吴恩达机器学习(十五)—— ex6:Support Vector Machines(MATLAB+Python)
吴恩达机器学习系列内容的学习目录 → \rightarrow →吴恩达机器学习系列内容汇总。
- 一、支持向量机
-
- 1.1 样本数据集1
- 1.2 带有高斯核的SVM
-
- 1.2.1 高斯核
- 1.2.2 样本数据集2
- 1.2.3 样本数据集3
- 二、垃圾邮件分类
-
- 2.1 预处理电子邮件
-
- 2.1.1 预处理电子邮件
- 2.2 从电子邮件中提取特征
- 2.3 训练SVM用于垃圾邮件分类
- 2.4 垃圾邮件的主要预测因素
- 2.5 可选练习:尝试自己的电子邮件
- 2.6 可选练习:构建自己的数据集
- 三、MATLAB实现
-
- 3.1 ex6.m
- 3.2 ex6_spam.m
- 四、Python实现
-
- 4.1 ex6.py
- 4.2 ex6_spam.py
本次练习对应的基础知识总结 → \rightarrow →SVM。
本次练习对应的文档说明和提供的MATLAB代码 → \rightarrow → 提取码:4txu。
本次练习对应的完整代码实现(MATLAB + Python版本) → \rightarrow →Github链接。
一、支持向量机
在前半部分的练习中,我们将使用支持向量机(SVM)处理各种样本2D数据集。使用这些数据集进行实验将帮助我们提高SVM工作的直觉以及如何使用具有SVM的高斯内核。在未来一半的练习中,我们将使用支持向量机来构建垃圾邮件分类器。
提供的脚本ex6.m将帮助我们开始前半部分的练习。
1.1 样本数据集1
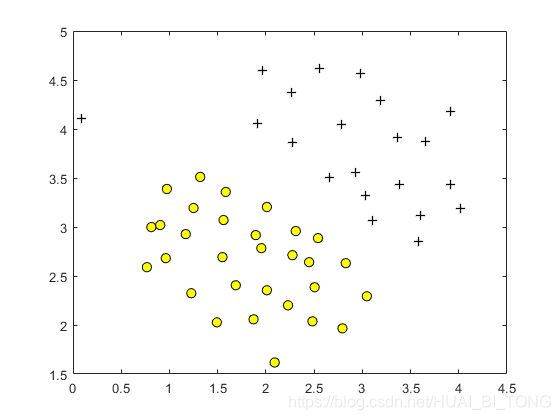
我们将首先使用2D样本数据集,可以由线性边界分隔。脚本ex6.m将绘制训练数据(图1)。在该数据集中,正样本(用+)和负样本(用o)位置的差距建议自然分离。但请注意,左侧大约(0.1,4.1)处有一个异常的正样本+。作为本练习的一部分,我们还将看到该异常值如何影响SVM决策边界。
在这部分练习中,我们将尝试使用不同值的 C C C参数用于SVM。非正式地, C C C参数是控制错误分类训练样本的惩罚的正值。一个较大的 C C C参数告诉SVM尝试正确对所有样本进行分类。 C C C类似于 1 / λ 1/λ 1/λ的角色,其中 λ λ λ是我们以前用于Logistic回归的正则化参数。
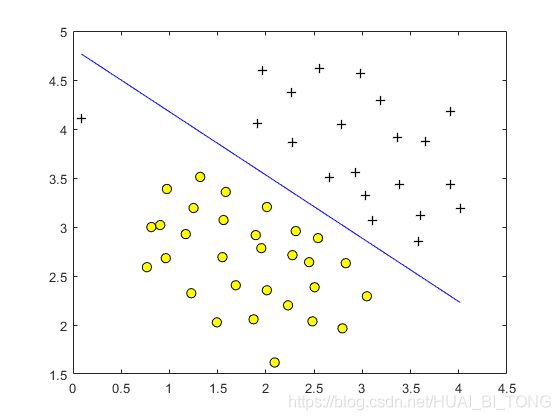
ex6.m的下一部分将使用我们已包含的SVM软件训练SVM(使用 C = 1 C = 1 C=1),我们已经包含在开始代码中,svmTrain.m。当 C = 1 C = 1 C=1时,我们应该发现SVM放置决策边界在两个数据集之间的间隙中,并将左侧的数据点误分类(图2)。
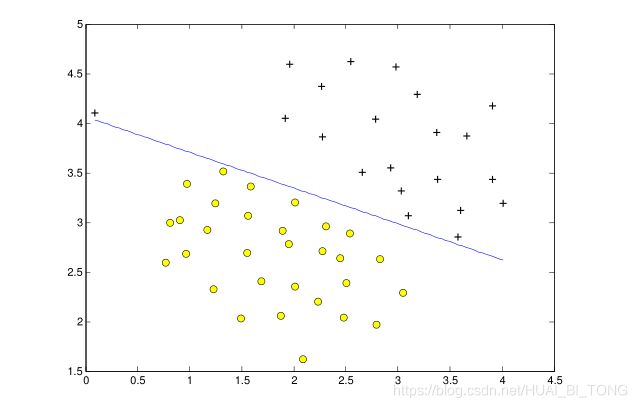
我们的任务是在此数据集中尝试不同的 C C C值。具体来说,我们应该将脚本中的 C C C值更改为 C = 100 C = 100 C=100并再次训练SVM。当 C = 100 C = 100 C=100时,我们可以发现SVM对每个单一样本进行正确分类,但似乎有一条不是自然拟合数据的决策边界(图3)。
1.2 带有高斯核的SVM
在这部分练习中,我们将使用SVM进行非线性分类。特别是,我们将在线性不可分的数据集中使用带有高斯核的SVM。
1.2.1 高斯核
找到SVM的非线性决策边界,我们需要首先实现高斯核函数。我们可以将高斯核函数视为一个相似性函数,以测量一对样本 ( x ( i ) , x ( j ) ) (x(i),x(j)) (x(i),x(j))之间的“距离”。高斯核也由带宽参数 σ σ σ参数化,该参数决定了当样本进一步分开时,相似度度量减少(到0)的速度。
我们现在应该在gaussiankernel.m中完成代码,以计算两个样本 ( x ( i ) , x ( j ) ) (x(i),x(j)) (x(i),x(j))之间的高斯核。高斯核函数的定义如下: k g a u s s i a n ( x ( i ) , x ( j ) ) = e x p ( − ∥ x ( i ) − x ( j ) ∥ 2 2 σ 2 ) = e x p ( − ∑ k = 1 n ( x k ( i ) − x k ( j ) ) 2 2 σ 2 ) k_{gaussian}\left ( x^{(i)},x^{(j)} \right )=exp\left ( -\frac{\left \| x^{(i)}-x^{(j)} \right \|^{2}}{2\sigma ^{2}} \right )=exp\left ( - \frac{\sum_{k=1}^{n} \left ( x^{(i)}_{k} -x^{(j)}_{k}\right )^{2}}{2\sigma ^{2}}\right ) kgaussian(x(i),x(j))=exp(−2σ2∥∥x(i)−x(j)∥∥2)=exp⎝⎜⎛−2σ2∑k=1n(xk(i)−xk(j))2⎠⎟⎞
完成gaussiankernel.m需要填写以下代码:
sim = exp(-(x1 - x2)' * (x1 - x2) / (2 * sigma ^2));
完成函数gaussiankernel.m后,脚本ex6.m将在两个提供的样本上测试核函数,我们应该期望看到的结果为0.324652。
