你熟练掌握的STL容器有哪些?(最详细)
文章目录
- 一 vector
- 二 deque
- 三 list
- 四 迭代器拷贝
- 五 vector, list 和 deque之间的区别
-
- 5.1vector
- 5.2deque
- 5.3list
- 六 map
-
- 6.1map
- 6.2multimap
- 6.3unordered_map
- 6.4unordered_multimap
- 七 set 集合
- 八 总结
一 vector
1,vector介绍
vector是STL标准库中的容器,是一个序列式容器,里面的底层实现是一个顺序表结构,可以动态增长长度的数组
2,vector的特性
数据自动初始化为0,可以动态增长长度,支持随机访问数据,对内存边界进行检查
3,vector的使用
(1)头文件
#include
(2)类的原型
template <typename T>
class vector{
vector();
vector(int size);
vector<int size,fill);
};
(3)定义
vector<类型> 变量名
4,vector的初始化的方法
(1)创建了一个动态数组
vector
(2)创建了一个数组长度为10
vector
(3)进行聚合初始化
vector
5,vector中的迭代器
(1)begin 指向首地址(有数据,指向第一个元素)
(2)end 指向结束的地址(指向空数据)
vector
创建一个迭代器对象,指向vector容器中的第一个元素位置
迭代器的头部
vector
输出元素的头部
cout << *itor << endl;
迭代器的尾部
auto end = v.end();
迭代器是一个前闭后开的一个区间 [begin,end)
迭代器的遍历
for (auto it = v.begin(); it != v.end(); it++)
{
cout << (*it) << " ";
}
6,vector 兼容C语言
(1)通过data函数返回C语言指针
vector<int> vec(10);
int *p=vec.data();
(2)通过首地址和尾地址,进行拷贝原来的数组
int arr[10] = {
8, 2, 5, 25, 14, 51, 35, 20, 71, 33 };
vector<int> vec(arr,arr+10);
cout << vec << endl;
7,vector常用的函数
(1)vctor 数据的内存分配
| push_back | 从尾部插入一个数据 |
|---|---|
| pop_back | 从尾部删除一个数据 |
| insert | 从指定的位置插入一个元素 |
| erase | 从指定的位置删除(擦除)一个元素 |
| size | 获取当前大小 |
| resize | 重新调整大小 |
| assign | 重新分配内存空间 |
| capacity | 获取实际的内存空间 |
| clear | 清除所有数据 |
实例
void test()
{
vector<int> vec = {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
cout << vec;
vec.push_back(11);
cout << vec;
vec.pop_back();
cout << vec;
vec.insert(vec.begin() + 6, 66);
cout << vec;
vec.erase(vec.begin() + 2);
cout << vec;
cout << "数组容器当前的长度是:" << vec.size() << endl;
vec.resize(20); //新添加的数据会自动补上0
cout << vec;
cout << "数组容器当前的长度是:" << vec.size() << endl;
//resize数据比原来小会将后面的数据删除
vec.resize(5);
cout << vec;
vec.resize(10);
cout << vec;
cout << "vec的实际内存是:" << vec.capacity() << endl;
vec.assign({
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 });
cout << vec;
vec.assign(10, 6);
cout << vec;
vec.clear();
cout << vec;
}

(2)vector数据的访问操作
| front | 获取头部部元素 |
|---|---|
| back | 获取尾部元素 |
| at | 相当于 [] |
| data | 返回数组指针 |
| begin | 迭代器首地址 |
| end | 迭代器结束地址 |
| rbegin | 反向迭代器 |
| rend | 反向迭代器结束地址 |
实例
void test()
{
vector<int> vec = {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
cout << vec.front() << endl; //获取头部部元素
cout << vec.back() << endl; //获取尾部元素
cout << vec.at(2) << ":" << vec[5] << endl;
for (auto it = vec.begin(); it != vec.end(); it++)
{
cout << (*it) << " ";
}
cout << endl;
