PyTorch Resnet实现图像分类
1.数据集
数据集地址:https://www.kaggle.com/slothkong/10-monkey-species
采用kaggle上的猴子数据集,包含两个文件:训练集和验证集。每个文件夹包含10个标记为n0-n9的猴子。图像尺寸为400x300像素或更大,并且为JPEG格式(近1400张图像)。
图片样本
图片类别标签,训练集,验证集划分说明

2.代码
#导入相应的库
import torch
import time
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
import torch.optim as optim
import torch.nn.functional as F
from torch.autograd import Variable
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
#初始化设置
BATCH_SIZE = 8
num_epochs = 10
#设置训练集
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224), #随机裁剪到224x224大小
transforms.RandomHorizontalFlip(), #随机水平翻转
transforms.RandomRotation(degrees=15), #随机旋转
transforms.ToTensor(), #转化成Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) #正则化
])
train_dataset = ImageFolder("../input/10-monkey-species/training/",transform = train_transform) #训练集数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2) #加载数据
#设置测试集
test_transform = transforms.Compose([
transforms.Resize((224, 224)), #resize到224x224大小
transforms.ToTensor(), #转化成Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) #正则化
])
test_dataset = ImageFolder("../input/10-monkey-species/validation/",transform = test_transform) #测试集数据
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=BATCH_SIZE, shuffle=False,num_workers=2) #加载数据
#打印训练集测试集大小
train_data_size = len(train_dataset)
valid_data_size = len(test_dataset)
print(train_data_size,valid_data_size)
#构建Resnet模型
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512*4, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.reshape(out.shape[0],-1)
out = self.fc(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2,2,2,2])
def ResNet34():
return ResNet(BasicBlock, [3,4,6,3])
def ResNet50():
return ResNet(Bottleneck, [3,4,6,3])
def ResNet101():
return ResNet(Bottleneck, [3,4,23,3])
def ResNet152():
return ResNet(Bottleneck, [3,8,36,3])
net = ResNet50().to('cuda:0') #设置为GPU训练
loss_function = nn.CrossEntropyLoss() #设置损失函数
optimizer = optim.Adam(net.parameters(), lr=0.0002) #设置优化器和学习率
#定义训练函数
def train_and_valid(model, loss_function, optimizer, epochs=30):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
history = []
best_acc = 0.0
best_epoch = 0
for epoch in range(epochs):
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch+1, epochs))
model.train()
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
#因为这里梯度是累加的,所以每次记得清零
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()
for j, (inputs, labels) in enumerate(test_loader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_function(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss/train_data_size
avg_train_acc = train_acc/train_data_size
avg_valid_loss = valid_loss/valid_data_size
avg_valid_acc = valid_acc/valid_data_size
#将每一轮的损失值和准确率记录下来
history.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if best_acc < avg_valid_acc:
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
#打印每一轮的损失值和准确率,效果最佳的验证集准确率
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch+1, avg_valid_loss, avg_train_acc*100, avg_valid_loss, avg_valid_acc*100, epoch_end-epoch_start
))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
return history
#开始训练
history = train_and_valid(net, loss_function, optimizer, num_epochs)
#将训练参数用图表示出来
history = np.array(history)
plt.plot(history[:, 0:2])
plt.legend(['Tr Loss', 'Val Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1.1)
#plt.savefig(dataset+'_loss_curve.png')
plt.show()
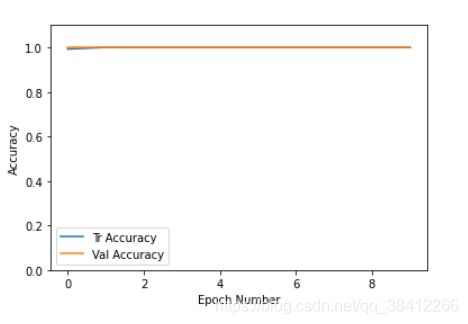
plt.plot(history[:, 2:4])
plt.legend(['Tr Accuracy', 'Val Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1.1)
#plt.savefig(dataset+'_accuracy_curve.png')
plt.show()
3.执行结果
1.训练集测试集大小
1097 272
2.训练过程
Epoch: 1/10
Epoch: 001, Training: Loss: 0.0000, Accuracy: 99.2707%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 92.4534s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 2/10
Epoch: 002, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 93.2498s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 3/10
Epoch: 003, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 92.6632s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 4/10
Epoch: 004, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 92.8753s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 5/10
Epoch: 005, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 93.1554s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 6/10
Epoch: 006, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 93.1266s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 7/10
Epoch: 007, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 92.7661s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 8/10
Epoch: 008, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 92.3729s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 9/10
Epoch: 009, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 93.6452s
Best Accuracy for validation : 1.0000 at epoch 001
Epoch: 10/10
Epoch: 010, Training: Loss: 0.0000, Accuracy: 100.0000%,
Validation: Loss: 0.0000, Accuracy: 100.0000%, Time: 93.0953s
Best Accuracy for validation : 1.0000 at epoch 001
3.损失值曲线

4.准确率曲线