Python数据分析
Python数据分析
第一章Python基础
1.1Python解释器
Python是一种解释性语言,Python解释器通过一次执行一条语句来运行程序,在命令行键入python命令可以调用标准交互的Python解释器。
键入exit()或者ctrl + z 返回命令行提示符。
在IPython里使用ctrl + L来清屏。
作为数据分析一般不会用标准交互的解释器,一般使用IPython或Juptyter笔记本
- IPython是一个for Humans 的Python交互式shell,支持变量自动补全,自动缩进,支持bash shell命令,内置了许多实用功能和函数,同时它也是科学计算和交互可视化的最佳平台。
- Jupyter Notebook就像是一个草稿本,能将文本注释,数学方程,代码和可视化内容全部组合到一个易于共享的文档中,以web页面的方式展示,它是数据分析,机器学习的必备工具。
2.1IPython基础
2.1.1变量的打印输出
可以使用Python的print()或漂亮打印(pretty-printed),与通常print函数来打印有所不同。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DVEDccyP-1596355463831)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\159395023348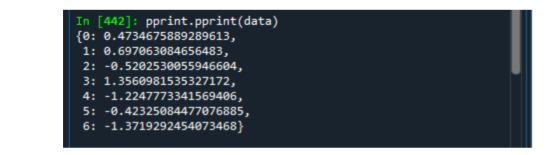
8.png)]
对于以由的Python程序,简单的复制粘贴到IPython就可以执行。
2.1.2运行Jupyter笔记本
Jupyter项目的主要组件之一就是notebook,一种用于代码,文本(有无标签),数据可视化和其他输出的交互式文档。
Jupyter笔记本与内核交互,内核以热呢数量的编程语言实现了Jupyter交互计算协议,Python的Jupyter内核采用IPython系统作为底层行为。
要启动Jupyter,在终端运行jupyter notebook命令:或者在Anaconda平台直接启动。一般来说除非你启动是带了–no-browser参数,一般会自动在你的浏览器打开。
当你保存笔记本,会创建一个扩展名为.ipynb的文件,这是一种自包含文件格式,包含当前在笔记本的所有内容(包括任何计算的代码的输出),这些东西可以被其他Jupyter用户加载编辑,为了加载一个已有的笔记本,我们可以将文件放在启动文件的同一个目录里,或者其子目录里,然后从Jupyter登录页面双击那个文件名。
2.1.3Tab补全功能
跟标准的Python外壳相比,IPython外壳具有tab补全功能。
2.1.4对象自省功能
在变量或方法名后加一个?,会显示一些相关信息
定义一个函数,添加文档字符串;使用?可以显示文档字符串
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MyH3G0PK-1596355463842)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593951652531.png)]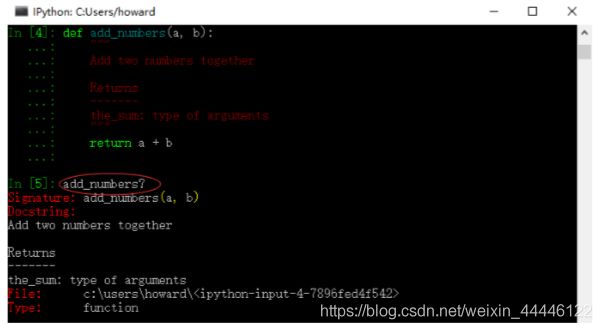
用??可以显示函数的源代码
?还可以结合通配符*搜索IPython的命名空间
注意,python shell不具有对象自身功能。
2.1.5%run命令–运行Python脚本
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gJoympyQ-1596355463846)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593951907874.png)]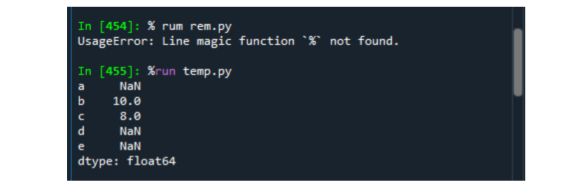
2.1.6 %load命令–加载Python脚本
2.1.7%paste执行剪贴板的代码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PUSRh46S-1596355463855)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593952076136.png)]
将上述代码全部选中,然后复制到剪贴板里
在IPython里利用魔法命令%paste,可以执行剪贴板里的代码。
值得注意的是%paste 和%cpaste在IPython5.0版本后已取消,直接复制粘贴就可以,查看IPython版本号
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Gn8kYIGJ-1596355463858)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593953145422.png)]
3.1Python语言基础
3.1.1Python基本数据类型
Python基本数据类型总共有六个
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Number
- 整型(int)
- 浮点型(float)
- 复数(complex):分为实数部分和虚数部分可以用a+bj,或者complex(a,b)来表示,复数的实部a和虚部b都是浮点型
#Number中常见的方法
#1.类型转换 int(X),float(X),complex(X)
#2.数字运算 注意 /(返回一个浮点数) 和 //(返回整数,需要用这个,如果分子分母中含有浮点数,那么结果也是含有浮点数的)的区别就可以了,其他运算符和其他开发语言一样
