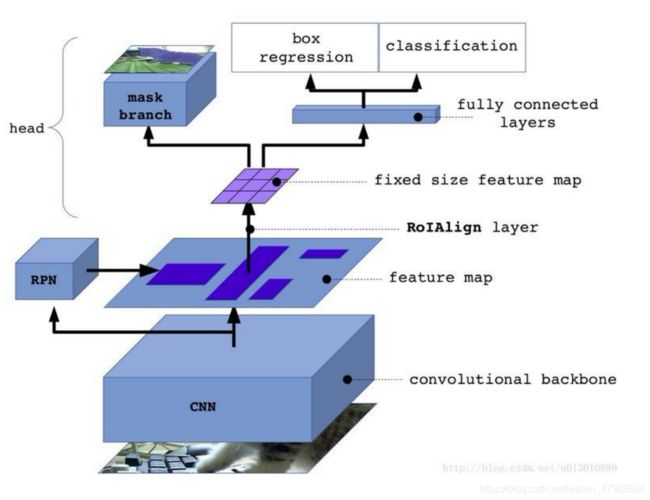
==图 3.1 Mask R-CNN 整体框架 ==
Mask R-CNN 将整个结构划分为 3 个部分,Faster r-cnn、ROIAlign 和 FCN。
算法步骤分为:
(1)输入一幅图片进行预处理
(2)输入到预训练的神经网络模型获取对应 feature map
(3)对 feature map 中每一点预设 ROI,获取多个候选 ROI
(4)将 ROI 送入 RPN 网络进行二值分类和回归。
(5)对剩下 ROI 进行 ROIAlign 操作。
3.2 训练样本的制作及标注
本设计先行制定两种数据集的制作方案,主要分为:
(1)方案一:原图不分割,直接使用高分辨率原图像进行数据增强和标记
(2)方案二:原图分割,再使用分割后的子图进行数据增强和标记按照两种方案获得的数据集如图 3.2 所示。

图 3.2 两种方案的数据集对比
由于方案一的样本图片尺寸过大,且一张图片种的绝缘子串数量众多,标记难度和工作量较大,仅标记了 100 张玻璃绝缘子的样本图作为绝缘子串分割的备用方案。
而方案二的图片经过多等分的图像分割并统一 resize 至 1024p 的分辨率,可获得大量绝缘子串样本,且每张图片上的样本较少且形状较为相似,降低了人工标记的难度。包含 5 种类型的绝缘子串的数据集共有 1343 张图片,各种绝缘子图片如图 3.3 所示,其中白色陶瓷绝缘子 24 张、复合绝缘子 56 张、带盘棕色陶瓷绝缘子 89 张、玻璃绝缘子 487 张、棕色陶瓷绝缘子 187 张和负样本 500 张。
 图 3.3 各种类型的绝缘子图片
图 3.3 各种类型的绝缘子图片
使用网页版的 via2.0.8 进行对数据集的标注,标注结果如图 3.4 所示。

图 3.4 via 标注绝缘子串珠
标记结果生成的带有 via 格式的 json 文件,如下图 3.5 所示
 图 3.5 via 格式的 json 文件
图 3.5 via 格式的 json 文件
其中 filename 是文件名,size 是图片面积大小,一个shape_attributes 代表一个绝缘子,all_points_x,是标注点的 x 坐标数组,all_points_y 是标注点的 y 坐标的数组,两个数组的同一列构成一个点,即标注在图像中的点。
标注后将数据集集按 8:2 进行划分为训练集和测试集。
3.3 Mask R-CNN 训练过程
3.3.1部分训练参数设置
训练所使用的 GPU 型号为 GTX1080Ti,GPU 显存为 10G,部分训练参数设置如表 3.1 所示。
表 3.1 训练部分参数

