Flutter · Python AI 弹幕播放器来袭
AI智能弹幕(也称蒙版弹幕):弹幕浮在视频的上方却永远不会挡住人物。起源于哔哩哔哩的web端黑科技,而后分别实现在IOS和Android的app端,如今被用于短视频、直播等媒体行业,用户体验提升显著。
本文除了会使用Flutter新方案进行跨端实现,同时也会讲解如何将一段任意视频流使用opencv-python处理成蒙版数据源,达成从0到1的前后端AI体系。先来看看双端最终运行效果吧:
自行clone源码打包:Zoe barrage
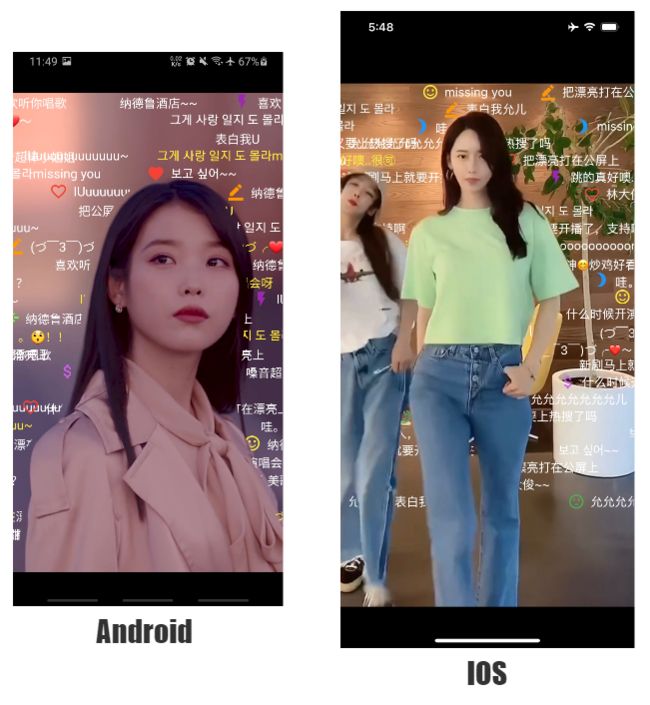
IPhone运行录屏:点这里
APP运行截图:
实现流程目录
- Python后端:
- 依次提取视频流的 关键帧 保存为图片
- 将所有关键帧传给 神经网络模型 让算法将图片中非人物抹去,并保存图片帧
- 将只含有人物的图片帧进行 像素色值转换,得到 灰度图,最后再转为 黑白反色图
- 通过识别黑白反色图的 轮廓坐标 ,生成一份 时间:路径 配置文件提供给前端
- Flutter前端:
- 实现一个弹幕调度动画组
- 根据 配置文件 将弹幕外层容器 裁剪 为一个刚好透出人物的漏洞形状,也称蒙版
- 引入播放器,视频流播放时,为 关键帧 同步渲染其对应的蒙版形状
- 拓展:
- Web前端实现
- 视频点播与直播
- 总结与优化
1. Python后端
1.1 提取关键帧
# config.py --- 配置文件
import os
import cv2
VIDEO_NAME = 'source.mp4' # 处理的视频文件名
FACE_KEY = '*****' # AI识别key
FACE_SECRET = '*****' # AI密钥
dirPath = os.path.dirname(os.path.abspath(__file__))
cap = cv2.VideoCapture(os.path.join(dirPath, VIDEO_NAME))
FPS = round(cap.get(cv2.CAP_PROP_FPS), 0)
# 进行识别的关键帧,FPS每上升30,关键帧间隔+1(保证flutter在重绘蒙版时的性能的一致性)
FRAME_CD = max(1, round(FPS / 30))
if cv2.CAP_PROP_FRAME_COUNT / FRAME_CD >= 900:
raise Warning('经计算你的视频关键帧已经超过了900,建议减少视频时长或FPS帧率!')
