价值一个亿的 Python 方法、函数总结,学妹直呼心疼哥哥
目录
- 阅读前必读(不看会错过一个亿)
- 一、字符串操作
-
- 1.1 capitalize() 方法——字符串首字母转换为大写
- 1.2 casefold() 方法——所有大写字符转换为小写
- 1.3 center() 方法——字符串居中填充
- 1.4 count() 方法——统计字符串出现次数
- 1.5 encode() 方法——编码字符串
- 1.6 decode() 方法——解码字符串
- 1.7 endswith() 方法——是否以指定子字符串结尾、startswith() 方法
- 1.8 find() 方法——字符串首次出现的索引位置(rfind()、index()、rindex())
- 1.9 format() 方法——格式化字符串
- 1.10 f-string ——格式化字符串
- 1.11 字符串的判断方法 isalnum()、isalpha()、isdecimal()、isdigit()、isidentifier()、islower()、isnumeric()、isprintable()、isspace()、istitle()、isupper()
- 1.12 join() 方法——连接字符串、元组、列表和字典
- 1.13 len() 函数——计算字符串长度或元素个数
- 1.14 ljust() 方法——字符串左对齐填充、rjust()方法——字符串右对齐填充
- 1.15 大小写转换方法 lower()、swapcase()、title()、upper()
- 1.16 lstrip() 方法——截掉字符串左边的空格或指定的字符
- 1.17 partition()方法——分割字符串为元组
- 1.18 replace() 方法——替换字符串
- 1.19 split() 方法——分割字符串
- 1.20 strip() 方法——去除字符串头尾特殊字符
- 1.21 zfill() 方法——字符串前面填充
- 二、列表
-
- 2.1 [] --直接创建列表
- 2.2 append() 方法--添加列表元素
- 2.3 clear() 方法--删除列表中的所有元素
- 2.4 copy() 方法--复制列表中所有元素
- 2.5 count() 方法--获取指定元素出现的次数
- 2.6 enumerate() 函数--遍历列表
- 2.7 extend() 方法--将序列的全部元素添加到另一列表中
- 2.8 index() 方法--获取指定元素首次出现的索引
- 2.9 insert() 方法--向列表的指定位置插入元素
- 2.10 not in --查找列表元素是否不存在
- 2.11 pop()方法--删除列表中的元素
- 2.12 remove() 方法--删除列表中的指定元素
- 2.13 reverse() 方法--反转列表中的所有元素
- 2.14 sort() 方法--排序列表元素
- 2.15 sorted() 函数--排序列表元素
- 2.16 sum() 函数--统计数值列表的元素和
- 2.17 print() 函数--输出列表内容
- 2.18 list() 函数--创建列表
- 三、元组
-
- 3.1 () --直接创建元组
- 3.2 del --删除元组
- 3.3 in --查找元组元素是否存在
- 3.4 len() 函数--计算元组元素个数
- 3.5 max() 函数--返回元组中元素最大值
- 3.6 tuple() 函数--将序列转换为元组
- 四、字典
-
- 4.1 {} --直接创建字典
- 4.2 clear() 方法--删除字典中的全部元素
- 4.3 copy() 方法--浅复制一个字典
- 4.4 del 关键字--删除字典或字典中指定的键
- 4.5 dict() 函数--创建字典
- 4.6 fromkeys() 方法--创建一个新字典
- 4.7 get() 方法--获取字典中指定键的值
- 4.8 items() 方法--获取字典的所有"键值对"
- 4.9 key in dict --判断指定键是否存在于字典中
- 4.10 keys() 方法--获取字典的所有键
- 4.11 pop() 方法--删除字典中指定键对应的键值对并返回被删除的值
- 4.12 popitem() 方法 --返回并删除字典中的键值对
- 4.13 setdefault() 方法--获取字典中指定键的值
- 4.14 update() 方法--更新字典
- 4.15 values() 方法--获取字典的所有值
- 五、集合
-
- 5.1 "{}" --直接创建集合
- 5.2 "&" --交集
- 5.3 "^" --对称差集
- 5.4 "|" --并集
- 5.5 "-" --差集
- 5.6 "<=" --判断当前集合是否为另一个集合的子集
- 5.7 "==" --判断两个集合是否相等
- 5.8 ">=" --判断当前集合是否为另一个集合的超集
- 5.9 add()方法 --向集合中添加元素
- 5.10 clear()方法 --删除集合中的全部元素
- 5.11 copy()方法 --复制一个集合
阅读前必读(不看会错过一个亿)
一、字符串操作
Chapter Three : Python 序列之字符串操作详解
1.1 capitalize() 方法——字符串首字母转换为大写
capitalize() 方法用于将字符串的首字母转换为大写,其他字母为小写。capitalize() 方法的语法格式如下:
def capitalize(self, *args, **kwargs):
"""
Return a capitalized version of the string.
More specifically, make the first character have upper case and the rest lower case.
"""
pass
⇒ str.capitalize()
【示例1】将字符串的首字母转换为大写。

【示例2】字符串全是大写字母只保留首字母大写。
cn = '没什么是你能做却办不到的事。'
en = "THERE'S NOTHING YOU CAN DO THAT CAN'T BE DONE."
print(cn)
print('原字符串:', en)
# 字符串转换为小写后首字母大写
print('转换后:', en.lower().capitalize())
运行程序,输出结果为:
没什么是你能做却办不到的事。
原字符串: THERE'S NOTHING YOU CAN DO THAT CAN'T BE DONE.
转换后: There's nothing you can do that can't be done.
【示例3】对指定位置字符串的首字母大写。
cn = '没什么是你能做却办不到的事。'
en = "There's nothing you can do that can't be done."
print(cn)
print('原字符串:', en)
# 对指定位置字符串转换为首字母大写
print(en[0:16] + en[16:].capitalize())
运行程序,输出结果为:

1.2 casefold() 方法——所有大写字符转换为小写
casefold() 方法是 Python3.3 版本之后引入的,其效果和 lower() 方法非常相似,都可以转换字符串中所有大写字符为小写。两者的区别是:lower() 方法只对 ASCII 编码,也就是 A-Z 有效,而 casefold() 方法对所有大写(包括非中英文的其他语言)都可以转换为小写。casefold() 方法的语法格式如下:
def casefold(self, *args, **kwargs): # real signature unknown
""" Return a version of the string suitable for caseless comparisons. """
pass
⇒ str.casefold()
⇒ 返回将字符串中所有大写字符转换为小写后生成的字符串。
【示例1】将字符串中的大写字母转换为小写。

【示例2】对非中英文的其他语言字符串中的大写转换为小写。

从以上结果看:lower() 方法没有进行转换,而 casefold() 方法将 ß 转换为小写字母 ss。因此,在对非中英文的其他语言字符串中的大写转换为小写时,应使用 casefold() 方法。
【示例3】判断英文短句是否为“回文”。首先科普下“回文”。在中文中,相同的词汇或句子调换位置或颠倒过来,产生首尾回环的情趣,叫做回文。例如,“客上天然居,居然天上客”;心清可品茶,茶品可清心。而在英语中,回文是一种英语修辞手法。英语中最著名的一个回文,是拿破仑被流放到Elba岛时说的一句话:Able was I ere I saw Elba(在我看到Elba岛之前,我曾所向无敌),这句话不论是从左向右看,还是从右向左看,内容都一样。下面我们就用Python来检测一下,首先需要将英文统一转换为小写,然后再进行判断,否则会影响判断结果。代码如下:
cn = '在我看到Elba岛之前,我曾所向无敌'
en = 'Able was I ere I saw Elba'
# 转换为小写
en = en.casefold()
# 反转字符串
rev_en = reversed(en)
print(cn)
print(en)
print(list(en))
print(list(reversed(en)))
# 判断字符串是否为“回文”
if list(en) == list(rev_en):
print('此句是回文!')
else:
print('此句不是回文!')
【示例4】判断小写字母在所在字符串中出现的次数。
import string
# 26个小写英文字母
chars = string.ascii_lowercase
print('26个小写英文字母:', chars)
test_str = 'AmoXiang is SO cool'
print('原字符串:', test_str)
test_str = test_str.casefold()
c = {
}.fromkeys(chars, 0)
# 统计小写字母出现的次数
for char in test_str:
if char in c:
c[char] += 1
print(c)
1.3 center() 方法——字符串居中填充
字符串对象的 center() 方法用于将字符串填充至指定长度,并将原字符串居中输出。center() 方法的语法格式如下:

width:参数表示要扩充的长度,即新字符串的总长度。
fillchar:参数表示要填充的字符,如果不指定该参数,则使用空格字符来填充。
【示例1】填充指定的字符串。
print('四川大学'.center(10)) # 长度为10,不指定填充字符,前后各填充3个空格
print('四川大学'.center(6, '-')) # 长度为6,指定填充字符,前后各填充一个'-'字符
print('四川大学'.center(5, '-')) # 长度为5,只在字符串前填充一个'-'字符
print('四川大学'.center(12, '-')) # 长度为12,字符串前后各填充4个'-'字符
print('四川大学'.center(3, '-')) # 长度为3,不足原字符串长度,输出原字符串
运行程序,输出结果为:
四川大学
-四川大学-
-四川大学
----四川大学----
四川大学
【示例2】文本按照顺序显示并且居中对齐。下面输出《中国诗词大会》中的经典诗词《锦瑟》,代码如下。
str1 = ['锦瑟',
'李商隐',
'锦瑟无端五十弦',
'一弦一柱思华年',
'庄生晓梦迷蝴蝶',
'望帝春心托杜鹃',
'沧海月明珠有泪',
'蓝田日暖玉生烟',
'此情可待成追忆',
'只是当时已惘然']
for str1_s in str1:
print('||%s||' % str1_s.center(11, ' '))
1.4 count() 方法——统计字符串出现次数
count() 方法用于统计字符串中某个字符出现的次数,如起始位置从 11 到结束位置 17 之间字符出现的次数,如下图所示。

count() 方法的语法格式如下:
str.count(sub,start,end)
参数说明:
- str:表示原字符串。
- sub:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,默认为第一个字符,索引值为 0,可单独指定。
- end:可选参数,表示检索范围的结束位置的索引,默认为字符串的最后一个位置,不可以单独指定。
例如,子字符串 o 在字符串 www.mingrisoft.com 起始位置从 11 到结束位置 17 之间中出现的次数,如下图所示:

注意:这里要注意一点,结束位置为17,但是统计字符个数时不包含17这个位置上的字符。例如结束位置为 16,那么o出现的次数为1。
【示例1】

【示例2】统计关键词在字符串中不同位置处出现的次数。
en = "There's nothing you can do that can't be done."
# 字母"o"在不同位置处出现的次数
print(en.count('o', 0, 17)) # 1
print(en.count('o', 0, 27)) # 3
print(en.count('o', 0, 47)) # 4
【示例3】统计字符串中的标点符号。首先通过 string 模块的 punctuation 常量获取所有标点符号,然后判断字典中每个字符是否为标点符号,如果是标点符号则使用 count() 方法进行统计,最后汇总,代码如下:
import string
count = 0
test_str = "https://blog.csdn.net/xw1680%$&,*,@!"
# 将输入的字符串创建一个新字典
c = {
}.fromkeys(test_str, 0)
for keys, values in c.items():
if keys in string.punctuation: # 统计标点符号
count = test_str.count(keys) + count
# 字符串中包含: 14 个标点符号
print('字符串中包含:', count, '个标点符号')
【示例4】统计文本中数字出现的个数。下面统计文本文件中数字出现的个数,如图所示。

示例代码:
import string
f = open('./digits.txt', 'r')
chars = f.read()
count = 0
# 将输入的字符串创建一个新字典
c = {
}.fromkeys(chars, 0)
for keys, values in c.items():
if keys in string.digits: # 统计数字
count = chars.count(keys) + count
print('文本中包含:', count, '个数字') # 14
1.5 encode() 方法——编码字符串
编码是将文本(字符串)转换成字节流,Unicode 格式转换成其他编码格式。在 Python 中提供了 encode() 方法,该方法的作用是将 Unicode 编码转换成其他编码的字符串,如下图所示。如 str1.encode(‘gbk’),表示将 Unicode 编码的字符串 str1 转换成 GBK 编码。

encode() 方法的语法格式如下:
str.encode([encoding="utf-8"][,errors="strict"])
参数说明:
- str:表示要进行转换的字符串。
- encoding=“utf-8”:可选参数,用于指定进行转码时采用的编码,默认为 utf-8,如果想使用简体中文可以设置为 gbk 或 gb2312(与网站使用的编码方式有关)。当只有一个参数时,可省略前面的
encoding=,直接写编码。 - errors=“strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或 xmlcharrefreplace(使用XML的字符引用)等,默认值为 strict。
【示例1】将指定字符串转为不同的编码格式。
test_str = '我爱Amo' # 定义字符串
utf8Str = test_str.encode(encoding='utf-8') # 采用utf-8编码
gbkStr = test_str.encode(encoding='gbk') # 采用GBK编码
print(utf8Str) # 输出utf-8编码内容:b'\xe6\x88\x91\xe7\x88\xb1Amo'
print(gbkStr) # 输出GBK编码内容:b'\xce\xd2\xb0\xaeAmo'
【示例2】Python中URL链接的编码处理。
最近在豆瓣电影搜索《千与千寻》的时候发现搜素链接是这样的:
https://movie.douban.com/subject_search?search_text=%E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB&cat=1002
很明显 千与千寻 被编码成了 %E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB,那么在 Python 中如何处理这种链接呢?首先来了解下 URL 编码方法:URL 编码方式是把需要编码的字符转化为 %xx 的形式。通常 URL 编码是基于 utf-8,也可能是 gbk 或 gb2312(这与网站使用的编码方式有关)。测试下上述链接中 URL 编码是否为 千与千寻,首先使用 encode() 方法将 千与千寻 的编码格式设置为 utf-8,然后使用 urllib 模块的 quote() 函数将转码后的字符串设置为 URL 编码,代码如下:
from urllib.parse import quote
from urllib.parse import unquote
# 编码测试
my_str1 = '千与千寻'.encode('utf-8')
# 使用urllib模块quote函数进行编码
my_str2 = quote(my_str1)
print(my_str2) # %E5%8D%83%E4%B8%8E%E5%8D%83%E5%AF%BB
# 使用urllib模块unquote函数进行解码
print(unquote(my_str2))
将结果与链接中的字符串对比完全一样,那么这种编码方式可以通过 urllib 模块的 unquote 函数进行解码。
1.6 decode() 方法——解码字符串
解码是将字节流转换成字符串(文本),其他编码格式转成 unicode。在 Python 中提供了 decode() 方法,该方法的作用是将其他编码的字符串转换成 unicode 编码,如 str1.decode(‘gb2312’),表示将 gb2312 编码的字符串 str1 转换成 unicode 编码。decode() 方法的语法格式如下:
bytes.decode([encoding="utf-8"][,errors="strict"])
参数说明:
- bytes:表示要进行转换的字节数据,通常是 encode() 方法转换的结果。
- encoding=“utf-8”:可选参数,用于指定进行解码时采用的字符编码,默认为 utf-8,如果想使用简体中文可以设置为 gbk 或 gb2312(与网站使用的编码方式有关)。当只有一个参数时,可省略前面的
encoding=,直接写编码。 - errors=“strict”:可选参数,用于指定错误处理方式,其可选择值可以是strict(遇到非法字符就抛出异常)、ignore(忽略非法字符)、replace(用“?”替换非法字符)或 xmlcharrefreplace(使用XML的字符引用)等,默认值为 strict。
【示例1】对指定的字符串进行解码。
# 定义字节编码
Bytes1 = bytes(b'\xe6\x88\x91\xe7\x88\xb1Amo')
# 定义字节编码
Bytes2 = bytes(b'\xce\xd2\xb0\xaeAmo')
str1 = Bytes1.decode("utf-8") # 进行utf-8解码
str2 = Bytes2.decode("gbk") # 进行gbk解码
print(str1) # 输出utf-8解码后的内容:我爱Amo
print(str2) # 输出gbk解码后的内容:我爱Amo
【示例2】解码爬虫获取的字节形式代码。在使用python爬取指定的网页时,获取的内容中,如果汉字都是字节码的情况下,可以通过 decode() 方法实现 html 代码的解码工作。代码如下:
import requests # 网络请求模块
# 对爬取目标发送网络请求
response = requests.get('https://www.baidu.com/')
html_bytes = response.content # 获取爬取的内容,该内容为字节形式
print(html_bytes) # 打印字节形式的html代码
print(html_bytes.decode('utf-8')) # 打印解码后的html代码
运行程序,输出结果为:

