简介
项目介绍: Adventure Works Cycles 是一家销售自行车及相关零件的公司,通过现有数据监控销售情况,获取最新商品销售趋势及区域分布情况进行可视化展示,为业务决策提供洞察,实现高效经营。
负责内容:1. 根据实际业务需要,使用python+SQL语句对ODS基础层数据聚合加工,提取关键分析指标,并加载到DW汇总层,最终形成三张聚合表(订单日期聚合表、同比数据表和时间地区产品聚合表)。
- 在Linux环境下使用shell命令后台运行脚本,实现BI看板所需三张聚合数据表按逻辑顺序的每日自动更新。
- 使用PowerBI连接MySQL数据库实现Sales Dashboard,包括销售情况、时间趋势、区域分布指标的可视化监控。主要从时间、地区和产品维度,展示订单量、销售额、客单价、销售产品结构和销售预期达成率等关键指标。
可视化看板截图



一、背景介绍
Adventure Works Cycles是基于微软SQL Server中AdventureWorks 示例数据库所构建的虚拟公司,它是一家大型跨国制造公司。该公司向北美,欧洲和亚洲商业市场生产并销售金属和复合材料自行车。尽管其基本业务位于华盛顿州的博塞尔市,拥有290名员工,但几个区域销售团队遍布整个市场。
二、分析目的:
为满足业务团队自主分析,并基于销售情况快速做出决策的需求。要求数据部门和业务部门沟通需求的数据指标,考虑实现数据自动聚合更新并输出可视化看板。
三、分析框架

四、分析过程
1. 数据指标梳理与理解
目的:探索现有数据库包含哪些表和字段,结合业务需求,梳理可分析的指标。
(1) 数据库探索
数据库共有6张表,且主要可以分成三类,一类是ods开头的明细表(订单明细表、每日新增用户表),一类是dw开头的聚合表(时间地区产品聚合表、每日环比表和当日维度表),还有一种dim开头的维度表(日期维度表)。
(2) 数据梳理
根据业务理解并与相关同事沟通了解,对项目会用到的数据表和字段进行梳理,形成数据字典。具体字段内容如下:

(3) 指标体系
分析所需指标:
- 时间维度——年、季度、月、昨日、今日
- 地区维度——区域、省份、城市
- 订单产品维度——订单日期、客户编号、产品类别、产品子类、产品名、产品单价、产品销售数量
- 各类同比(如消费金额、定单量、单均价等)及占比值(如产品类别)
2. 利用python进行底层数据聚合
根据业务需要,接下来对基础层数据聚合加工,提取关键分析指标,形成三张聚合表(订单日期聚合表、同比数据表和新的时间地区产品聚合表)。具体处理逻辑梳理如下:

(1) 订单日期聚合表
从Mysql数据库中获取ods_sales_orders订单明细表并按日期分组聚合,计算每日总金额、订单量和客单价。读取dim_date_df日期维度表,与上表结合,得到dw_order_by_day订单日期聚合表。 部分代码如图:

(2) 同比数据表
从Mysql数据库中获取上一步生成的dw_order_by_day订单日期聚合表,对当日/昨天/当月/当季/当年标签进行判断,计算各时间维度下与去年同期的总金额、订单量和客单价同比数据。得到dw_amount_diff当日维度表,部分代码如图:


(3) 当日时间地区产品聚合表
读取并聚合当日的ods_sales_orders订单明细表、ods_customer每日新增用户表和dim_date_df日期维度表,形成dw_customer_order当日时间地区产品聚合表。部分代码如图:

3. 在Linux服务器上部署代码,让其每日自动更新
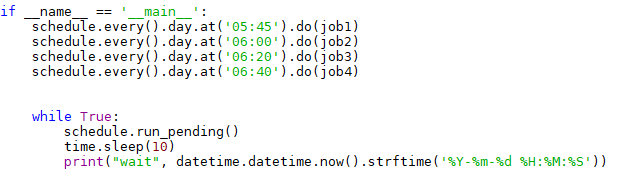
这里使用python的schedule模块实现数据自动更新,部分代码实现如下:
接着,将写好的定时任务脚本传到Linux服务器中,并挂到后台运行。
nohup python3 -u schedule_job_test.py > schedule_job_test.log 2>&1 &
此时定时文件被运行,会返回一个任务ID。
使用以下语句查看新建的任务ID,确定其是否成功在后台运行。
ps aux| grep schedule_job_test.py
查看任务日志。
cat schedule_job_test.log

