零基础入门NLP之新闻文本分类挑战赛——基于深度学习的文本分类2
在上一章节,我们通过FastText快速实现了基于深度学习的文本分类模型,但是这个模型并不是最优的。在本章我们将继续深入。
一、Word2vec
Word2vec,是一群用来产生词向量的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在word2vec中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。[百度百科]
1、什么是 Word Embedding ?
在说明 Word2vec 之前,需要先解释一下 Word Embedding。 它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。
这一步解决的是”将现实问题转化为数学问题“,是人工智能非常关键的一步。
将现实问题转化为数学问题只是第一步,后面还需要求解这个数学问题。所以 Word Embedding 的模型本身并不重要,重要的是生成出来的结果——词向量。因为在后续的任务中会直接用到这个词向量。
2、什么是 Word2vec ?
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
3、Word2vec 的 2 种训练模式
CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。下面简单做一下解释:
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。

Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。

4、优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
1、Negative Sample(负采样)
2、Hierarchical Softmax
5、优缺点
优点
1、由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
2、比之前的 Embedding方 法维度更少,所以速度更快
3、通用性很强,可以用在各种 NLP 任务中
缺点
1、由于词和向量是一对一的关系,所以多义词的问题无法解决。
2、Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化
参考资料
https://easyai.tech/ai-definition/word2vec/
斯坦福大学深度学习与自然语言处理第二讲:词向量
二、TextCNN
Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。
将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。
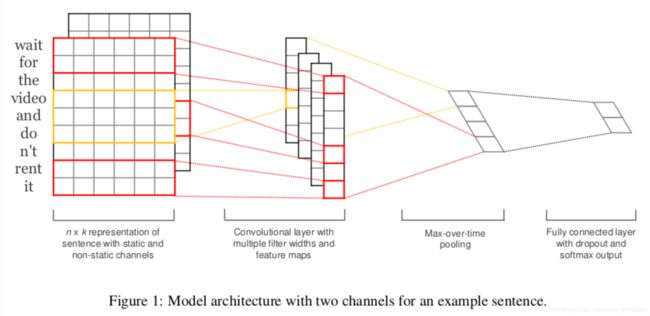 TextCNN的详细过程原理图如下:
TextCNN的详细过程原理图如下:
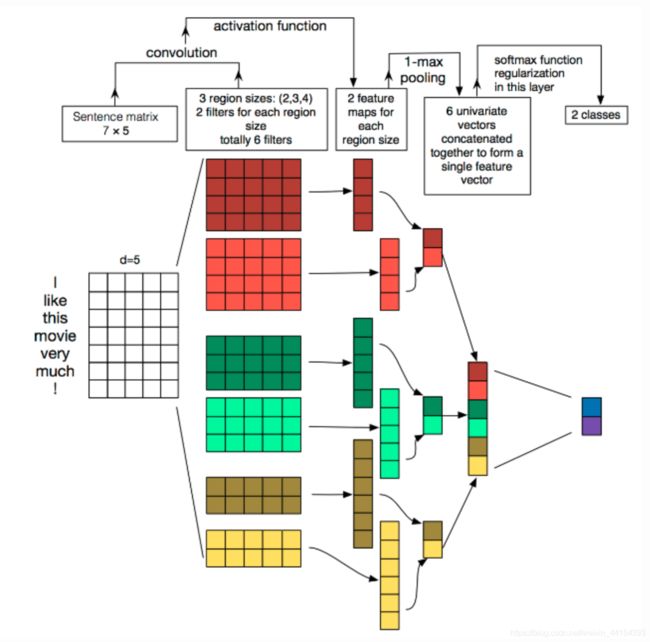
TextCNN详细过程:
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
通道(Channels):
图像中可以利用 (R, G, B) 作为不同channel;
文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):
图像是二维数据;
文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
Pooling层:
利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
参考资料:
https://www.cnblogs.com/bymo/p/9675654.html
三、TextRNN
这里的文本可以一个句子,文档(短文本,若干句子)或篇章(长文本),因此每段文本的长度都不尽相同。在对文本进行分类时,我们一般会指定一个固定的输入序列/文本长度:该长度可以是最长文本/序列的长度,此时其他所有文本/序列都要进行填充以达到该长度;该长度也可以是训练集中所有文本/序列长度的均值,此时对于过长的文本/序列需要进行截断,过短的文本则进行填充。总之,要使得训练集中所有的文本/序列长度相同,该长度除之前提到的设置外,也可以是其他任意合理的数值。在测试时,也需要对测试集中的文本/序列做同样的处理。
假设训练集中所有文本/序列的长度统一为n,我们需要对文本进行分词,并使用词嵌入得到每个词固定维度的向量表示。对于每一个输入文本/序列,我们可以在RNN的每一个时间步长上输入文本中一个单词的向量表示,计算当前时间步长上的隐藏状态,然后用于当前时间步骤的输出以及传递给下一个时间步长并和下一个单词的词向量一起作为RNN单元输入,然后再计算下一个时间步长上RNN的隐藏状态,以此重复…直到处理完输入文本中的每一个单词,由于输入文本的长度为n,所以要经历n个时间步长。