【示例3】操作不同编码格式的文件。建立一个文件 test1.txt,文件格式为 ANSI,内容如下:

用 Python 来读取,代码如下:
# 用python来读取
print(open('./test1.txt', encoding="gbk").read())
运行程序,输出结果为:
机器码:NH57Q35XD5MZVI7ZWL7H2UX0I
用户名:MZRCE44HHKBQ
将 test1.txt 另存为 test2.txt,并将编码格式改为 utf-8,再使用 Python 读取test2.txt,代码如下:
# 用python来读取
print(open('./test2.txt', encoding="gbk").read())
此时出现了乱码,这是由于字符经过不同编码解码再编码的过程中使用的编码格式不一致导致的。那么,接下来我们使用 decode() 方法进行解码,代码如下:
# 用python来读取
print(open('./test2.txt', encoding="utf8").read())
1.7 endswith() 方法——是否以指定子字符串结尾、startswith() 方法
endswith() 方法用于检索字符串是否以指定子字符串结尾。如果是则返回 True,否则返回 False。endswith() 方法的语法格式如下:
str.endswith(suffix[, start[, end]])
参数说明:
- str:表示原字符串。
- suffix:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
- end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
【示例1】 检索网址是否以“.com”结尾

【示例2】 筛选目录下所有以.txt结尾的文件。在开发项目过程中,经常会用到 python 判断一个字符串是否以某个字符串结尾,例如,筛选目录下所有以.txt结尾的文件,代码如下:
import os
file_list = os.listdir('./')
for item in file_list:
if item.endswith('.txt'):
print(item)
运行程序,输出结果为:

startswith() 方法——是否以指定的子字符串开头。
1.8 find() 方法——字符串首次出现的索引位置(rfind()、index()、rindex())
find() 方法实现查询一个字符串在其本身字符串对象中首次出现的索引位置,如起始位置从 11 到结束位置 17 之间子字符串出现的位置,如下图所示。如果没有检索到该字符串,则返回-1。

find() 方法的语法格式如下:
str.find(sub,start,end)
参数说明:
- str:表示原字符串。
- sub:表示要检索的子字符串。
- start:可选参数,表示检索范围的起始位置的索引,如果不指定,则从头开始检索。
- end :可选参数,表示检索范围的结束位置的索引,如果不指定,则一直检索到结尾。
例如,子字符串 o 在字符串 www.mingrisoft.com 起始位置从 11 到结束位置 17 之间首次出现的位置,如下图所示:

说明:Python 的字符串对象还提供了 rfind() 方法,其作用与 find() 方法类似,只是从字符串右边开始查找。Python 的字符串也提供了 index() 方法,它与 find() 方法功能相同,区别在于当 find() 方法没有检索到字符串时会返回 -1,而 index() 方法会抛出 ValueError 异常。
【示例1】 检索邮箱地址中“@”首次出现中的位置

【示例2】提取括号内数据。日常处理数据过程中,有时需要提取括号内的数据,例如下图所示括号内的手机号。

下面使用 find() 方法查找括号所在位置,然后使用切片方法提取括号内的手机号,代码如下:
str1 = '张三(13566688888)'
l1 = str1.find('(')
l2 = str1.find(')')
print(str1[l1 + 1:l2]) # 13566688888
【示例3】从邮箱地址提取ID并将首字母大写。一般情况下,邮箱地址都是由ID和服务器地址组成,那么通过邮箱地址就可以提取到ID或服务器地址。例如,提取ID并将首字母大写,效果如图所示。

下面使用 find() 方法查找字符串中 @ 的位置,然后使用切片方法提取 ID 并通过 capitalize() 方法设置首字母大写,代码如下:
with open('./email.txt', 'r') as file:
for value1 in file.readlines():
L = value1.find('@')
print(value1[0:L].capitalize())
运行程序,结果为:
Gcytom
Jackeer
Mingrisoft
Mrkj_2019
【示例4】查询字符串中指定字符的全部索引。Python 中字符串只提供了 index() 方法来获取指定字符的索引,但是该方法只能获取字符串中第一次出现的字符索引,所以要想获取字符串中指定字符的全部索引时需要通过自定义函数的方式来实现。代码如下:
str_index_list = [] # 保存指定字符的索引
def get_multiple_indexes(string, str):
str2 = string # 用于获取字符串总长度
while True: # 循环
if str in string: # 判断是否存在需要查找的字符
first_index = string.index(str) # 获取字符串中第一次出现的字符对应的索引
string = string[first_index + 1:] # 将每次找打的字符从字符串中截取掉
result = len(str2) - len(string) # 计算截取部分的长度
str_index_list.append(result - 1) # 长度减1就是字符所在的当前索引,将索引添加列表中
else:
break # 如果字符串中没有需要查找的字符就跳出循环
print(str_index_list) # 打印指定字符出现在字符串中的全部索引
s = "aaabbdddabb" # 测试用的字符串
# [0, 1, 2, 8]
get_multiple_indexes(s, 'a') # 调用自定义方法,获取字符串中指定字符的全部索引
rfind() 方法返回子字符串在字符串中最后一次出现的位置(从右向左查询),如果没有匹配项则返回-1。
rindex() 方法的作用与 index() 方法类似。rindex() 方法用于查询子字符串在字符串中最后出现的位置,如果没有匹配的字符串会报异常。另外,还可以指定开始位置和结束位置来设置查找的区间。
1.9 format() 方法——格式化字符串
全网最细 Python 格式化输出用法讲解
1.10 f-string ——格式化字符串
f-string 是格式化字符串的常量,它是 Python3.6 新引入的一种字符串格式化方法,主要目的是使格式化字符串的操作更加简便。f-string 在形式上是以 f 或 F 字母开头的字符串,然后通过一对单引号将要拼接的变量按顺序排列在一起,每个变量名称都需要使用一对花括号括起来,例如输出 IP 地址格式的字符串,如下图所示。

f-string 语法格式如下:
sval = f'{s1}{s2}{s3}……'
f-string 功能非常强大,而且使用起来也简单方便,因此 Python3.6 以上版本推荐使用 f-string 进行字符串格式化。下面详细介绍一下 f-string 在各个方面的应用。
【示例1】连接指定字符串。

【示例2】替换指定内容。f-string用花括号{}表示被替换字段,其中直接填入替换内容即可,代码如下:
name = 'Iphone12'
print(f'您购买的商品是:{name}')
number = 20210517
print(f'您的会员ID是:{number}')
price = 6300
print(f'您消费的金额是:{price}')
运行程序,输出结果为:
您购买的商品是:Iphone12
您的会员ID是:20210517
您消费的金额是:6300
【示例3】表达式求值与函数调用。f-string的大括号{}内还可以填入表达式或调用函数,Python会求出其结果并填入返回的字符串内,例如下面的代码。
print(f'结果为: {5 * 2 + 8}')
name = 'AMO'
print(f'转换为小写:{name.lower()}')
print(f'结果为: {(2 + 5j) / (2 - 2j)}') # 复数
【示例4】将数字格式化为二进制、八进制、十进制和十六进制。使用 f-string 可以实现将数字格式化为不同的进制数,省去了进制转换的麻烦,具体介绍如下:
- b:二进制整数格式
- d:十进制整数格式
- o:八进制整数格式
- x:十六进制整数格式(小写字母)
- X:十六进制整数格式(大写字母)
例如,将 12345 分别格式化为二进制、十进制、八进制和十六进制,代码如下:
a = 12345
print(f'二进制:{a:^#10b}') # 居中,宽度10位,二进制整数,显示前缀0b
print(f'十进制:{a:^#10d}') # 十进制整数
print(f'八进制:{a:^#10o}') # 八进制整数,显示前缀0o
print(f'十六进制:{a:^#10X}') # 十六进制整数(大写字母),显示前缀0X
运行程序,输出结果为:
二进制:0b11000000111001
十进制: 12345
八进制: 0o30071
十六进制: 0X3039
【示例5】字符串左对齐、右对齐和居中。f-string 支持三种对齐方式:
- <:左对齐(字符串默认对齐方式);
- >:右对齐(数值默认对齐方式);
- ^:居中。
下面以以左对齐、右对齐和居中输出 听天色等烟雨而我在等你,固定宽度 18 位,代码如下:
a = '听天色等烟雨而我在等你'
print(f'左对齐:{a:<18}') # 左对齐
print(f'右对齐:{a:>18}') # 右对齐
print(f'居中对齐:{a:^18}') # 居中对齐
运行程序,输出结果为:

【示例6】为数字添加千位分隔符。在数字中加进一个符号,可以避免因数字位数太多而难以看出它的值。一般每隔三位数加进一个逗号,也就是千位分隔符,以便更加容易认出数值。在Python中也可以实现这样的分隔符。下面使用f-string实现为数字加千位分隔符。f-string 可以使用逗号(,)和下划线(_)作为千位分隔符,其中逗号(,)仅适用于浮点数、复数与十进制整数,而对于浮点数和复数,逗号(,)只分隔小数点前的数位;下划线(_)适用于浮点数、复数和二进制、八进制、十进制和十六进制整数,对于浮点数和复数,下划线(_)只分隔小数点前的数位,而对于二进制、八进制、十六进制整数,固定从低位到高位每隔四位插入一个下划线(_),对于十进制整数则是每隔三位插入一个下划线(_)。下面举例说明,代码如下。
val1 = 123456.78
print(f'{val1:,}') # 浮点数使用,作为千位分隔符
val2 = 12345678
print(f'{val2:015,d}') # 高位补零,宽度15位,十进制整数,使用,作为千位分隔符
val3 = 0.5 + 2.5j
print(f'{val3:30.3e}') # 宽度30位,科学计数法,3位小数
val4 = 12345678988
print(f'{val4:_o}') # 八进制整数,使用_作为千位分隔符
【示例7】在f-string大括号内填入lambda表达式。f-string大括号内也可填入lambda表达式,但lambda表达式的冒号(:)会被f-string误认为是表达式与格式描述符之间的分隔符,为避免歧义,需要将lambda表达式置于括号()内,例如下面的代码:
# 结果为:16777217
print(f'结果为:{(lambda x: x ** 8 + 1)(8)}')
# 结果为:+257.0
print(f'结果为:{(lambda x: x ** 8 + 1)(2):<+8.1f}')
【示例8】将系统日期格式化为短日期。f-string可以对日期进行格式化,如格式化成类似系统中的短日期、长日期等,其适用于date、datetime和time对象,相关介绍如下:
- %d:表示日,是数字,以 0 补足两位
- %b:表示月(缩写)
- %B:表示月(全名)
- %m:表示月(数字,以 0 补足两位)
- %y:年(后两位数字,以 0 补足两位)
- %Y:年(完整数字,不补零)
下面输出当前系统日期并将其格式化为短日期格式,代码如下:
import datetime
e = datetime.datetime.today() # 获取当期系统日期
print('当前系统日期:', e)
print(f'短日期格式:{e:%Y/%m/%d}') # 短日期格式
print(f'短日期格式:{e:%Y-%m-%d}')
print(f'短日期格式:{e:%y-%b-%d}')
print(f'短日期格式:{e:%y-%B-%d}')
运行程序,输出结果为:

【示例9】将系统日期格式化为长日期。下面使用f-string将当前系统日期格式化为长日期格式,代码如下:
import datetime
e = datetime.datetime.today()
# 当前系统日期: 2021-05-17 12:59:10.275374
print('当前系统日期:', e) # 当期系统日期
# 长日期格式:2021年05月17日
print(f'长日期格式:{e:%Y年%m月%d日}') # 长日期格式
【示例10】根据系统日期返回星期几。f-string 可以根据系统日期返回星期(数字),相关介绍如下:
- %a:星期几(缩写),如 ‘Sun’;
- %A:星期几(全名),如 ‘Sunday’;
- %w:星期几(数字,0 是星期日、6 是星期六),如 ‘0’
- %u:星期几(数字,1 是星期一、7 是星期日),如 ‘7’
下面使用 f-string 中的 %w 返回当前系统日期的星期。由于返回的星期是数字,还需要通过自定义函数进行转换,0 表示星期日,依次排列直到星期六,代码如下:
import datetime
e = datetime.datetime.today() # 获取当前系统日期
# 定义数字星期返回星期几的函数
def get_week(date):
week_dict = {
0: '星期日',
1: '星期一',
2: '星期二',
3: '星期三',
4: '星期四',
5: '星期五',
6: '星期六',
}
day = int(f'{e:%w}') # 根据系统日期返回数字星期并转换为整型
return week_dict[day]
print(f'今天是:{e:%Y年%m月%d日}') # 长日期格式
print(get_week(datetime.datetime.today())) # 调用函数返回星期几
运行程序,输出结果为:

【示例11】判断当前系统日期是今年的第几天第几周。f-string可以根据当前系统日期返回一年中的第几天和第几周,相关介绍如下:
- %j:一年中的第几天(以0补足三位),如 2019年1月1日 返回 ‘001’
- %U:一年中的第几周(以全年首个周日后的星期为第 0 周,以 0 补足两位,如 ‘00’),如 ‘30’
- %W:一年中的第几周(以全年首个周一后的星期为第 0 周,以 0 补足两位,如 ‘00’),如 ‘30’
- %V:一年中的第几周(以全年首个星期为第 1 周,以 0 补足两位,如 ‘01’),如 ‘31’。
下面分别使用 f-string 中的 %j 返回当前系统日期是一年中的第几天、使用 %U、%W 和 %V 返回当前系统日期是一年中的第几周,代码如下:
import datetime
e = datetime.datetime.today() # 获取当前系统日期
print(f'今天是:2021年的第{e:%j}天') # 返回一年中的第几天
print(f'今天是:2021年的第{e:%U}周') # 返回一年中的第几周
print(f'今天是:2021年的第{e:%W}周')
print(f'今天是:2021年的第{e:%V}周')
运行程序,输出结果为:

【示例12】根据当前系统日期返回时间。f-string可以根据当前系统日期返回时间,相关介绍如下:
- %H:小时(24小时制,以 0 补足两位),如 ‘14’
- %I:小时(12小时制,以 0 补足两位),如 ‘02’
- %p:上午/下午,如上午为 ‘AM’,下午为 ‘PM’
- %M:分钟(以 0 补足两位),如 ‘48’
- %S:秒(以 0 补足两位),如 ‘48’
- %f:微秒(以 0 补足六位),如 ‘734095’
下面根据当前系统日期返回时间,代码如下:
import datetime
e = datetime.datetime.today()
print(f'今天是:{e:%Y年%m月%d日}') # 长日期格式
print(f'时间是:{e:%H:%M:%S}') # 返回当前时间
print(f'时间是:{e:%H时%M分%S秒 %f微秒}') # 返回当前时间到微秒(24小时制)
print(f'时间是:{e:%p%I时%M分%S秒 %f微秒}') # 返回当前时间到微秒(12小时制)
运行程序,输出结果为:

1.11 字符串的判断方法 isalnum()、isalpha()、isdecimal()、isdigit()、isidentifier()、islower()、isnumeric()、isprintable()、isspace()、istitle()、isupper()
1. isalnum() 方法用于判断字符串是否由字母和数字组成。如果字符串中至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False。

2. isalpha() 方法用于判断字符串是否只由字母组成。如果字符串中至少有一个字符并且所有字符都是字母则返回 True,否则返回 False。

3. isdecimal() 方法用于检查字符串是否只包含十进制字符。这种方法只适用于 unicode 对象。定义一个十进制字符串,只要在字符串前添加 u 前缀即可。如果字符串只包含数字则返回 True,否则返回 False。

4. isdigit() 方法——判断字符串是否只由数字组成。如果字符串只包含数字则返回 True,否则返回 False。
【示例1】数字转换为整型前进行判断。将数字转换为整型时,如果用户输入的不是数字那么使用 int() 函数进行转换时将出现错误提示,此时可以通过 isdigit() 方法先判断用户输入的是否为数字,如果是数字则转换为整型,否则提示用户重新输入,代码如下:
while True:
str1 = input('请输入数字:')
# 使用isdigit()方法判断是否为全数字
my_val = str1.isdigit()
if my_val:
str_int = (int(str1)) # 将数字转换为整型
print(str_int) # 输出
print(type(str_int)) # 判断类型
break
else:
print('不是数字,请重新输入!')
运行程序,输出结果为:

5. isidentifier() 方法用于判断字符串是否是有效的Python标识符,还可以用来判断变量名是否合法。如果字符串是有效的Python标识符返回True,否则返回False。
【示例1】判断字符串是否为Python标识符或者变量名是否合法。
print('if'.isidentifier()) # True
print('break'.isidentifier()) # True
print('while'.isidentifier()) # True
print('_b'.isidentifier()) # True
print('重庆大学888m'.isidentifier()) # True
print('886'.isidentifier()) # False
print('8a'.isidentifier()) # False
print(''.isidentifier()) # False
6. islower() 方法——判断字符串是否全由小写字母组成。如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是小写,则返回True,否则返回False。

7. isnumeric()方法——判断字符串是否只由数字(支持罗马数字、汉字数字等)组成。如果字符串只由数字组成,则返回True,否则返回False。
【示例1】判断字符串只由数字组成。
str1 = u'mr12468'
print(str1.isnumeric()) # False
str1 = u'12468'
print(str1.isnumeric()) # True
str1 = u'ⅠⅡⅣⅦⅨ'
print(str1.isnumeric()) # True
str1 = u'㈠㈡㈣㈥㈧'
print(str1.isnumeric()) # True
str1 = u'①②④⑥⑧'
print(str1.isnumeric()) # True
str1 = u'⑴⑵⑷⑹⑻'
print(str1.isnumeric()) # True
str1 = u'⒈⒉⒋⒍⒏'
print(str1.isnumeric()) # True
str1 = u'壹贰肆陆捌uuu'
print(str1.isnumeric()) # False
从运行结果看,isnumeric() 方法不仅支持 Unicode 数字、还支持全角数字(双字节)、罗马数字以及汉字数字。
【示例2】简易滤除字符串列表中的数字。如果想从一个含有数字、汉字和字母的列表中滤除仅含有数字的字符,那么可以使用正则表达式来完成,但是如果觉得麻烦,还可以使用 isnumeric() 方法,代码如下:
str1 = ['AMO', '2019', 'AMO88', '12', u'小柒']
for s in str1:
if not s.isnumeric(): # 滤除数字
print(s)
8. isprintable()方法——判断字符是否为可打印字符。isprintable() 方法用于判断字符串中所有字符是否都是可打印字符或字符串为空。Unicode 字符集中“Other”、“Separator”类别的字符是不可打印的字符(但不包括ASCII码中的空格(0x20)。isprintable() 方法可用于判断转义字符。
说明:ASCII码中第0~32号及第127号是控制字符;第33~126号是可打印字符,其中第48~57号为0~9十个阿拉伯数字;65~90号为26个大写英文字母,97~122号为26个小写英文字母。如果字符串中的所有字符都是可打印的字符或字符串为空则返回True,否则返回False。
【示例1】判断字符串中的所有字符是否都是可打印的。
str1 = '\n\t'
print(str1.isprintable()) # False
str1 = 'mr_soft'
print(str1.isprintable()) # True
str1 = '12345'
print(str1.isprintable()) # True
str1 = '蜘蛛侠'
print(str1.isprintable()) # True
9. isspace()方法——判断字符串是否只由空格组成。如果字符串中只包含空格,则返回True,否则返回False。
【示例1】判断字符串是否由空格组成。

10. istitle()方法——判断首字母是否大写其他字母小写。如果字符串中所有的单词首字母为大写而其他字母为小写则返回True,否则返回False。
【示例1】判断字符串中所有的单词首字母是否为大写。

11. isupper()方法——判断字符串是否全由大写字母组成。如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是大写,则返回True,否则返回False。
【示例1】判断字符串完全由大写字母组成。

1.12 join() 方法——连接字符串、元组、列表和字典
join() 方法用于连接字符串列表。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串,例如下图所示:

join() 方法的语法如下:
str.join(sequence)
- str:分隔符,即用什么连接字符串,可以是逗号“,”、冒号“:”、分号“;”和斜杠“/”等等,也可以为空。
- sequence:可以是字符串、字符串数组、列表、元组或字典等。
下面通过一个简单的举例来了解一下 join() 方法的用法。例如连接字符串列表“四”、“川”、“大”、“学”,代码如下:
s = ['四', '川', '大', '学']
print(''.join(s)) # 四川大学
print('-'.join(s)) # 四-川-大-学
print('/'.join(s)) # 四/川/大/学
【示例1】将NBA元组数据输出NBA对阵数据(元组转文本)。有这样一组元组数据“(‘凯尔特人’,‘雄鹿’),(‘猛龙’,‘雄鹿’),(‘雄鹿’,‘篮网’),(‘老鹰’,‘雄鹿’),(‘雷霆’,‘雄鹿’),(‘热火’,‘雄鹿’)”,将每组对阵用vs连接,代码如下:
# 定义元组
my_str = (('凯尔特人', '雄鹿'), ('猛龙', '雄鹿'), ('雄鹿', '篮网'), ('老鹰', '雄鹿'), ('雷霆', '雄鹿'), ('热火', '雄鹿'))
# 遍历元组
number = [tuple(x) for x in my_str]
for i in number:
newStr = ' vs '.join(tuple(i)) # 用vs连接元组
print(newStr)
运行程序,输出结果为:
凯尔特人 vs 雄鹿
猛龙 vs 雄鹿
雄鹿 vs 篮网
老鹰 vs 雄鹿
雷霆 vs 雄鹿
热火 vs 雄鹿
【示例2】以不同方式连接音乐列表(列表转文本)。
music = ['辞九门回忆', '会不会', '单身情歌', '错位时空', '红色高跟鞋']
print(music)
print(' '.join(music))
print('\n'.join(music))
print('\t'.join(music))
【示例3】连接字典(字典转文本)。
# 定义字典
my_str = {
'四': 1, '川': 2, '大': 3, '学': 4}
print(':'.join(my_str))
【示例4】创建由小写字母和数字组合的18位随机码。
import random
import string
# b2j4c0f95odmqz7nga
print(''.join(random.sample(string.ascii_lowercase + string.digits, 18)))
1.13 len() 函数——计算字符串长度或元素个数
len() 函数的主要功能是获取一个(字符、列表、元组等)可迭代对象的长度或项目个数。其语法格式如下:
len(s)
参数说明:
- 参数s:要获取其长度或者项目个数的对象。如字符串、元组、列表、字典等;
- 返回值:对象长度或项目个数。
【示例1】获取字符串长度。
# 字符串中每个符号仅占用一个位置,所以该字符串长度为34
str1 = '今天会很残酷,明天会更残酷,后天会很美好,但大部分人会死在明天晚上。'
# 在获取字符串长度时,空格也需要占用一个位置,所以该字符串长度为10
str2 = 'hello word'
print('str1字符串的长度为:', len(str1)) # 打印str1字符串长度 34
print('str2字符串的长度为', len(str2)) # 打印str2字符串长度 10
# 打印str2字符串去除空格后的长度
print('str2字符串去除空格后的长度为:', len(str2.replace(' ', ''))) # 9
【示例2】计算字符串的字节长度。
def byte_size(string):
return len(string.encode('utf-8')) # 使用encode()函数设置编码格式
print(byte_size('Hello World')) # 11
print(byte_size('人生苦短,我用Python')) # 27
"""
说明:在utf-8编码格式下,一个中文占3个字节。
"""
1.14 ljust() 方法——字符串左对齐填充、rjust()方法——字符串右对齐填充
字符串对象的 ljust 方法是用于将字符串进行左对齐右侧填充。ljust() 方法的语法格式如下:
str.ljust(width[,fillchar])
- width 参数表示要扩充的长度,即新字符串的总长度。
- fillchar 参数表示要填充的字符,如果不指定该参数,则使用空格字符来填充。
【示例1】 左对齐填充指定的字符串。以各种方式填充字符串“四川大学”并且左对齐,代码如下:
print("四川大学".ljust(8)) # 长度为8,不指定填充字符,字符串后由4个空格字符来填充
print("四川大学".ljust(5, "-")) # 长度为5,指定填充字符,字符串后填充一个"-"字符
print("四川大学".ljust(3, "-")) # 长度为3,不足原字符串长度,输出原字符串
【示例2】 ljust()方法通过统计字符长度后填充空格的方式使输出的字符串对齐,但ljust()方法在填充包含中英文字符串的时候,填充后的长度总是不对,导致输出无法真正对齐。其根本原因在于ljust()方法统计字符长度时,英文占1个字符位,中文占2个字符位,而由于 Python3 的 utf-8 编码方式,中英文都占1字符位,而gbk编码方式是英文1字符位,中文2字符位。因此,解决该问题应首先更改编码方式,然后再使用ljust()方法对齐,对齐后的效果如下图所示。

代码如下:
u_list = list()
u_list.append([1, '北京大学', 'Peking University', '685'])
u_list.append([2, '中国人民大学', 'Renmin University of China', '685'])
u_list.append([3, '浙江大学', 'Zhejiang University', '676'])
u_list.append([4, '武汉大学', 'Wuhan University', '632'])
u_list.append([5, 'mrsoft', 'mrsoft', '123'])
u_list.append([6, 'mr学院', 'mr College', '123'])
for ul in u_list:
len1 = len(ul[1].encode('gbk')) - len(ul[1]) # 更改编码方式后计算字符串长度
print(ul[0], ul[1].ljust(20 - len1), ul[2], ul[3].rjust(30 - len(ul[2]))) # 使用ljust()和rjust()方法对齐
1.15 大小写转换方法 lower()、swapcase()、title()、upper()
1. lower() 方法——大写字母转换为小写字母。如果字符串中没有需要被转换的字符,则将原字符串返回;否则将返回一个新的字符串,将原字符串中每个需要进行小写转换的字符都转换成等价的小写字符,且字符长度与原字符长度相同。

2. swapcase() 方法用于对字符串的大小写字母进行转换并生成新的字符串,原字符串中的字母大写使用swapcase()方法后会转成小写;原字符串中的字母小写使用swapcase()方法后会转成大写。

3. title() 方法——单词首字母转换为大写

4. upper()方法用于将字符串中的小写字母转换为大写字母。如果字符串中没有需要被转换的字符,则将原字符串返回;否则返回一个新字符串,将原字符串中每个需要进行大写转换的字符都转换成等价的大写字符,且新字符长度与原字符长度相同。

1.16 lstrip() 方法——截掉字符串左边的空格或指定的字符
lstrip() 方法用于截掉字符串左边的空格或指定的字符。lstrip() 方法的语法格式如下:
str.lstrip([chars])
参数说明:
- str:原字符串。
- chars:指定要截掉的字符串,可以是一个字符,或者多个字符,匹配时不是按照整个字符串匹配的,而是按照顺序一个个字符匹配的。
- 返回值:返回截掉字符串左边的空格或指定字符后生成的新字符串。
【示例1】去除字符串左边无用的字符。
str1 = '*****amoxiang***'
print(str1.lstrip('*'))
print(str1.lstrip('**'))
print(str1.lstrip('****'))
print(str1.lstrip('*i')) # 一个个字符匹配,i与原字符不匹配
1.17 partition()方法——分割字符串为元组
partition() 方法根据指定的分隔符将字符串进行分割。如果字符串中包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子字符串,第二个为分隔符本身,第三个为分隔符右边的子字符串,如下图所示:

partition() 方法的语法格式如下:
str.partition(str)
【示例1】以“.”为分隔符将网址分割为元组。
pythonUrl = 'https://blog.csdn.net/xw1680?' # 定义字符串
t1 = pythonUrl.partition('.') # 以"."分割
# ('https://blog', '.', 'csdn.net/xw1680?')
print(t1)
rpartition() 方法与 partition() 方法基本一样,细微区别在于 rpartition() 方法是从目标字符串的末尾也就是右边开始搜索分割符。

1.18 replace() 方法——替换字符串
replace() 方法用于将某一字符串中一部分字符替换为指定的新字符,如果不指定新字符,那么原字符将被直接去除,例如图1和图2所示的效果。

replace() 方法的语法格式如下:
str.replace(old [, new [, count]])
- old:将被替换的子字符串。
- new:字符串,用于替换old子字符串。
- count:可选参数,表示要替换的次数,如果不指定该参数则替换所有匹配字符,而指定替换次数时的替换顺序是从左向右依次替换。
【示例1】替换字符串中指定的字符。
str1 = 'www.baidu.com'
# www.douban.com
print(str1.replace('baidu', 'douban'))
【示例2】身份证号中的重要数字用星号代替。身份证号或手机号等重要的数据不能随意传递,可以把其中的几个重要数字用星号代替,以起到保护隐私的作用,如下图所示。

下面使用 replace() 方法将身份证号中间 8 位替换为星号 *,代码如下:
str1 = '333333201501012222'
s1 = str1[6:14]
# 333333********2222
print(str1.replace(s1, '********'))
1.19 split() 方法——分割字符串
split() 方法可以把一个字符串按照指定的分隔符切分为字符串列表,例如下图所示的效果。该列表的元素中,不包括分隔符。

split() 方法的语法格式如下:
str.split(sep, maxsplit)
参数说明:
- str:表示要进行分割的字符串。
- sep:用于指定分隔符,可以包含多个字符,默认为 None,即所有空字符(包括空格、换行“\n”、制表符“\t”等)。
- maxsplit:可选参数,用于指定分割的次数,如果不指定或者为 -1,则分割次数没有限制,否则返回结果列表的元素个数,个数最多为 maxsplit+1。
- 返回值:分隔后的字符串列表。
说明:在 split() 方法中,如果不指定 sep 参数,那么也不能指定 maxsplit参数。在使用split()方法时,如果不指定参数,默认采用空白符进行分割,这时无论有几个空格或者空白符都将作为一个分隔符进行分割。
【示例1】根据不同的分隔符分割字符串。
str1 = 'www.baidu.com'
list1 = str1.split() # 采用默认分隔符进行分割
list2 = str1.split('.') # 采用.号进行分割
list3 = str1.split(' ', 1) # 采用空格进行分割,并且只分割第1个
print(list1) # ['www.baidu.com']
print(list2[1]) # baidu
print(list3) # ['www.baidu.com']
【示例2】删除字符串中连续多个空格而保留一个空格。
line = '吉林省 长春市 二道区 东方广场中意之尊888'
# 吉林省 长春市 二道区 东方广场中意之尊888
print(' '.join(line.split()))
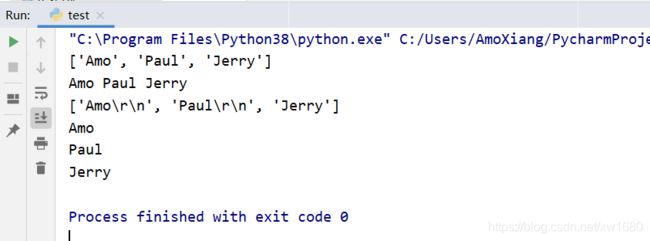
splitlines() 方法——返回是否包含换行符的列表。splitlines() 方法用于按照换行符(\r、\r\n、\n) 分割,返回一个是否包含换行符的列表,如果参数 keepends 为 False,则不包含换行符,如果为 True,则包含换行符。
str1 = 'Amo\r\nPaul\r\nJerry'
list1 = str1.splitlines() # 不带换行符的列表
print(list1)
print(list1[0], list1[1], list1[2])
list2 = str1.splitlines(True) # 带换行符的列表
print(list2)
print(list2[0], list2[1], list2[2], sep='') # 使用sep去掉空格
运行程序,效果如下图所示:
1.20 strip() 方法——去除字符串头尾特殊字符
strip() 方法用于移除字符串左右两边的空格和特殊字符,例如图1所示的效果。

strip() 方法的语法格式如下:
str.strip([chars])
参数说明:
- str:原字符串。
- chars:为可选参数,用于指定要去除的字符,可以指定多个。例如,设置chars为
*,则去除左、右两侧包括的或*。如果不指定 chars 参数,默认将去除字符串左右两边的空格、制表符\t、回车符\r、换行符\n等。

1.21 zfill() 方法——字符串前面填充
zfill() 方法返回指定长度的字符串,原字符串右对齐,字符串前面填充 0。zfill() 方法语法格式如下:
str.zfill(width)
# width:指定字符串的长度。原字符串右对齐,前面填充0。
【示例1】数字编号固定五位前面补零。
n = '886'
s = n.zfill(5)
# 学生学号为: 00886
print('学生学号为:', s)
【示例2】循环自动编号。
data_sort = []
i = 0
data = '莱科宁 236,汉密尔顿 358,维泰尔 294,维斯塔潘 216,博塔斯 227' # 字符串数据
new_list = data.split(',') # 将字符串数据分割为列表
# 将车手与积分数据添加到新的列表中
for item in new_list:
open_data = item.split(' ')
data_sort.append([open_data[1], open_data[0]])
data_sort.sort(reverse=True) # 数据降序排列
print('输出F1大奖赛车手积分'.center(25), '\n')
print('排名 车手 积分')
# 循环打印每个赛车手与对应积分
for item in data_sort:
i = i + 1
print(str(i).zfill(2).ljust(6), item[1].ljust(10) + '\t', item[0].ljust(6) + '\t')
运行程序,效果如下图所示:

【示例3】实现复杂的数字编号。
import random # 导入随机模块
char = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F'] # 随机数据
shop = '100000056303' # 固定编号
prize = [] # 保存抽奖号码的列表
inside = '' # 中段编码
amount = input('请输入购物金额:') # 获取输入金额
many = int(int(amount) / 100)
if int(amount) >= 100:
# 随机生成中段7为编码
for i in range(0, 7):
if inside == '':
inside = random.choice(char)
else:
inside = inside + random.choice(char)
# 生成尾部4为数字,并将组合的抽奖号添加至列表
for i in range(0, many):
number = str(i + 1).zfill(4)
prize.append([shop, inside, number])
else:
print('购物金额低于100元,不能参加抽奖!!!')
print('本次购物抽奖号码')
# 输出最终的抽奖号码
for item in prize:
print(''.join(item))
运行程序,效果如下图所示:

二、列表
2.1 [] --直接创建列表
在 Python 中,可以直接通过中括号 [] 创建列表,创建列表时,在中括号的内容放置由逗号分隔的元素。其语法格式如下:
listname = [element1,element2,element3,…,elementn]
参数说明:
- listname表示列表的名称,可以是任何符合 Python 命名规则的标识符。
- element 1、element 2、element 3、element n:表示列表中的元素,个数没有限制,并且只要是 Python 支持的数据类型就可以。
【示例1】通过“=”符号定义列表。
num = [7, 14, 21, 28, 35, 42, 49, 56, 63] # 定义数值型列表
verse = ['埃及金字塔', '巴比伦空中花园', '宙斯神像', '亚历山大灯塔'] # 定义字符型列表
python = ['优雅', "明确", '''简单'''] # 定义注释字符型列表
print('num列表内容为:', num)
print('verse列表内容为:', verse)
print('python列表内容为:', python)
【示例2】通过“=”符号定义二维列表。
# 定义二维列表
untitle = ['Python', 28, '人生苦短,我用Python', ['爬虫', '自动化运维', '云计算', 'Web开发']]
print('untitle列表内容为:', untitle)
【示例3】通过列表推导式生成列表。
import random
list1 = [i for i in range(10)] # 创建0~10之间(不包括10)的数字列表
print(list1)
list2 = [i for i in range(10, 100, 10)] # 创建10~100之间(不包括100)的整十数列表
print(list2)
# 创建10个4位数的随机数列表
list3 = [random.randint(1000, 10000) for i in range(10)]
print(list3)
list4 = [i for i in '壹贰叁肆伍'] # 将字符串转换为列表
print(list4)
# 生成所有单词首字母列表
list5 = [i[0] for i in ['Early', 'bird', 'gets', 'the', 'worm']]
print(list5)
# 将原列表中的数字折半后生成新的列表
list6 = [int(i * 0.5) for i in [1200, 5608, 4314, 6060, 5210]]
print(list6)
list7 = [i for i in ('Early', 'bird', 'gets', 'the', 'worm')] # 通过元组生成新的列表
print(list7)
# 将字典的Key生成新的列表
list8 = [key for key in {
'qq': '84978981', 'mr': '84978982', 'wgh': '84978980'}]
print(list8)
list9 = [key for key in {
1, 3, 5, 7, 9}] # 通过集合生成有序列表
print(list9)
2.2 append() 方法–添加列表元素
列表对象的 append() 方法,是用于向列表的末尾追加元素。其语法格式如下:
listname.append(obj)
参数说明:
- listname:表示要添加元素的列表名称。
- obj:表示要添加到列表末尾的对象。
【示例1】 向列表中添加指定元素。定义一个包括5个元素的列表,然后应用append()方法向该列表的末尾再添加一个元素,示例代码如下:
building = ['醉翁亭', '放鹤亭', '喜雨亭', '陶然亭', '爱晚亭'] # 原列表
print('原列表:', building) # 打印原列表
building.append('湖心亭') # 向列表的末尾添加元素
print('添加元素后的列表:', building) # 打印添加元素后的列表
输出结果为:

【示例2】 向列表中添加类型不同的元素。append()方法向列表末尾添加的元素类型可以与原列表中的元素类型不同。示例代码如下:
building = ['刀', '枪', '剑', '戟']
print('原列表:', building)
building.append(['scoop', 50]) # 向列表中添加列表类型的元素
print('添加列表类型元素后的新列表:', building)
building.append((100, 200)) # 向列表中添加元组类型的元素
print('添加元组类型元素后的新列表:', building)
building.append(9) # 向列表中添加数值类型的元素
print('添加数值类型元素后的新列表:', building)
【示例3】 将txt文件中的信息添加至列表中。首先需要以读取文件的方式打开目标文件,然后循环遍历文件中每行内容,再将每行内容添加至指定的列表中。示例代码如下:
result = [] # 保存txt每行数据
print('txt文件内信息如下:')
# 以读取模式打开txt文件
with open('user-name.txt', 'r') as f:
for line in f: # 循环遍历每行信息
print(line.strip('\n'))
result.append(line.strip('\n')) # 将txt文件中每行信息添加至列表中
print('提取后的信息为:', result) # 打印提取后的信息
输出结果为:
txt文件内信息如下:
zhangsan77421
lisi88548
wangqi2654
wangxiaoer400
wangsinan333
zhangjing111
提取后的信息为: ['zhangsan77421', 'lisi88548', 'wangqi2654', 'wangxiaoer400', 'wangsinan333', 'zhangjing111']
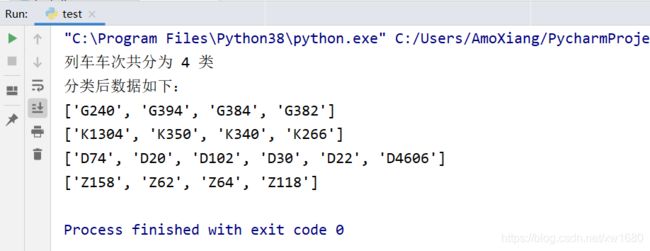
【示例4】根据列表字符元素首字母对字符元素分类。创建列车车次的列表数据,再分别创建一个保存分类后数据的列表与保存车次分类首字母的集合。通过for循环获取列车车次数据中有哪几种首字母,然后根据首字母对车次信息进行分类即可。示例代码如下:
# 列车车次数据
train = ['D74', 'D20', 'G240', 'D102', 'Z158', 'G394', 'K1304', 'D30', 'D22', 'G384', 'G382', 'D4606', 'K350', 'K340',
'Z62', 'Z64', 'K266', 'Z118']
result = [] # 保存分类后数据
type_set = set() # 保存分类首字母
for i in train: # 遍历车次信息
type_set.add(i[0]) # 将首字母添加至集合中
print('列车车次共分为', len(type_set), '类')
for index, z in enumerate(type_set): # 遍历车次分类的首字母
result.append([]) # 根据分类数量,向分类后数据列表中添加空列表
for t in train: # 循环遍历车次信息
if t[0] == z: # 如果车次信息首字母相同
result[index].append(t) # 将该车次信息添加至当前首字母分类中
print('分类后数据如下:')
for r in result: # 循环遍历分类后数据
print(r)
输出结果为:
【示例5】通过循环遍历筛选列表中的重复元素。循环遍历带有重复元素的列表,然后判断用于保存筛选后的数据列表中是否存在当前遍历的元素,不存在就将该元素添加至保存筛选后的数据列表中,最后打印筛选后的列表内容。代码如下:
info_list = [1, 2, 2, 3, 4, 4, 5, 5, 5, 6, 7, 8, 9] # 重复元素的列表数据
new_list = [] # 保存筛选后的数据列表
for i in info_list: # 遍历重复元素的列表
if i not in new_list: # 判断元素是否存在new_list列表中
new_list.append(i) # 不存在就添加进new_list列表中
print(new_list) # 打印筛选后的列表[1, 2, 3, 4, 5, 6, 7, 8, 9]
【示例6】通过列表推导式的方式筛选列表中的重复元素。
info_list = [1, 2, 2, 3, 4, 4, 5, 5, 5, 6, 7, 8, 9] # 重复元素的列表数据
new_list = [] # 保存筛选后的数据列表
# 通过列表推导式的方式筛选列表中的重复元素
[new_list.append(i) for i in info_list if i not in new_list]
print(new_list) # 打印筛选后的列表[1, 2, 3, 4, 5, 6, 7, 8, 9]
【示例7】随机生成双色球7个号码。在实现双色球7个号码的获取时,首先在while循环中从1~33的数字内依次随机生成6个红色号码并将号码添加至列表当中,然后再从1~16的数字中随机生成1个蓝色号码添加列表后跳出while循环,输出列表中随机生成的双色球7个号码。示例代码如下:
import random # 导入随机模块
number_list = [] # 保存双色球中奖号码
# 循环随机抽取号码
while True:
red_number = random.randint(1, 33) # 随机生成红球号码
if red_number not in number_list:
number_list.append(red_number) # 将选取的红球号码添加至列表
if len(number_list) == 6:
blue_number = random.randint(1, 16) # 随机生成红球号码
number_list.append(blue_number) # 将选取的蓝球号码添加至列表
break # 篮球号码添加完成以后跳出循环
print(number_list) # [26, 5, 21, 31, 20, 14, 7]
2.3 clear() 方法–删除列表中的所有元素
使用 clear() 方法可以删除列表中的所有元素。其语法格式如下:
listname.clear() # listname:表示列表的名称。
【示例1】 清空列表中所有元素。
fish = ['鲸鱼', '鲨鱼', '刀鱼', '鲶鱼', '剑鱼', '章鱼', '鱿鱼', '鲤鱼'] # 原列表
print('清空前的列表:', fish)
fish.clear() # 清空列表中的所有元素
print('清空后的列表:', fish)
输出结果为:
清空前的列表: ['鲸鱼', '鲨鱼', '刀鱼', '鲶鱼', '剑鱼', '章鱼', '鱿鱼', '鲤鱼']
清空后的列表: []
【示例2】 清空二维列表中所有元素。创建一个二维列表,然后应用列表对象的clear()方法清空二维列表中的所有元素,示例代码如下:
# 定义二维列表
untitle = ['Python', 28, '人生苦短,我用Python', ['爬虫', '自动化运维', '云计算', 'Web开发']]
print('清空前的二维列表:', untitle)
untitle.clear() # 清空二维列表
print('清空后的二维列表:', untitle)
【示例3】 清空二维列表中的子列表。创建一个二维列表,然后通过列表索引的方式指定子列表的位置,再通过clear()方法清空子列表中的所有元素,示例代码如下:
untitle = ['Python', 28, '人生苦短,我用Python', ['爬虫', '自动化运维', '云计算', 'Web开发']]
print('清空前的二维列表:', untitle)
untitle[3].clear() # 清空子列表中的所有元素
# ['Python', 28, '人生苦短,我用Python', []]
print('清空后的二维列表:', untitle)
【示例4】 清空二维列表中与目标列表相同的子列表。循环遍历二维列表,比较子列表是否与目标列表相同,如果相同就将对应的子列表清空。代码如下:
two_lst = [[1, 2, 3], ['1', '2', '3'], [1, 2, 3]] # 二维列表
target_list = [1, 2, 3] # 目标列表
for i in two_lst:
if i == target_list: # 如果二维列表中子列表与目标列表相同
i.clear() # 清空二维列表中子列表
# [[], ['1', '2', '3'], []]
print('清空后的二维列表:', two_lst)
2.4 copy() 方法–复制列表中所有元素
在 Python 中,提供了 copy() 方法,使用该方法可以复制某一列表中的所有元素并生成一个新列表。其语法格式如下:
listname.copy() # listname:表示列表的名称。
【示例1】将原列表中的所有元素复制到新列表中。定义一个保存影视类奖项名称的列表,然后应用copy()方法列表中的所有元素复制到新列表中,示例代码如下:
old = ['金鹰奖', '百花奖', '飞天奖', '白玉兰奖', '华表奖', '金鸡奖'] # 原列表
print('原列表:', old)
new = old.copy() # 将原列表的所有元素复制到新列表中
print('新列表:', new)
【示例2】混合类型的列表元素复制到新的列表当中。对于混合类型的列表,也可以应用copy()方法列表中的所有元素复制到新列表中,示例代码如下:
old = ['great', 54345, ['?', 68], (21, '加油'), '努力'] # 原列表
print('原列表:', old)
new = old.copy() # 将原列表的所有元素复制到新列表中
print('新列表:', new)
注意:copy()和直接赋值的区别:使用“=”直接赋值,是引用赋值,更改一个,另一个同样会变。copy()复制一个副本,原值和新复制的变量互不影响。如下面的例子所示:
a = ['龙虎英雄会', '十二金钱镖', '乱世枭雄', '老店风云', '三侠五义']
b = a # 直接赋值
c = a.copy() # 复制列表中的所有元素
print('a:', a)
print('b:', b)
print('c:', c, '\n')
del a[1] # 删除列表中的第2个元素
print('a:', a)
print('b:', b)
print('c:', c, '\n')
b.remove('老店风云') # 移除指定元素
print('a:', a)
print('b:', b)
print('c:', c, '\n')
c.append('禁烟风云') # 添加指定元素
print('a:', a)
print('b:', b)
print('c:', c)
2.5 count() 方法–获取指定元素出现的次数
使用列表对象的 count() 方法可以获取指定元素在列表中出现的次数。其语法格式如下:
listname.count(obj)
参数说明:
- listname:表示列表的名称。
- obj:表示要获取的对象。
- 返回值:元素在列表中出现的次数。
【示例1】判断列表中指定元素出现的次数。创建一个列表,应用列表对象的count()方法判断元素“乒乓球”出现的次数,示例代码如下:
play = ['乒乓球', '跳水', '女排', '举重', '射击', '体操', '乒乓球'] # 原列表
num = play.count('乒乓球') # 用count()方法获得列表中“乒乓球”出现的次数,结果赋给num
print('乒乓球出现的次数为:', num) # 2
【示例2】判断混合类型列表中指定元素出现的次数。如果是混合类型的列表[99,[‘刘备’,99,‘袁绍’],(99,‘孙权’,‘刘表’),‘曹操’,99],应用列表对象的count()方法判断“99”元素出现的次数时,将只统计列表中数字类型的元素,出现在列表类型元素或元组类型元素里的“99”将不被计数。示例代码如下:
monkey = [99, ['刘备', 99, '袁绍'], (99, '孙权', '刘表'), '曹操', 99] # 原列表
num = monkey.count(99) # 用count()方法获得列表中“99”出现的次数,结果赋给num
print('99出现的次数为:', num) # 2
【示例3】判断二维列表中指定元素出现的次数。创建一个二维列表作为数据,然后循环遍历列表中的元素并判断列表中是否包含list类型数据,如果包含则获取该列表中指定元素出现的次数,最后统计指定元素出现的总次数即可。示例代码如下:
# 某公司迟到点名数据
two_list = ['小赵', '老钱', '老孙', '小李', ['小赵', '老周', '老孙', '小王'], ['老吴', '老吴', '小冯', '小赵']]
count = 0 # 叠加列表元素出现的次数
goal = '小赵' # 需要查找的元素
for i in two_list: # 循环遍历列表元素
if type(i) == list: # 判断列表中元素是否还有列表
count += i.count(goal) # 如果有列表则获取该列表中指定元素出现的次数
# 最后打印整个二维列表中指定元素出现的次数 3
print(goal, '元素在二维列表中出现了', two_list.count(goal) + count, '次!')
【示例4】获取列表中不同类型元素出现的次数。
ranking_list = [{
1: 'Java'}, [2, 'C'], (3, 'Python'), {
1: 'Java'}] # 多类型元素的列表
print(ranking_list.count(ranking_list[0])) # 获取列表中指定元素的数量 2
print(ranking_list.count({
1: 'Java'})) # 获取列表中指定字典数据的数量 2
print(ranking_list.count([2, 'C'])) # 获取列表中指定列表数据的数量 1
print(ranking_list.count((3, 'Python'))) # 获取列表中指定元组数据的数量1
2.6 enumerate() 函数–遍历列表
enumerate() 函数将一个可迭代的对象组合为一个带有数据和数据下标的索引序列,返回一个枚举对象,enumerate() 函数多用在 for 循环中,用于遍历序列中的元素以及它们的下标。其语法格式如下:
enumerate(iterable, start=0)
参数说明:
- iterable:一个序列、迭代器或其他支持迭代的对象,如列表、元组、字符串等。
- start:下标的起始值,默认从0开始。
- 返回值:返回一个 enumerate (枚举)对象。
【示例1】遍历enumerate对象。enumerate()函数是将一个可迭代的对象组合为一个带有数据和数据的索引序列,返回一个枚举对象。例如,定义一个保存中国古典文学中四大名著的列表,然后通过for循环和enumerate()函数遍历该列表,并输出索引和四大名著的名称,示例代码如下:
print('中国古典文学中四大名著:')
team = ['《三国演义》', '《水浒传》', '《西游记》', '《红楼梦》']
for index, item in enumerate(team): # 遍历索引与四大名著的名称
print(index + 1, item) # 打印索引与四大名著的名称
【示例2】将enumerate对象转换为列表。定义一个元组,使用enumerate()函数根据定义的元组创建一个enumerate对象,并使用list()函数将其转换为列表,示例代码如下:
num = ('one', 'two', 'three', 'four') # 创建元组数据
print(enumerate(num)) # 返回一个enumerate对象
print(list(enumerate(num))) # 使用list()函数转换为列表,下标的起始值默认从0开始
print(list(enumerate(num, 2))) # 设置下标的起始值从2开始
提示:从上面的运行结果可以看出,enumerate()函数返回的是一个enumerate对象,如果想要得到列表,可以用list()函数进行转换。
【示例3】通过enumerate()函数合并列表索引。定义两个列表,通过enumerate()函数将其组成索引序列,最后合成一个列表,并且实现下标的连续性。示例代码如下:
list1 = ['python', 'java', 'asp.net', 'c++', 'vb'] # 创建列表list1
list2 = ['sqlserver', 'oracle', 'mysql', 'mongodb'] # 创建列表list2
en1 = enumerate(list1) # 创建list1列表的enumerate对象
en2 = enumerate(list2, start=5) # 创建list2列表的enumerate对象,下标以5开始
resultList = list(en1) + list(en2) # 将两个enumerate对象转换为列表,并合为一个列表
print('合并后的列表内容为:\n', resultList) # 打印合并后的列表内容
【示例4】循环遍历序列中的元素及下标。enumerate()函数多用在for循环中,用于遍历序列中的元素以及它们的下标。使用for循环和enumerate()函数实现同时输出索引值和元素内容的功能,其语法格式如下:
for index,item in enumerate(listname):
# 输出index和item
参数说明:
- index:用于保存元素的索引。
- item:用于保存获取到的元素值,要输出元素内容时,直接输出该变量即可。
- listname:序列名称。
通过 enumerate() 函数,循环遍历序列中的元素及下标。示例代码如下:
list3 = ['Forever', 'I Need You', 'Alone', 'Hello'] # 列表数据
for index, item in enumerate(list3): # 循环遍历列表中的元素及下标
print('列表元素下标为:', index, '列表元素为:', item)
输出结果为:
列表元素下标为: 0 列表元素为: Forever
列表元素下标为: 1 列表元素为: I Need You
列表元素下标为: 2 列表元素为: Alone
列表元素下标为: 3 列表元素为: Hello
2.7 extend() 方法–将序列的全部元素添加到另一列表中
extend() 方法是向列表中添加一个元素,而 extend() 方法可以实现将一个序列中的全部元素添加到列表中。其语法格式如下:
listname.extend(seq)
参数说明:
- listname:表示要添加元素的列表名称。
- seq:表示要被添加的序列。语句执行后,seq 的内容将追加到 listname 的后面。
【示例1】将序列中的全部元素添加至列表。定义一个包括2个元素的,名为color的列表,然后应用extend()方法将另外3个序列中的元素添加到color列表的末尾,示例代码如下:
color = ['红', '橙'] # 定义原列表
print('原列表:', color)
color.extend(['黄', '绿']) # 将列表['黄','绿']中的元素全部添加到color的末尾
print('添加列表元素:', color)
color.extend(('青', '蓝')) # 将元组('青','蓝')中的元素全部添加到color的末尾
print('添加元组元素:', color)
color.extend('紫黑白') # 将字符串'紫黑白'中的元素全部添加到color的末尾
print('添加字符串元素:', color)
输出结果为:

