Bourne强化学习笔记2:彻底搞清楚什么是Q-learning与Sarsa
为了理清强化学习中最经典、最基础的算法——Q-learning,根据ADEPT的学习规律(Analogy / Diagram / Example / Plain / Technical Definition),本文努力用直观理解、数学方法、图形表达、简单例子和文字解释来展现其精髓之处。区别于众多Q-learning讲解中的伪代码流程图,本文将提供可视化的算法流程图帮助大家学习、对比Q-learning与Sarsa。
( 在此假设大家已了解TD Method, ε-greedy policy,off-policy 和 on-policy相关知识。想了解的童鞋也可在本文最后Reference或链接中学习)
一、直观理解
任何强化学习的问题都需要兼顾探索(Exploration)和利用(Exploitation),因此TD方法也对应有两种经典的衍生算法:Q-learning(off-policy)和Sarsa(on-policy)。基于off-policy思想的Q-learning,与Monte Carlo 方法中off-policy的灵魂思路是一致的,除了更新价值的步数不一样之外。在此引用笔者之前回答中关于off-policy的一个比喻。
古时候,优秀的皇帝都秉持着“水能载舟 亦能覆舟”的思想,希望能多了解民间百姓的生活。皇帝可以选择通过微服出巡,亲自下凡了解百姓生活(On-policy),虽然眼见为实,但毕竟皇帝本人分身乏术,掌握情况不全;因此也可以派多个官员去了解情况,而皇帝本人则躺在酒池肉林里收听百官情报即可(Off-policy)。 (坏皇帝则派出“锦衣卫”_(´ཀ`」 ∠)_)
不清楚off-policy的同学可以点击以下传送门:
https://www.zhihu.com/question/57159315/answer/465865135
二、算法流程
本文首先放出两张一目了然的流程图: Q-learning和Sarsa,为了可以直接于可视化流程图的比较之中领悟这两种方法的思路和差别。
1. Sarsa
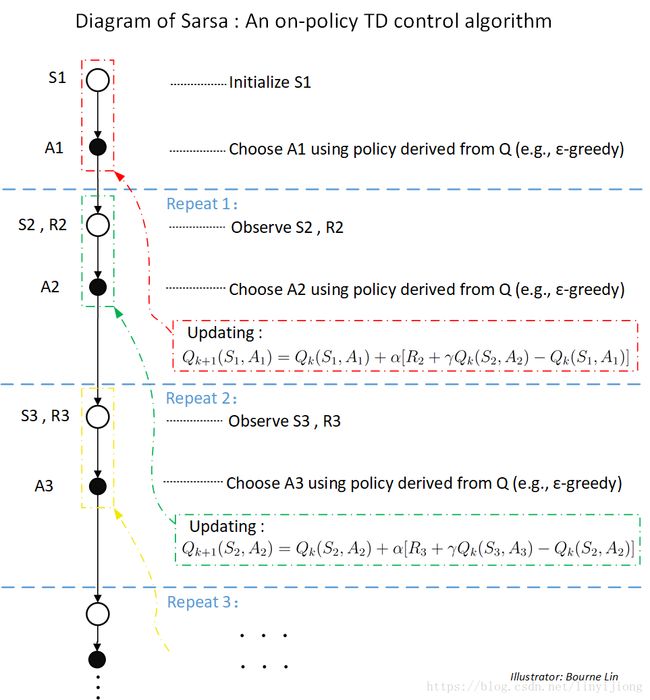
(已了解Sarsa的同学也不要轻易跳过,或者对比过后,你会有新的发现)
1.1) 一个回合(Episode)开始,随机选择(初始化)第一个状态。并基于 ε-greedy策略在状态中选择动作,有两种情况,一是有 的概率直接选择具有最大值Q的动作,二是有 ε 概率随机选择 下的任意动作(在第二种情况下每个动作的概率均为 ,其中 为 下的动作总个数)。