#3.随机函数
#3.1 choice(seq)从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。
#3.2 randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1
#3.3 random() 随机生成下一个实数,它在[0,1)范围内。
#3.4 seed([x]) 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。
#3.5 shuffle(lst) 将序列的所有元素随机排序
#3.6 uniform(x, y) 随机生成下一个实数,它在[x,y]范围内。
字符串
#在需要在字符中使用特殊字符时,python使用反斜杠\进行转义
#Python字符串的遍历直接使用索引[0:]
#Python字符串运算符
""""
+ 字符串连接 a + b 输出结果: HelloPython
* 重复输出字符串 a*2 输出结果:HelloHello
[] 通过索引获取字符串中字符 a[1] 输出结果 e
[ : ] 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 a[1:4] 输出结果 ell
in 成员运算符 - 如果字符串中包含给定的字符返回 True 'H' in a 输出结果 True
not in 成员运算符 - 如果字符串中不包含给定的字符返回 True 'M' not in a 输出结果 True
r/R 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。
print( r'\n' )
print( R'\n' )
% 格式字符串 请看下一节内容。
""""
列表[]
Python 有6个序列为内置类型,最为常见的为列表和元组,序列都可以进行的操作包括索引,切片,加,乘,检查成员,此外Python内置了确定序列的长度以及最大元素和最小元素的方法
列表的数据项不需要相同的数据类型,列表元素可以重复,列表元素是有序的,指的是存取顺序一致
#list列表中常用的方法
#定义列表
list = [1,2,3,4,5]
#更新列表 list(索引值) = 要更新的数据 java 中通过set方法更改List集合的值
#打印列表 print(列表名)
#删除列表的元素 使用 del list[index] 或者 remove list[index]
元组()
元组和列表很类似,不同之处在于元组的元素不能修改,元组使用的是小括号,列表使用的是方括号
#所谓元组的不可变指的是元组所指向的内存中的内容不可变。
"""
>>> tup = ('r', 'u', 'n', 'o', 'o', 'b')
>>> tup[0] = 'g' # 不支持修改元素
Traceback (most recent call last):
File "", line 1, in
TypeError: 'tuple' object does not support item assignment
>>> id(tup) # 查看内存地址
4440687904
>>> tup = (1,2,3)
>>> id(tup)
4441088800 # 内存地址不一样了
"""
#从以上实例可以看出,重新赋值的元组 tup,绑定到新的对象了,不是修改了原来的对象。
字典{}
字典是一种可变容器模型,且可以存储任意类型的变量,字典的每个键值对之间使用逗号分割,键值之间使用冒号
字典值可以是任何的 python 对象,既可以是标准的对象,也可以是用户定义的,但键不行。
两个重要的点需要记住:
- 不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住,如下实例:
#!/usr/bin/python3
dict = {
'Name': 'Runoob', 'Age': 7, 'Name': '小菜鸟'}
print ("dict['Name']: ", dict['Name']) #dict['Name']: 小菜鸟
- 键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行,如下实例:
#!/usr/bin/python3
dict = {
['Name']: 'Runoob', 'Age': 7}
print ("dict['Name']: ", dict['Name'])
""""
Traceback (most recent call last):
File "test.py", line 3, in
dict = {['Name']: 'Runoob', 'Age': 7}
TypeError: unhashable type: 'list'
""" "
集合
集合(set)是一个无序的 不重复元素序列(元素不重复和底层数据结构相关),可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
#定义一个set集合
set = {
1,2,3,4,5,6}
#添加元素: set.add()
#移除元素: set.remove(X),set.discard(X)使用这个方法移除元素,如果元素不存在不会报错
#计算集合元素个数:len(set)
#清空集合:set.clear()
#判断元素是否在集合中 X in set 返回一个布尔值
注意事项
Python中没有数组这一基本类型,注意和Java区分开来,注意元组不是数组,它和列表的区别在于元组的数据是不能改变的,定义的时候使用的是()
3.1.2一些注意事项