Evaluating the Gaussian Kernel ...
Gaussian Kernel between x1 = [1; 2; 1], x2 = [0; 4; -1], sigma = 2.000000 :
0.324652
(for sigma = 2, this value should be about 0.324652)
1.2.2 样本数据集2
ex6.m中的下一部分将加载和绘制数据集2(图4)。从该图中,我们可以观察到不存在可以将该数据集的正样本和负样本分开的线性决策边界。但是,通过使用具有高斯核的SVM,我们将能够学习一个非线性决策边界,该边界可以合理地为数据集进行划分。

如果我们已正确实现高斯核函数,则ex6.m将继续使用此数据集上的高斯核训练SVM。
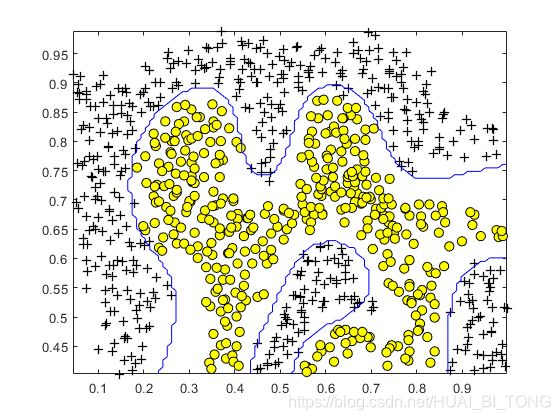
图5显示了通过带有高斯核的SVM找到的决策边界。决策边界能够正确地分离大多数正样本和否样本,并很好地跟随数据集的轮廓。
1.2.3 样本数据集3
在这部分练习中,我们将获得更实用的技能,了解如何使用带有高斯核的SVM。 ex6.m的下一部分将加载并显示第三个数据集(图6)。我们将在此数据集上使用带有高斯核的SVM。
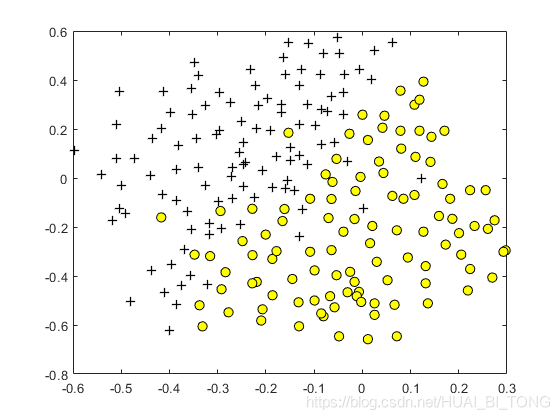
在提供的数据集ex6data3.mat中,我们将获得变量 X X X, y y y, X v a l Xval Xval, y v a l yval yval。 ex6.m中提供的代码使用从dataset3Params.m加载的参数和数据集 ( X , y ) (X,y) (X,y)来训练SVM分类器。
我们的任务是使用交叉验证集 X v a l Xval Xval, y v a l yval yval来确定要使用的最佳参数 C C C和 σ σ σ。我们应该编写帮助我们搜索参数 C C C和 σ σ σ所需的任何其他代码。对于 C C C和 σ σ σ,建议以乘法步尝试值(例如,0.01, 0.03, 0.1, 0.3, 1, 3, 10, 30)。请注意,我们应该尝试 C C C和 σ σ σ(例如, C = 0.3 C = 0.3 C=0.3和 σ = 0.1 σ= 0.1 σ=0.1)所有可能的一对值。例如,如果我们给 C C C和 σ 2 σ^{2} σ2尝试上面列出的8个值,则最终将训练和评估(在交叉验证集上)共 8 2 = 64 8^{2}= 64 82=64个不同的模型。
在确定要使用的最佳参数 C C C和 σ σ σ后,我们应该在dataset3Params.m中修改代码,找到最佳参数。对于我们的最佳参数,SVM返回了图7所示的决策边界。

完成dataset3Params.m需要填写以下代码:
C_vec = [0.01 0.03 0.1 0.3 1 3 10 30]';
sigma_vec = [0.01 0.03 0.1 0.3 1 3 10 30]';
error_val = zeros(length(C_vec),length(sigma_vec));
error_train = zeros(length(C_vec),length(sigma_vec));
for i = 1:length(C_vec)
for j = 1:length(sigma_vec)
model= svmTrain(X, y, C_vec(i), @(x1, x2) gaussianKernel(x1, x2, sigma_vec(j)));
predictions = svmPredict(model, Xval); %svmPredict()使用经过训练的支持向量机模型返回预测向量
error_val(i,j) = mean(double(predictions ~= yval));
end
end
% figure
% error_val
% surf(C_vec,sigma_vec,error_val) % 画出三维图找最低点
[minval,ind] = min(error_val(:)); % 0.03 %[minval,ind] = min():minval表示最小值,ind表示最小值的位置
[I,J] = ind2sub([size(error_val,1) size(error_val,2)],ind);%ind2sub()把数组或者矩阵的线性索引转化为相应的下标,返回i,j,也就是返回的行标和列标
C = C_vec(I) % 1
sigma = sigma_vec(J) % 0.100
% [I,J]=find(error_val == min(error_val(:)) ); % 另一种方式找最小元素位子
% C = C_vec(I) % 1
% sigma = sigma_vec(J) % 0.100
二、垃圾邮件分类
现如今,许多电子邮件服务提供垃圾邮件过滤器,可以将电子邮件分类为垃圾邮件和非垃圾邮件的高精度。在本部分练习中,我们将使用SVM来构建我们自己的垃圾邮件过滤器。
我们将训练一个分类器以分类给定电子邮件 x x x是否是垃圾邮件( y = 1 y = 1 y=1)或非垃圾邮件( y = 0 y = 0 y=0)。特别是,我们需要将每封电子邮件转换为特征向量 x ∈ R n x∈R^{n} x∈Rn。练习中的以下部分将通过电子邮件构建此类特征向量。
