Tensorflow(5):梯度下降,激活函数,反向传播及链式法则,fashionMNIST实战,kerasAPI,自定义网络层,加载和保存模型,CIFAR10实战
1、梯度下降
what is gradient
- 导数,derivative
- 偏微分 partial derivative
- 梯度,gradient

梯度是每一个轴的偏微分组合而成的向量
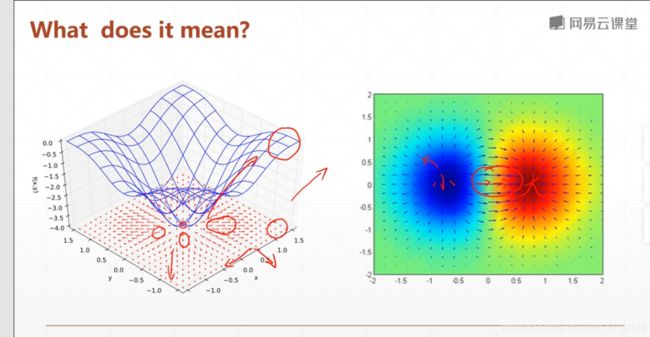
what does it mean
梯度的方向是函数值变大的反向
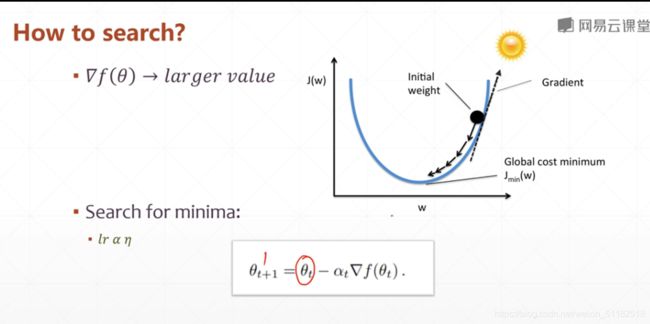
how to search
按照梯度反向更新


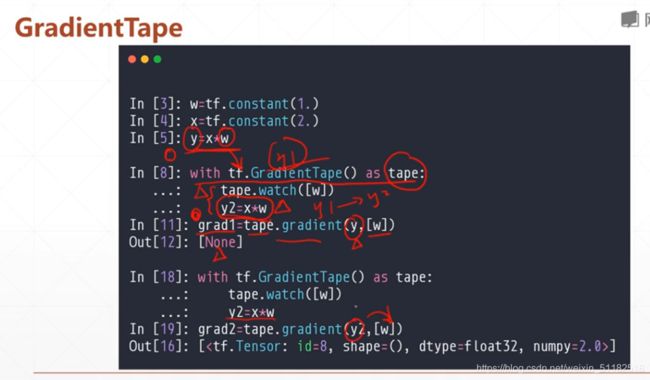
autograd
with tf.GradientTape()as tape:
[w_grad]=tape.gradient(loss,[w])
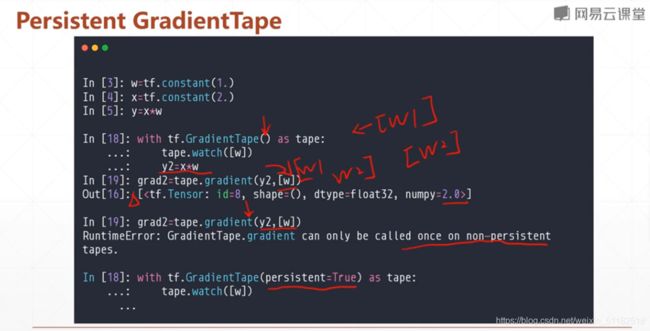
presistent GradientTape
可以再调用一次