- 列表变量赋值给列表变量,采用的时地址传递方式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JaI0hneh-1596355463864)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593955808035.png)]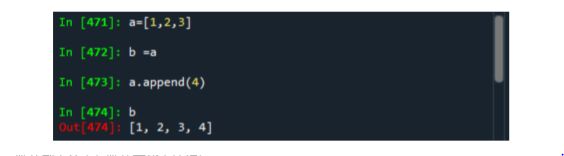
-
数值型字符串与数值不能直接相加
在java中会自动转为字符串拼接操作,Python是动态类型语言,但又是一种强类型的语言,所以5+“5”是不被允许的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OFXSd94Z-1596355463866)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593955893185.png)]
-
判断变量是否是某种类型
- 通过isintance(变量名,类型名)判断变量是不是指定的数据类型
- isinstance(变量名,(类型名列表))判断变量是不是列表中的数据类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ImaRkUyZ-1596355463868)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593956379951.png)]

-
通过getattr(对象名,‘方法名’)函数了解对象指定方法的参数情形
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UVWKUzS9-1596355463870)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593956488831.png)]

-
鸭子类型(Duck Typing)
如果它走起来像一只鸭子,叫起来像一只鸭子,那么它就是一只鸭子
比如,你可以验证一个对象是迭代的,如果它实现了迭代器协议,遂于很多对象,意味着他又一个
_iter_魔法方法。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SQ91XzqS-1596355463872)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593956696556.png)]

-
二元运算符与比较
is 要看内容和地址,两者相同,结果为真==只看内容,不看地址,只要内容相同,结果就为真
a =[1,2,3] b = a c = list(a) a is b Out[492]: True a is not c Out[493]: True a == c Out[494]: True a =None a is None Out[496]: True a ==None Out[497]: True -
可变与不可变对象
Python的绝大数对象,比如lists,dicts,NumPy arrays与用户自定义类型(classes),都是可变的,意味着对象包含的值是可以修改的。但是值得注意的是字符串和元组是不可改变的。
x =['foo',2,[4,5]] x[2]=[100,200] x Out[500]: ['foo', 2, [100, 200]] dict1 ={ '1':'mike','2':'alice','3':'green'} dict1['2']='justin' dict1 Out[503]: { '1': 'mike', '2': 'justin', '3': 'green'} message ="I love you" message[0] Out[505]: 'I' message[0]='my' Traceback (most recent call last): File "" , line 1, in <module> message[0]='my' TypeError: 'str' object does not support item assignment tuple1=(3,4,(1,2)) tuple1[2] Out[508]: (1, 2) tuple1[2]=(100,200) Traceback (most recent call last): File "" , line 1, in <module> tuple1[2]=(100,200) TypeError: 'tuple' object does not support item assignment -
标量类型
None str bytes float bool int 注意 /和//的区别 要取整请使用//,/得到小数位 -
字符串
定界符:单引号,双引号,三引号(多行字符串),数值可以转换成字符串,字符串是可迭代对象,可以转换成列表,字符串模板功能
a =5 b =str(a) type(b) Out[512]: str b Out[513]: '5' s='python' iter(s) Out[515]: <str_iterator at 0x2d181f66388> list(s) Out[516]: ['p', 'y', 't', 'h', 'o', 'n'] s[:3] Out[517]: 'pyt' s[2:] Out[518]: 'thon' s[2:4] Out[519]: 'th' -
字节与Unicode
encode:编码,decode:解码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pfeaCVhW-1596355463874)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1594135278455.png)]