在此练习的其余部分,我们将使用脚本ex6_spam.m。此练习中包含的数据集基于SpamAssassin Public Corpus的一个子集。为了本练习的目的,我们只能使用电子邮件的正文(不包括电子邮件标题)。
2.1 预处理电子邮件
从机器学习任务开始,查看数据集中的样本通常是很有见地的。图8显示了包含URL、电子邮件地址(最后)、数字和美元金额的电子邮件示例。虽然许多电子邮件将包含类似类型的实体(例如,数字、其他URL或其他电子邮件地址),但特定实体(例如,特定的URL或特定的美元金额)几乎每封电子邮件都不同。因此,在处理电子邮件中经常使用的方法是“规范化”这些值,以便所有URL都相同处理,所有数字都相同处理等。例如,我们可以用唯一的字符串“httpaddr”替换电子邮件中的每个URL,以指示存在URL。这样做的效果是让垃圾邮件分类器根据是否存在任何URL而不是特定URL来做出分类决策。这通常会提高垃圾邮件分类器的性能,因为垃圾邮件发送者经常随机化URL,因此在新的垃圾邮件中再次看到任何特定URL的几率非常小。
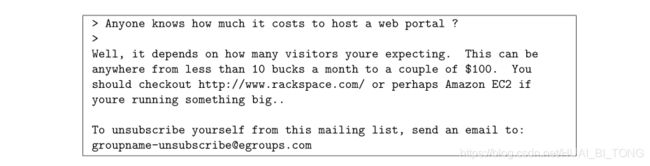
在processEmail.m中,我们已经实现了以下电子邮件预处理和归一化步骤:
- 小写(Lower-casing): 整个电子邮件转换为小写,以便忽略大小写(例如,IndIcaTE与Indicate相同)。
- 删除HTML(Stripping HTML): 从电子邮件中删除所有HTML标记。许多电子邮件通常会带来HTML格式化;我们删除所有HTML标记,以至于只有内容仍然存在。
- 归一化URL(Normalizing URLs): 所有URL都替换为文本“httpaddr”。
- 归一化电子邮件地址(Normalizing Email Addresses): 所有电子邮件地址都替换为文本“emailaddr”。
- 归一化数字(Normalizing Numbers): 所有数字都替换为文本“number”。
- 归一化美元(Normalizing Dollars): 所有美元符号($)替换为文本“dollar”。
- 词干提取(Word Stemming): 单词减少为它们的词干形式。例如,“discount”、 “discounts”、“discounted” 和 “discounting”全部用“discount”代替。有时,词干实际上从末尾脱离额外的字符,所以“include”、“includes”、 “included”
和 “including” 都替换为“includ”。 - 删除非单词(Removal of non-words): 非单词和标点符号已被删除。所有白色空间(标签,换行符,空格)都已减少到单个空间字符。
这些预处理步骤的结果如图9所示。在预处理具有左词碎片和非单词的同时,该形式将更容易使用以进行特征提取。

2.1.1 预处理电子邮件
在预处理电子邮件后,我们有一份单词列表(如图9)为每封电子邮件。下一步是选择我们要在我们的分类器中使用的单词以及我们想要省略的单词。
对于这项练习,我们只选择了最常见的单词作为我们考虑的一组词(词汇表)。由于很少出现在训练集中的单词只在几封电子邮件中,因此它们可能会导致模型过度拟合我们的训练集。完整的词汇表列表在文本vocab.txt中,也显示在图10中。我们通过选择垃圾邮件语料库中至少发生100次的所有单词来选择我们的词汇列表,从而产生1899个单词的列表。在实践中,通常使用大约10,000到50,000字的词汇表。

给定词汇表,现在我们可以将预处理电子邮件(如图9)中的每个单词映射到一个单词索引列表中,该列表包含词汇列表中单词的索引。图11显示了示例电子邮件的映射。具体而言,在示例电子邮件中,“anyone”单词首先归一化为“anyon”,然后在词汇表中映射到索引86。

我们的任务现在是在processEmail.m中完成代码以执行此映射。在代码中,我们将获得一个字符串str,它是预处理电子邮件中的单个单词。我们应该在词汇表vocabList中查找单词,并找到此单词是否存在于词汇表中。如果单词存在,则应将单词的索引添加到word indices变量中。如果单词不存在,因此不在词汇表中,可以跳过这个词。
完成processEmail.m需要填写以下代码:
for i=1:length(vocabList)
if( strcmp(vocabList{i}, str) )%strcmp(s1,s1)是用于做字符串比较的函数,如果s1和s1是一致的,则返回1,否则返回0
word_indices = [word_indices;i];%将所有索引的值存入word_indices
end
end
一旦实现了processEmail.m,脚本ex6_spam.m将在电子邮件示例上运行代码,并且我们应该看到类似于图9和11的输出。

2.2 从电子邮件中提取特征
我们现在将实现将每封电子邮件转换为 R n R^{n} Rn向量的特征提取。对于此练习,我们将在词汇表中使用 n = ≠ n = \neq n==单词。具体地,用于电子邮件的特征 x i ∈ { 0 , 1 } x_{i}∈\left \{ 0, 1 \right \} xi∈{ 0,1}对应于字典中的第 i i i个单词是否在电子邮件中。也就是说,如果第 i i i个单词在电子邮件中 x i = 1 x_{i}=1 xi=1,如果第 i i i个单词不在电子邮件中 x i = 0 x_{i}=0 xi=0。
