系统框架:

其中损失网络是在imgnet上预训练过的vgg16,训练过程中参数保持不变;
变换网络fw是深度残差网络(deep residual cnn);
损失网络对比生成网络生成的图片与每一幅训练集中的目标图片,
于是损失函数可表示为:
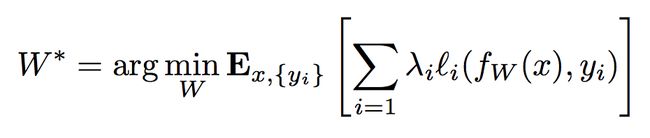
网络细节的设计大体遵循DCGAN中的设计思路:
1.不使用pooling层,而是使用strided和fractionally strided卷积来做downsampling和upsampling,
2.使用了五个residual blocks
深度残差网络(resnet):理论上网络深度越深能够提供更好的特征表示,然而梯度弥散/爆炸成为训练深层次的网络的障碍,导致无法收敛。有一些方法可以弥补,如归一初始化,各层输入归一化,使得可以收敛的网络的深度提升为原来的十倍。然而,虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差。深度残差网络采用的解决方法是让网络F(x)学习残差y-x,基于的理论是至少让误差不会变得更大。
残差连接可以帮助网络学习到一致性(identity function),而生成模型也要求结果图像和生成图像共享某些结构,因而,残差连接能够更好地对应DCGAN的生成模型。
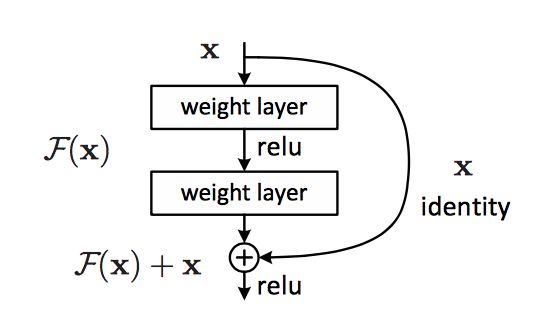


3.除了输出层之外的所有的非residual blocks后面都跟着spatial batch normalization和ReLU的非线性激活函数。
4.输出层使用一个scaled tanh来保证输出值在[0, 255]内。
5.第一个和最后一个卷积层使用9×9的核,其他卷积层使用3×3的核。
损失函数构建:
损失函数与gatys的定义类似,具体有,
1. 感知损失并不是直接构建在生成图与目标图之间,而是通过损失网络的二者响应之间
2.特征重构损失(内容损失):

3.风格重构损失:


结论:
与gatys的原文相比,最大的特点是快!一次训练,终身搞定!(当然训练的速度如狗屎一般慢)