实战案例
import tensorflow as tf
w = tf.Variable(1.0)
b = tf.Variable(2.0)
x = tf.Variable(3.0)
with tf.GradientTape() as t1:
with tf.GradientTape() as t2:
y = x * w + b
dy_dw, dy_db = t2.gradient(y, [w, b])
d2y_dw2 = t1.gradient(dy_dw, w)
print(dy_dw)
print(dy_db)
print(d2y_dw2)
assert dy_dw.numpy() == 3.0
assert d2y_dw2 is None
2、激活函数及其梯度
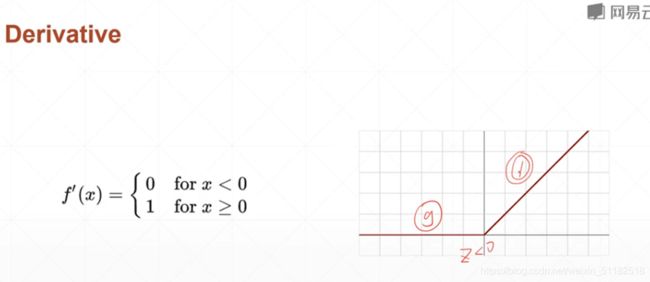
阶梯式的激活函数

该函数无法求导
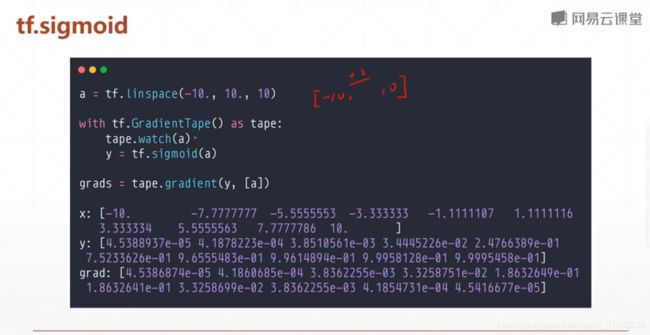
sigmoid/logistic

sigmoid函数的导数

连续的光滑的,在0,1之间
取点:梯度在两端过于接近,梯度离散
Tanh

将x映射到[-1,1]区间


Rectified Linear Unit(RELU)整形的线性单元
小于0,不响应
大于0,线性相应

保持梯度不变,解决了sigmoid函数梯度离散和梯度爆炸的情况
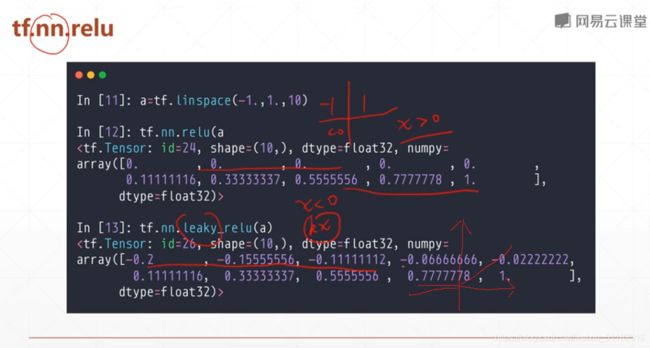
x<0时,斜率小于1,大于0时,斜率为1

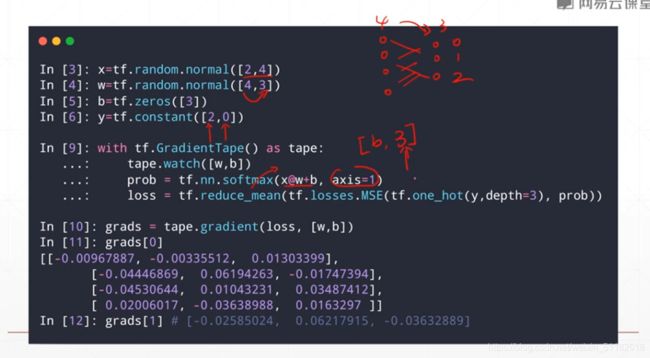
3、损失函数及其梯度

交叉熵用于分类较多

mse的梯度求解


- tape.watch([w,b])#如果w和b已经是variable形式就不需要这一步
- 将y做one-hot编码与prob通过tf.losses.MSE求总的误差再除以所有的N