【示例2】向列表中添加混合类型的序列。通过extend()方法向列表末尾添加混合类型的序列。示例代码如下:
building = ['滕王阁', '蓬莱阁', '天心阁', '天一阁'] # 定义原列表
print('原列表:', building)
# 将列表['tall',(6,9),['?','!'],300]中的全部元素添加到building的末尾
building.extend(['tall', (6, 9), ['?', '!'], 300])
print('新列表:', building)
说明:如果通过extend()方法向列表中添加字典数据时,在默认情况下只会将字典中的key值添加至列表当中。示例代码如下:
surname = ['赵', '钱', '孙', '李'] # 定义列表
surname.extend({
'1': '周'}) # 向列表中添加字典数据
print('新列表内容为:', surname) # 打印添加后的列表内容
【示例3】将二维列表转换为一维列表。便利二维列表中的子列表,然后将子列表中的元素添加至一维列表当中,代码如下:
two_list = [[1, 2], [3, 4], [5, 6], [7, 8]] # 创建二维列表
one_list = [] # 一维列表
for i in two_list: # 便利二维列表中的元素
one_list.extend(i) # 将二维列表中子列表内的元素添加值一维列表内
print(one_list) # 打印一维列表
【示例4】将同时包含一维和二维的列表转换为一维列表。在一个二维列表中,既有普通的数值类型元素,也有列表元素,现在需要将该二维列表转化为一维列表,代码如下:
def spread(arg):
ret = []
for i in arg:
if isinstance(i, list): # 如果元素是列表,则使用extend方法将每个元素添加到列表
ret.extend(i)
else: # 如果元素不是列表,则使用append方法追加到原列表
ret.append(i)
return ret # 返回一维列表
print(spread([1, 2, 3, [4, 5, 6], [7], 8, 9]))
2.8 index() 方法–获取指定元素首次出现的索引
使用列表对象的 index() 方法可以获取指定元素在列表中首次出现的位置(即索引)。其语法格式如下:
listname.index(obj)
参数说明:
- listname:表示列表的名称。
- obj:表示要查找的对象。
- 返回值:首次出现的索引值,如果没有找到将抛出异常。
【示例1】判断指定元素首次出现的位置。创建一个列表,然后应用列表对象的index()方法判断元素“纳达尔”首次出现的位置,示例代码如下:
champion = ['费德勒', '德约科维奇', '纳达尔', '穆雷', '瓦林卡', '西里奇'] # 原列表
# 用index()方法获得列表中"纳达尔"首次出现的位置的索引,结果赋给position
position = champion.index('纳达尔')
print('纳达尔首次出现的位置的索引为:', position) # 2
【示例2】判断混合型列表中指定元素出现的位置。创建一个混合类型元素的列表,然后应用列表对象的index()方法判断指定元素出现的位置,示例代码如下:
city = ['杭州', ('扬州', 4, '苏州'), [16, '株洲', '徐州'], 32, '郑州'] # 原列表
# 用index()方法获得列表中指定元素首次出现的位置的索引,结果赋给position
position = city.index(('扬州', 4, '苏州'))
print('指定元素首次出现位置的索引为:', position) # 1
说明:如果是混合类型的列表,应用列表对象的index()方法判断元素"苏州"首次出现的位置时,将只判断列表中字符串类型的元素,出现在元组类型元素里的"苏州"将不被判断。示例代码如下:
city = ['杭州', ('扬州', 4, '苏州'), [16, '株洲', '徐州'], 32, '郑州'] # 原列表
# 用index()方法获得列表中指定元素首次出现的位置的索引,结果赋给position
position = city.index('苏州')
print('判断苏州元素首次出现位置的索引为:', position)
执行上面的代码,将提示下图所示的错误:

【示例3】使用del关键字删除指定索引的元素。
goal = '宙斯神像' # 需要删除的元素
verse = ['埃及金字塔', '巴比伦空中花园', '宙斯神像', '亚历山大灯塔'] # 定义字符型列表
del verse[verse.index(goal)] # 删除指定索引的元素
print('删除指定元素的列表为:', verse)
2.9 insert() 方法–向列表的指定位置插入元素
如果想要向列表的指定位置插入元素,可以使用列表对象的 insert() 方法实现。其语法格式如下:
listname.insert(index,obj)
参数说明:
- listname:表示原列表。
- index:表示对象 obj 需要插入的索引值。
- obj:表示要插入列表中的对象。
【示例1】向列表的指定位置添加元素。定义一个包括5个元素的列表,然后应用insert()方法向该列表的第2个位置处添加一个元素,示例代码如下:
building = ['北京', '长安', '洛阳', '金陵', '汴梁'] # 定义原列表
print('原列表:', building)
building.insert(1, '杭州') # 向原列表的第2个位置处添加元素
print('新列表:', building)
输出结果为:

2.10 not in --查找列表元素是否不存在
not in是 not 和 in 两个关键字的组合,主要用于判断特定的值在列表中不存在时返回 True,否则返回 False。其语法格式如下:
if 'A' not in list:
参数说明:
- 'A’表示需要在列表中查找的元素值。
- list 表示查找目标的列表名称。
- 返回值:在列表中未找到对应的元素将返回 True,否则返回 False。

2.11 pop()方法–删除列表中的元素
在列表中,可以使用 pop() 方法删除列表中的一个元素(默认最后一个元素)。其语法格式如下:
listname.pop(index)
参数说明:
- listname:表示列表的名称。
- index:列表中元素的索引值,必须是整数;如果不写,默认 index = -1。
- 返回值:被删除的元素的值。
【示例1】删除列表中最后一个元素。定义一个保存8个元素的列表,删除最后一个元素,示例代码如下:
city = ['里约热内卢', '伦敦', '北京', '雅典', '悉尼', '亚特兰大', '巴塞罗那', '首尔'] # 原列表
delete = city.pop() # 删除列表的最后一个元素
print('删除的元素:', delete)
print('删除最后一个元素后的列表:', city)
【示例2】删除列表中指定元素。定义一个保存4个元素的列表,删除第2个元素,示例代码如下:
building = ['岳阳楼', '黄鹤楼', '鹳雀楼', '望湖楼'] # 原列表
delete = building.pop(1) # 删除列表的第2个元素,将删除的元素返回给delete
print('删除的元素:', delete)
print('删除第2个元素后的列表:', building)
说明:pop(index)括号中的index参数是可选的,index是列表中元素的索引值,pop(index)表示删除索引为index的元素,并将删除元素作为返回值。
【示例3】以负数作为索引删除列表元素。
building = ['岳阳楼', '黄鹤楼', '鹳雀楼', '望湖楼'] # 原列表
delete = building.pop(-4) # 删除列表的第1个元素,将删除的元素返回给delete
print('删除的元素:', delete)
print('删除第1个元素后的列表:', building)
2.12 remove() 方法–删除列表中的指定元素
使用 remove() 方法可以删除列表中的指定元素。其语法格式如下:
listname.remove(obj)
参数说明:
- listname:表示列表的名称。
- obj:表示列表中要移除的对象,这里只能进行精确匹配,即不能是元素值的一部分。
【示例1】删除列表中的指定元素。创建一个列表,然后应用列表对象的remove()方法删除列表中指定的元素,示例代码如下:
# 原列表
movie = [9, ('疯狂原始人', '功夫熊猫', 9), ['海底总动员', 9, '超能陆战队'], 9, '里约大冒险']
print('删除前的列表:', movie)
movie.remove(9) # 删除列表中的9
print('删除后的列表:', movie)
movie.remove(('疯狂原始人', '功夫熊猫', 9)) # 删除列表中的('疯狂原始人','功夫熊猫',9)
print('删除后的列表:', movie)
【示例2】删除数值列表中的指定数值。创建一个数值列表,然后应用列表对象的remove()方法删除列表中指定的数值元素,示例代码如下:
int_list = [1, 3, 5, 0, 4, 4, 1, 7, 9, 9, 6] # 模拟手机号码
print('删除前的列表:', int_list)
int_list.remove(1) # 删除数值元素1
print('删除后的列表:', int_list)
【示例3】通过for循环删除列表中指定类型的元素。创建一个包含多种类型元素的列表,然后循环遍历列表中的每个元素,如果元素类型为指定的元素类型,即可通过remove()方法删除当前元素即可。示例代码如下:
a_list = ['a', 123, 12.1, -1] # 创建多类型元素的列表
for i in a_list: # 循环遍历列表中的元素
if type(i) == str: # 判断元素的类型是否为字符类型
a_list.remove(i) # 是字符类型将当前元素在列表中移除
print('移除字符类型元素后的列表:', a_list) # 打印移除字符类型元素后的列表
【示例4】通过for循环删除列表中指定索引范围的元素。创建一个数值列表,循环遍历指定索引范围的列表对象,然后删除索引对应的元素值。示例代码如下:
number_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 数值列表
# 循环删除列表索引为0~5所对应的元素
for i in number_list[0:6]:
number_list.remove(i)
print('删除元素后的列表为:', number_list)
del 关键字、pop() 方法、remove() 方法的区别如下:
- del 关键字可以实现删除整个列表对象,而 pop() 方法与 remove() 方法无法实现。
- del 关键字与 pop() 方法在删除指定元素时需要通过指定元素索引,而 remove() 方法需要指定元素值对象。
- pop() 方法在删除元素时可以返回当前删除的元素值,而 del 关键字与 remove() 方法无法实现。
2.13 reverse() 方法–反转列表中的所有元素
列表对象提供了 reverse() 方法,使用该方法可以将列表中的所有元素进行反转。其语法格式如下:
listname.reverse() # listname:表示列表的名称。
【示例1】符换列表中的所有元素反转。定义一个含有5个元素的列表,然后应用reverse()方法将原列表中的所有元素反转,示例代码如下:
num = ['一', '二', '三', '四', '五']
print('原列表:', num)
num.reverse() # 反转列表中的所有元素
print('新列表:', num)
输出结果为:

【示例2】混合类型的列表中所有元素反转。对于混合类型的列表,也可以应用reverse()方法将原列表中的所有元素反转,示例代码如下:
num = [1, '二', ['Ⅲ', 4], (5, '⑥')]
print('原列表:', num)
num.reverse() # 反转列表中的所有元素
print('新列表:', num)
2.14 sort() 方法–排序列表元素
列表对象中提供了 sort() 方法,该方法用于对原列表中的元素进行排序,排序后原列表中的元素顺序将发生改变。其语法格式如下:
listname.sort(key=None, reverse=False)
参数说明:
- listname:表示要进行排序的列表。
- key:表示指定一个从每个列表元素中提取一个用于比较的键(例如,设置“key=str.lower”表示在排序时不区分字母大小写)。
- reverse:可选参数,如果将其值指定为 True,则表示降序排列,如果为 False,则表示升序排列。默认为升序排列。
【示例1】数值列表的排序。定义一个保存10名学生Python理论成绩的列表,然后应用sort()方法对其进行排序,示例代码如下:
grade = [98, 99, 97, 100, 100, 96, 94, 89, 95, 100] # 10名学生Python理论成绩列表
print('原列表:', grade)
grade.sort() # 进行升序排列
print('升 序:', grade)
grade.sort(reverse=True) # 进行降序排列
print('降 序:', grade)
【示例2】字符串列表的排序。使用sort()方法对字符串列表进行排序时,采用的规则是先对大写字母排序,然后再对小写字母排序。如果想要对字符串列表进行排序(不区分大小写时),需要指定其key参数。例如,定义一个保存英文字符串的列表,然后应用sort()方法对其进行升序排列,示例代码如下:
char = ['cat', 'Tom', 'Angela', 'pet'] # 原列表
char.sort() # 默认区分字母大小写
print('区分字母大小写:', char)
char.sort(key=str.lower) # 不区分字母大小写
print('不区分字母大小写:', char)
【示例3】将列表按自定义规则排序。使用sort()方法也可以按指定的规则进行排序。具体方法是先定义排序规则的函数,然后调用sort()方法时,指定key参数值为自定义的函数名。例如,定义一个包含字典子元素的列表,实现按字典的指定键值进行排序,代码如下:
def rulesort(elem): # 定义排序规则函数
return elem['english']
list1 = [{
'name': 'mr', 'english': 99},
{
'name': '碧海苍梧', 'english': 100},
{
'name': '零语', 'english': 98}]
print('排序前:', list1)
list1.sort(key=rulesort) # 按指定规则排序
print('升序排序后:', list1)
list1.sort(key=rulesort, reverse=True) # 按指定规则排序
print('降序排序后:', list1)
【示例4】按拼音顺序对列表按中文排序。在Python中,对列表按中文排序,可以借助第三方模块xpinyin实现。例如,定义保存三国人物名称列表,并对其按拼音顺序排序,代码如下:
from xpinyin import Pinyin # 导入第三方模块,需要先应用pip install xpinyin命令安装
pin = Pinyin() # 实例化
result = [] # 临时列表
list1 = ['刘备', '曹操', '关羽', '诸葛亮', '张飞', '周瑜']
print('排序前:', list1)
for item in list1:
result.append((pin.get_pinyin(item), item)) # 添加拼音
result.sort() # 按拼音排序
result = [i[1] for i in result] # 去掉添加的拼音再生成列表
print('排序后:', result) # 输出排序后的结果
2.15 sorted() 函数–排序列表元素
Python 函数 | sorted 函数详解
2.16 sum() 函数–统计数值列表的元素和
sum() 函数用于对列表、元组或集合等可迭代对象进行求和计算。其语法格式如下:
sum(iterable[, start])
参数说明:
- iterable:可迭代对象,如列表、元组、range对象等。
- start:可选参数,指定相加的参数(即序列值相加后再次相加的值),如果没有设置此参数,则默认为0。
- 返回值:求和结果。
注意:在使用sum()函数对可迭代对象进行求和时,需要满足参数必须为可迭代对象且可迭代对象中的元素类型必须是数值型,否则将提示TypeError。
【示例1】列表元素求和。sum()函数可以用于可迭代对象的求和计算,例如通过sum()函数对列表中元素求和,可以使用如下代码:
number = [10, 20, 30, 40, 50, 60, 70]
print('原列表:', number)
print('元素和:', sum(number))
【练习】求下面10名同学的成绩总和。
# 10名学生Python理论成绩列表
grade_list = ['98','99','97','100','100','96','94','89','95','100']
2.17 print() 函数–输出列表内容
【示例1】输出列表内容。在Python中,如果想将列表的内容输出也比较简单,可以直接使用print()函数。例如,要想打印上面列表中的untitle列表,则可以使用下面的代码:
untitle = ['Python', 28, '人生苦短,我用Python']
print(untitle)
# 要获取列表untitle中索引为2的元素
print(untitle[2])
2.18 list() 函数–创建列表
list() 函数用于将序列转换成列表类型并返回一个数据列表,其语法格式如下:
list(seq)
参数说明:
- seq:表示可以转换为列表的数据,其类型可以是 range 对象、字符串、列表、元组、字典或者其他可迭代类型的数据。
- 返回值:列表。
- list() 函数可以传入一个可迭代对象,如字符串、元组、列表、range 对象等,结果将返回可迭代对象中元素组成的列表。list() 函数也可以不传入任何参数,结果返回一个空列表。
【示例1】创建列表。例如通过range对象直接创建一个列表,示例代码如下:
range_list = list(range(10, 20, 2)) # 通过range对象创建列表
print('通过range对象创建的列表内容为:', range_list)
print(list()) # 不传入参数,创建一个空列表
print(list('一二三四')) # 将字符串转换为列表
print(list(('壹', '贰', '叁', '肆'))) # 将元组转换为列表
print(list(['Ⅰ', 'Ⅱ', 'Ⅲ', 'Ⅳ'])) # 参数为列表则原样输出
print(list()) # 不传入参数,创建一个空列表
print(list('Python')) # 将字符串转换为列表
print(list(('a', 'b', 'c', 'd'))) # 将元组转换为列表
print(list(['Forever', 'I Need You', 'Alone', 'Hello'])) # 参数为列表则原样输出
print(list(range(1, 11))) # 将range对象转换为列表
【示例2】将字典转换为列表。使用list()函数将字典转换为列表,示例代码如下:
dictionary = {
'Python': 98, 'Java': 80, 'C语言': 75} # 定义字典
print(list(dictionary)) # 使用list()函数转换为列表
提示:list()函数的参数为字典时,会返回字典的key组成的列表。如果需要将字典中的values()转换为列表时可以使用如下代码:
print(list(dictionary.values())) # 将字典中values转换为列表
三、元组
3.1 () --直接创建元组
在 Python 中,可以直接通过小括号 () 创建元组 ,创建元组时,在小括号的内容放置由逗号分隔的元素。其语法格式如下:
tuplename = (element 1,element 2,element 3,…,element n)
参数说明:
- tuplename:表示元组的名称,可以是任何符合 Python 命名规则的标识符;
- elemnet 1、elemnet 2、elemnet 3、elemnet n:表示元组中的元素,个数没有限制,并且只要是 Python 支持的数据类型就可以。
【示例1】 通过“()”符号定义元组。
empty = () # 创建空列表
num = (7, 14, 21, 28, 35, 42, 49, 56, 63) # 创建数值元组
team = ('马刺', '火箭', '勇士', '湖人') # 创建字符串类型元组
# 混合类型元组
untitle = ('Python', 28, ('人生苦短', '我用Python'), ['爬虫', '自动化运维', '云计算', 'Web开发'])
print('数值元组:', num)
print('字符串元组:', team)
print('混合类型元组:', untitle)
print('空元组:', empty)
【示例2】 不用括号定义元组。
team = '马刺', '火箭', '勇士', '湖人' # 不使用括号定义元组
print('不是使用括号来定义元组:', team)
【示例3】 定义单个元素的元组。
verse1 = ('世界杯冠军',) # 定义单个元素的元组
print('单个元素的元组:', verse1)
【示例4】 通过元组推导式生成元组。
import random
tuple1 = tuple((i for i in range(10))) # 创建0~10之间(不包括10)的数字元组
print(tuple1)
tuple2 = tuple((i for i in range(10, 100, 10))) # 创建10~100之间(不包括100)的整十数元组
print(tuple2)
# 创建10个4位数的随机数元组
tuple3 = tuple((random.randint(1000, 10000) for i in range(10)))
print(tuple3)
tuple4 = tuple((i for i in '壹贰叁肆伍')) # 将字符串转换为元组
print(tuple4)
# 生成所有单词首字母元组
tuple5 = tuple((i[0] for i in ('Early', 'bird', 'gets', 'the', 'worm')))
print(tuple5)
# 将原元组中的数字折半后生成新的元组
tuple6 = tuple((int(i * 0.5) for i in (1200, 5608, 4314, 6060, 5210)))
print(tuple6)
tuple7 = tuple((i for i in ['Early', 'bird', 'gets', 'the', 'worm'])) # 通过列表生成新的元组
print(tuple7)
# 将字典的Key生成新的元组
tuple8 = tuple((key for key in {
'qq': '84978981', 'mr': '84978982', 'wgh': '84978980'}))
print(tuple8)
tuple9 = tuple((key for key in {
1, 3, 5, 7, 9})) # 通过集合生成有序元组
print(tuple9)
3.2 del --删除元组
元组中的元素是不允许被删除的,但是对于已经创建的元组不再使用时,可以使用 del 语句将其删除,其语法格式如下:
del tuplename
其中,tuplename 为要删除元组的名称。定义一个名称为 team 的元组,保存世界杯夺冠热门球队,这些夺冠热门球队在小组赛和第一轮淘汰赛后都被淘汰了,因此应用 del 语句将其删除,示例代码如下:

说明:del 语句在实际开发时,并不常用。因为 Python 自带的垃圾回收机制会自动销毁不用的元组,所以即使我们不手动将其删除,Python 也会自动将其回收。
3.3 in --查找元组元素是否存在
in 保留字在 python 中的应用非常广泛,在元组中同样可以实现查找元组元素是否存在。如果元组中存在要查找的元素返回 True,否则返回 False。例如,定义一个保存 5 个化学元素的元组,查找元组中是否含有“锰”元素和“铁”元素,可以使用下面的代码:

not in --查找元组元素是否不存在。not in 与 in 关键字相反,用于查找元组元素是否不存在。如果元组中不存在要查找的元素返回 True,否则返回 False。例如,定义一个保存 5 个水果元素的元组,查找元组中是否不含有“芒果”元素和“苹果”元素,可以使用下面的代码:

3.4 len() 函数–计算元组元素个数
在 Python 中,可以使用 len() 函数计算元组中元素的个数。其语法格式如下:
len(tuplename) # tuplename:表示元组的名称。
例如,创建一个元组,内容为几种常见的歌唱方法,然后应用 len() 函数计算元组中元素的个数,可以使用下面的代码:

【示例1】
# 创建星期英文元组
tuple2 = ('Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday')
print('tuple2元组中元素长度最大为:', max(len(i) for i in tuple2)) # 打印tuple2元组中长度最大值
# 打印tuple2元组中长度最大的元素
print('tuple2元组中长度最大的元素为:', max(tuple2, key=lambda i: len(i)))
# 打印tuple2元组中长度最小的元素
print('tuple2元组中长度最小的元素为:', min(tuple2, key=lambda i: len(i)))
【示例2】
# 创建国际旅游胜地前四名的二维元组
tuple3 = (('威尼斯', 1), ('阿姆斯特丹运河', 2), ('马尔代夫', 3), ('迪拜', 4))
print('二维元组tuple3的长度为:', len(tuple3)) # 打印二维元组的长度 4
# 打印二维元组中旅游胜地名称最长的元组
print('旅游胜地名称最长的元组为:', max(tuple3, key=lambda i: len(i[0])))
3.5 max() 函数–返回元组中元素最大值
在 Python 中,可以使用 max() 函数计算元组中元素的个数。其语法格式如下:
max(tuplename) # tuplename:表示元组的名称。
【示例1】
number = (4, 16, 36, 25, 9)
print('元组:', number)
print('元素最大值:', max(number))
tuple2 = ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sept', 'Oct',
'Nov', 'Dec', 'Mon', 'Tues', 'Wed', 'Thur', 'Fri') # 月份、星期简写元组
print(max(tuple2)) # 输出tuple2的最大值(先比较元组的第1个元素,如果相同,再比较第2个元素…)
print(max(tuple2, key=lambda x: len(x))) # 输出元组中长度最大(即字符最多)的元组
# NBA球队成绩元组
tuple3 = ('勇士 57', '掘金 54', '开推者 53', '火箭 53', '爵士 50', '雷霆 49', '马刺 48', '快船 48')
print(max(tuple3, key=lambda x: x[-2:])) # 获取元祖后两项数据的最大值,即获胜场次取最大值
tuple4 = (('肖申克的救赎', 1994, 9.3), ('教父', 1972, 9.2), ('教父2', 1974, 9.1),
('蝙蝠侠:黑暗骑士', 2008, 9.0), ('低俗小说', 1994, 8.9)) # 电影信息元组
print(max(tuple4, key=lambda x: x[1])) # 按每个元祖的第2项取最大值,即出品年份
print(max(tuple4, key=lambda x: x[2])[0]) # 按元祖的第3项(打分)取最大值,只输出最大值的第一个元素
tuple5 = ((90, 128, 87.103), (78, 99, 134.106), (98, 102, 133.80), (66, 78, 97, 56), (98, 123, 88.79))
print(max(max(tuple5, key=lambda x: x[1]))) # 按照tuple5的第2项取最大值,然后在最大值中再取最大值
print(max(tuple5, key=lambda x: (x[0] + x[1] + x[2]))) # 按照元组的3项之和获取最大值
print(max(tuple5, key=lambda x: (x[0], x[1]))) # 按元组第1项和第2项取最大值,第一项相同,比较第2项
输出结果为:

min() 函数–返回元组中元素最小值,用法与 max()函数一样,这里就不再过多进行强调。
3.6 tuple() 函数–将序列转换为元组
通过 tuple() 函数可以将一个序列作为参数,并将这个序列转换为元组。其语法格式如下:
tuple(seq)
参数说明:
- seq:表示可以转换为元组的数据,其类型可以是 range 对象、字符串、列表、字典、元组或者其他可迭代类型的数据;如果参数是元组,参数则会被原样返回。
- 返回值:元组。如果不传入任何参数,将返回一个空元组。
【示例1】将序列转换为元组。
print(tuple(range(15, 30, 3))) # 将range对象转换为元组
print(tuple()) # 不传入参数,创建一个空元组
print(tuple('①②③④')) # 将字符串转换为元组
print(tuple(['㈠', '㈡', '㈢', '㈣'])) # 将列表转换为元组
print(tuple(('壹', '贰', '叁', '肆'))) # 参数为元组则原样输出
print(tuple('Python')) # 参数为字符串
print(tuple(range(10, 20, 2))) # 创建一个10~20之间(不包括20)所有偶数的元组
print(tuple((89, 63, 100))) # 原样返回
【示例2】将列表转换为元组。
list1 = ['Forever', 'I Need You', 'Alone', 'Hello'] # 英文歌曲列表
print('列表:', list1) # 输出英文歌曲列表
tuple1 = tuple(list1) # 转换为元组
print('元组:', tuple1) # 输出元组
print('将列表中指定元素转换为元组:', tuple(list1[3]))
print('将列元素范围转换为元组:', tuple(list1[1:]))
【示例3】将字典转换为元组。
# 定义的字典数据
dictionary = {
'小英子': '5月5日', '阳光': '12月8日', '茜茜': '7月6日', }
print(dictionary) # 输出字典
print(tuple(dictionary)) # 转换为元组输出
提示:tuple() 函数的参数为字典时,会返回字典的 key 组成的元组。如果需要将字典中的 values() 转换为元组时可以使用如下代码:
print(tuple(dictionary.values())) # 将字典中values转换为元组
【示例4】将generator对象转换为元组。
import random # 导入random标准库
# 创建一个包含10个随机数的生成器对象
random_number = (random.randint(10, 100) for i in range(10))
random_number = tuple(random_number) # 转换为元组
print('转换后:', random_number) # 输出转换后的元组
四、字典
4.1 {} --直接创建字典
在创建字典时,使用一对大括号 {},在大括号中间放置使用冒号分隔的 键 和 值 作为元素,相邻两个元素使用逗号分隔。其语法格式如下:
dictionary = {
'key1':'value1', 'key2':'value2', …, 'keyn':'valuen',}
参数说明:
- dictionary:表示字典名称。
- key1、key2…keyn:表示元素的键,必须是唯一的,并且不可变,例如可以是字符串、数字或者元组。
- value1、value2…valuen:表示元素的值,可以是任何数据类型,不是必须唯一。
【示例1】 通过“{}”符号定义字典。
# 键为字符串的字典
link = {
'qq': '84978981', 'mr': '84978982', 'wgh': '84978980'} # 定义值为字符串的字典
record = {
'english': 97, 'chinese': 99, 'python': 100, 'c': 96} # 定义值为数字的字典
# 定义值为列表的字典
language = {
'python': ['优雅', '明确', '简单'], 'java': ['继承', '封装', '多态']}
student = {
1: '明日', 2: '零语', 3: '惜梦'} # 定义键为数值的字典
temp = {
('a', 'b'): ('1000', '1001')} # 定义键为元组的字典
print('link字典:', link)
print('record字典:', record)
print('language字典:', language)
print('student字典:', student)
print('temp字典:', temp)
输出结果为:
link字典: {'qq': '84978981', 'mr': '84978982', 'wgh': '84978980'}
record字典: {'english': 97, 'chinese': 99, 'python': 100, 'c': 96}
language字典: {'python': ['优雅', '明确', '简单'], 'java': ['继承', '封装', '多态']}
student字典: {1: '明日', 2: '零语', 3: '惜梦'}
temp字典: {('a', 'b'): ('1000', '1001')}
【示例2】 通过字典推导式生成字典。
import random
# 键为数值的随机数字典
random_dict = {
i: random.randint(1000, 10000) for i in range(5)}
print(random_dict)
# 键为字符串的字典
char = {
i[0].upper(): i for i in ['Early', 'bird', 'gets', 'the', 'worm']}
print(char)
# 根据列表创建字典
name = ['绮梦', '冷伊一', '香凝', '黛兰'] # 作为键的列表
sign = ['水瓶', '射手', '双鱼', '双子'] # 作为值的列表
dictionary = {
i: j + '座' for i, j in zip(name, sign)} # 使用列表推导式生成字典
print(dictionary) # 输出转换后字典
# 用一个字典中符合指定条件的元素生成一个新字典
student = {
'绮梦': '水瓶座', '冷伊一': '双子座', '香凝': '双鱼座', '黛兰': '双子座'}
new_student = {
k: v for k, v in student.items() if v == '双子座'}
print('双子座的学生:', new_student)
输出结果为:
{0: 7025, 1: 8173, 2: 7979, 3: 7399, 4: 4226}
{'E': 'Early', 'B': 'bird', 'G': 'gets', 'T': 'the', 'W': 'worm'}
{'绮梦': '水瓶座', '冷伊一': '射手座', '香凝': '双鱼座', '黛兰': '双子座'}
双子座的学生: {'冷伊一': '双子座', '黛兰': '双子座'}
4.2 clear() 方法–删除字典中的全部元素
字典中的 clear() 方法用于删除字典内的全部元素。执行 clear() 方法后,原字典将变为空字典。其语法格式如下:
dict.clear()
参数说明:
- dict:字典对象。
- 返回值:None。
【示例1】 删除字典中的全部元素。