1.2) 进入第一次循环(Repeat 1 / Step 1):执行 之后(与环境互动),观察下一个状态 ,并马上得到 的即时回报 。此时,再次基于 ε-greedy策略,在状态中选择动作。得到 后,即可进行Q函数的更新(Update),更新中的 为ε-greedy策略下所随机选取的动作,这是与Q-learning的不同之处!(下标 k 或 i 表示最近一次更新的Q值,是一个迭代序数而非时间步(step)序数,在此可先忽略。)
1.3) 不断循环第二步,直到终止状态。
2. Q-learning
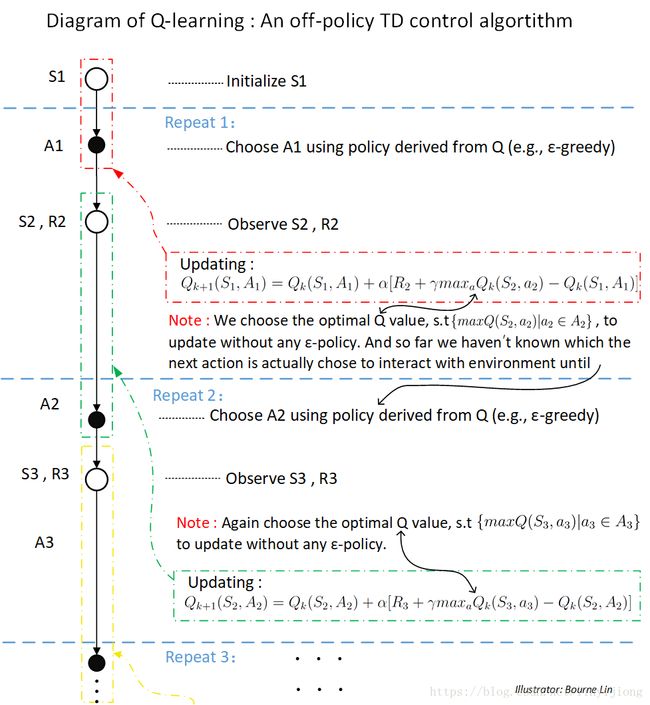
2.1) 一个回合(Episode)开始,随机选择(初始化)第一个状态。
2.2) 进入第一次循环(Repeat 1 / Step 1):首先基于 ε-greedy策略在状态中选择动作。选择并执行 之后(与环境互动),观察下一个状态 ,并马上得到 的即时回报 。此时,立即进行Q函数的更新(Update),更新中的 为我们人为直接选择 下所有动作中具有最大Q值的动作,这就是与Saras根本区别!
2.3) 更新完毕后,进入第二次循环:基于 ε-greedy策略,在状态中选择动作与环境互动(此前在状态时候并未采取动作与环境互动)。值得注意的是,我们在循环1中更新(Update)时所选取 的动作 是唯一的(人为强制选择),即最具有最大价值Q的动作 ;而循环2中作为需要与环境互动的第二次动作 则是基于ε-greedy策略(即在此时究竟选取 对应的动作 还是其他动作完全根据是随机选择,听天由命吧 0.0 )!因此,基于ε-greedy策略,与环境互动、做学习训练时做动作选择的决策(在off-policy中这被称为行为策略)与Sarsa是一致的。
3. 细节
不少学童鞋对这两幅伪码图中的动作符号存疑:为什么动作的表示有时候为大写的A,有时候为小写的a?
(引用R. S. Sutton与A.G. Barto于2018年1月1日发布的《Reinforcement learning: An introduction》第二版)

Pseudo code of Sarsa

Pseudo code of Q-learning
大写的A表示集合,比如 则表示 下的所有动作,而 则表示具体的一个动作,它们之间的关系为:。回到流程图中,可以发现出现a都在Q-learning的update公式中,这是因为我们在更新时,人为指定选择具有最大值Q的a,这是具有确定性的事件(Deterministic)。而在Q-learning中与环境互动的环节、在Sarsa中更新Q值的环节与环境互动的环节时,动作的选择是随机的( ε-greedy),因此所有动作都有可能被选中,只不过是具有最大值Q的动作被选中的概率大。
此时我们可以清楚知道Sutton书中的伪代码的全部含义啦^_^!