-
类型转换
x='3.1415926' y =float(x) type(x),type(y) Out[524]: (str, float) int(True),int(False) Out[525]: (1, 0) -
None
如果一个函数没有显式返回一个值,那么隐含返回一个None
-
Python内置的datetime模块提供了date,time与datetime类型
-
for循环,后续补充
-
pass --no-op statement,后修补充
-
range 后续补充
-
ternary expressions(三元表达式)
value =true-expr if condition else false-expr
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LLFdjIJH-1596355463878)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1594137297042.png)]

-
闭包
闭包满足三个条件:
- 存在于嵌套关系的函数中
- 嵌套的内部函数引用了外部函数的变量
- 嵌套的外部函数将内部函数名作为返回值返回
-
构造方法
第二章导论
Anaconda的使用
Anaconda是一个集成各类Python工具的集成平台,包括conda,某个版本的Python,一批第三方库等
conda:一个工具,用于包管理和环境管理,其中包管理于pip类似,管理Python第三方库,环境管理能够允许用户使用不同版本的Python,并且能够灵活切换,conda将工具,第三方库,Python版本,conda都当作包,同等对待
#conda的操作
conda --version 获取conda版本
conda update conda 升级conda
Spyder:Python编程工具
IPythond的魔术命令
以%符号开头,是IPython在Python语法基础上的增强功能,分为行魔法(%)和单元魔法(%%)
利用%antumagic命令可以设置自动魔法命令是ON 还是OFF,当设置为ON的时候,魔法命令可以省掉前面%,默认情况下automagic为ON状态,当设置为OFF时,魔法命令不能省略前面%
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B2Qlvk7O-1596355463880)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593953441448.png)]
- IPython 的?:变量前或后增加?将显示一些通用信息,包括函数对应的源码
- IPython 的%run:%run用于运行.py程序,注意%run在一个空的命名空间执行%
- %magic:显示所有的魔术命令
- %hist:IPython命令的输入历史
- %pdb:异常发生后自动进入调试器
- %reset:删除当前命名空间的全部变量或名称
- %who:显示当前IPython命名空间中已经定义的变量
- %time statement:给出代码的执行时间,statement表示一段代码
- %timeit statement:多次执行代码,计算综合平均执行时间
一个数据:表达一个含义
一组数据:表达一个或多个含义
摘要:有损地提取数据特征的过程
一组数据经过摘要要得到的数据应该是这样的,含有基本统计信息(含排序);分布/累计统计;数据特征(相关性,周期性等);数据挖掘(形成知识)
安装或升级Python包
-
安装格式
1.conda install package_name 2.pip install package_name -
升级格式命令
1.conda upgrade package_name 2.pip install --upgrade package_name
注意的是:可以使用conda和pip命令来安装包,但是建议升级conda包的时候,不建议使用pip,那么做会导致环境问题,使用Anaconda,最好先尝试用conda升级包。
行话
-
Munge/munging/wrangling
整理或清理:描述将非结构化或混乱数据转换成结构化或干净话形式的完整过程。
-
Pseudocode
伪代码:描述一个算法或过程,沉陷一个类似代码的形式,但是可能并不是有效的源代码
-
Syntatic sugar
句法糖:指的是这样的程序句法,没有添加新的功能,但是让某些东西更容易更方便键入。
第三章NumPy
2.1数据维度
-
维度:一组数据的组织形式
-
一维数据:由对等关系的有序或无序数据构成,采用线性方式组织,对应列表(列表数据类型可以不同,有序),数组(数据类型相同,有序)和集合(无序)等概念。
-
二维数据:二维数据是由多个一维数据构成,是一维数据的组合形式。表格是典型的二维数据
-
多维数据:由一维或二维在新维度上扩展形成,比如时间维度
-
高维数据:键值对组织起来,仅利用最基本的二元关系展示数据间的复杂结构
2.2数据维度的Python表示
- 一维数据:列表(有序)或集合(无序)类型 [3,4,5,6]或{3,4,5,6}
- 二维数据:列表类型[[1,2,3,4],[1,2,3,4]]
- 多维数据:列表类型(有序)
- 高维数据:字典类型 或者数据表示格式 JSON,XML 和YAML dict ={“firstName”:“Tian”,“lastName”:“an”}
2.3NumPy
NumPy是一个开源的Python科学计算基础库,包含:
- 一个强大的N维数组对象 ndarray
- 广播功能函数,用于数组之间计算