因受训练 GPU 性能的限制,为减少训练样本进入模型 resize 后损失掉的像素值,将IMAGE_MAX_DIM 设置为 1024;在图片进入 ProposalLayer 层进行处理时,会使用到极大值抑制算法,模型会选择一个最佳的先验框 best_anchor,当检测先验框 left_anchor 和最佳的先验框 best_anchor 的 IOU 大于 0.6 则会被舍弃; 其余参数均为根据经验值或默认进行设置。
3.3.2训练过程
训练所使用的预训练模型为 mask_rcnn_coco.h5 , 通过执行 python3 insulator.py train --dataset=…/…/datasets/insulator --weights=coco 命令进行训练,训练输出参数如图 3.6 所示,当 epoch 达到 60 时,可见总体 loss 值已经降至 0.6299 左右,在 logs 文件夹下可得到最终的训练模型 mask_rcnn_insulator_final。

图 3.6 训练输出参数
3.4Mask R-CNN 训练结果分析
3.4.1检测及分割过程
(1)方案一:直接将测试集的原图送入到模型进行绝缘子检测和分割。原图及其分割结果如图 3.7,肉眼可见轮廓十分粗糙,与人工标注的掩模图进行计算得 dice 系数为 0.47 左右,除了训练样本数量过少,可能还存在高分辨率原图样本标记出来的轮廓特征较复杂的问题,加大了模型学习的复杂性,模型训练时的数据拟合性能变差,导致模型在检测时对绝缘子串珠的沟壑难以分辨,仅能分割出绝缘子大致的外形,而无法分辨出绝缘子串珠的位置、数量及可能存在的自爆点,因此在低样本量情况下使用高分辨率图片作训练样本的方案不可行。
 图 3.7 方案一检测结果与原图对比
图 3.7 方案一检测结果与原图对比
(2)方案二:为减小模型检测和训练时输入图像样本特征差异,在检测也同样将输入图片进行等分割批量输入到训练好得模型中进行检测,检测完成后将各分割检测图再进行合并,合并后的结果如图 3.8 所示,将检测结果使用python-opencv 进行开运算和闭运算处理,以去除因分割检测造成图片间的断痕, 与人工标注的掩模图进行计算得 dice 系数为 0.83 左右,如图 3.9,但边缘仍存在一些较为宽的断痕,可能是训练集类似因分割而中断特征的绝缘子样本数量不够多导致的,但基本能够达到绝缘子串珠分割的预期效果。

图 3.8 方案二检测结果

图 3.9 方案二结果所得 dice 系数
四、绝缘子自爆区域识别与定位
4.1数据集制作
针对于任务二,本文所用数据集来自无人机航拍 40 张数据原始图像,其中包含了 35 张含有自爆区域的原图,经由图像分割、图像增强、归一化大小等数据预处理,共有 1773 张含有自爆缺陷的数据集,其中瓷质绝缘子 602 张,632 张玻璃绝缘子,539 张带盘绝缘子,分别以自定义标签序号从 1 开始重命名,统一 resize 成 1024×1024 尺寸。如图 4.1 所示为部分数据集的展示结果。
图 4.1 部分数据集
4.2样本标记及分类
利用 labellmg 标记工具对数据集进行标记,如下图 4.2 所示,将自爆区域的用 rectangle 标记,包含前后两个绝缘子。

图 4.2 labellmg 标记图片
生成xml 文件如图 4.3 所示,xml 文件中描述了标注中有用的信息,其中 size是标注图像的大小以及深度,节点 bndbox 包含的自爆区域的 boundingbox。

图 4.3 labellmg 生成 xml 标注文件
将数据集按 VOC 格式放入相应的文件夹,其格式如图 4.4 所示,将数据集随机按 8:2 的比例划分训练集和测试集。

图 4.4 VOC 格式目录
其中 JPEGImages 是图片原图,Annotations 存放 xml 格式文件,每个 xml 对应 JPEGImages 中的一张图片,ImageSets 下的 Main 文件夹是训练集和测试集的名字,labels 文件夹是对应标注文件后生成的 boundingbox 的归一化后取值范围为 0-1 的中心坐标和相对宽高。
4.3基于 Yolo-v3 的自爆区域识别与定位
4.3.1 Yolo-v3 网络结构
Yolo-v3 的基础网络是 Darknet-53,从第 0 层到第 74 层,共有 53 个卷积层, 其余为 res 层。