因此,对于典型的电子邮件,其特征为:
x = [ 0 ⋮ 1 0 ⋮ 1 0 ⋮ 0 ] ∈ R n x=\begin{bmatrix} 0\\ \vdots \\ 1 \\ 0 \\ \vdots \\ 1 \\ 0 \\ \vdots \\ 0 \end{bmatrix}\in R^{n} x=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡0⋮10⋮10⋮0⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤∈Rn
给定word indices,我们现在应该完成代码emailFeatures.m来为每封电子邮件生成一个特征向量。
完成emailFeatures.m需要填写以下代码:
for i = 1:length(word_indices)
x(word_indices(i)) = 1;
end
一旦实现了emailFeatures.m,ex6_spam.m的下一部分就会在电子邮件示例上运行代码。我们应该看到特征向量的长度为1899,具有45个非零条目。
Length of feature vector: 1899
Number of non-zero entries: 45
2.3 训练SVM用于垃圾邮件分类
完成了特征提取函数后,ex6_spam.m的下一步将加载预处理的训练数据集,用于训练SVM分类器。spamTrain.mat包含4000个垃圾邮件和非垃圾邮件的训练样本,而spamTest.mat包含1000个测试样本。每封原始电子邮件都是使用 processEmail 和emailFeatures函数处理的,并转换为向量 x i ∈ R 1899 x_{i}∈R^{1899} xi∈R1899。
加载数据集后,ex6_spam.m将继续训练SVM以在垃圾邮件 ( y = 1 ) (y = 1) (y=1)和非垃圾邮件 ( y = 0 ) (y = 0) (y=0)之间进行分类。一旦训练完成,我们应该看到分类器获得约99.8%的训练精度,约98.5%的测试精度。
Training Accuracy: 99.825000
Test Accuracy: 99.000000
2.4 垃圾邮件的主要预测因素

为了更好地了解垃圾邮件分类器是如何工作的,我们可以检查参数,以查看分类器认为哪些词最能预测垃圾邮件。ex6_spam.m的下一步是在分类器中找到具有最大正值的参数,并显示相应的单词(图12)。因此,如果电子邮件包含单词,例如“guarantee”,“remove”,“dollar”和“price”(图12所示的主要预测因素),则可能被归类为垃圾邮件。

2.5 可选练习:尝试自己的电子邮件
我们现在已经训练了垃圾邮件分类器,可以开始在自己的电子邮件上尝试。在开始代码中,我们包含了两封电子邮件示例(emailSample1.txt 和 emailSample2.txt)和两封垃圾邮件示例(spamSample1.txt 和 spamSample2.txt)。 ex6_spam.m的最后一部分在第一个垃圾邮件样本上运行垃圾邮件分类器,并使用学习的SVM对其进行分类。现在我们应该尝试我们提供的其他示例,看看分类器是否正确。也可以用自己的电子邮件替换示例(纯文本文件)来尝试自己的电子邮件。
电子邮件示例emailSample1.txt的分类结果:
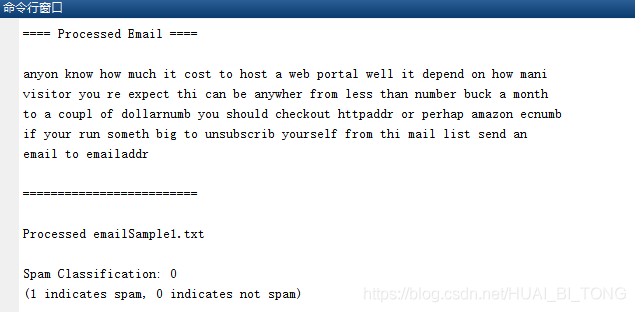
电子邮件示例spamSample1.txt的分类结果:

2.6 可选练习:构建自己的数据集
在本练习中,我们提供了一个预处理的训练集和测试集。使用现在已完成的相同函数(processEmail.m 和 emailFeatures.m)创建这些数据集。对于此可选练习,我们将使用 SpamAssassin Public Corpus语料库中的原始电子邮件构建自己的数据集。
我们在此可选练习中的任务是从公共语料库下载原始文件并提取它们。提取后,我们应该在每封电子邮件上运行processEmail和emailFeatures函数,以从每封电子邮件中提取一个特征向量。这将允许我们构建一个样本 X , y X,y X,y的数据集。然后,将数据集随机分为训练集、交叉验证集和测试集。
在构建自己的数据集时,我们可以尝试构建自己的词汇表(通过选择数据集中发生的高频字)并添加我们认为可能有用的任何其他函数。最后,还可以尝试使用高度优化的SVM工具箱,例如 LIBSVM。
三、MATLAB实现
3.1 ex6.m
%% Machine Learning Online Class
% Exercise 6 | Support Vector Machines
%
% Instructions
% ------------
%
% This file contains code that helps you get started on the
% exercise. You will need to complete the following functions:
%
% gaussianKernel.m
% dataset3Params.m
% processEmail.m
% emailFeatures.m
%
% For this exercise, you will not need to change any code in this file,