在这份配置文件中,会先读取视频的帧率,30FPS的视频会吧每一帧都当做关键帧进行处理,60FPS则会隔一帧处理一次,这样是为了保证Flutter在绘制蒙版的性能统一。
另外需要注意的是由于演示DEMO为完全离线环境,视频和最终蒙版文件都会被打包到APP,视频文件不宜过大。
# frame.py --- 视频帧提取
import os
import shutil
import cv2
import config
dirPath = os.path.dirname(os.path.abspath(__file__))
images_path = dirPath + '/images'
cap = cv2.VideoCapture(os.path.join(dirPath, config.VIDEO_NAME))
count = 1
if os.path.exists(images_path):
shutil.rmtree(images_path)
os.makedirs(images_path)
# 循环读取视频的每一帧
while True:
ret, frame = cap.read()
if ret:
if(count % config.FRAME_CD == 0):
print('the number of frames:' + str(count))
# 保存截取帧到本地
cv2.imwrite(images_path + '/frame' + str(count) + '.jpg', frame)
count += 1
cv2.waitKey(0)
else:
print('frames were created successfully')
break
cap.release()
这里使用opencv提取视频的关键帧图片并保存在当前目录images文件夹下。
1.2 通过AI模型提取人物
提取图像中人物的工作需要交给 卷积神经网络 来完成,不同程度的训练对图像分类的准确率影响很大,而这也直接决定了最终的效果。大公司有算法团队来专门训练模型,我们的DEMO使用FACE++提供的开放测试接口,准确率与其付费商用的无异,就是会被限流,失败率高达80%,不过后面我们可以在代码编写中解决这个问题。
# discern.py --- 调用算法接口返回人体模型灰度图
import os
import shutil
import base64
import re
import json
import threading
import requests
import config
dirPath = os.path.dirname(os.path.abspath(__file__))
clip_path = dirPath + '/clip'
if not os.path.exists(clip_path):
os.makedirs(clip_path)
# 图像识别类
class multiple_req:
reqTimes = 0
filename = None
data = {
'api_key': config.FACE_KEY,
'api_secret': config.FACE_SECRET,
'return_grayscale': 1
}
def __init__(self, filename):
self.filename = filename
def once_again(self):
# 成功率大约10%,记录一下被限流失败的次数 :)
self.reqTimes += 1
print(self.filename +' fail times:' + str(self.reqTimes))
return self.reqfaceplus()
def reqfaceplus(self):
abs_path_name = os.path.join(dirPath, 'images', self.filename)
# 图片以二进制提交
files = {'image_file': open(abs_path_name, 'rb')}
try:
response = requests.post(
'https://api-cn.faceplusplus.com/humanbodypp/v2/segment', data=self.data, files=files)
res_data = json.loads(response.text)
# 免费的API 很大概率被限流返回失败,这里递归调用,一直到这个图片成功识别后返回
if 'error_message' in res_data:
return self.once_again()
else:
# 识别成功返回结果
return res_data
except requests.exceptions.RequestException as e:
return self.once_again()
# 多线程并行函数
def thread_req(n):
# 创建图像识别类
multiple_req_ins = multiple_req(filename=n)
res = multiple_req_ins.reqfaceplus()
# 返回结果为base64编码彩色图、灰度图
img_data_color = base64.b64decode(res['body_image'])
img_data = base64.b64decode(res['result'])
with open(dirPath + '/clip/clip-color-' + n, 'wb') as f:
# 保存彩色图片
f.write(img_data_color)
with open(dirPath + '/clip/clip-' + n, 'wb') as f:
# 保存灰度图片
f.write(img_data)
print(n + ' clip saved.')