输出的概率分布的累加应该为1,这点sigmoid函数无法做到。
softmax:将原本最大的输出变得更大
softmax的导数
i=j时

i != j 时


交叉熵求偏导
经过激活函数前的叫logits
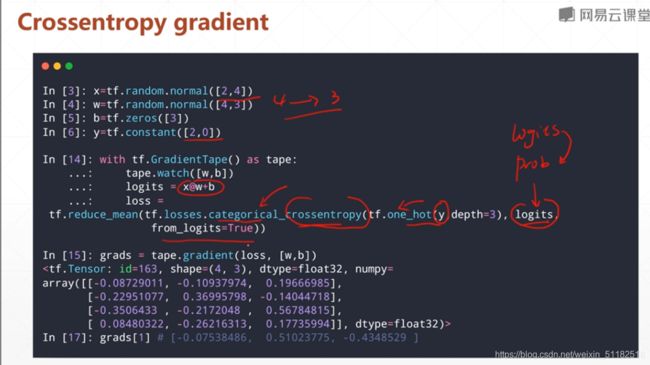
给定输入x为两个样本,一个样本4个特征。所以权值对应特征也有4个,每个权值又有三个方向的值。
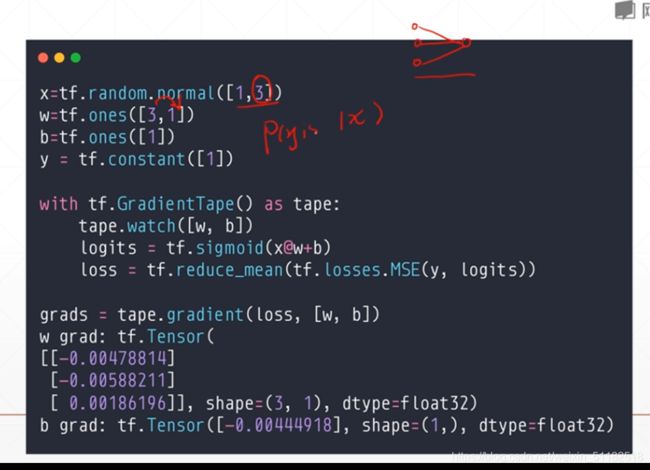
4、单输出感知机及其梯度

上方的数字表示layer的层数,下面的数字表示当前层数下的第几个节点
求导过程


代码
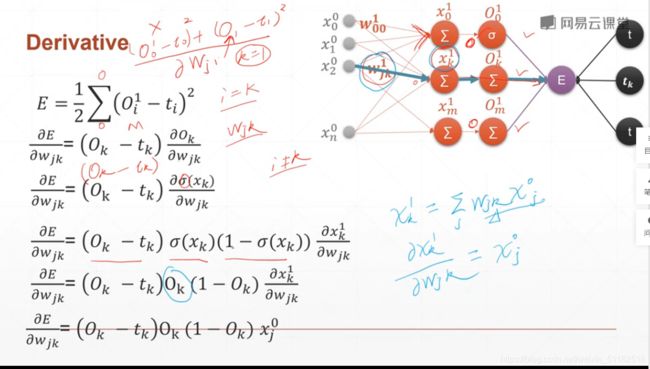
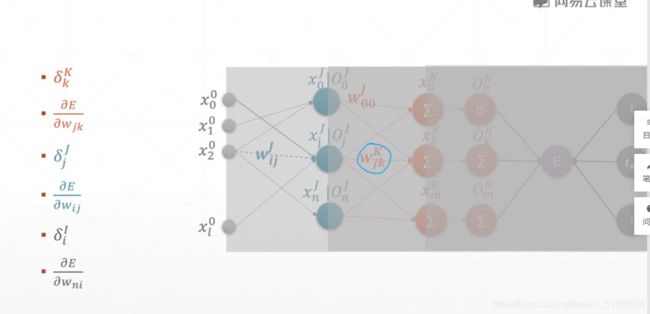
5、多层感知机及其梯度

w j k 1 w_{jk}^1 wjk1的意义:在layer1上,第一层layer输出的第k个logits和第j个输入之间的关系。
6、链式法则
把最后一层的误差一层一层的输入到中间层