说明该任务在后台自动运行,并每十秒输出一段日志。
完成以上操作后只要云服务器保持开启状态,后台就会每日自动更新所需表。需要中止后台任务可使用命令——kill 任务ID。
4. 连接Power bi 部署展示
使用Power BI链接新生成的三张聚合表,并通过web发布形成链接。
可视化看板链接
5. 实现hive数据仓库以及处理日常需求
随着数据量增大,使用python进行聚合变的困难起来,为解决大数据场景问题,以下引入hive代替python进行数据聚合。主要流程为使用sqoop抽取数据进入hive数据库,在hive中进行数据聚合,Linux服务器部署自动更新,使用sqoop将更新后数据传输回Mysql。
Sqoop:SQL-to-Hadoop
把关系型数据库的数据导入到 Hadoop 系统 ( 如 HDFS、HBase 和 Hive) 中;把数据从 Hadoop 系统里抽取并导出到关系型数据库里。利用MapReduce 加快数据传输速度。
(1) Sqoop抽取mysql数据到hive
import sqoop
步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
步骤2:Sqoop启动一个Map-Only的MR作业,利用元数据信息并行将数据写入Hadoop。
把dim_date_df日期维度表、ods_customer每日新增用户表和ods_sales_orders订单明细表数据通过sqoop工具迁移到Hive的ods库中。以dim_date_df日期维度表为例编写shell脚本,其他两张表同理:
hive -e "drop table if exists ods.dim_date_df" # 删除hive原有的旧表
sqoop import \
--hive-import \
--connect jdbc:mysql:///主机名:端口/目录名 \
--driver com.mysql.jdbc.Driver \ # Hadoop根目录
--username xxxxx \ #用户名
--password xxxxx \ #密码
--query \ ## 构建表达式执行
"select * from dim_date_df where "'$CONDITIONS'" " \
--fetch-size 50000 \ ## 一次从数据库读取 n 个实例,即n条数据
--hive-table ods.dim_date_df \ ## 创建dim_date_df表
--hive-drop-import-delims \ ## 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符
--delete-target-dir \ ## 如果目标文件已存在就把它删除
--target-dir /user/hadoop/sqoop/dim_date_df \ ## 数据文件被放在了hive的默认/user/hadoop/sqoop/dim_date_df下面
-m 1 ## 迁移过程使用1个map(开启一个线程)

(2) 建立数据仓库,做聚合数据处理
编写Hive SQL,放到shell脚本中运行,这里以聚合生成dw_order_by_day每日环比表为例,同理生成其他两张表。
hive -e "drop table if exists ods.dw_order_by_day"
hive -e "
CREATE TABLE ods.dw_order_by_day(
create_date string,
is_current_year bigint,
is_last_year bigint,
is_yesterday bigint,
is_today bigint,
is_current_month bigint,
is_current_quarter bigint,
sum_amount double,
order_count bigint)
"
hive -e "
with dim_date as
(select create_date,
is_current_year,
is_last_year,
is_yesterday,
is_today,
is_current_month,
is_current_quarter
from ods.dim_date_df),
sum_day as
(select create_date,
sum(unit_price) as sum_amount,
count(customer_key) as order_count
from ods.ods_sales_orders
group by create_date)
insert into ods.dw_order_by_day
select b.create_date,
b.is_current_year,
b.is_last_year,
b.is_yesterday,
b.is_today,
b.is_current_month,
b.is_current_quarter,
a.sum_amount,
a.order_count
from sum_day as a
inner join dim_date as b
on a.create_date=b.create_date
"
(3) Sqoop从hive导出数据到mysql
export sqoop
将数据从Hadoop 导入关系型数据库导中。
步骤1:Sqoop与数据库Server通信,获取数据库表的元数据信息;
步骤2:并行导入数据 :将Hadoop 上文件划分成若干个split.每个split 由一个Map Task 进行数据导入。
编写Hive SQL,放到shell脚本中运行,这里将dw_order_by_day每日环比表的数据抽取回mysql数据库为例,同理生成其他两张表。
sqoop export \
--connect "jdbc:mysql://主机名:端口/目录名" \
--username xxxxx \ ##数据库账号
--password xxxxx \ ##数据库密码
--table dw_order_by_day \
--export-dir /user/hive/warehouse/ods.db/dw_order_by_day \
--input-null-string "\\\\N" \
--input-null-non-string "\\\\N" \
--input-fields-terminated-by "\001" \
--input-lines-terminated-by "\\n" \
-m 1
(4) Linux服务器定时更新部署
linux的定时任务使用crontab文件来实现
1. 编写job_shedule.sh文件,按执行顺序添加文件
sh /home/xxx/sqoop_dim_date_df.sh
sh /home/xxx/sqoop_ods_customer.sh
sh /home/xxx/sqoop_ods_sales_order.sh
sh /home/xxx/create_dw_order_by_day.sh
sh /home/xxx/create_dw_amount_diff.sh
sh /home/xxx/create_dw_customer_order.sh
sh /home/xxx/create_dw_order_by_day.sh
sh /home/xxx/create_dw_amount_diff.sh
sh /home/xxx/create_dw_customer_order.sh
2. 添加定时任务,设定每天早上6点执行
编辑crontab 文件
vi /etc/crontab
添加定时任务:
0 6 * * * sh home/xxx/job_schedule.sh > /dev/null 2>&1 ##避免当程序在指定的时间执行后,系统发一封邮件给当前的用户,显示该程序执行的内容