图 4.5 Yolo-v3 卷积过程
如上图4.5 所示,从图中可以清晰看到整个流程,其中通过先验框的K-means 聚类得到的 9 个簇均匀分布在图中右下角的 yolo detection,采用不同尺度来获取特征作为 yolo 检测的输入。
相比于其他的网络,如表 4.1 所示,优点在于快速,背景误检率低,相比R-CNN 系列缺点,识别物体精度低,召回率低。
表 4.1 Darknet-53 与其他主干网络对比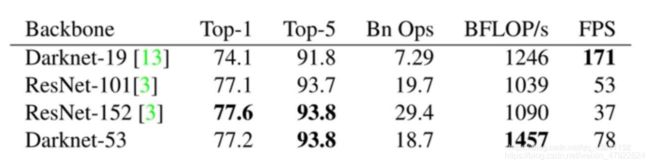
4.3.2Yolo-v3 训练过程可视化分析
训练使用的 GPU 是 GeForceGTX1080Ti,GPU 显存 10GB。yolo 的 cfg 文件中设置 batch=64,subdivisions=16,width=768,height=768。将 80%的训练集放入训练,训练日志如图 4.6 所示。

图 4.6 训练日志部分数据
训练过程中 loss 损失函数如下图 4.7 所示,由图可以看出 loss 函数趋近于收敛,当 loss 低于 0.06,可停止训练。

图 4.7 Yolo-v3 的 loss 函数变化曲线
如图 4.8 所示为 IOU 交叠率的变化曲线,随着 batch 越大,IOU 逐渐趋近于1,可认为训练结果较为良好。
 图 4.8 Yolo-v3 的 IOU 变化曲线
图 4.8 Yolo-v3 的 IOU 变化曲线
4.3.3Yolo-v3 训练结果分析
通过执行指令./darknet detector valid cfg/insulator.data
cfg/Yolo-v3-insulator-test.cfg backup/Yolo-v3-insulator_final.weights 验证剩下 20% 测试集,验证后计算出 Mean AP,如下图 4.9 所示,由图可以看到,Yolo-v3 的AP 指标为 92.2%
 图 4.9 Yolo-v3 的 AP 计算结果
图 4.9 Yolo-v3 的 AP 计算结果
作出 AP 与 recall 变化曲线,如图 4.10 所示。

图 4.10 Yolo-v3 的 AP 和 recall 变化曲线
随机选自无人机航拍原始图像中的 010.JPG 进行 2×2 分割后检测,检测结果如下图 4.11 和 4.12 所示。

图 4.11 基于 Yolo-v3 的 010.JPG 的自爆区域识别与定位结果
图 4.12 基于 Yolo-v3 绝缘子自爆区域的识别与定位结果
由图 4.11 可以看出,绝缘子自爆区域识别率为 100%,xmin=3391,xmax=3641,ymin=2137, ymax=237,与官方标准的 xml 中 xmin=3365, xmax=3362,ymin=2138,ymax=2350,进行对比,计算出 IOU 为,IOU 结果如下图 4.13 所示
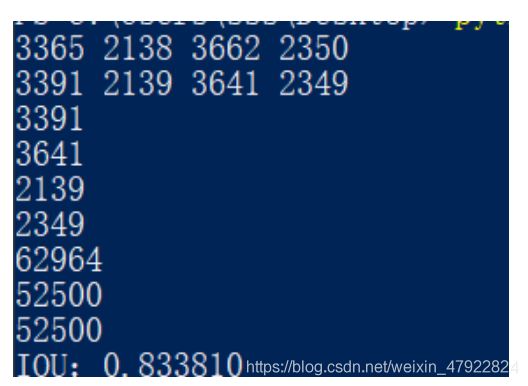 图 4.13 与官方 010.JPG 的 IOU 率
图 4.13 与官方 010.JPG 的 IOU 率
与原始图片含有自爆区域的 35 张平均 IOU=0.819022
4.4基于 Yolo-v4 的自爆区域识别与定位
4.4.1Yolo-v4 网络结构
Yolo-v4 选择 CSPDarknet53 作为主干网络,配合 SPP 模块,PANet 通道融合以及 Yolo-v3 的 anchor based head。
表 4.2 用于图像分类的神经网络参数
如上表 4.2 所示,对比了三种 SOTA 主干网络的,可以看到 CSPDarknet53的感受域、参数量以及速度都是最好的。
Yolo-v4 还使用了额外的改进措施:
(1)提出新的数据增强方法 Mosaic 和 Self-Adversarial Training (SAT)
(2)使用遗传算法选择最优的超参数。
(3)改进的 SAM、改进的 PAN 和交叉小批量归一化(CmBN)。
Yolo-v4 与其他算法上在 COCO 目标检测的识别对比,如下图 4.14 所示。