# 读取之前准备好的所有视频帧图片进行识别
image_list = os.listdir(os.path.join(dirPath, 'images'))
image_list_sort = sorted(image_list, key=lambda name: int(re.sub(r'\D', '', name)))
has_cliped_list = os.listdir(clip_path)
for n in image_list_sort:
if 'clip-' + n in has_cliped_list and 'clip-color-' + n in has_cliped_list:
continue
'''
为每帧图片起一个单独的线程来递归调用,达到并行效果。所有图片被识别保存完毕后退出主进程,此过程需要几分钟。
(这里每个线程中都是不断地递归网络请求、挂起等待、IO写入,不占用CPU)
'''
t = threading.Thread(target=thread_req, name=n, args=[n])
t.start()
先读取上文images目录下所有关键帧列表,并为每一个关键帧图片起一个线程,每个线程里创建一个识别类multiple_req的实例,在每个实例里会对当前传入的文件进行不断递归提交识别请求,一直到识别成功为止(请大家自行申请一个免费KEY,我怕face++把我的号封了:)返回识别后的图片保存在clip目录下。
这个过程因为接口命中成功率很低,同一张图片甚至会反复识别几十次,不过大部分时间都是在等待网络传输和IO读写,所以可以放心大胆地起几百个线程CPU单核都跑不满,等个几分钟全部结果返回脚本会自动退出。
1.2 像素转换、生成轮廓路径
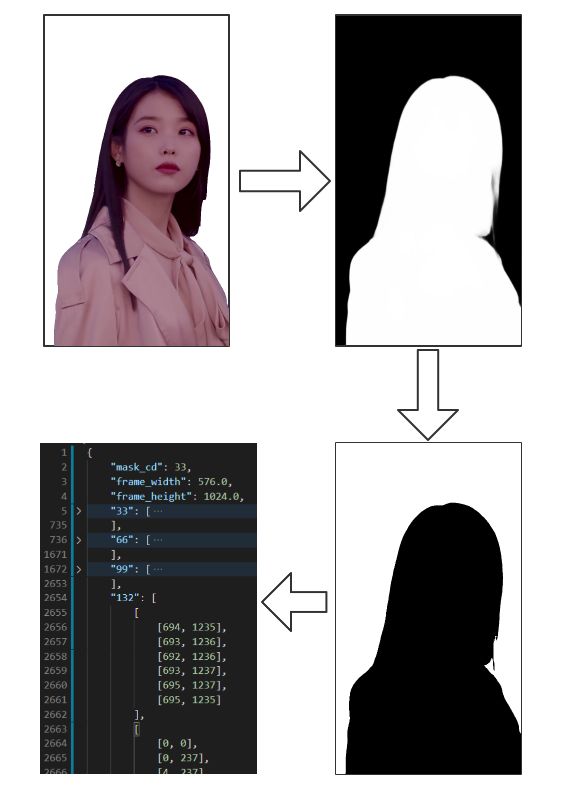
我们之前已经得到了算法帮我们提取后的人关键帧,接下来需要利用opencv来转换像素:
人物关键帧 to 灰度图 to 黑白反色图 to 轮廓JSON
# translate.py --- openCV转换灰度图 & 轮廓判定转换坐标JSON
import os
import json
import re
import shutil
import cv2
import config
dirPath = os.path.dirname(os.path.abspath(__file__))
clip_path = os.path.join(dirPath, 'mask')
cap = cv2.VideoCapture(os.path.join(dirPath, config.VIDEO_NAME))
frame_width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # 分辨率(宽)
frame_height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # 分辨率(高)
FPS = round(cap.get(cv2.CAP_PROP_FPS), 0) # 视频FPS
mask_cd = int(1000 / FPS * config.FRAME_CD) # 初始帧时间
milli_seconds_plus = mask_cd # 每次递增一帧的增加时间
jsonTemp = { # 最后要存入的json配置
'mask_cd': mask_cd,
'frame_width': frame_width,
'frame_height': frame_height
}
if os.path.exists(clip_path):
shutil.rmtree(clip_path)
os.makedirs(clip_path)
# 输出灰度图与轮廓坐标集合
def output_clip(filename):
global mask_cd
# 读取原图(这里我们原图就已经是灰度图了)
img = cv2.imread(os.path.join(dirPath, 'clip', filename))
# 转换成灰度图(openCV必须要转换一次才能喂给下一层)
gray_in = cv2.cvtColor(img , cv2.COLOR_BGR2GRAY)
# 反色变换,gray_in为一个三维矩阵,代表着灰度图的色值0~255,我们将黑白对调
gray = 255 - gray_in
# 将灰度图转换为纯黑白图,要么是0要么是255,没有中间值
_, binary = cv2.threshold(gray , 220 , 255 , cv2.THRESH_BINARY)
# 保存黑白图做参考
cv2.imwrite(clip_path + '/invert-' + filename, binary)
# 从黑白图中识趣包围图形,形成轮廓数据
contours, _ = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 解析轮廓数据存入缓存
clip_list = []
for item in contours:
if item.size > 0:
# 每个轮廓是一个三维矩阵,shape为(n, 1, 2) ,n为构成这个面的坐标数量,1没什么意义,2代表两个坐标x和y
rows, _, __ = item.shape
clip = []
clip_list.append(clip)
for i in range(rows):
# 将np.ndarray转为list,不然后面JSON序列化解析不了
clip.append(item[i, 0].tolist())
millisecondsStr = str(mask_cd)
# 将每一个轮廓信息保存到key为帧所对应时间的list
jsonTemp[millisecondsStr] = clip_list
print(filename + ' time(' + millisecondsStr +') data.')
