C#中的构建字典: DictionaryBase类和SortedList类
C#中的构建字典: DictionaryBase类和SortedList类
1、简介
字典是一种把数据作为键值对(key-value pair)来存储的数据结构. 作为一种抽象的类, DictionaryBase类可以用来实现不同的数据结构, 其中这些数据结构全部把数据存储成键值对. 这些数据结构可能是哈希表, 链表或者其他一些数据结构类型. 本章节会讨论如何创建基础字典, 以及如何使用DictionaryBase类的继承方法. 稍后当研究更加专有的数据结构的时候将会用到这些技术。
基于字典的数据结构的实例之一就是SortedList. 这个类是按照分类顺序基于键值来存储键值对的. 这是一种有趣的数据结构, 因为通过引用数据结构中值的索引位置也可以访问到存储在结构中的数据, 这也使得结构的行为在某些方面和数组很相像. 本章的最后会讨论SortedList类的行为。
2、DictionaryBase类
大家可以把字典数据结构看成是一种计算机化的词典. 要搜索的词就是关键字, 而词的定义就是值. DictionaryBase类是一种用作专有字典实现基础的抽象类。
存储在字典中的键值对实际上是作为DictionaryEntry 对象来存储的. DictionaryEntry 结构提供了两个字段, 一个是关键字另一个是值. 在这个结构中所要关注的只是 Key 属性和Value 属性这两个属性(或方法). 当把键值对录入到字典内的时候, 这些方法会返回存储的值. 本章稍后会讨论DictionaryEntry 对象。
就内部而言, 会把键值对存储在被称为 InnerHashTable的哈希表对象中. 本书的第12 章会详细讨论哈希表, 所以现在只要把它看成是一种有效的用来存储键值对的数据就可以了.DictionaryBase类实际上实现了来自System.Collections命名空间的接口, IDictionary.此接口是本书稍后要研究的许多类的基础, 包括ListDictionary类和Hashtable类。
2.1、DictionaryBase类的基础方法和属性
在用字典对象进行操作的时候需要执行几种操作. 就最少操作数量而言, 需要 Add 方法来添加新数据, 需要Item 方法来取回数值, 需要Remove 方法来移除键值对, 还需要Clear方法来清除所有数据的数据结构。
首先查看一个继承了DictionaryBase的类. 下列代码说明了一个存储名字和 IP 地址的类的实现:
public class IPAddresses : DictionaryBase
{
public IPAddresses()
{
}
public void Add(string name, string ip)
{
base.InnerHashtable.Add(name, ip);
}
public string Item(string name)
{
return base.InnerHashtable[name].ToString();
}
public void Remove(string name)
{
base.InnerHashtable.Remove(name);
}
}
第一个实现的方法就是构造函数, 只需要调用针对基类的默认构造函数就行了. Add方法把名字/IP 地址对作为参数, 并把它们传递给在基本类中实例化的InnerHashTable 对象的Add方法。
Item 方法用来获得指定关键字对应的值. 这里把关键字传递给InnerHashTable对象相应的Item 方法. 然后会返回用关联的关键字存储在内部哈希表中的值。
最后, Remove 方法把参数传递给关联的内部哈希表的Remove 方法, 然后会把关键字和与关键字相关联的值从哈希表中移除掉。
下面来看看利用了这些方法的一个程序 :
static void Main()
{
IPAddresses myIPs = new IPAddresses();
myIPs.Add("张三", "192.155.12.1");
myIPs.Add("李四", "192.155.12.2");
myIPs.Add("王五", "192.155.12.3");
Console.WriteLine("总共有" + myIPs.Count + "个IP地址");
Console.WriteLine("张三的IP是 : " + myIPs.Item("张三"));
myIPs.Clear();
Console.WriteLine("清空了IP列表后, 还有" + myIPs.Count + "个IP地址");
Console.ReadLine();
}
程序运行的结果:

现在我们对类要做一个修改, 使构造函数重载以便于把来自文件的数据装载到字典内. 下面是新构造函数的代码, 此代码需要添加到上面的IPAddresses类内 :
public IPAddresses(string txtFile)
{
string line;
string[] words;
StreamReader inFile;
inFile = File.OpenText(txtFile);
while (inFile.Peek() != -1)
{
line = inFile.ReadLine();
words = line.Split(',');
this.InnerHashtable.Add(words[0], words[1]);
}
inFile.Close();
}
现在测试一下新的构造函数 :
static void Main()
{
IPAddresses myIPs = new IPAddresses(@"Test.txt");
Console.WriteLine("总共有{0}个IP地址", myIPs.Count);
Console.WriteLine("韩八的IP是: " + myIPs.Item("韩八"));
Console.WriteLine("孙九的IP是: " + myIPs.Item("孙九"));
Console.WriteLine("陈七的IP是: " + myIPs.Item("陈七"));
Console.ReadLine();
}
程序运行结果:

2.2、其他的DictionaryBase方法
还有两种方法, CopyTo 方法和GetEnumerator方法. 本小节来讨论这些方法。
CopyTo方法把字典的内容复制给一维的数组. 尽管可以把数组声明成 Object, 然后用CType函数把对象转换成为DictionaryEntry, 但是这里应该把数组声明成DictionaryEntry数组。
下面的代码段举例说明了CopyTo方法的用法 :
IPAddresses myIPs = new IPAddresses(@"Test.txt");
DictionaryEntry[] ips = new DictionaryEntry[myIPs.Count];
myIPs.CopyTo(ips, 0);
CopyTo方法需要两个参数: 要复制到的数组和开始复制的索引位置。
一旦把字典的数据放入数组, 就可以使用数组处理数据内容. 下面的代码简单的输出了全部的数组内容 :
for (int i = 0; i <= ips.GetUpperBound(0); i++)
Console.WriteLine(ips[i].ToString());
程序运行结果:
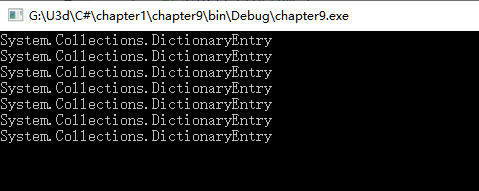
不幸的是, 程序输出的内容不是我们想要的. 问题原因就是, 我们向数组中存储的是DictionaryEntry对象, 所以如果用ToString方法输出数组元素本身, 看到的就是上面的内容。
为了真实地看到DictionaryEntry对象内的数据, 我们需要使用DictionaryEntry对象的 Key 属性或Value属性来查看其保存的键或值. 当字典的内容复制给DictionaryEntry数组的时候, 数据的复制就是根据键值的顺序进行的. 下面的代码可以正确的输出键和值 :
for(int i = 0; i <= ips.GetUpperBound(0); i++)
{
Console.WriteLine(ips[index].Key);
Console.WriteLine(ips[index].Value);
}
输出结果如下 : (顺序变了, 可以推测出InnerHashtable是有序的学了第十章哈希表之后, 才明白, 恰恰是因为InnerHashtable是无序才会这样)

3、KeyValuePair泛型类
C#提供了一种类用来创建象字典式的对象, 此对象是基于关键字来存储数据的。
这种类被称为是KeyValuePair类. 由于每个对象只能持有一个关键字和一个值, 所以它的用途有所局限。
一个KeyValuePair 对象可以向下面这样实例化:
KeyValuePair<string, int> mcmillan = new KeyValuePair<string, int>("McMillan", 99);
下面的代码分别获取键和值 :
Console.Write(mcmillan.Key);
Console.Write(" " + mcmillan.Value);
如果把对象放置在数组内, 那么KeyValuePair类是比较好用的. 下列程序举例说明如何实现简单的成绩单 :
static void Main()
{
KeyValuePair<string, int>[] gradeBook = new KeyValuePair<string, int>[10];
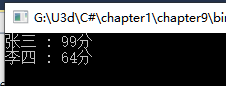
gradeBook[0] = new KeyValuePair<string, int>("张三", 99);
gradeBook[1] = new KeyValuePair<string, int>("李四", 64);
for (int i = 0; i <= gradeBook.GetUpperBound(0); i++)
if (gradeBook[i].Value != 0)
Console.WriteLine(gradeBook[i].Key + " : " + gradeBook[i].Value + "分");
Console.ReadLine();
}
程序运行结果:
4、SortedList类
正如在本章介绍部分提到的那样, SortedList基于键的值对其内部分键值对数据进行排序. 当存储数据的键的顺序很重要时可以使用这种数据结构. 比如, 在标准词典中希望所存储的词是按照字母的顺序存储的情况. 本章稍后还将说明如何用类来保存一个单独分类的值表。
4.1、使用SortedList类
既然SortedList 类是DictionaryBase 类的特殊化, 所以SortedList类可以按照许多和先前章节用类相同的方式来使用。
为了说明这一点, 下面的代码创建了包含三个名字和IP 地址的SortedList对象:
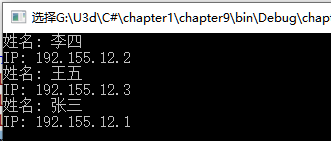
SortedList myips = new SortedList();
myips.Add("Mike", "192.155.12.1");
myips.Add("David", "192.155.12.2");
myips.Add("Bernica", "192.155.12.3");
这里的名字是键, 而IP 地址则是值。
SortedList类的泛型版本允许确定关键字和值两者的数据类型:
SortedList<Tkey, TValue>
例如, 可以把myips 象下面这样实例化 :
SortedList<string, string> myips = new SortedList<string, string>();
下列代码将遍历所有的键, 并以当前获取的键作为参数, 使用Item方法来获取对应的值 :
foreach (string key in myips.Keys)
Console.WriteLine("姓名: " + key + "\n" + "IP: " + myips[key]);
程序运行结果:
也可以通过引用索引来访问数据, 索引就是这些键值对数据在列表中实际存储据数据的数组内的位置. 如下所示 :
for (int i = 0; i < myips.Count; i++)
Console.WriteLine("姓名 : " + myips.Keys[i] + "\n" + "IP : " + myips.Values[i]);
结果跟上面的数据显示方式是一样的 :

还可以通过关键字或索引把键值对从SortedList中移除. 下面这段代码说明了这两种移除的方法:
myips.Remove("David");
myips.RemoveAt(1);
如果想要用索引访问SortedList, 但又不知道想要访问的键值对的索引, 那么可以用下面的方法获取索引 :
int indexZhang3 = myips.IndexOfKey("张三");
int indexIPZhang3 = myips.IndexOfValue(myips["张三"]);
SortedList类还包含了许多其他方法, 这里还是大家通过C#官方在线文档来学习它们.