- 整合C/C++/Fortran代码工具,底层由C实现的,非常快
- 线性代数,傅里叶变换,随机数生成功能
NumPy是SciPy,Pandas等数据处理或科学计算库的基础
2.3.1NumPy的引用
import numpy as np
#尽量使用这个别名
N维数组对象:ndarry
- 数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据
- 设置专门的数组对象,经过优化,可以提升这类应用的运算速度
- 数组对象采用相同的数据类型,有助于机身运算和存储空间
- 一般来说,如果不指定,NumPy的整数类型默认是int32,实数默认类型是float64
def pySum():
a = [0,1,2,3,4]
b = [9,8,7,6,5]
c =[]
for i in range(len(a)):
c.append(a[i]**2+b[i]**3)
return c
print(pySum())
#使用numpy的效果是,把一维数组当作一个单个数据来计算
import numpy as np
def npSum():
a = np.array([0,1,2,3,4])
b = np.array([9,8,7,6,5])
c = a**2 + b**3
return c
print(npSum())
2.3.2N维数组对象:ndarray
ndarray是Python中一个快速,灵活的大型数据集容器,数组,允许你使用标量的操作语法在整个数据块上进行科学计算。ndaarray 是一个多维数组对象,由两部分组成
- 实际的数据
- 描述这些数据的元数据(数据维度,数据类型等)
#通常不建议使用 np.ndarray()来创建ndarray对象
import numpy as np
np.ndarray([1,2,3,4])#不建议使用这个方法来生成一个ndarray对象,
np.array()此方法返回一个ndarray对象,我们一般使用这个np.array()函数来生成ndarray对象,ndarray是一个类对象,array是一个方法将列表和元组转为数组ndarray
ndarray数组一般要求所有元素类型相同(同质),数组下标从0开始,
#ndarray创建实例
import numpy as np
#a = np.array([[1,2,3,4,5],[6,7,8,9,10]])
#print(a)
b =np.ndarray([1,2,3,4,5])#不推荐使用
print(b)
ndarray对象的属性
介绍两个名词:
- 轴(axis):保存数据的维度,(维度指的是一组数据的组织形式),在这个维度下数据的排布
- 秩(rank):轴的数量(维度的数量)
常见的属性:
-
.ndim:秩,即轴的数量或者说使维度的数量,秩的数量从0开始计算,0为第一个
-
.shape:ndarray对象的尺度,对于矩阵,n行m列
-
.size:ndarray对象元素的个数:相当于.shape中n*m的值
-
.dtype:ndarray对象的元素类型
-
.itemsize:该属性表示数组中每个元素的大小(以字节为单位),例如数组的类型为float64,那么itemsize就等于8(64/8)
-
常见的数组类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3PYoSaH4-1596355463881)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1594209807403.png)]
-
-
.itemsize:ndarray对象中每个元素的大小,以字节为单位
注意可以使用astype来显式的转换数组的数据类型,使用astype总是生成新的数组,即使你传入的数组对象元素类型是一样的。或者使用np.asarray()或np.array()方法生成新的数组,然后指明元素类型。
import numpy as np
a =np.array((1,2,3,4,5))
a
Out[528]: array([1, 2, 3, 4, 5])
a.dtype
Out[529]: dtype('int32')
b=a.astype('float64')
b
Out[531]: array([1., 2., 3., 4., 5.])
b.dtype
Out[532]: dtype('float64')
a=np.array((1,2,3,4,5))
b=np.array(a,dtype=np.float)
b.dtype
Out[535]: dtype('float64')
a.dtype
Out[536]: dtype('int32')
import numpy as np
a = np.array([1,2,3,4,4])
print(a.ndim)#1
print(a.shape)#(5,)
print(a.size)#5
print(a.dtype)#int32
print(a.itemsize)#4
########################################
b = np.array([[1,2,3,4,5],[6,7,8,9,10]])
b.ndim #2
b.shape#(2,5)
b.size#10
b.dtype#int32
b.itemsize#4
###########################################
import numpy as np
b = np.array([1,2,3,4,5])
b.dtype
Out[189]: dtype('int32')
a =b.astype(np.float)
a
Out[191]: array([1., 2., 3., 4., 5.])