图 4.14 COCO 目标检测的各算法的 AP 与 FPS 对比
从图中可以看出,Yolo-v4 相比于 Yolo-v3 的AP 和FPS 提高了10% 和 12%。
4.4.2 Yolo-v4 训练可视化分析
训练使用的 GPU 是 GeForceGTX1080Ti,GPU 显存 10GB 。yolo 的 cfg 文件中设置 batch=64,subdivisions=40,width=864,height=864。将 80%的训练集放入训练,训练日志如图 4.15 所示。

图 4.15 Yolo-v4 训练日志
训练过程中 loss 损失函数如下图 4.16 所示,由图可以看出 loss 函数趋近于收敛,通过调节学习率防止过拟合,当 loss 低于 0.06,可停止训练。

图 4.16 Yolo-v3 的 loss 函数变化曲线
如图 4.17 所示为 IOU 交叠率的变化曲线,随着 batch 越大,期望 IOU 逐渐趋近于 1。

图 4.17 Yolo-v3 的 IOU 变化曲线
4.4.3 Yolo-v4 训练结果分析
通过执行指令./darknet detector valid cfg/insulator.data
cfg/Yolo-v4-insulator-test.cfg backup/Yolo-v4-insulator_final.weights 验证剩下 20% 测试集,验证后计算出 Mean AP,如下图 4.18 所示,由图可以看到,Yolo-v4 的AP 指标为 94.7%,相比于 Yolo-v3 的 AP 为 92.2%,精度提高了 2.5%。
 图 4.18 Yolo-v4 的 AP 计算
图 4.18 Yolo-v4 的 AP 计算
作出 AP 与 recall 变化曲线,如下图 4.19 所示。

图 4.19 Yolo-v4 AP 与 recall 变化曲线
随机选自无人机航拍原始图像中的 010.JPG 进行 2×2 分割后检测,检测结果如下图 4.20 和 4.21 所示。

图 4.20 基于 Yolo-v4 的 010.JPG 绝缘子的自爆区域识别与定位结果
图 4.21 基于 Yolo-v4 的绝缘子自爆区域识别与定位结果
由图 4.20 可以看出,绝缘子自爆区域识别率为 99%,xmin=3353,xmax=3685, ymin=2139, ymax=2349,与官方标准的 xml 中 xmin=3365,xmax=3362, ymin=2138,ymax=2350,进行对比,计算出 IOU 为 0.887021,IOU 结果如下图4.22 所示

图 4.22 与官方 010.JPG 的 IOU 率
与原始图片含有自爆区域的 35 张平均 IOU=0.825439
4.5 Yolo-v3 与 Yolo-v4 的结果对照
如图 4.23 所示,同样的数据集,Yolo-v3 的 AP 指标为 0.922,Yolo-v4 为0.947,显然精度上 Yolo-v4 更胜一筹。由上面数据可知,而 Yolo-v3 的平均 IOU 率为 0.819022,Yolo-v4 的平均 IOU 率为 0.825439,可以看出 Yolo-v4 的 IOU 定位精度更高。因此我们采用 Yolo-v4 作为绝缘子自爆区域的识别定位模型。
 (a)Yolo-v3 的 AP
(a)Yolo-v3 的 AP