quotient rule

chain rule

对于实际的神经网络,还有激活函数,所以用展开式的方式求导会很麻烦


7、反向传播算法
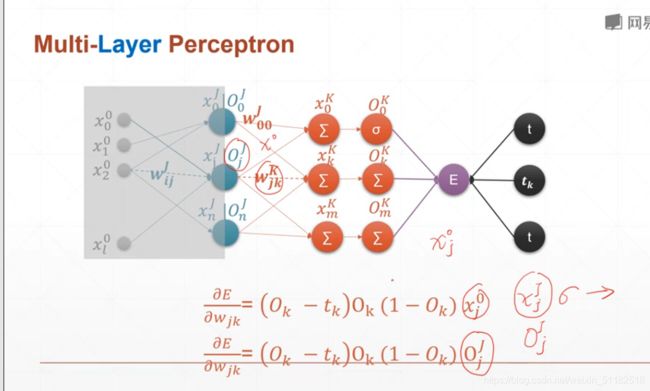
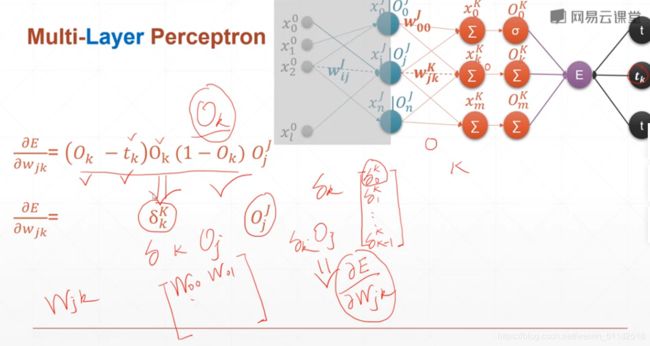

对于某一层layer的某个权值的偏导数等于它前面所有层数的一个值得累加再对它当前函数求偏导。
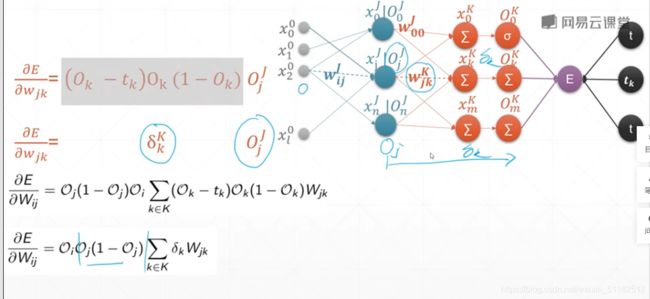
- 右半部分,后续得layers得输出和权值之间相乘的累加
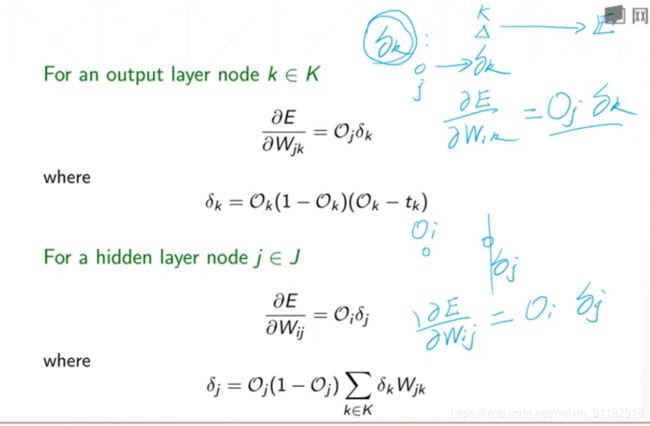
从后向输出开始求导计算
8、2d函数优化实例