a.dtype
Out[192]: dtype('float64')
ndarray元素的类型
对比:Python语法只支持整数,浮点数和复数3种类型
- 科学计算涉及数据较多,对存储和性能都有较高要求
- 对元素类型精细定义,有助于NumPy合理使用存储空间并优化性能
- 对元素类型精细定义,有助于程序员对程序规模有合理评估
需要注意的使ndarray虽然元素类型支持较多,但是建议一个ndarray对象存储的元素类型应该是要同质的,因为ndarray数组虽然可以由非同质对象构成,但是非同质ndarray对象无法有效的发挥NumPy优势,尽量避免使用。
impoart numpy as np
a = np.array([1,2,3,4,5.0])
a.dtype#float 64
a.itemsize#8
b = np.array([1,2,3,4,5])
b.dtype#int 32
b.itemsize#4
#建议使用同质元素
2.3.3ndarray数组的创建方法
-
从Python中的列表,元组等类型创建ndarray数组,这里使用到了array方法,将列表,元组,图像,转换为ndarray数组,array函数接受任何序列对象,或者其他数组
""" #定义格式 x = np.array(list/tuple) x = np.array(list/tuple,dtype=np.float32) 当np.array()不指定dtype时,NumPy将根据数据情况,关联一个dtype类型 """ import numpy as np a =np.array([1,2,3]) a Out[76]: array([1, 2, 3]) b = np.array((1,2,3),dtype=np.float32) b Out[78]: array([1., 2., 3.], dtype=float32) b.dtype Out[79]: dtype('float32') ##############列表和元组混合类型创建,但是要注意元素个数是一样的 c = np.array([[1,2],(1,2)]) c = np.array([[1,2],(1,2,3)]) c Out[85]: array([list([1, 2]), (1, 2, 3)], dtype=object) ##元素类型不一样,当作对象看待,不是同质的,不利用NumPy发挥作用 -
使用NumPy函数创建ndarray数组,如:arange,one,zeros等
- np.arange(n):类似range()函数,返回ndarray类型,元素从0到n-1,arange是Python内建函数的数组版
-
np.ones(shape):根据shape生成一个全1数组,shape是元组类型
- np.ones_like(a):根据数组a的形状生成一个全1数组
- np.zeros(shape):根据shape生成一个全0数组,shape是元组类型
- np.zeros_like(a):根据数组a的形状生成一个全0的数组
- np.full(shape,val):根据shape生成一个数组,每个元素都是val
- np.full_like(a,val):根据数组a的形状生成一个数组,每个元素值都是val
-
np.eye(n):创建一个正方形n*n单位矩阵,对角线为1,其余为0
- np.linspace():根据起止数据等间距地填充数据,形成数组
- np.concatenate():将两个或多个数组合并形成一个新的数组
-
np.empty:该方法可以创建一个空数组,如果指明shape,则生成的数为随机数
import numpy as np
#使用arange(n)创建ndarray数组,生成的是0-(n-1)的整数
a = np.arange(10)
#使用np.ones(shape)创建数组,生成的元素是浮点数
b = np.ones((2,3))
#使用np.ones_like()生成数组
b1 = np.ones_like(b)
#使用np.zeros(shape)创建数组,生成的元素是浮点数
c = np.zeros((2,3))
#使用np.zeros_like(a)生成数组
c1 = np.zeros_like©
#使用np.full(shape,1)生成一个全是1的数组,它是一个2行3列的矩阵
d = np.full((2,3),1)
#使用np.full_like(d,2)生成数组
d1 = np.full_like(d,2)
#使用np.eye(n),创建一个数组,生成的元素是浮点数
e = np.eye(10)
#np.linspace():根据起止数据等间距地填充数据,形成数组,np.linspace 有个参数endpoint=True,默认为true 包含终止元素,如果把endpoint=false,就是不包含False,注意在Python中布尔值要首字母大写True False
f = np.linspace(1,10,3)#起始1 终止元素10 总共3个元素
f1= np.linspace(1,10,3,endpoint=False)#array([1., 4., 7.])