% or any other files other than those mentioned above.
%
%% Initialization
clear ; close all; clc
%% =============== Part 1: Loading and Visualizing Data ================
% We start the exercise by first loading and visualizing the dataset.
% The following code will load the dataset into your environment and plot
% the data.
%
fprintf('Loading and Visualizing Data ...\n')
% Load from ex6data1:
% You will have X, y in your environment
load('ex6data1.mat');
% Plot training data
plotData(X, y);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ==================== Part 2: Training Linear SVM ====================
% The following code will train a linear SVM on the dataset and plot the
% decision boundary learned.
%
% Load from ex6data1:
% You will have X, y in your environment
load('ex6data1.mat');
fprintf('\nTraining Linear SVM ...\n')
% You should try to change the C value below and see how the decision
% boundary varies (e.g., try C = 1000)
C = 1;
model = svmTrain(X, y, C, @linearKernel, 1e-3, 20);%svmTrain()训练支持向量机分类器并返回训练模型;linearKernel()返回x1和x2之间的线性核函数
visualizeBoundaryLinear(X, y, model);%visualizeBoundaryLinear()绘制由支持向量机学习的线性决策边界
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =============== Part 3: Implementing Gaussian Kernel ===============
% You will now implement the Gaussian kernel to use
% with the SVM. You should complete the code in gaussianKernel.m
%
fprintf('\nEvaluating the Gaussian Kernel ...\n')
x1 = [1 2 1]; x2 = [0 4 -1]; sigma = 2;
sim = gaussianKernel(x1, x2, sigma);%gaussianKernel()returns a gaussian kernel between x1 and x2
fprintf(['Gaussian Kernel between x1 = [1; 2; 1], x2 = [0; 4; -1], sigma = %f :' ...
'\n\t%f\n(for sigma = 2, this value should be about 0.324652)\n'], sigma, sim);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =============== Part 4: Visualizing Dataset 2 ================
% The following code will load the next dataset into your environment and
% plot the data.
%
fprintf('Loading and Visualizing Data ...\n')
% Load from ex6data2:
% You will have X, y in your environment
load('ex6data2.mat');
% Plot training data
plotData(X, y);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ========== Part 5: Training SVM with RBF Kernel (Dataset 2) ==========
% After you have implemented the kernel, we can now use it to train the
% SVM classifier.