寻找局部最小值

研究初始点对于搜索点的结果
plot

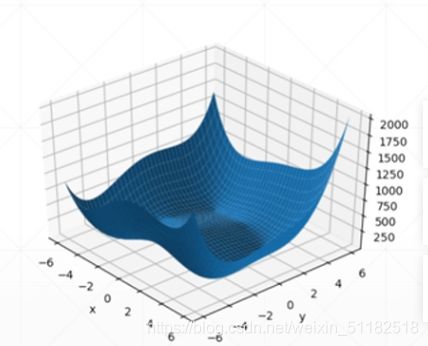
gradient descent

- 随机一个初始点
- 迭代200次
- 求y
- 求每次的梯度
- 做梯度更新
8、手写数字问题实战
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets,layers,optimizers,Sequential,metrics
def preprocess(x,y):
#将x,y转变为tensor格式
x=tf.cast(x,dtype=tf.float32)/255.
y=tf.cast(y,dtype=tf.int32)
return x,y
#分割训练集和数据集
(x,y),(x_test,y_test)=datasets.fashion_mnist.load_data()
print(x.shape,y.shape)
#对训练集做处理
db=tf.data.Dataset.from_tensor_slices((x,y))
batchsize=128
db=db.map(preprocess).shuffle(10000).batch(batchsize)
#对测试集做处理
db_test=tf.data.Dataset.from_tensor_slices((x_test,y_test))
db_test=db_test.map(preprocess).batch(batchsize)
db_iter=iter(db)
sample=next(db_iter)
print("batch",sample[0].shape,sample[1].shape)
#建立NN 五层线性层
model=Sequential([
layers.Dense(256,activation=tf.nn.relu),#[b,784]=>[b,256]
layers.Dense(128,activation=tf.nn.relu),#[b,256]=>[b,128]
layers.Dense(64,activation=tf.nn.relu),#[b,128]=>[b,64]
layers.Dense(32,activation=tf.nn.relu),#[b,64]=>[b,32]
layers.Dense(10) #[b,32]=>[b,10]
])
model.build(input_shape=[None,28*28])
model.summary()
optimizers=optimizers.Adam(lr=1e-3)
def main():
for epoch in range(30):
for step,(x,y) in enumerate(db):
#x:[b,28,28]
#y:[b]
x=tf.reshape(x,[-1,28*28])
with tf.GradientTape() as tape:
#[b,784]=>[b,10]
logits=model(x)
y_onehot=tf.one_hot(y,depth=10)
loss_mse=tf.reduce_mean(tf.losses.MSE(y_onehot,logits))
loss2=tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot,logits,from_logits=True))
#计算梯度
grads=tape.gradient(loss2,model.trainable_variables)
#参数更新
optimizers.apply_gradients(zip(grads,model.trainable_variables))
if step%100==0:
print(epoch,step,"loss",float(loss_mse),float(loss2))
total_correct=0
total_number=0
for x,y in db_test:
x=tf.reshape(x,[-1,28*28])
logits=model(x)
#logits=>prob
prob=tf.nn.softmax(logits,axis=1)
pred=tf.argmax(prob,axis=1)
pred=tf.cast(pred,dtype=tf.int32)
correct=tf.equal(pred,y)
correct=tf.reduce_sum(tf.cast(correct,dtype=tf.int32))
total_correct+=int(correct)
total_number+=x.shape[0]
acc=total_correct/total_number
print(epoch,"test acc:",acc)
if __name__=="__main__":
main()

9、可视化
TensorBoard
Visdom
- installation
- Curves
- image visualization
principle
- listen logdir 监听磁盘的目录 web从listen取数据
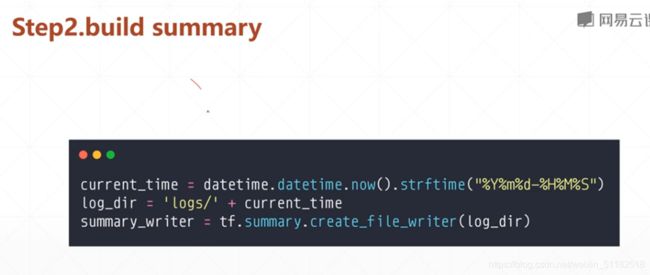
- build summary instance
- fed data into summary instance 把数据喂给summary,数据自动更新到磁盘中
step 1 run listener


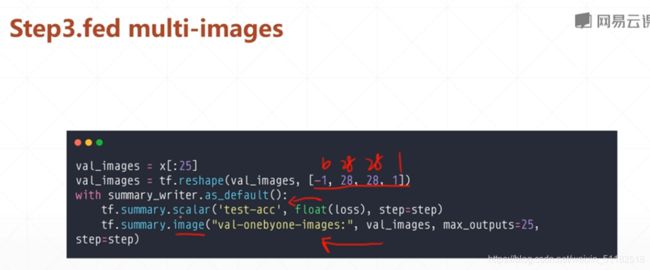
使用image_grid 把图片组合成一张图片

10、tf.keras高层接口
- datasets
- layers
- losses
- metrics
- optimizers
loss和acc指的不是每一次迭代得acc
metrics