【示例2】清空通过推导式所创建的字典。

4.3 copy() 方法–浅复制一个字典
字典中的 copy() 方法用于浅复制一个字典,浅复制(shallow copy)指的是复制父对象,不会复制对象内部的子对象。其语法格式如下:
dict.copy()
参数说明:
- dictionary:字典对象。
- 返回值:返回一个字典的浅复制。
【示例1】浅复制一个具有相同键值对的新字典。

【示例2】浅复制一个具有相同键值对的新字典。
d1 = {
'time': 2018, 'place': ['Beijing']}
d2 = d1 # 直接赋值,引用对象
d3 = d1.copy() # 浅复制字典
# 修改dict1数据
d1['time'] = 2019
d1['place'].append('Shanghai')
# 输出字典内容
print('d1为', d1)
print('d2为', d2) # 输出结果与d1相同
print('d3为', d3) # 输出复制结果
输出结果为:
d1为 {'time': 2019, 'place': ['Beijing', 'Shanghai']}
d2为 {'time': 2019, 'place': ['Beijing', 'Shanghai']}
d3为 {'time': 2018, 'place': ['Beijing', 'Shanghai']}
说明:浅复制实际上只复制了一层,当原对象内包含可变对象的元素时(例如,列表、字典、集合),对于这个可变对象,python会把它当作一个公共镜像存储起来,然后对他的复制都被当成一个引用,所以说当其中一个引用将镜像改变之后另一个引用使用镜像的时候,这个镜像就已经被改变了。
【示例3】浅复制一个更新后的字典。

4.4 del 关键字–删除字典或字典中指定的键
在实现字典内容的删除时,可以使用 del 关键字删除整个字典或字典中指定的键。使用 del 关键字删除字典的语法格式如下:
del dict[key] # 删除字典中指定的键
del dict # 删除字典
参数说明:
- dict:字典对象。
- key:要删除的键。
【示例1】先删除字典中指定的键再删除整个字典。
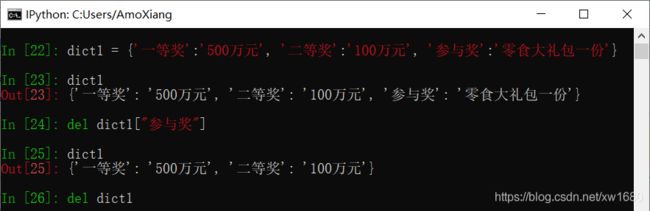
当使用del命令删除一个字典中不存在的键时,将抛出KeyError异常。代码如下:

为防止删除不存在的键时抛出异常,可以使用操作符 in 先判断指定键是否存在与字典中,然后再使用 del 命令删除指定的键,代码如下:

4.5 dict() 函数–创建字典
dict() 函数用于创建一个字典对象,其语法格式如下:
dict()
dict(**kwargs)
dict(mapping, **kwargs)
dict(iterable, **kwargs)
参数说明:
- ** kwargs,一到多个关键字参数;如 dict(one=1, two=2, three=3)
- mapping,元素容器,如 zip 函数;
- iterable,可迭代对象;
- 返回值:一个字典。如果不传入任何参数时,则返回空字典;
【示例1】创建字典。
dictionary = dict()
print('创建空字典:', dictionary)
# 通过给定 "键-值对" 的方式来创建字典
dictionary = dict(刘能='刘', 赵四='赵', 谢广坤='谢', 王长贵='王')
print(dictionary)
【示例2】通过给定的关键字参数创建字典。
# 通过给定的关键字参数创建字典
d1 = dict(mr='www.baidu.com') # 字符串的key与值
print(d1) # 打印d1字典内容
d2 = dict(Python=98, English=78, Math=81) # 字符串的key,int类型的值
print(d2) # 打印d2字典内容
d3 = dict(name='Tom', age=21, height=1.5) # 字符串的key,多种类型的值
print(d3) # 打印d3字典内容
提示:使用dict()函数通过给定的关键字参数创建字典时,name键名必须都是Python中的标识符,否则会提示 SyntaxError。错误代码如下:

【示例3】通过传入映射函数创建字典。
# 通过映射函数创建字典
a1 = dict(zip((1, 2, 3, 4), ('杰夫•贝佐斯', '比尔•盖茨', '沃伦•巴菲特', '伯纳德•阿诺特')))
print(a1) # 打印a1字典内容,key为int类型,值为字符串类型
a2 = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
print(a2) # 打印a2字典内容,key为字符串类型,值为int类型
a3 = dict(zip(['北京', '上海', '长春'], ['晴', '大雨', '小雪']))
print(a3) # 打印a3字典内容,key与值都是字符串类型
【示例4】通过传入可迭代对象创建字典。
# 通过可迭代对象创建字典
b1 = dict([('Monday', 1), ('Tuesday', 2), ('Wednesday', 3)]) # 元组对象
print(b1) # 打印b1字典内容
b2 = dict([['apple', 6.5], ['orange', 3.98], ['pear', 8], ['banana', 2.89]]) # 列表对象
print(b2) # 打印b2字典内容
【示例5】通过关键字索引访问字典成员。
# 商品信息
commodity = {
'name': 'Chocolates',
'number': 12,
'price': 19.8}
name = commodity['name'] # 获取字典中商品名称
# 根据获取的商品数量和商品单价,计算商品总价
total_price = commodity['number'] * commodity['price']
print('商品名称为:', name) # 输出商品名称 Chocolates
print('商品总价为:', total_price) # 输出商品总价 237.60000000000002
【示例6】通过关键字索引插入与修改字典中的成员。
name = {
'刘能': '刘', '赵四': '赵', '谢广坤': '坤'} # 名字数据
print('原字典数据为:', name) # 打印原字典数据
name['谢广坤'] = '谢' # 将名字值修改为姓氏
print('修改后的字典数据为:', name) # 打印修改后的字典数据
name['王长贵'] = '王' # 向原字典数据中插入数据
print('插入新数据的字典为:', name) # 打印插入新数据后的字典
4.6 fromkeys() 方法–创建一个新字典
字典对象中的 fromkeys() 方法用于创建一个新的字典。以序列 seq 中的元素作为字典的键,用 value 作为字典所有键对应的值。其语法格式如下:
dict.fromkeys(seq[, value])
参数说明:
- dict:字典对象。
- seq:序列(如字符串、列表、元组等),作为新字典的键。
- value:可选参数,如果提供 value 值则该值将被设置为字典的值,字典所有键对应同一个值,如果不提供 value 值,则默认返回 None。
- 返回值:返回一个新字典。
【示例1】创建字典中所有值为None的字典。

【示例2】创建一个所有值为相同值的字典。
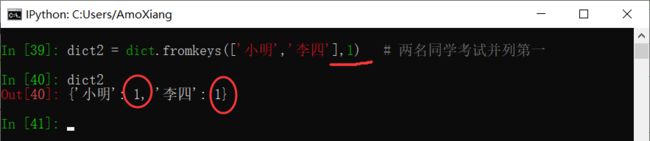
【示例3】循环创建多个同值字典。

4.7 get() 方法–获取字典中指定键的值
在使用字典时,很少直接输出它的内容。一般需要根据指定的键得到相应的结果。Python 中推荐的方法是使用字典对象的 get() 方法获取指定键的值。其语法格式如下:
dict.get(key[,default])
参数说明:
- dict:字典对象,即要从中获取值的字典。
- key:字典中要查找的键。
- default:可选参数,当指定的键不存在时,返回默认值,如果省略 default 参数,则返回 None。
- 返回值:如果字典中键存在,则返回键所对应的值;如果键不存在,则返回 default 默认值。
【示例1】获取字典中键对应的值。
dict1 = {
'北京': '晴', '上海': '阵雨转晴', '广州': '阴'}
print(dict1) # 输出字典
print('北京的天气为:', dict1.get('北京')) # 获取"北京"的天气报告,返回键对应的值
【示例2】获取字典中不存在的键所对应的值。
dict1 = {
'name': 'Tom', 'age': 21} # 创建字典
# 通过get()方法访问一个字典里的没有的键,返回None,也可自定义默认值
print(dict1.get('height')) # 返回None
print(dict1.get('height', '165cm')) # 返回165cm
【示例3】通过for循环获取列表中指定键对应的值。
dict_info = {
'name': 'Tom', 'age': 21, 'height': 1.5} # 字典数据
list_info = ['name', 'age', 'height'] # 保存字典键的列表
for i in list_info: # 循环获取列表内键对应的值
print(dict_info.get(i))
【示例4】获取字典中最小键所对应的值。
# 公司内部运动成绩排名
dict_info = {
1: '小王', 2: '老黄', 3: '小李', 4: '小张', 5: '老刘'}
minimal_key = min(dict_info.keys(), key=lambda i: i) # 获取字典数据中最小的键
print('公司内容运动会第一名是:', dict_info.get(minimal_key)) # 根据最小的键获取对应的值
【示例5】通过for循环获取字典中指定类型键所对应的值。
# NBA 18-19赛季季后赛,西部前三名“胜场”积分
nba_dict = {
57: '勇士', 54.0: '掘金', '53': '开拓者'}
for i in nba_dict.keys(): # 循环遍历字典中的键
if type(i) == int: # 判断键类型为int时
value = nba_dict.get(i) # 获取int类型的键所对应的值
print('指定类型键对应的值为:', value)
【示例6】根据字符型键第一个元素获取对应的值。
# 列车有、无票数据
train = {
'D74': '有票', 'G240': '无票', 'G384': '有票', 'D102': '有票'}
initial = input('请输入需要查询列车的首字母!')
if initial.isupper(): # 如果输入的字符为大写字母
for i in train.keys(): # 循环遍历字典中的键
if i[0] == initial: # 判断键首字母与输入字母相同时
print(i, ':', train.get(i)) # 打印查询的列车信息
else:
print('输入内容不合法!')
输出结果如下:

4.8 items() 方法–获取字典的所有"键值对"
使用字典对象的 items() 方法可以获取字典的所有 键值对。返回的是一个可迭代对象,可以使用 list() 函数转换为列表。其语法格式如下:
dict.items()
参数说明:
- dict:字典对象。
- 返回值:返回一个可迭代对象。
【示例1】获取字典中所有“键值对”。
dictionary = {
'hour': 3, 'minute': 45, 'second': 21} # 创建字典
print(dictionary.items()) # 获取字典的键值对,返回一个可迭代对象
print(list(dictionary.items())) # 使用list()函数转换为列表
【示例2】循环遍历字典中的全部“键值对”。
dictionary = {
'语文': 98, '数学': 95, '英语': 88} # 创建字典
for item in dictionary.items(): # 通过for循环获取字典中的全部"键值对"
print(item) # ('语文', 98)
【示例3】通过for循环分别遍历字典中的键和值。
dictionary = {
'2017年': 1682, '2018年': 2135} # 创建字典
for key, value in dictionary.items(): # 通过for循环获取字典中具体的每个键和值
print(key, '天猫双十一当天成交额:', value, '亿元')
【示例4】根据给出的值获取对应的键。
dict_name = {
'刘能': '刘', '赵四': '赵', '谢广坤': '坤'} # 名字数据
def get_key(dict_name, value): # 自定义根据值获取键的函数
return [k for (k, v) in dict_name.items() if v == value] # 列表推导式获取指定值对应的键
key = get_key(dict_name, '赵') # 调用函数获取“赵”对应的键
print('赵对应的键为:', key[0])
4.9 key in dict --判断指定键是否存在于字典中
字典 in 操作符用于判断指定键是否存在于字典中,如果键在字典中返回 True,否则返回 False。in 操作符的语法格式如下:
key in dict
参数说明:
- key:要在字典中查找的键。
- dict:字典对象。
- 返回值:如果键在字典中返回 True,否则返回 False。对于 not in 刚好相反,如果键在字典中返回 False,否则返回 True。

4.10 keys() 方法–获取字典的所有键
字典 keys() 方法用于获取一个字典所有的键。返回的是一个可迭代对象,可以使用 list() 函数转换为列表。其语法格式如下:
dict.keys()
参数说明:
- dict:字典对象。
- 返回值:返回一个可迭代对象。
【示例1】获取字典中的所有键。

【示例2】循环遍历字典中的键。
dictionary = {
'杰夫•贝佐斯': 1, '比尔•盖茨': 2, '沃伦•巴菲特': 3, '伯纳德•阿诺特': 4} # 创建字典
for key in dictionary.keys(): # 通过for循环获取字典中的具体的key(键)
print(key)
【示例3】循环遍历字典中的键。
# 字典数据
dict_demo = {
1: '杰夫•贝佐斯', 2: '比尔•盖茨', 3: '沃伦•巴菲特', 4: '伯纳德•阿诺特'}
for i in dict_demo.keys(): # 遍历字典中所有键
value = dict_demo.get(i) # 获取键对应的值
print('字典中的值有:', value)
4.11 pop() 方法–删除字典中指定键对应的键值对并返回被删除的值
字典中的 pop() 方法用于删除字典内指定键所对应的键值对,并返回被删除的值。指定的键如果不在字典中,则必须设置一个 default 值,否则会报错,此时返回的就是 default 值。其语法格式如下:
dict.pop(key[, default])
参数说明:
- dict:字典对象。
- key:指定字典中要删除的键。
- default:可选参数,指定的键不在字典中,必须设置 default 默认值,否则会报错。
- 返回值:如果指定的键在字典中,则返回指定键所对应的值,否则返回设置的 default 值。
【示例1】删除字典中指定键所对应的键值对,并返回被删除的值。

【示例2】删除字典中指定键所对应的键值对,并设置default值。

4.12 popitem() 方法 --返回并删除字典中的键值对
字典中的 popitem() 方法用于返回并删除字典中的一个键值对(一般删除字典末尾的键值对)。其语法格式如下:
dict.popitem()
参数说明:
- dict:字典对象。
- 返回值:返回一个(key,value)形式的键值对。
【示例1】返回并删除字典中的一个键值对。

【示例2】 分别获取返回并删除字典中的键与值。

4.13 setdefault() 方法–获取字典中指定键的值
字典 setdefault() 方法和 get() 方法类似,用于获取字典中指定键的值。如果键不在字典中,则会添加键到字典且将 default 值设为该键的值,并返回该值。其语法格式如下:
dict.setdefault(key[,default])
参数说明:
- dict:字典对象,即要从中获取值的字典。
- key:字典中要查找的键。
- default:可选参数,如果指定键的值不存在时,返回该值,默认为 None。
- 返回值:如果键在字典中,则返回键所对应的值。如果键不在字典中,则向字典中添加这个键,且设置 default 为这个键的值,并返回 default 值。
注意:在使用字典 setdefault() 方法时需要注意,如果指定的键存在,仍设置了 default 值,default 值不会覆盖原来已经存在的键所对应的值。