%
fprintf('\nTraining SVM with RBF Kernel (this may take 1 to 2 minutes) ...\n');
% Load from ex6data2:
% You will have X, y in your environment
load('ex6data2.mat');
% SVM Parameters
C = 1; sigma = 0.1;
% We set the tolerance and max_passes lower here so that the code will run
% faster. However, in practice, you will want to run the training to
% convergence.
model= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma));
visualizeBoundary(X, y, model);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =============== Part 6: Visualizing Dataset 3 ================
% The following code will load the next dataset into your environment and
% plot the data.
%
fprintf('Loading and Visualizing Data ...\n')
% Load from ex6data3:
% You will have X, y in your environment
load('ex6data3.mat');
% Plot training data
plotData(X, y);
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ========== Part 7: Training SVM with RBF Kernel (Dataset 3) ==========
% This is a different dataset that you can use to experiment with. Try
% different values of C and sigma here.
%
% Load from ex6data3:
% You will have X, y in your environment
load('ex6data3.mat');
% Try different SVM Parameters here
[C, sigma] = dataset3Params(X, y, Xval, yval);%dataset3Params()返回在练习的第3部分中选择的C和sigma(带有RBF核的支持向量机的最佳学习参数)
% Train the SVM
model= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma));
visualizeBoundary(X, y, model);
3.2 ex6_spam.m
%% Machine Learning Online Class
% Exercise 6 | Spam Classification with SVMs
%
% Instructions
% ------------
%
% This file contains code that helps you get started on the
% exercise. You will need to complete the following functions:
%
% gaussianKernel.m
% dataset3Params.m
% processEmail.m
% emailFeatures.m
%
% For this exercise, you will not need to change any code in this file,
% or any other files other than those mentioned above.
%
%% Initialization
clear ; close all; clc
%% ==================== Part 1: Email Preprocessing ====================
% To use an SVM to classify emails into Spam v.s. Non-Spam, you first need
% to convert each email into a vector of features. In this part, you will
% implement the preprocessing steps for each email. You should
% complete the code in processEmail.m to produce a word indices vector
% for a given email.
fprintf('\nPreprocessing sample email (emailSample1.txt)\n');
% Extract Features
file_contents = readFile('emailSample1.txt');%readFile()读取文件并返回其全部内容
word_indices = processEmail(file_contents);%processEmail()预处理电子邮件正文并返回单词索引列表
% Print Stats
fprintf('Word Indices: \n');
fprintf(' %d', word_indices);
fprintf('\n\n');
fprintf('Program paused. Press enter to continue.\n');
pause;
%% ==================== Part 2: Feature Extraction ====================
% Now, you will convert each email into a vector of features in R^n.
% You should complete the code in emailFeatures.m to produce a feature
% vector for a given email.
fprintf('\nExtracting features from sample email (emailSample1.txt)\n');
% Extract Features
file_contents = readFile('emailSample1.txt');
word_indices = processEmail(file_contents);
features = emailFeatures(word_indices);%emailFeatures()接受单词索引向量并从单词索引生成特征向量
% Print Stats
fprintf('Length of feature vector: %d\n', length(features));
fprintf('Number of non-zero entries: %d\n', sum(features > 0));
fprintf('Program paused. Press enter to continue.\n');
pause;
%% =========== Part 3: Train Linear SVM for Spam Classification ========
% In this section, you will train a linear classifier to determine if an
% email is Spam or Not-Spam.
% Load the Spam Email dataset
% You will have X, y in your environment
load('spamTrain.mat');
fprintf('\nTraining Linear SVM (Spam Classification)\n')
fprintf('(this may take 1 to 2 minutes) ...\n')
C = 0.1;
model = svmTrain(X, y, C, @linearKernel);%svmTrain()训练支持向量机分类器并返回训练模型;linearKernel()返回x1和x2之间的线性核函数
p = svmPredict(model, X);%使用经过训练的SVM模型(svmTrain)返回预测向量
fprintf('Training Accuracy: %f\n', mean(double(p == y)) * 100);
%% =================== Part 4: Test Spam Classification ================
% After training the classifier, we can evaluate it on a test set. We have
% included a test set in spamTest.mat
% Load the test dataset
% You will have Xtest, ytest in your environment
load('spamTest.mat');
fprintf('\nEvaluating the trained Linear SVM on a test set ...\n')
p = svmPredict(model, Xtest);
fprintf('Test Accuracy: %f\n', mean(double(p == ytest)) * 100);
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% ================= Part 5: Top Predictors of Spam ====================
% Since the model we are training is a linear SVM, we can inspect the
% weights learned by the model to understand better how it is determining
% whether an email is spam or not. The following code finds the words with
% the highest weights in the classifier. Informally, the classifier
% 'thinks' that these words are the most likely indicators of spam.
%
% Sort the weights and obtin the vocabulary list
[weight, idx] = sort(model.w, 'descend');%mode为'descend'时,进行降序排序,weight是排序好的向量,idx是向量weight中对model.w的索引
vocabList = getVocabList();
fprintf('\nTop predictors of spam: \n');
for i = 1:15
fprintf(' %-15s (%f) \n', vocabList{idx(i)}, weight(i));
end
fprintf('\n\n');
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
%% =================== Part 6: Try Your Own Emails =====================
% Now that you've trained the spam classifier, you can use it on your own
% emails! In the starter code, we have included spamSample1.txt,
% spamSample2.txt, emailSample1.txt and emailSample2.txt as examples.