for (auto it = vec.rbegin(); it != vec.rend(); it++)
{
cout << (*it) << " ";
}
cout << endl;
}

二 deque
1,deque介绍
双端队列,deque的底层实现是一个链表数组,序列式容器
2,deque的使用
(1)头文件
#include
(2)定义:
deque<数据类型> 变量名;
3,deque的初始化
(1)定义了一个整型的双端队列;
deque
deque
deque
deque与vector类型,都可以进行数据的访问,插入和删除
deque可以进行高效的头部插入和删除数据
(2)从头部添加数据
void push_front();
(3)从头部删除数据
void pop_front();
(4)从头部添加数据
void emplace_front() ;
(5)实例
void test()
{
deque<int> de = {
1, 2, 3, 4, 5, 6, 7, 8, 9, 0 };
cout << de << endl;
de.push_back(30);
cout << de << endl;
de.pop_back();
cout << de << endl;
de.push_front(-1);
cout << de << endl;
de.pop_front();
cout << de << endl;
}

4,deque中的迭代器
(1)begin 指向首地址(有数据,指向第一个元素)
(2)end 指向结束的地址(指向空数据)
(3)rbegin -> rend ,表示的是一个反向跌代器
反向迭代器的头部指向最后一个元素
deque
(4)实例
for (auto r = de.begin(); r != de.end(); r++)
{
cout << (*r) << " ";
}
for (auto r = de.rbegin(); r != de.rend(); r++)
{
cout << (*r) << " ";
}
5, deque特点
deque是双端队列的数据结构,可以在队首高效的添加和删除元素,这是相对于vector的优势。
deque内部采用分段连续的内存空间来存储元素,在插入元素的时候随时都可以重新增加一段新的空间并链接起来,因此虽然提供了随机访问操作,但访问速度和vector相比要慢。
deque并没有data函数,因为deque的元素并没有放在数组中。
deque因为没有固定的内存空间不提供capacity和reserve操作。
6,函数相关
| void begin() | 将迭代器返回到开头(增长方向:begin -> end) |
|---|---|
| void end(); | 将迭代器返回到结尾 |
| void rbegin(); | 返回反向迭代器以反向开始(增长方向:rbegin -> rend) |
| void rend(); | 将反向迭代器返回到反向结束 |
| void cbegin() | 将const_iterator返回到开头与begin类似,区别在于begin指向的值可以改变,cbegin指向的值不可改变 |
| void cend() | 将const_iterator返回到开头末尾 |
| void crbegin() | 返回const_reverse_iterator以反向开始 |
| void crend() | 将const_reverse_iterator返回到反向结束 |
| void swap() | 交换两个容器的内容 |
| void emplace() | 在迭代器位置插入元素 |
| void emplace_front() | 在首部添加一个元素 |
| void emplace_back() | 在尾部添加一个元素 |
实例
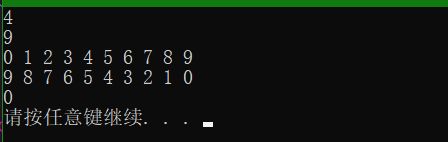
void test3()
{
deque<int> de = {
0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
cout << de[4] << endl;
//反向迭代器的头部指向最后一个元素
deque<int>::reverse_iterator rt = de.rbegin();
cout << (*rt) << endl;
for (auto r = de.begin(); r != de.end(); r++)
{
cout << (*r) << " ";
}
cout << endl;
for (auto r = de.rbegin(); r != de.rend(); r++)
{
cout << (*r) << " ";
}
cout << endl;
deque<int>::const_iterator ct = de.cbegin();
cout << (*ct) << endl;
//常量反向迭代器
deque<int>::const_reverse_iterator crt = de.crbegin();
}
三 list
1,list介绍
list是一个双向链表,序列式容器
2,容器属性
底层实现是一个双向链表
3,list的使用
(1)头文件
#include
(2)定义
list <类型> 变量名
(3)初始化
创建一个list对象
list
可以初始化长度
ist
list
4,特点
list和deque的元素在内存的组织形式不同,以链表的形式保存
list也可以在尾部和头部加入元素,因此也支持push_back和push_front以及pop_front和push_back