(b)Yolo-v4 的AP
图 4.23 Yolo-v3 和 Yolo-v4 的 AP 比较
4.6小目标预测策略
4.6.1高分辨率图像直接预测
由于原始图片为无人机航拍照片,多为高分辨率图像如 7360×4912,自曝区域在图像占比率低于 1%,如将原始图像,不经过预处理,直接放入模型中识别,效果不佳。如下图 4.24 所示为 Yolo-v4 的 7360*4912 的识别效果。
图 4.24 Yolo-v4 小目标识别效果
由图 4.24 可知,直接将 7360×4912 原始图片放进模型中预测效果很差,不仅会导致一些自爆区域漏检,大大降低识别率,还会导致 IOU 区域的定位不准确。因此无论是识别精度还是 IOU 交叠率,效果都不好。显然,对于高分辨率的图像,自爆区域识别不能采取直接将 7360×4912 的原始图片放入模型中预测。
4.6.2等比例分割
针对高分辨图片不能直接放入模型预测的问题,最简单的方法是将图片等比例分割成几块,使之每一块中的目标占图片比例适中,分别放入模型中预测,得到的预测结果后,再按回原来的比例拼接,最终合成一个与原始图片大小一致的检测结果图。如图 4.25 所示,为将原始图片 028.JPG 进行 4×4 等比例分割的预测结果图。
图 4.25 028.JPG 4×4 分割识别结果
如上图可以看出,将高分辨率图像进行分割,使之目标占图片比例适中,再放进模型中预测,可以得到较好的结果。如下图 4.26,为将 028.JPG 进行 4×4 分割后的 16 个小块的预测结果图拼接成最终结果。
图 4.26 028.JPG 拼接结果图
通过等额分割后的图片也可以计算出 boundngbox 的位置。如 028.JPG 进行4×4 的分割成 16 个小块,第一行的小块命名为 00.JPG,01.JPG,02.JPG,03.JPG,第二行小块命名为 10.JPG,11.JPG,12.JPG,13.JPG 等,其中,00 代表第 0 行用 row 表示,第 0 列用 col 表示,而 boundingbox 的计算为
X m i n = c o l × 4 ( 1 ) X_{min}=col×4 \qquad(1) Xmin=col×4(1)
Y m i n = r o w × 4 ( 2 ) Y_{min}=row×4 \qquad(2) Ymin=row×4(2)
但是等比例分割存在中一个问题,若把绝缘子自爆区的正好分割,如图 4.27 所示,左边的绝缘子自爆区域正好被分割,以至于该图的绝缘子自爆区域被忽略, 或者无法获取完整的 boundingbox,其原因在于采用等比例分割的方法,该方法的缺陷无法避免,因此该方法也存在的弊端。
 图 4.27 自爆区域被分割
图 4.27 自爆区域被分割
4.6.3滑动窗口以及 NMS
针对于以上预测小目标识别方法存在的问题,本文借鉴了 Adam Van Etten的 You Only Look Twice 论文的思想、卫星图中小目标检测部分算法。
本文中核心思想是通过滑动窗口,步进式的将原输入图像切块,滑动窗口的大小以及步进的大小可调,调至目标占图片比例适中即可,然后将每个滑动窗口分别放入模型进行检测。为了保证被分割后的图片中目标信息能够完整的被检测到,每个滑动窗口有可能对同一目标进行两次或四次检测,因此采用非极大抑制NMS 算法得出其中一个最好的框。
如图 4.28 所示,通过滑动窗口裁剪为指定尺寸 1024*1024 的图像作为模型的输入,裁剪后的图像称为 chip,相邻的 chip 可能会出现部分区域的重叠,如图所示,目的是保证原始图片的每个区域都能被完整检测,防止绝缘子自爆区域被分割。
图 4.28 滑动窗口思想