将每次得loss添加进res列表,求average
step1: build a meter
acc_meter=metrics.Accuracy()
loss_meter=metrics.Mean()
step2:update data
loss_meter.update_state(loss)
acc_meter.update_state(y,pred)
step3:get average data
print(step,"loss",loss_meter.result(),numpy())
print(step,"acc:",total_correct/total,acc_meter.result().numpy())
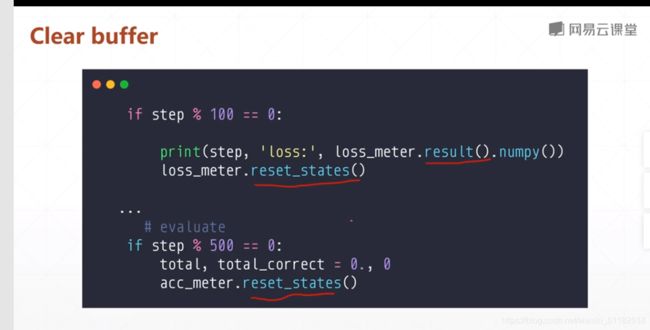
clear buffer
实战
import tensorflow as tf
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32) / 255.
y = tf.cast(y, dtype=tf.int32)
return x,y
batchsz = 128
(x, y), (x_val, y_val) = datasets.mnist.load_data()
print('datasets:', x.shape, y.shape, x.min(), x.max())
db = tf.data.Dataset.from_tensor_slices((x,y))
db = db.map(preprocess).shuffle(60000).batch(batchsz).repeat(10)
ds_val = tf.data.Dataset.from_tensor_slices((x_val, y_val))
ds_val = ds_val.map(preprocess).batch(batchsz)
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.build(input_shape=(None, 28*28))
network.summary()
optimizer = optimizers.Adam(lr=0.01)
acc_meter = metrics.Accuracy()
loss_meter = metrics.Mean()
for step, (x,y) in enumerate(db):
with tf.GradientTape() as tape:
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# [b, 784] => [b, 10]
out = network(x)
# [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# [b]
loss = tf.reduce_mean(tf.losses.categorical_crossentropy(y_onehot, out, from_logits=True))
loss_meter.update_state(loss)
grads = tape.gradient(loss, network.trainable_variables)
optimizer.apply_gradients(zip(grads, network.trainable_variables))
if step % 100 == 0:
print(step, 'loss:', loss_meter.result().numpy())
loss_meter.reset_states()
# evaluate
if step % 500 == 0:
total, total_correct = 0., 0
acc_meter.reset_states()
for step, (x, y) in enumerate(ds_val):
# [b, 28, 28] => [b, 784]
x = tf.reshape(x, (-1, 28*28))
# [b, 784] => [b, 10]
out = network(x)
# [b, 10] => [b]
pred = tf.argmax(out, axis=1)
pred = tf.cast(pred, dtype=tf.int32)
# bool type
correct = tf.equal(pred, y)
# bool tensor => int tensor => numpy
total_correct += tf.reduce_sum(tf.cast(correct, dtype=tf.int32)).numpy()
total += x.shape[0]
acc_meter.update_state(y, pred)
print(step, 'Evaluate Acc:', total_correct/total, acc_meter.result().numpy())
Compile & Fit
- compile
- fit
- evaluate
- predict
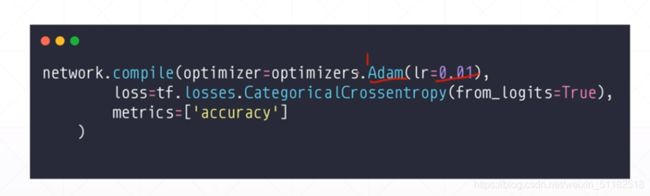
- 指定优化器
- 指定loss
- 指定acc