mask_cd += milli_seconds_plus
# 列举刚才算法返回的灰度图
clipFrame = []
for name in os.listdir(os.path.join(dirPath, 'clip')):
if not re.match(r'^clip-frame', name):
continue
clipFrame.append(name)
# 对文件名进行排序,按照帧顺序输出
clipFrameSort = sorted(clipFrame, key=lambda name: int(re.sub(r'\D', '', name)))
for name in clipFrameSort:
output_clip(name)
# 全部坐标提取完成后写成json提供给flutter
jsObj = json.dumps(jsonTemp)
fileObject = open(os.path.join(dirPath, 'res.json'), 'w')
fileObject.write(jsObj)
fileObject.close()
print('calc done')
对每一个人物关键帧进行计算,这里就是一层层的像素操作。opencv会把图片像素点生成numpy三维矩阵,计算速度快,操作起来便捷,比如我们要把一个三维矩阵gray_in的灰度图黑白像素对换,只需要gray = 255 - gray_in就可以得到一个新的矩阵而不需要用python语言来循环。
最后把计算出的帧的闭包图形路径转换为普通的多维数组类型并存入配置文件Map,key为视频的进度时间ms,value为闭包路径(就是图中白色区域的包围路径,排除黑色人物区域),是一个二维数组,因为一帧里会有n个闭包路径组成。另外还要将视频信息存入配置文件,其中frame_cd就是告诉flutter每间隔多少ms切换下一帧蒙版,视频的宽高分辨率用于flutter初始化播放器自适应布局。
具体JSON数据结构可见上方图片。现在我们已经得到了一个res.json的配置文件,里面包含了该视频关键帧数据的裁剪坐标集,接下来就用flutter去剪纸吧~
2. Flutter前端
2.1 弹幕调度动画组
弹幕调度系统各端实现都大同小异,只是动画库的API方式区别。flutter里使用SlideTransition可以实现单条弹幕文字的动画效果。
// core.dart --- 单条弹幕动画
class Barrage extends StatefulWidget {
final BarrageController barrageController;
Barrage(this.barrageController, {Key key}) : super(key: key);
@override
_BarrageState createState() => _BarrageState();
}
class _BarrageState extends State with TickerProviderStateMixin {
AnimationController _animationController;
Animation _offsetAnimation;
_PlayPauseState _playPauseState;
void _initAnimation() {
final barrageController = widget.barrageController;
_animationController = AnimationController(
value: barrageController.value.scrollRate,
duration: barrageController.duration,
vsync: this,
);
_animationController.addListener(() {
barrageController.setScrollRate(_animationController.value);
});
_offsetAnimation = Tween(
begin: const Offset(1.0, 0.0),
end: const Offset(-1.0, 0.0),
).animate(_animationController);
_playPauseState = _PlayPauseState(barrageController)
..init()
..addListener(() {
_playPauseState.isPlaying ? _animationController.forward() : _animationController.stop(canceled: false);
});
if (_playPauseState.isPlaying) {
_animationController.forward();
}
}
void _disposeAnimation() {
_animationController.dispose();
_playPauseState.dispose();
}
@override
void initState() {
super.initState();
_initAnimation();
}
@override
void didUpdateWidget(Barrage oldWidget) {
super.didUpdateWidget(oldWidget);
_disposeAnimation();
_initAnimation();
}
@override
void deactivate() {
_disposeAnimation();
super.deactivate();
}
@override
Widget build(BuildContext context) {
return SlideTransition(
position: _offsetAnimation,
child: SizedBox(
width: double.infinity,
child: widget.barrageController.content,
),
);
}
}
当有海量弹幕来袭时,首先需要在播放器上层的Container容器中创造多个弹幕通道,并通过算法调度每一个弹幕该出现在哪个通道,初始化动画,并在移除屏幕后dispose动画并移除该条弹幕的Widget

在此基础上,还需要设置一个时间的随机性,让每一条弹幕动画的飘动时间有一个细微的差异,以此来优化整体弹幕流的视觉效果。关于弹幕调度详细代码可参考此项目core.dart文件。这里便不做详述。
2.2 裁剪蒙版容器
// main.dart (部分代码) --- 初始化时引入配置文件
class Index extends StatefulWidget {
//...
}
class IndexState extends State with WidgetsBindingObserver {
//...
Map cfg;
@override
void initState() {
super.initState();
WidgetsBinding.instance.addObserver(this);
Future loadString = DefaultAssetBundle.of(context).loadString("py/res.json");
loadString.then((String value) {
setState(() {
cfg = json.decode(value);
});
});
}
//...
//...