当多个窗口进行滑动时,可能会导致同一个目标被识别多次,如图 4.29 所示,因而可以采用 NMS 算法,抑制不是极大值的矩形框。
图 4.29 滑动窗口对同一目标识别多次
通过滑动窗口的思想,将绝缘子原始图片进行滑动预测自爆区域取得优异的效果。具体步骤如图 4.30 所示,将原始图片 001.JPG 通过滑动窗口方式,将滑动窗口分辨率固定原始图片的一半,步进大小固定为原始图片的四分之一,即相邻的两个滑动窗口有 50%的区域重叠。
图 4.30 滑动窗口将 001.JPG 分割
图 4.31 滑动窗口预测结果
如上图 4.31 所示为滑动窗口放入模型的预测结果,每个图片的第一个字符为行的索引,第二个字符为列的索引,规定索引从 0 开始,每个 boundingbox 相对于原始图片的位置计算为:
本文将滑动窗口大小固定原始图片 1/2:
W i n d o w _ X = 1 2 × s r c . c o l s ( 3 ) Window\_ X=\frac{1}{2}\times src.cols \qquad(3) Window_X=21×src.cols(3)
W i n d o w _ Y = 1 2 × s r c . r o w s ( 4 ) Window\_ Y=\frac{1}{2}\times src.rows \qquad(4) Window_Y=21×src.rows(4)
窗口步进大小固定为滑动窗口的 1/2,即原始图片的 1/4。X,y 的窗口步进大小为:
x s t e p = 1 2 × W i n d o w _ X ( 5 ) x_{step}=\frac{1}{2}\times Window\_ X \qquad(5) xstep=21×Window_X(5)
y s t e p = 1 2 × W i n d o w _ Y ( 6 ) y_{step}=\frac{1}{2}\times Window\_ Y \qquad(6) ystep=21×Window_Y(6)
式中 src 为原始图片,src.cols 为原始图片的行数,src.rows 为原始图片的列数。
假设目标在滑动窗口的 boundingbox 位置为 x1,y1,w1,h2,
X m i n = X 1 + c o l × x s t e p ( 7 ) X_{min}=X_1+col\times x_{step}\qquad(7) Xmin=X1+col×xstep(7)
Y m i n = Y 1 + r o w × y s t e p ( 8 ) Y_{min}=Y_1+row\times y_{step}\qquad(8) Ymin=Y1+row×ystep(8)
X m a x = X 1 + w l + c o l × x s t e p ( 9 ) X_{max}=X_1+wl+col\times x_{step}\qquad(9) Xmax=X1+wl+col×xstep(9)
Y m a x = Y 1 + h 2 + r o w × y s t e p ( 10 ) Y_{max}=Y_1+h2+row\times y_{step}\qquad(10) Ymax=Y1+h2+row×ystep(10)
式中 row 为行的索引,代表第 row 行,同时也是滑动窗口命名的第一个数字,如上图 4.31 所示,col 为列的索引,代表第 col 列,同时也是滑动窗口的第二个数字。Xmin,Xmax,Ymin,Ymax 为目标的 boundingbox 相对于原始高分辨率图像的位置。
如图 4.32 所示,为相邻两个 boundingbox 相对于原始图片的位置