4.14 update() 方法–更新字典
字典中的 update() 方法用于更新字典,其参数可以是字典或者某种可迭代的数据类型。其语法格式如下:
dict.update(args)
参数说明:
- dict:指定的源字典对象。
- args:表示添加到指定字典 dict 里的参数,可以是字典或者某种可迭代的数据类型。
【示例1】将一个字典的键值对更新到(添加到)另一个字典中。
dict1 = {
'a': 1, 'b': 2}
print('更新前:', dict1) # 输出更新前的字典内容
dict2 = {
'c': 3}
dict1.update(dict2) # 将字典dict2中的"键值对"添加到字典dict中
print('更新后:', dict1) # 输出更新后的字典内容
【示例2】以元组为参数更新字典。
dict1 = {
'apple': 5.98, 'banana': 3.68}
print('更新前:', dict1) # 输出更新前的字典内容
list1 = [('pear', 3.00), ('watermelon', 2.89)] # 列表中的每个元组是一个键值对
dict1.update(list1) # 更新字典
print('更新后:', dict1) # 输出更新后的字典内容
提示:如果字典update()方法的参数是可迭代对象,则可迭代对象中的每一项自身必须是可迭代的,并且每一项只能有两个对象。第一个对象将作为新字典的键,第二个对象将作为其键对应的值。
【示例3】更新字典中相同的键。
dict1 = {
'apple': 5.98, 'banana': 3.68}
print('更新前:', dict1) # 输出更新前的字典内容
# 如果两个字典中有相同的键,则字典dict2中的键值将覆盖源字典dict1中的键值
dict2 = {
'apple': 8.89, 'pear': 3.00}
dict1.update(dict2) # 将字典dict2中的"键值对"添加到字典dict1中
print('更新后:', dict1) # 输出更新后的字典内容
【示例4】更新原字典中不存在的键值对。
# 小明第一次学习的单词
dict1 = {
'Tiger': '老虎', 'Giraffe': '长颈鹿', 'Lion': '狮子'}
# 第二次复习了第一次的两个单词,又新学习了两个单词
dict2 = {
'Tiger': '老虎', 'Lion': '狮子', 'Horse': '马', 'Bear': '熊'}
for i in dict2.items(): # 遍历dict2中的键值对
if i not in list(dict1.items()): # 如果dict2中的键值对不存在dict1当中
dict1.update([i]) # 就将不存在的键值对更新至dict1中
print('小明共学习了以下这些单词:\n', dict1)
4.15 values() 方法–获取字典的所有值
字典 values() 方法用于获取一个字典所有的值。返回的是一个可迭代对象,可以使用 list() 函数转换为列表。其语法格式如下:
dict.values()
参数说明:
- dict:字典对象。
- 返回值:返回一个可迭代对象。
【示例1】获取字典中所有值。
dictionary = {
'hour': 3, 'minute': 45, 'second': 21} # 创建字典
print(dictionary.values()) # 获取字典的所有值,返回一个可迭代对象
print(list(dictionary.values())) # 使用list()函数转换为列表
【示例2】循环遍历获取字典中的值。
dictionary = {
'小英子': '3月5日', '阳光': '12月8日', '茜茜': '7月6日', } # 创建字典
for value in dictionary.values(): # 通过for循环获取字典中具体的value(值)
print(value)
【示例3】通过lambda表达式获取字典中指定条件的值。
dict_demo = {
'apple': 6.5, 'orange': 3.98, 'pear': 8, 'banana': 2.89}
max_value = max(dict_demo.values(), key=lambda i: i) # 获取字典中所有值最大的那个
print('字典中值最大的为:', max_value)
# 获取字典中所有float类型的值
type_value = list(filter(lambda i: type(i) == float, dict_demo.values()))
print('字典中所有float类型的值为:', type_value)
# 获取字典中长度为3的那个值
len_value = list(filter(lambda i: len(str(i)) == 3, dict_demo.values()))
print('字典中长度为3的值是:', len_value[0])
五、集合
5.1 “{}” --直接创建集合
在 Python 中,创建 set 集合也可以像列表、元组和字典一样,直接将集合赋值给变量从而实现创建集合,即直接使用大括号 {} 创建。语法格式如下:
setname = {
element 1,element 2,element 3,…,element n}
参数说明:
- setname:表示集合名称,可以是任何符合 Python 命名规则的标识符。
- element1、element2、element3、elementn:表示集合中的元素,个数没有限制,并且只要是 Python 支持的不可变数据类型(如字符串、数字、元组及布尔类型的 True 或者 False 等,但不能是列表、字典等)就可以,如下:

【示例1】直接创建集合并输出。
set1 = {
2, 4, 6, 8} # 创建10以内偶数的集合
print('set1:', set1)
set2 = {
'a', 'b', 'c', 'd', 'e'} # 部分小写英文字母的集合
print('set2:', set2)
# 手机品牌名称字符串的集合
set3 = {
'华为', 'Iphone', 'OPPO', '小米'}
print('set3:', set3)
set4 = {
'Python', 18, ('人生苦短', '我用Python')} # 不同类型数据的集合
print('set4:', set4)
# 保存学生信息元组的集合
set5 = {
('1001', 'Amo', 10, 20, 30), ('1002', 'Paul', 100, 96, 97)}
print('set6:', set5)
set6 = {
'A', 'B', 'C', 'A', 'D', True}
print('set6:', set6)
输出结果为:

说明:在创建集合时,如果输入了重复的元素,Python会自动只保留一个。由于Python中的set集合是无序的,所以每次输出时元素的排列顺序可能都不相同。
【示例2】循环遍历集合中的元素。
# 直接创建集合
name_set = {
"Amo", "Paul", "Jerry", "Ben", "Crystal"}
for name in name_set:
print(name) # 输出集合元素
【示例3】通过集合推导式生成集合。
import random
set1 = {
i for i in range(10)} # 创建0~10之间(不包括10)的数字集合
print(set1)
set2 = {
i for i in range(2, 10, 2)} # 创建10以内(不包括10)的偶数集合
print(set2)
# 创建无重复的4位随机数集合
set3 = {
random.randint(1000, 10000) for i in range(10)}
print(set3)
set4 = {
i for i in '壹贰叁肆伍'} # 将字符串转换为集合
print(set4)
# 生成所有单词首字母集合
set5 = {
i[0] for i in ['Early', 'bird', 'gets', 'the', 'worm']}
print(set5)
# 将原集合中的数字折半后生成新的集合
set6 = {
int(i * 0.5) for i in {
1200, 5608, 4314, 6060, 5210}}
print(set6)
set7 = {
i for i in ('Early', 'bird', 'gets', 'the', 'worm')} # 通过元组生成新的集合
print(set7)
# 将字典的Key生成新的集合
set8 = {
key for key in {
'Amo': '84978981', 'Jerry': '84978982', 'Paul': '84978981'}}
print(set8)
# 将字典的Value生成新的集合
set9 = {
v for k, v in {
'Amo': '84978981', 'Jerry': '84978982', 'Paul': '84978981'}.items()}
print(set9)
5.2 “&” --交集
可以使用 & 符号来计算两个或更多集合的交集,即返回集合 a 和集合 b 中都包含的元素。其语法格式如下:
set_a & set_b # 相当于set_a.intersection(set_b)
参数说明:
- set_a:集合 a。
- set_b:集合 b,参数可以是一个或多个集合。
- 返回值:返回集合的交集。
【示例1】计算两个集合的交集。通过“&”计算两个集合的交集,示例代码如下:
# 创建集合
a = {
3, 4, 5, 6}
b = {
5, 6, 7, 8}
# 返回集合的交集
print("a、b的交集:", a & b) # 返回{5, 6}
输出结果为:
a、b的交集: {5, 6}
【示例2】计算多个集合的交集。

【示例3】 在集合中“&”不等于“and”。在python 中 “&”代表的是位运算符,而“and”代表的是逻辑运算符,当 set1 and set2 的结果为 True 时,返回的结果并不是 True,而是运算结果的最后一位变量的值,这里返回的是 set2 的值。当 set1 & set2 时,则表示求set1和set2的交集(获取两个集合共同拥有的元素)。示例代码如下:
set1 = {
1, 3, 5, 7, 9}
set2 = {
2, 4, 6, 7, 8}
print('and结果为:', set1 and set2)
print('&结果为:', set1 & set2)
输出结果为:
and结果为: {2, 4, 6, 7, 8}
&结果为: {7}
5.3 “^” --对称差集
可以使用 ^ 符号来计算两个集合的对称差集。即返回由集合 a 和集合 b 中不重复的元素组成的集合。其语法格式如下:
set_a ^ set_b # 相当于set_a.symmetric_difference(set_b)
参数说明:
- set_a:集合 a。
- set_b:集合 b。
- 返回值:返回对称差集。
【示例1】 计算集合的对称差集。通过“^”计算集合的对称差集,示例代码如下:

5.4 “|” --并集
可以使用 | 符号来计算两个或更多集合的并集,即将集合a和集合b中的元素合并在一起。其语法格式如下:
set_a | set_b # 相当于set_a.union(set_b)
参数说明:
- set_a:集合 a。
- set_b:集合 b,参数可以是一个或多个集合。
- 返回值:返回集合的并集。
提示:执行集合的并集操作时,重复的元素会自动保留一个。集合的并集操作,也可以使用union()方法。
【示例1】 计算集合的并集。
# 创建集合
a = {
1, 2}
b = {
3, 4, 5, 6}
c = {
1, 3, 10}
# 返回集合的并集
print("a、b的并集:", a | b) # 返回{1, 2, 3, 4, 5, 6}
print("a、b、c的并集:", a | b | c) # 返回{1, 2, 3, 4, 5, 6, 10}
print("a、c的并集:", a.union(c)) # 返回{1, 2, 3, 10}
【示例2】 在集合中“|”不等于“or”。
a = 'python' # 字符串数据a
b = 'pycharm' # 字符串数据b
set1 = set(a) # 将字符串a转换为集合1
set2 = set(b) # 将字符串b转换为集合2
print('or结果为:', set1 or set2)
print('|结果为:', set1 | set2)
5.5 “-” --差集
可以使用 - 符号来计算两个或更多集合的差集。即集合元素包含在集合 a 中,但不包含在集合 b 中。其语法格式如下:
set_a - set_b # 相当于set_a.difference(set_b)
参数说明:
- set_a:集合 a。
- set_b:集合 b,参数可以是一个或多个集合。
- 返回值:返回集合的差集。
【示例1】 计算集合的差集。
# 创建集合
a = {
1, 2, 3, 4}
b = {
3, 4, 5, 6}
c = {
1, 3, 10}
# 返回集合的差集
print("a与b的差集:", a - b) # 返回{1, 2}
print("a与c的差集:", a - c) # 返回{2, 4}
print("a与b、c的差集:", a - b - c) # 返回{2}
print("b与c的差集:", b.difference(c)) # 返回{4, 5, 6}
print("c与b的差集:", c.difference(b)) # 返回{1, 10}
5.6 “<=” --判断当前集合是否为另一个集合的子集
可以使用 <= 运算符判断当前集合是否为另一个集合的子集,即判断集合 a 中的所有元素是否都包含在集合 b 中。其语法格式如下:
set_a <= set_b # 相当于set_a.issubset(set_b)
参数说明:
- set_a:集合 a。
- set_b:集合 b。
- 返回值:返回布尔值,如果集合 a 中的所有元素都包含在集合 b 中,则返回 True,否则返回 False。
【示例1】 判断一个集合是否为另一个集合的子集。
# 创建集合
a = {
1, 2, 3, 4}
b = {
1, 3, 4, 5, 6}
c = {
1, 3}
d = {
3, 1}
# 判断集合是否为另一个集合的子集
print("a<=b返回:", a <= b) # 返回False
print("c<=a返回:", c <= a) # 返回True
print("c<=d返回:", c <= d) # 返回True
print("c.issubset(b)返回:", c.issubset(b)) # 返回True
【示例2】 使用“<”运算符判断当前集合是否为另一个集合的真子集。子集就是一个集合中的全部元素是另一个集合中的元素,有可能与另一个集合相等;真子集就是一个集合中的元素全部是另一个集合中的元素,但不存在相等。
# 创建集合
a = {
"Python", "Java"}
b = {
"Java", "Python"}
c = {
"Java", "PHP", "C#"}
# 判断一个集合是否为另一个集合的子集
print("a<=b返回:", a <= b) # 返回True
print("a<=c返回:", a <= c) # 返回False
# 判断一个集合是否为另一个集合的真子集
print("a, a < b) # 返回False
print("a, a < c) # 返回False
5.7 “==” --判断两个集合是否相等
可以使用 == 运算符判断两个集合是否相等(包含相同的元素),即判断集合 a 和集合 b 中的元素是否相同。其语法格式如下:
set_a == set_b
参数说明:
- set_a:集合 a。
- set_b:集合 b。
- 返回值:返回布尔值,如果集合 a 和集合 b 中的元素相同,则返回 True,否则返回 False。
!=与==刚好相反,如果集合a和集合b中的元素相同,则返回False,否则返回True。语法格式如下:
set_a == set_b
【示例1】判断两个集合是否相等。
# 创建集合
a = {
"刀", "枪", "剑", "戟"}
b = {
"戟", "剑", "枪", "刀"}
c = {
"斧", "钺", "钩", "叉"}
# 判断两个集合是否相等
print("a==b返回:", a == b) # 返回True
print("a==c返回:", a == c) # 返回False
print("a!=b返回:", a != b) # 返回False
print("a!=c返回:", a != c) # 返回True
5.8 “>=” --判断当前集合是否为另一个集合的超集
可以使用 >= 运算符判断当前集合是否为另一个集合的超集,即判断集合 b 中的所有元素是否都包含在集合 a 中。其语法格式如下:
set_a >= set_b # 相当于set_a.issuperset(set_b)
参数说明:
- set_a:集合 a。
- set_b:集合 b。
- 返回值:返回布尔值,如果集合 b 中的所有元素都包含在集合 a 中,则返回 True,否则返回 False。
【示例1】判断一个集合是否为另一个集合的超集。
# 创建集合
a = {
'赵', '钱', '孙', '李'}
b = {
'赵', '孙', '李', '周', '吴'}
c = {
'赵', '孙'}
d = {
'王', '郑'}
# 判断集合是否为另一个集合的超集
print("a>=b返回:", a >= b) # 返回False
print("b>=c返回:", b >= c) # 返回True
print("a>=c返回:", a >= c) # 返回True
print("a.issuperset(d)返回:", a.issuperset(d)) # 返回False
【示例2】使用“>”运算符判断当前集合是否为另一个集合的真超集。如果集合b中的每一个元素都在集合a中,且集合a中可能包含集合b中没有的元素,则集合a就是集合b的超集(有可能与另一个集合相等);若集合a中一定有集合b中没有的元素,则集合a是集合b的真超集(不存在相等)。
# 创建集合
a = {
"001", "003", "005"}
b = {
"003", "005"}
c = {
"005", "003"}
# 判断一个集合是否为另一个集合的超集
print("a>=b返回:", a >= b) # 返回True
print("b>=c返回:", b >= c) # 返回True
# 判断一个集合是否为另一个集合的真超集
print("a>b返回:", a > b) # 返回True
print("b>c返回:", b > c) # 返回False
5.9 add()方法 --向集合中添加元素
集合中的 add() 方法用于向集合中添加元素,如果添加的元素在集合中已存在,则不执行任何操作。其语法格式如下:
set.add(element)
参数说明:
- set:表示要添加元素的集合。
- element:表示要添加的元素内容,只能使用字符串、数字、元组及布尔类型的 True 或者 False 等不可变对象,但不能使用列表、字典等可变对象。
【示例1】将指定元素添加到集合当中。使用add()方法将指定元素添加到集合中,示例代码如下:
university = {
"重庆大学", "重庆邮电大学", "厦门大学", "四川大学"}
print("添加元素前:", university)
university.add("南京大学") # 添加一个元素
print("添加元素后:", university)
输出结果为:
添加元素前: {'四川大学', '重庆大学', '重庆邮电大学', '厦门大学'}
添加元素后: {'重庆大学', '重庆邮电大学', '四川大学', '南京大学', '厦门大学'}
【示例2】向集合中添加已经存在的元素。

注意:集合 add() 方法的 element 参数只能使用字符串、数字、元组及布尔类型的 True 或者 False 等不可变对象,但不能使用列表、字典等可变对象。否则将提示 TypeError 错误。代码如下:

5.10 clear()方法 --删除集合中的全部元素
集合中的 clear() 方法用于删除集合中的全部元素,使其变为空集合。其语法格式如下:
set.clear() # set:表示要删除全部元素的集合。
【示例1】删除集合中的全部元素。

提示:我们可以使用del set命令删除整个集合。但del语句在实际开发时,并不常用。因为Python自带的垃圾回收机制会自动销毁不用的集合,所以即使我们不手动将其删除,Python也会自动将其回收。
5.11 copy()方法 --复制一个集合
集合中的 copy() 方法用于复制一个集合。其语法格式如下:
set.copy()
参数说明:
- set:表示需要复制的集合。
- 返回值:返回复制后的新集合。
【示例1】复制一个集合。

【示例2】直接赋值和copy()方法的区别。
a = {
1, 2, 3, 4, 5} # 创建集合a
b = a # 直接赋值
c = a.copy() # 复制一个集合
print("a:", a)
print("b:", b)
print("c:", c, "\n")
a.add("Python") # 添加指定元素到集合a
print("a:", a)
print("b:", b)
print("c:", c, "\n")
b.discard(5) # 移除b中的指定元素
print("a:", a)
print("b:", b)
print("c:", c, "\n")
c.clear() # 清空集合c
print("a:", a)
print("b:", b)
print("c:", c)