list可以高效的在内部插入元素而不需要移动元素
list独有的成员函数remove()可以移除和参数匹配的元素。
list删除数据的时候会马上回收资源
list在多线程的时候相对比较安全
5,相关函数
相比vector新增函数
| void push_front() | 从头部插入数据 |
|---|---|
| void pop_front() | 从尾部插入数据 |
| void remove() | 删除元素值 |
| void unique() | 删除连续重复的数值 |
| void merge() | 归并两个有序链表 |
| void sort() | 调用list内部的排序算法 |
没有at()不能进行内部的随机访问,即不支持[] 操作符和at()
list::iterator 没有 operator+();
list::iterator 没有 operator+=();
capcity(); 不能获取空间长度
resize(); 不能修改长度
实例
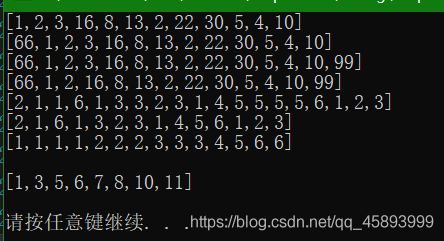
void test6()
{
list<int> l = {
1, 2, 3, 16, 8, 13, 2, 22, 30, 5, 4, 10 };
cout << l;
l.push_front(66);
cout << l;
l.push_back(99);
cout << l;
l.remove(3);
cout << l;
list<int> l2 = {
2, 1, 1, 6, 1, 3, 3, 2, 3, 1, 4, 5, 5, 5, 5, 6, 1, 2, 3 };
cout << l2;
l2.unique(); //只删除连续重复的数据
cout << l2;
l2.sort();
cout << l2 << endl;
list<int> m1 = {
3, 6, 7, 8, 11 };
list<int> m2 = {
1, 5, 10 };
m2.merge(m1);
cout << m2 << endl;
}
归并两个有序链表
两个链表必须是有序的
四 迭代器拷贝
1,普通的容器可以进行迭代器进行拷贝
vector
vector
2,不同的容器之间也可以通过迭代器进行拷贝
(1)声明一个vector容器
vector
(2)将vector的数据拷贝到list容器中
list
(3)将vector的数据拷贝到deque容器中
deque
(4)list和deque可以反向的拷贝给vector使用
3,实例
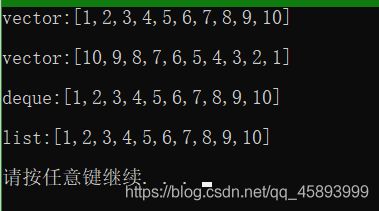
void copy_test()
{
vector<int> vec = {
1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
vector<int> vec2(vec.begin(), vec.end());
vector<int> vec3(vec.rbegin(), vec.rend());
cout <<"vector:"<< vec2 << endl;
cout << "vector:" << vec3 << endl;
deque<int> de(vec.begin(), vec.end());
cout << "deque:" << de << endl;
list<int> l1(vec.begin(), vec.end());
cout << "list:" << l1 << endl;
}
五 vector, list 和 deque之间的区别
5.1vector
特点:数据全部顺序存储,允许直接访问其任何元素,高效的随机访问,快速的从尾部添加(删除)数据,并且可以返回一个C语言指针
底层:是一个地址有序存储的数组,以连续的地址存储
缺点:内部插入数据和删除数据的效率低下,内存大小有限,当该数组后的内存空间不够时,需要重新申请一块足够大的内存并进行内存的拷贝,容量有限
5.2deque
特点:结合了数组和链表的两个特点,既可快速在序列的首尾相对快速进行元素添加(删除),又可以进行随机访问
底层:是一个数组链表,每段数组分段存储在内存中
缺点:访问速度略比vector要慢,从中间插入(删除)数据效率低下
5.3list
特点:高效的进行内部的插入和删除,并能够真正的从内存中销毁数据,数据插入和删除不会影响其他迭代器的访问
底层:是一个双向链表,节点和节点之间进行链接
缺点:不支持随机访问,有一定的额外内存
六 map
6.1map
1,map介绍
map 字典 映射 ,map是一个关系式容器 ,以模板(泛型)方式实现 ,底层通常是由一颗红黑树组成,第一个可以称为键(key),第二个可以称为该键的值(value),在map内部所有的key都是有序的,并且不会有重复的值
2,map的特点
(1)map是一个容器
容器里面存放元素,把这个元素分成两个逻辑区块,第一个称为键(key) ,每个键(key)只能在map中出现一次,并且会进行有序的排列,第二个称为该键值(value),这两个区块当成一个组来进行管理,每一个节点的内容是由一个pair
(2)key和value 的条件
key是唯一的,不重复的,里面的key会自动去除重数据,map会根据key的值自动的进行一个排序,每个key对应着一个value
3,map的使用
map中每个键值对称之为节点
(1)头文件
#include
(2)map的存放的节点容器时一个pair的类
原型
template <typename K,typename V>
class pair{
public:
K first; //key的值
V seconed; //value的值
pair(K& first,V& seconed): first(first),seconed(seconed){
}
}
(3)用法
pair节点通常是通过map返回的一数据类型
pair
pair
pair
make_pair(v1, v2);
4,初始化方式
(1)定义
map<模板1,模板2> 变量名
(2) 定义一个 m 的空对象
map
(3)map聚合初始化方式初始化map
map<string,int> mymap = {
{
"abcd", 0 },
{
"efgh", 1 },
{
"hello", 2},
};
5,插入数据
(1)插入键值对
m.insert(pair
(2)该函数会自动识别类型
m.insert(make_pair(key,value));
(3)c++11 新增加的插入方式
m.insert({ key, value });
6,访问数据
访问和修改键值对
m.at(key);
如果不存在会自动插入一个新的元素进去
m[key]=value;
7,map常见用途
需要建立字符串与整数之间映射关系,通过一个唯一的key来建立存储关系的
8,迭代器操作
map迭代器不能进行+ 和-运算符操作
可以使用 ++ – 运算符进行遍历
9,遍历方式
(1)for循环遍历
for(map<T1,T>::iterator iter=m.begin();iter!=end;iter++){
cout<<iter->first<<":"<<iter->seconed<<endl;
}
(2)foreach遍历
for (auto e:map){
cout<<e.first<<":"<<e.seconed<<endl;
}
10,map的相关函数
| void insert() | 插入元素 |
|---|---|
| void erase(iterator iter) | 删除一个元素,参数是迭代器 ,通过find找到key的迭代器,然后删除 |
| iterator find() | 查找一个元素 通过key的值查找 返回一个迭代器 ,如果没有找到的话会返回 end() |
| Value at() | 通过key访问或修改数据 |
| Value operator [Key k] | 修改数据,访问数据,插入数据 (不会自动创建) |
| iterator begin() | 返回指向map头部的迭代器 |
| iterator end() | 返回指向map末尾的迭代器 |
| reverse_iterator rbegin() | 返回一个指向map尾部的逆向迭代器 |
| reverse_iterator rend() | 返回一个指向map头部的逆向迭代器 |
| int size() | 返回map中元素的个数 |
| long max_size() | 返回可以容纳的最大元素个数 |
| void clear() | 删除所有元素 |
| void count() | 返回指定key出现的次数 map中key只会出现一次,所以只会返回1或者是0 |
| void empty() | 如果map为空则返回true |
| void swap() | 交换两个map |
| void lower_bound() | 返回键值>=给定元素的第一个位置 |
| void upper_bound() | 返回键值>给定元素的第一个位置 |
| void get_allocator() | 返回map的配置器 |
| void equal_range() | 返回特殊条目的迭代器对 |
实例
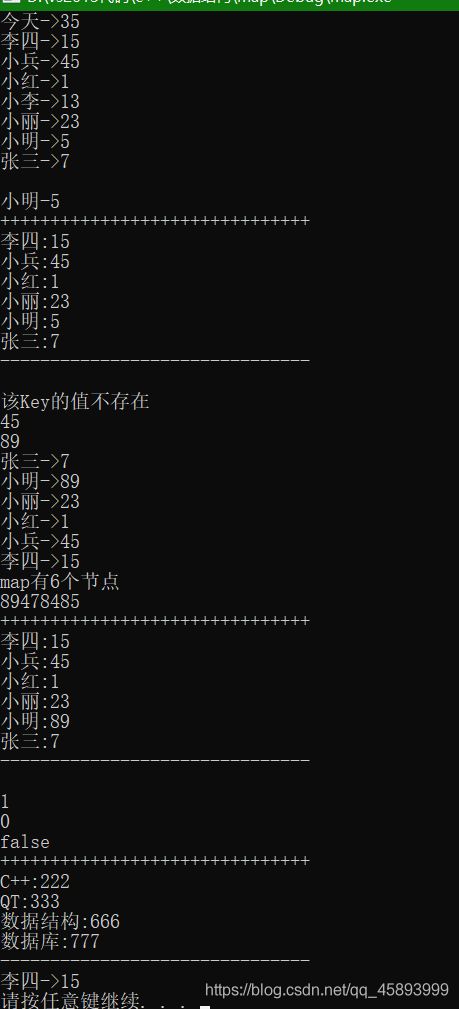
void text()
{
map<string, int> m =
{
{
"小明", 5 },
{
"张三", 7 },
{
"小丽", 23 },
{
"小红", 1 },
{
"李四", 15 },
{
"小兵", 45 },
{
"小明", 21 },
{
"小李", 13 },
};
m.insert({
"今天", 35 });
for (auto it = m.begin(); it != m.end(); it++)
{
cout << it->first << "->" << it->second << endl;
}
cout << endl;
m.erase(m.begin());
auto tmp = m.find("小明");
cout << tmp->first << "-" << tmp->second << endl;
m.erase(m.find("小李"));
cout << m << endl;
auto it = m.find("www");
{
m.erase(it);
}
else
{
cout << "该Key的值不存在" << endl;
}
cout << m.at("小兵") << endl; //访问数据
m.at("小明") = 89; //修改数据
cout << m.at("小明") << endl;
for (auto it = m.rbegin(); it != m.rend(); it++)
{
//迭代器指向的是一个类的话,用 -> 运算符解引用
cout << it->first << "->" << it->second << endl;
}
cout << "map有" << m.size() << "个节点" << endl;
cout << m.max_size() << endl;
cout << m << endl;