图 4.32 滑动窗口法生成xml 文件
由图中可以看出,同一图片生成两个预测框,计算后得出两个 boundingbox 相对于原始图片的位置十分接近,可以看到同一个目标被识别两次,因此采用非极大值抑制算法,如下图 4.33 为 NMS 的运算结果,左图为两个图相互交叠,通过 nms 算法抑制其中一个框,保留右边红色的框,计算得出最好的框。

图 4.33 NMS 非极大值抑制
五、总结与展望
本文主要探究了绝缘子串珠掩膜的分割和绝缘子自爆区域的识别与定位,使用 Mask R-CNN 进行绝缘子串珠分析,对比 Yolo-v3 与 Yolo-v4 自爆区域的识别与定位,结果表明用神经网络代替人工电力巡检具有良好的应用价值,并且采用Mask R-CNN 和 Yolo-v4 的研究方法,使用滑动窗口的思想进行小目标识别,对绝缘子的分割和识别有一定的研究价值。
本文中存在的特点有:
(1)在绝缘子串珠分割中采用了将高分辨率图片进行等分割再逐个进行训练和检测的思想,既能简化人工标注样本时的工作量,又能减少绝缘子串样本特征的复杂性,加快训练拟合速度,在确保检测精度的同时能够简化训练过程。
(2)对于任务二,虽然 yolo 系列在精度上可能不如 R-CNN,但其 FPS 高于其他目标检测算法的优势在工业上应用极其广泛。采用近日出世的 Yolo-v4 为绝缘子自爆区域的识别定位研究方法,为实际应用中作为衡量。
(3)采用 YOLT 与 Yolo-v4 相结合,进行通过滑动窗口的思想进行小目标识别策略,有效的避免了小目标识别、传统等比例分割算法的局限性,即将绝缘子自爆区域分割为多张图片,导致无法识别。
本文尚且存在的局限性有:
(1)针对于任务一,由于前期准备不够充分,仅仅使用 Mask R-CNN 这一种用于实例分割的神经网络模型,未能做到多模型比对实验,该模型算法对本设计的语义分割要求可能略显复杂,且检测时间较长,模型算法运算量大,造成了模型结构的浪费,后期改进可尝试多种模型比对或对 Mask R-CNN 模型网络进行优化剪枝。
(2)针对于任务一,因方案二对原高分辨率图片进行等分割过程中没有控制样本特征的相似性,导致样本过泛化,在图片检测过程中若遇到与绝缘子颜色或形状相近的其他物体(如钢架或树叶)会引发一定的误判,后期改进可在制作数据集时删掉差异过大的样本,尽可能控制特征的相似性以控制泛化度。
(3)针对于任务二,本文中数据集共 1773 张图片,有个别几张图像无法识别,因为时间仓促未能完善尽可能多的数据集,后期改进方向可以将数据集的数量增加到 3000,可能效果更佳。
(4)针对于任务二,本文中采用 Yolo-v3 和 Yolo-v4 进行绝缘子自爆区域的对比,由于 Yolo-v4 是 Yolo-v3 的改进,Yolo-v4 比 Yolo-v3 识别更精确是必然的, 由于时间仓促,未能将 Yolo-v4 与其他 R-CNN 算法进行比较,是本文的局限性之一,后期改进可以将 Yolo-v4 与其他 R-CNN 目标检测算法进行比较。但是本文率先采用 Yolo-v4 进行自爆区域检测,为绝缘子自爆区域的识别定位有一定的研究价值。
参考文献
[1]黄新波,张慧莹,张烨,等.基于改进色差法的复合绝缘子图像分割技术[J]. 高电压技术. 2018,44(8):2493~2500.
[2]熊杰. 航拍图像的绝缘子自爆特征识别研究[D]. 电子科技大学,2016
[3]Kaiming He,Georgia Gkioxari,Piotr Dollár,Ross Girshick. Mask R-CNN[D]. IEEE Conference on Computer Vision and Pattern Recognition(CVPR).2018.
[4]Joseph Redmon,Ali Farhadi.Yolo-v3:An Incremental Improvement[D]. University of Washington,20.
[5]Alexey Bochkovskiy,Chien-Yao Wang,Hong-Yuan Mark Liao. Yolo-v4:
Optimal Speed and Accuracy of Object Detection [J]. IEEE Conference on Computer Vision and Pattern Recognition(CVPR). 2020.
[6]毛星云. OpenCV3 编程入门[M]. 北京:电子工业出版社,2015:223-253.
[7]冈萨雷斯,伍兹.数字图象处理(第三版)[M]. 北京:电子工业出版社,2011.
[8]Adam Van Etten. You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery[J]. IEEE Conference on Computer Vision and Pattern