% The following code reads in one of these emails and then uses your
% learned SVM classifier to determine whether the email is Spam or
% Not Spam
% Set the file to be read in (change this to spamSample2.txt,
% emailSample1.txt or emailSample2.txt to see different predictions on
% different emails types). Try your own emails as well!
filename = 'emailSample1.txt';
% filename = 'emailSample2.txt';
% Read and predict
file_contents = readFile(filename);
word_indices = processEmail(file_contents);
x = emailFeatures(word_indices);
p = svmPredict(model, x);
fprintf('\nProcessed %s\n\nSpam Classification: %d\n', filename, p);
fprintf('(1 indicates spam, 0 indicates not spam)\n\n');
四、Python实现
4.1 ex6.py
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
from sklearn import svm#导入svm的svc类(支持向量分类)
# =============== Part 1: Loading and Visualizing Data ================
# 数据可视化
def plotData(x, y):
pos = np.where(y == 1)
neg = np.where(y == 0)
plt.plot(x[pos, 0], x[pos, 1], 'k+', lw=1, ms=7)
plt.plot(x[neg, 0], x[neg, 1], 'ko', mfc='y', ms=7)
print('Loading and Visualizing Data ...')
datainfo = sio.loadmat('ex6data1.mat')
X = datainfo['X']#提取原始输入特征矩阵
Y = datainfo['y'][:, 0]#[:, 0]返回第一列,提取标签 并转换为1维数组
plotData(X, Y)
plt.show()
_ = input('Press [Enter] to continue.')
# ==================== Part 2: Training Linear SVM ====================
# 线性可视化
def visualBoundaryLinear(x, y, theta, b):
xp = np.linspace(np.min(x[:, 0]), np.max(x[:, 0]), 100)
yp = -(theta[0]*xp+b)/theta[1]
plotData(x, y)
plt.plot(xp, yp, '-b')
print('Training Linear SVM ...')
c = 1.0
clf = svm.SVC(C=c, kernel='linear')#clf = SVC()创建分类器对象,线性核函数kernel=‘linear’
clf.fit(X, Y)#用训练数据拟合分类器模型
theta = clf.coef_.flatten()#取出权重矩阵,有两个值,分别是w0和w1,klearn中对超平面的表示并不是y=kx+b这样的,而是x作为第一个特征x0,y作为另一个特征x1,表示为:w0x0+w1x1+bias=0
b = clf.intercept_ #取出截距,使用clf.intercept_即可获取bias的值,画超平面y=-(w0/w1)x-bias/w1=-(w0*x+bias)/w1
visualBoundaryLinear(X, Y, theta, b)
plt.show()
_ = input('Press [Enter] to continue.')
# =============== Part 3: Implementing Gaussian Kernel ===============
# 高斯核
def gaussianKernel(x1, x2, sigma):
sim = np.exp(-(x1-x2).dot(x1-x2)/(2*sigma**2))
return sim
print('Evaluating the Gaussian Kernel ...')
x1 = np.array([1, 2, 1])
x2 = np.array([0, 4, -1])
sigma = 2
sim = gaussianKernel(x1, x2, sigma)
print('Gaussian Kernel between x1 = [1; 2; 1], x2 = [0; 4; -1], sigma = 0.5 :\
\t%f\n(this value should be about 0.324652)' % sim)
_ = input('Press [Enter] to continue.')
# =============== Part 4: Visualizing Dataset 2 ================
print('Loading and Visualizing Data ...')
datainfo = sio.loadmat('ex6data2.mat')
X = datainfo['X']
Y = datainfo['y'][:, 0]
plotData(X, Y)
plt.show()
_ = input('Press [Enter] to continue.')
# ========== Part 5: Training SVM with RBF Kernel (Dataset 2) ==========
# 绘制边界
def visualBoundary(x, y, model):
plotData(x, y)
x1plot = np.linspace(np.min(x[:, 0]), np.max(x[:, 0]), 100)
x2plot = np.linspace(np.min(x[:, 1]), np.max(x[:, 1]), 100)
x1, x2 = np.meshgrid(x1plot, x2plot)
vals = np.zeros(np.shape(x1))
for i in range(np.size(x1, 1)):
this_x = np.vstack((x1[:, i], x2[:, i])).T
vals[:, i] = model.predict(this_x)
plt.contour(x1, x2, vals)#等高线图 将0/1分界线(决策边界)画出来5);
# 这里需要注意的是gamma并不是原本中的sigma
print('Training SVM with RBF Kernel (this may take 1 to 2 minutes) ...')
c = 1; sigma = 0.1
gam = 1/(2*sigma**2)#gam=1/2sigma^2
clf = svm.SVC(kernel='rbf', C=1.0, gamma=gam)#RBF函数:exp(-gamma|u-v|^2)
clf.fit(X, Y)
visualBoundary(X, Y, clf)
plt.show()
_ = input('Press [Enter] to continue.')