cout << m.count("小明") << endl;
cout << m.count("小李") << endl;
m.insert({
"小李", 57 });
cout << boolalpha << m.empty() << endl;
map<string, int> m2 = {
{
"C++", 222 },
{
"QT", 333 },
{
"数据库", 777 },
{
"数据结构", 666 },
};
//交换两个容器内的数据
m2.swap(m);
cout << m;
auto it2 = m2.lower_bound("222");
cout << it2->first << "->" << it2->second << endl;
}
11,map的优缺点
(1)优点:
有序性:map结构的红黑树自身是有序的,不停的插入数据,总是获取到一个有序的数据。时间复杂度低:内部结构时红黑树,红黑树很多操作都是在log(n)的时间复杂度下实现的,因此效率高。
(2)缺点:空间占有率高:因为map内部实现是红黑树,每一个节点都需要额外保存,这样使得每一个节点都占用大量的空间。
6.2multimap
1,多表映射
多表映射的结构与map 相似,但是多表映射可以允许有多个重复的键值
2,特点:,
key的值可以重复
key的值仍然会进行排序
可以用做多个key时使用,由于会排序,所有key的位置都是连续的并排下去
3,头文件
#include
4,在无序映射中不能进行直接的键值操作
不可以直接通过键的值进行访问
int count() 返回指定key出现的次数,multimap中key会出现多次
5,实例
void test()
{
multimap<int, string> mm = {
{
1, "c语言" },
{
2, "C++" },
{
5, "数据结构" },
{
7, "操作系统" },
{
3, "计算机网络" },
{
9, "QT" }
};
mm.insert({
3, "编译原理" });
mm.insert({
6, "数据库" });
mm.insert({
6, "计算机原理" });
int i = 0;
for (auto it = mm.find(6); i < mm.count(6); i++, it++)
{
cout << "[" << it->first << "]" << it->second << endl;
}
mm.erase(mm.find(6));
for (auto p : mm)
{
cout << p.first << ":" << p.second << endl;
}
}

6.3unordered_map
1,无序映射
2,头文件
#include
c++11以下的的版本使用
#include
3,特点:
无序映射的key的值不会进行排序,但是会去除重复的key值
优点:内部结构是哈希表,查找为O(1),效率高.
缺点:哈希表的建立耗费时间。
应用场景:对于频繁查找的问题,用unordered_map更高效.
4,底层:是一个哈希表完成的
unordered_map 函数操作基本上与map的值一致
| void bucket_count() | 回槽(Bucket)数 |
|---|---|
| void bucket_size() | 返回槽大小 |
| void bucket() | 返回元素所在槽的序号 |
| void rehash() | 设置槽数 |
| void reserve() | 请求改变容器容量 |
5,实例
void test()
{
unordered_map<int, string > um = {
{
3, "123" },
{
6, "abc" },
{
1, "456" },
{
2, "789" },
{
3, "hello" },
{
2, "haha" }
};
for (auto p : um)
{
cout << p.first << ":" << p.second << endl;
}
}

6.4unordered_multimap
1,无序多表映射
2,特点
该容器底层是哈希表实现,里面的key既不会去重,也不会排序,用法与unordered_map类似,虽然不会排序,但重复的数据也会排列在一起
3,实例
void test()
{
unordered_multimap<int, int> umm = {
{
1, 0 }, {
0, 1 },
{
-1, 0 },{
1, 0 },
{
0, 1 },{
-1, 0 },
{
999, 234 },{
80, 56 },
};
for (auto p : umm)
{
cout << p.first << ":" << p.second << endl;
}
}
七 set 集合
1,集合内的元素是不重复的 ,类似map中的key元素,但是没有对应的value
2,定义
set<类型> s;
3,相关函数
| s.inert() | 插入元素 |
|---|---|
| s.erase() | 删除元素 |
| s.clear() | 清空集合 |
| s.size() | 集合元素的个数 |
| s.empty() | 判断集合是否为空 |
4,set 对应map 去重排序
set<int> s = {
5, 8, 3, 6, 9, 0, 4, 1, 2, 7, 11, 15, 22, 88};
for (auto e : s)
{
cout << e << " ";
}
cout << endl;

八 总结
学习容器的基本用法,知道容器的特性,容器之间的区别以及在什么情况下该使用哪个容器。我总结了两天半,太累了。