}
正式环境肯定是从网络http长连接或者socket获取实时数据,由于我们是离线演示DEMO,方便起见需要在初始化时加载刚才后端产出蒙版路径res.json打包到APP中。
// barrage.dart (部分代码) --- 裁剪蒙版容器
class BarrageInit extends StatefulWidget {
final Map cfg;
const BarrageInit({Key key, this.cfg}) : super(key: key);
@override
BarrageInitState createState() => BarrageInitState();
}
class BarrageInitState extends State {
//...
BarrageWallController _controller;
List curMaskData;
//...
@override
Widget build(BuildContext context) {
num scale = MediaQuery.of(context).size.width / widget.cfg['frame_width'];
return ClipPath(
clipper: curMaskData != null ? MaskPath(curMaskData, scale) : null,
child: Container(
color: Colors.transparent,
child: _controller.buildView(),
),
);
}
}
class MaskPath extends CustomClipper {
List curMaskData;
num scale;
MaskPath(this.curMaskData, this.scale);
@override
Path getClip(Size size) {
var path = Path();
curMaskData.forEach((maskEach) {
for (var i = 0; i < maskEach.length; i++) {
if (i == 0) {
path.moveTo(maskEach[i][0] * scale, maskEach[i][1] * scale);
} else {
path.lineTo(maskEach[i][0] * scale, maskEach[i][1] * scale);
}
}
});
return path;
}
@override
bool shouldReclip(CustomClipper oldClipper) {
return true;
}
}
flutter实现蒙版效果的核心就在于CustomClipper类,它允许我们通过Path对象来自定义坐标绘制一个裁剪路径(类似于canvas绘图),我们创建一个MaskPath,并在里面绘制我们刚才加载的配置文件的那一帧,然后通过ClipPath包裹弹幕外层容器,就可以实现一个剪裁蒙版的效果:
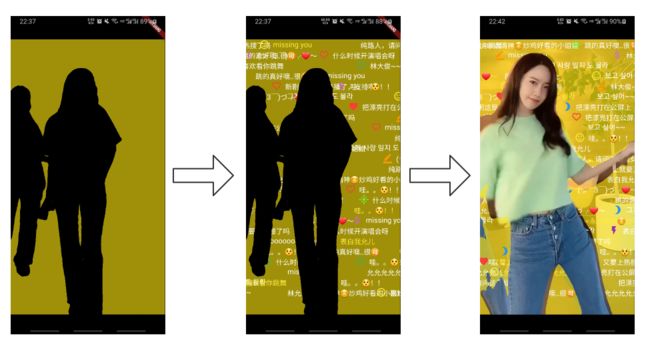
这里加背景色为了看的更清楚,后续我们会把Container背景颜色设置为Colors.transparent
2.3 视频流蒙版同步
首先我们需要引入一个播放器,考虑到IOS和Android插件的稳定性,我们用flutter官方提供的播放器插件video_player
// video.dart (部分代码) --- 监听播放器进度重绘蒙版
class VedioBg extends StatefulWidget {
//...
}
class VedioBgState extends State {
VideoPlayerController _controller;
Future _initializeVideoPlayerFuture;
bool _playing;
num inMilliseconds = 0;
Timer timer;
//...
@override
void initState() {
super.initState();
int cd = widget.cfg['mask_cd'];
_controller = VideoPlayerController.asset('py/source.mp4')
..setLooping(true)
..addListener(() {
final bool isPlaying = _controller.value.isPlaying;
final int nowMilliseconds = _controller.value.position.inMilliseconds;
if ((inMilliseconds == 0 && nowMilliseconds > 0) || nowMilliseconds < inMilliseconds) {
timer?.cancel();
int stepsTime = (nowMilliseconds / cd).round() * cd;
timer = Timer.periodic(Duration(milliseconds: cd), (timer) {
stepsTime += cd;
eventBus.fire(ChangeMaskEvent(stepsTime.toString()));
});
}
inMilliseconds = nowMilliseconds;
_playing = isPlaying;
});
_initializeVideoPlayerFuture = _controller.initialize().then((_) {});
_controller.play();
}
//...
}
在video初始化后,通过addListener开始监听播放进度。当播放进度改变时候,获取当前的进度毫秒,去寻找与当前进度最接近的配置文件中的数据集stepsTime,这个配置的蒙版就是当前播放画面帧的裁剪蒙版,**此时立刻通过eventBus.fire通知蒙版容器用key为stepsTime的数组路径进行重绘。**校准蒙版。
这里实际操作中会遇到两个问题:
- 如何确定当前的进度离哪一帧数据集最近?