- fit 一个数据集
- 指定epoch
- network:model

进度条走完,db完成了一次循环
evaluation
测试的手epoch和step都是固定的
测试代码
network.compile(optimizer=optimizers.Adam(lr=0.01),loss=tf.losses.CategoricalCrossentropy
(from_logits=True),metric=["accuracy"])
network.fit(db,epoch=10,validation_data=ds_val,validation_freq=2) #在training种做validation
network.evaluate(ds_val)#输出最后的acc

training和validation都有accuracy

predict
sample=next(iter(ds_val))
x=sample[0]
y=sample[1]
pred=network.predict(x)
y=tf.argmax(y.axis=1)
pred=tf.argmax(pred,axis=1)
11、自定义网络
- keras.Sequential
- keras.layers.Layer
- keras.Model

network.build(input_shape(None,28*28)):建立网路参数
- model.trainable_variables :网络中的所有参数
- model.call (x)
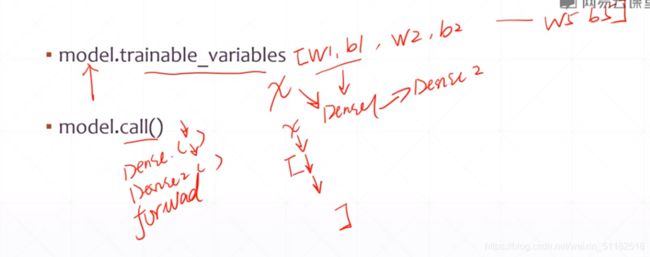
layer/model

compile/fit/evaluate/predict必须继承自model类
实现自定义层
class MyDense(layers.Layer):
def __ init__(self,inp_dim,output_dim):
super(MyDense,self).__init__()
self.kernal=self.add_variable("w",[inp_dim,outp_dim]) #self.add_variable 在母类中
self.bias=self.add_variable("b",[outp_dim])
def call(self,inputs,training=None):
[email protected]+self.bias
return out
创建一个五层的网络