三、Q-learning如何实现更加有效的探索?
清楚整个流程之后,我们来具体看看,Q-learning到底是怎么实现有意义的探索,如何在环境中发掘出更有价值的动作?(即一个当前估值(evaluate)不高但潜力巨大的动作的逆袭之路)
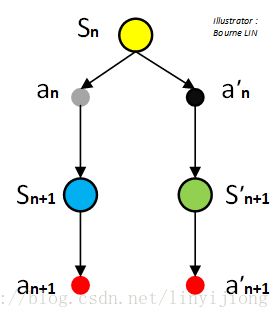
第一个简单的栗子
在这个例子中,我们将更新黄色状态的动作价值。
假设已知黄色状态下只有两个动作可选:灰动作和黑动作。而蓝色、绿色状态下最大价值动作均为红动作,其他动作暂不列出(因为在Q-learning中更新时,人为强制选择下一状态中最大价值的动作,因此同一状态下的其他动作在更新环节没有任何体现)。
在某个回合(episode)中,在时间步为n的时候(time step = n),所处状态为黄色。并且在第k-1次更新 时,( 通过即时奖励获取,不纳入更新迭代次数k),已知灰动作价值比黑动作大,即有
所以基于 ε-greedy策略选择动作,会出现情况①或②:
①有 的可能性选择当前最大价值Q的灰动作
而另一黑动作没有更新,即 。
其中, S_n=yellow 、 。
②有 ε /2 的可能性选择当前较小价值Q的黑动作 a_n':
而另一灰动作没有更新,即。
其中, S_n=yellow 、 。
无论发生情况①或是②,黄色状态下的灰动作与黑动作的价值的大小关系都可能发生变化!!我们通过取最大值(即greedy思想)来更新目标策略 \pi (target policy), :
比如,当出现情况②的时候,即探索(explore)了黑动作,更新后有 ,则此时黄色状态下的黑动作变为最优动作(颠覆了灰色动作有最大Q值的地位)。
四、另一个栗子
在此举一个非常直观的例子来帮助我们认识一下Q-learning和Sarsa的实际应用效果的区别。
在下面栅格化的小世界中,绿色区域为草地,在上面每移动一格子就会扣1分,而踏入黑色区域的悬崖(chasm),会扣一百分,并且回到起始点S (Start)。我们希望能学习到一条得分最高的路径到达终点T (Terminal)。分别使用Sarsa和Q-learning进行学习。结果如图所示,红色为相应算法的最优路径。

Sarsa v.s Q-learning
可以看到,Q-learning寻找到一条全局最优的路径,因为虽然Q-learning的行为策略(behavior)是基于 ε-greedy策略,但其目标策略(target policy)只考虑最优行为;而Sarsa只能找到一条次优路径,这条路径在直观上更加安全,这是因为Sarsa(其目标策略和行为策略为同一策略)考虑了所有动作的可能性( ε-greedy),当靠近悬崖时,由于会有一定概率选择往悬崖走一步,从而使得这些悬崖边路的价值更低。
五、总结
Q-learning虽然具有学习到全局最优的能力,但是其收敛慢;而Sarsa虽然学习效果不如Q-learning,但是其收敛快,直观简单。因此,对于不同的问题,我们需要有所斟酌。
Reference
-
Watkins C J C H, Dayan P. Technical Note: Q-Learning[J]. Machine Learning, 8(3-4):279-292, 1992.
-
R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction. IEEE Transactions on Neural Networks, 9(5):1054–1054, 2018.
声明:本图文未经作者允许,谢绝转载。
囧Bourne:强化学习中on-policy 与off-policy有什么区别?