- 答:在之前数据准备时,通过计算在配置写入了
mask_cd,这个时间是最初提取关键帧的间隔,有了间隔时长就可以通过计算得到int stepsTime = (nowMilliseconds / mask_cd).round() * mask_cd;
- 播放器的回调是500毫秒改变一次时间进度,但是我们要做到极致体验不能有这么久的延迟,否则不能保证画面和蒙版同步
- 答:在每次触发进度改变时,新起一个
Timer.periodic循环计时器,循环时间就是之前的mask_cd,同时把此刻的进度时间存起来,那么接下来的500毫秒内,即使播放器没有通知我们进度,我们也可以通过不断地累加自行技术,在计时器的回调里调用eventBus.fire通知蒙版重绘校准。切记当视频播放完成并开启循环模式时,要将计时器清除
到这里已经基本实现了一个Flutter AI弹幕播放器啦~
3. 拓展
3.1 Web前端实现
web前端实现要比native实现简单,这里稍微提及一下。服务端处理数据流程是不变的,但是如果只需要对接web前端,就不用将灰度图转换为json配置。这得益于webkit浏览器内核帮我们做了很多工作。 其实对于蒙版弹幕来讲本质上没有区别,因为视频网站不可能吧一整个视频编码为 目前flutter缺少稳定开源的多功能播放器插件,官方的插件只具备基本功能,比如直播流切片就无法支持,一些第三方机构的插件又不一定靠得住,也跟不上flutter版本更新的速度,这是目前整个flutter生态存在的问题,导致了要商用就需要投入大量研发成本去开发native插件。
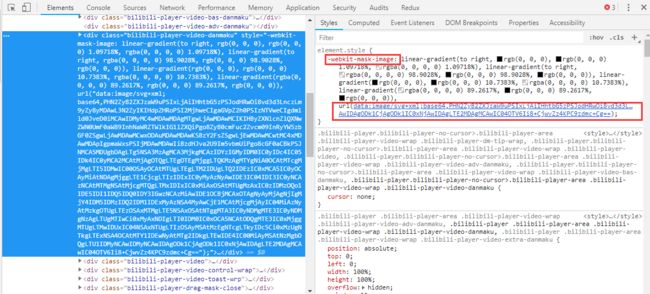
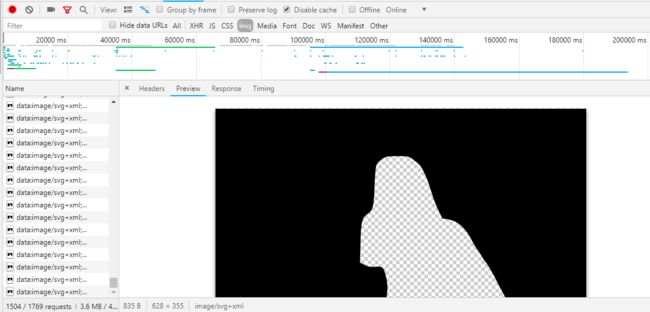
从哔哩哔哩网站中审查元素上就可以看到,在播放器元素上有一层弹幕蒙版-webkit-mask-image的CSS属性,传入我们之前生成的灰度图片,浏览器内部会帮我们挖出一个蒙版,省去了我们自己去计算轮廓的步骤,canvas和svg也有的API可以实现这个效果,但是无疑CSS是最简单的。
3.2 视频点播与直播
mp4格式放给用户,都是通过长连接返回m4s或flv的视频切片给用户,所以直播点播都一样。蒙版弹幕的配置信息,不管是web端的base64图片,还是app需要的坐标点json,都需要跟随视频切片一起编码为二进制流,拉到端内再解码,视频的部分喂给播放器,蒙版信息单独抽出来。这两部分得在一个数据包,如果分开传输,就会造成画面蒙版不同步的问题。
在直播场景中,视频上传到云端需要实时地提取关键帧,进行图像识别分类,最后再编码推给用户端,这个过程需要时间,所以在开启蒙版弹幕的直播间里会出现延迟,这个是正常的。3.3 总结
关于这个AI弹幕播放器DEMO,还有些可优化的细节,比如增加蒙版播放器的进度控制,横竖屏切换,特效弹幕等等。文中代码只引入了部分片段,前后端完整代码请参考:Github仓库:https://github.com/yukilzw/zoe_barrage