- 新建五层
- 在call中将输入输入进网络
- 输出为logits,没有经过softmax变为prob
- sequential中无法加入额外操作,自建得是可以的
实战代码
class MyDense(layers.Layer):
def __init__(self, inp_dim, outp_dim):
super(MyDense, self).__init__()
self.kernel = self.add_variable('w', [inp_dim, outp_dim])
self.bias = self.add_variable('b', [outp_dim])
def call(self, inputs, training=None):
out = inputs @ self.kernel + self.bias
return out
class MyModel(keras.Model):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = MyDense(28*28, 256)
self.fc2 = MyDense(256, 128)
self.fc3 = MyDense(128, 64)
self.fc4 = MyDense(64, 32)
self.fc5 = MyDense(32, 10)
def call(self, inputs, training=None):
x = self.fc1(inputs)
x = tf.nn.relu(x)
x = self.fc2(x)
x = tf.nn.relu(x)
x = self.fc3(x)
x = tf.nn.relu(x)
x = self.fc4(x)
x = tf.nn.relu(x)
x = self.fc5(x)
return x
network = MyModel()
- 建立变量和线性关系
- 建立网络和激活函数
- 通过定义的函数创建network
12、模型保存与加载
- save/load weights
- save/load entire model
- save_model
#保存权重
model.save_weights("")
#restore the weights
model=create_model()
model.load_weights("")
loss,acc=model.evaluate(test_images,test_labels)
保存weight代码
network.save_weights('weights.ckpt')
print('saved weights.')
del network
network = Sequential([layers.Dense(256, activation='relu'),
layers.Dense(128, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10)])
network.compile(optimizer=optimizers.Adam(lr=0.01),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
network.load_weights('weights.ckpt') #将上一步保存的weightload进当前network
print('loaded weights!')
network.evaluate(ds_val) #计算ds验证集的acc
保存整个模型
#保存网络
network.save("")
#用tf.keras.models.load_model加载网络
network=tf.keras.models.load_model("")
network.evaluate(x_val,y_val)
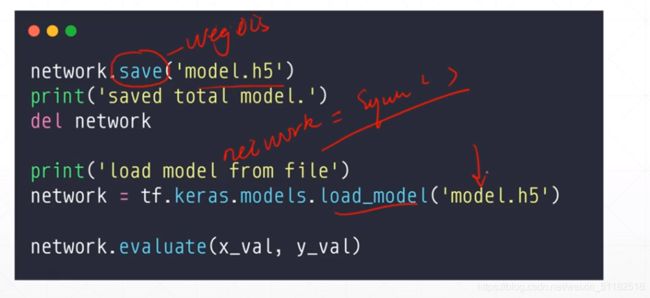
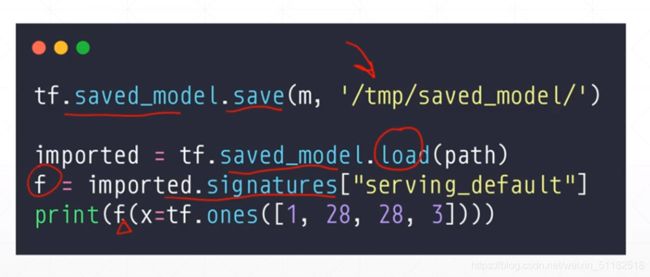
直接把model保存成一个函数模型
13、CIFAR10自定义网络实战
使用自定义网络层:去掉bias参数
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"]="2"
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets,layers,optimizers,Sequential,metrics
def preprocess(x,y):
#将x,y转变为tensor格式
x=2*tf.cast(x,dtype=tf.float32)/255.-1
y=tf.cast(y,dtype=tf.int32)
return x,y
#分割训练集和数据集
(x,y),(x_test,y_test)=datasets.cifar10.load_data()
#对target进行处理和one-hot encoding
y=tf.squeeze(y) #删除无用的dim
y_test=tf.squeeze(y_test)
y=tf.one_hot(y,depth=10)
y_test=tf.one_hot(y_test,depth=10)#depth可以通过查看y.shape得到
print(x.shape,y.shape)
#对训练集做处理
train_db=tf.data.Dataset.from_tensor_slices((x,y))
batchsize=128
train_db=train_db.map(preprocess).shuffle(10000).batch(batchsize)
test_db=tf.data.Dataset.from_tensor_slices((x_test,y_test))
test_db=test_db.map(preprocess).batch(batchsize)
sample=next(iter(train_db))
print("batch",sample[0].shape,sample[1].shape)
#新建网络对象
class MyDense(layers.Layer):
#to replace standard layers.Dense()
def __init__(self,input_dim,output_dim):
super(MyDense,self).__init__()
self.kernal=self.add_variable("w",[input_dim,output_dim])
# self.bias=self.add_variable("b",[output_dim])
def call(self,inputs,training=None):
[email protected]
return x
# 建立自定义网络
class mynetwork(keras.Model):
def __init__(self):
super(mynetwork,self).__init__()
self.fc1=MyDense(32*32*3,256)
self.fc2 = MyDense(256, 128)
self.fc3 = MyDense(128, 64)
self.fc4 = MyDense(64, 32)
self.fc5 = MyDense(32, 10)
def call(self,inputs,training=None):
x=tf.reshape(inputs,[-1,32*32*3])
x=self.fc1(x)
x=tf.nn.relu(x)
x=self.fc2(x)
x=tf.nn.relu(x)
x = self.fc3(x)
x = tf.nn.relu(x)
x = self.fc4(x)
x = tf.nn.relu(x)
x = self.fc5(x)
return x
network=mynetwork()
network.compile(optimizer=optimizers.Adam(lr=1e-3),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
network.fit(train_db,epochs=15,validation_data=test_db,validation_freq=1)
# 模型的保存
network.evaluate(test_db)
network.save_weights("ckpt/weights.ckpt")
del network
print("saved to ckpy/weights.ckpt")
#重新加载
network=mynetwork()
network.compile(optimizer=optimizers.Adam(lr=1e-3),
loss=tf.losses.CategoricalCrossentropy(from_logits=True),
metrics=["accuracy"])
network.fit(train_db,epochs=15,validation_data=test_db,validation_freq=1)
network.load_weights("ckpt/weights.ckpt")
print("loaded weights fron file.")
network.evaluate(test_db)
操作过程
- 加载数据集
- 对target做squeeze和onehot处理
- 建立训练集和测试集
- 查看sample中的batch
- 定义一个myDense类,设置一个layer的input和weight和输出
- 定义一个network类,给定nn的层数,weight的维度以及对x的输入过程和激活过程
- 建立network, compile添加梯度算法,定义loss格式,定义metrics为acc
- network fit 参数,指定测试集和迭代过程
- evaluate
- 保存weight
- 删除当前网络
- 建立一个新的网络
- 加载保存好的weight