# =============== Part 6: Visualizing Dataset 3 ================
datainfo = sio.loadmat('ex6data3.mat')
X = datainfo['X']
Y = datainfo['y'][:, 0]
Xval = datainfo['Xval']
Yval = datainfo['yval'][:, 0]
plotData(X, Y)
plt.show()
_ = input('Press [Enter] to continue.')
# ========== Part 7: Training SVM with RBF Kernel (Dataset 3) ==========
# 参数选择
def dataset3Params(x, y, xval, yval):
c = 1; sigma = 0.3
err_best = np.size(yval, 0)
c_choice = [0.3, 1.0]
sigma_choice = [0.1, 0.3]
for i in range(len(c_choice)):
for j in range(len(sigma_choice)):
clf = svm.SVC(C=c_choice[i], gamma=1/(2*sigma_choice[j]**2))
clf.fit(x, y)
pred = clf.predict(xval) #用训练好的分类器去预测
err = np.sum(pred != yval)/np.size(yval, 0)
if err_best>err:
err_best = err
c = c_choice[i]
sigma = sigma_choice[j]
return c, sigma
c, sigma = dataset3Params(X, Y, Xval, Yval)
clf = svm.SVC(C=c, gamma=1/(2*sigma**2))
clf = clf.fit(X, Y)
visualBoundary(X, Y, clf)
plt.show()
4.2 ex6_spam.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import scipy.io as scio
from sklearn import svm
import re #处理正则表达式的模块
import nltk #自然语言处理工具包
'''============================part1 邮件预处理========================='''
#查看样例邮件
f = open('emailSample1.txt', 'r').read()
print(f)
def processEmail(email):
email = email.lower() #转化为小写
email = re.sub('<[^<>]+>', ' ', email) #移除所有HTML标签
email = re.sub('(http|https)://[^\s]*', 'httpaddr', email) #将所有的URL替换为'httpaddr'
email = re.sub('[^\s]+@[^\s]+', 'emailaddr', email) #将所有的地址替换为'emailaddr'
email = re.sub('\d+', 'number', email) #将所有数字替换为'number'
email = re.sub('[$]+', 'dollar', email) #将所有美元符号($)替换为'dollar'
#将所有单词还原为词根//移除所有非文字类型,空格调整
stemmer = nltk.stem.PorterStemmer() #使用Porter算法
tokens = re.split('[ @$/#.-:&*+=\[\]?!()\{\},\'\">_<;%]', email) #把邮件分割成单个的字符串,[]里面为各种分隔符
tokenlist = []
for token in tokens:
token = re.sub('[^a-zA-Z0-9]', '', token) #去掉任何非字母数字字符
try: #porterStemmer有时会出现问题,因此用try
token = stemmer.stem(token) #词根
except:
token = ''
if len(token) < 1:
continue #字符串长度小于1的不添加到tokenlist里
tokenlist.append(token)
return tokenlist
#查看处理后的样例
processed_f = processEmail(f)
for i in processed_f:
print(i, end=' ')
#得到单词表,序号为索引号+1
vocab_list = np.loadtxt('vocab.txt', dtype='str', usecols=1)
#得到词汇表中的序号
def word_indices(processed_f, vocab_list):
indices = []
for i in range(len(processed_f)):
for j in range(len(vocab_list)):
if processed_f[i]!=vocab_list[j]:
continue
indices.append(j+1)
return indices
#查看样例序号
f_indices = word_indices(processed_f, vocab_list)
for i in f_indices:
print(i, end=' ')
input('Program paused. Press enter to continue')
'''============================part2 提取特征========================='''
def emailFeatures(indices):
features = np.zeros((1899))
for each in indices:
features[each-1] = 1 #若indices在对应单词表的位置上词语存在则记为1
return features
sum(emailFeatures(f_indices)) #45
input('Program paused. Press enter to continue')
'''============================part3 训练SVM========================='''
#训练模型
train = scio.loadmat('spamTrain.mat')
train_x = train['X']
train_y = train['y']
clf = svm.SVC(C=0.1, kernel='linear')
clf.fit(train_x, train_y)
#精度
def accuracy(clf, x, y):
predict_y = clf.predict(x)
m = y.size
count = 0
for i in range(m):
count = count + np.abs(int(predict_y[i])-int(y[i])) #避免溢出错误得到225
return 1-float(count/m)
accuracy(clf, train_x, train_y) #0.99825
print('train Accuracy:')
print(accuracy(clf, train_x, train_y))
#测试模型
test = scio.loadmat('spamTest.mat')
accuracy(clf, test['Xtest'], test['ytest']) #0.989
print('test Accuracy:')
print(accuracy(clf, test['Xtest'], test['ytest']))
input('Program paused. Press enter to continue')
'''============================part4 高权重词========================='''
#打印权重最高的前15个词,邮件中出现这些词更容易是垃圾邮件
i = (clf.coef_).size-1
while i >1883:
#返回从小到大排序的索引,然后再打印
print(vocab_list[np.argsort(clf.coef_).flatten()[i]], end=' ')
i = i-1
input('Program paused. Press enter to continue')
'''============================part5 预测邮件========================='''
t = open('spamSample2.txt', 'r').read()
#预处理
processed_f = processEmail(t)
f_indices = word_indices(processed_f, vocab_list)
#特征提取
x = np.reshape(emailFeatures(f_indices), (1,1899))
#预测
clf.predict(x)