#使用np.concatenate()将数组合并成一个新的数组
f11 =np.concatenate((f,f1)#array([ 1. , 5.5, 10. , 1. , 4. , 7. ]) 注意f,f1之间的括号
3. 从字节流(raw byte)中创建ndarray数组
4. 从文件中读取特定格式,创建ndarray数组
5. 此外我们还可以通过NumPy的随机函数来生成数组
- numpy.random.rand(n)
- numpy.random.randn(shape=?):创建符合正态分布的数组
- numpy,random,randint(low,hight,shape):
6. 总结,生成数组最简单的方法就是使用array函数,array函数接受任意的序列对象(当然也包括其他的数组),生成一个新的包含传递数据的NumPy数组,此外还有很多其他的函数可以创建新数组,例如,给定长度及形状后,zeros,可以一次性创造全0的数组,ones可以一次性创造全1 的数组,empty则可以创建一个没有初始化数字的数组,想要创建高维度的数组,则需要为shape传递一个元组。
##### 2.3.4ndarray数组的变换
- 元素类型变换
之前我们讲过数组对象由两部分组成,一个是实际的数据,另一个是数据类型,我们一般默认不写数据类型,实际上数据类型是可以进行改变的
1. astype()方法一定会创建一个新的数组(原始数据的一个拷贝),即使两个类型一致
```python
#数组类型的转换
import numpy as np
a = np.ones((2,3,4))
a.dtype#float64
b = a.astype(np.int)
b.dtype#int32
-
维度的变换
- .reshape(shape):不改变数组元素,返回一个shape形状的数组,原数组不变
- .resize(shape):与.reshape()功能一致,但是修改原数组
- .swapaxes(ax1,ax2):将数组n个维度中两个维度进行调换
- .flatten():将数组进行降维,返回折叠后的一维数组,原数组不变
#.reshape(shape):不改变数组元素,返回一个shape形状的数组,原数组不变 a = np.ones((2,3,3),dtype=np.int32) a.reshape((3,8))#没有改变原数组,注意在改变的时候要保证数组属性size不发生变化 a.resize((3,8))#原数组发生改变,注意在改变的时候要保证数组属性size不发生变化 #.swapaxes(ax1,ax2):将数组n个维度中两个维度进行调换,把一个两行三列的数组更改为3行两列 np.swapaxes(b,0,1)#把数组b,的0轴和1轴互换 #.flatten():将数组进行降维,返回折叠后的一维数组,原数组不变 c = np.arange(10).reshape(2,5).flatten()#array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) -
数组向列表的转换
- .tolist()
#数组向列表的转换 a = np.zeros((2,3),dtype=np.int) a Out[155]: array([[0, 0, 0], [0, 0, 0]]) ls = a.tolist() ls Out[157]: [[0, 0, 0], [0, 0, 0]] b = np.array(ls) b Out[159]: array([[0, 0, 0], [0, 0, 0]]) b.shape Out[160]: (2, 3)
2.3.5数组的操作
-
数组的索引
索引:获取数组中特定位置元素的过程
-
数组的切片
切片指的是获取数组元素子集的过程,a[1:4:2],遵循左闭右开原则,起始编号:终止编号(不含):步长,3个参数使用冒号分割
#多维数组的索引,先确定在哪个维下找数据 import numpy as np a = np.arange(24).reshape((2,3,4)) a Out[163]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) a[1,2,3] Out[164]: 23 a[0,1,2] Out[165]: 6 a[-1,-2,-3] Out[166]: 17 #多维数组的切片 b = np.arange(32).reshape(2,4,4) b Out[174]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15]], [[16, 17, 18, 19], [20, 21, 22, 23], [24, 25, 26, 27], [28, 29, 30, 31]]]) #:代表每一个维度都要切 b[:,1:2,:] Out[175]: array([[[ 4, 5, 6, 7]], [[20, 21, 22, 23]]]) b[:,1:4,:] Out[176]: array([[[ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15]], [[20, 21, 22, 23], [24, 25, 26, 27], [28, 29, 30, 31]]]) b[1:,1:4,:] Out[177]: array([[[20, 21, 22, 23], [24, 25, 26, 27], [28, 29, 30, 31]]]) #每个维度可以使用步长跳跃切片 b[:,:,::2] Out[179]: array([[[ 0, 2], [ 4, 6], [ 8, 10], [12, 14]], [[16, 18], [20, 22], [24, 26], [28, 30]]]) #二维数组的切片 arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]]) #数组沿着轴0进行切片,表达式arr2d[:2]的含义为选择arr2d的前两行 arr2d[:2] Out[230]: array([[1, 2, 3], [4, 5, 6]]) arr2d[:] Out[231]: array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) #如果将索引和切片混合,就可以得到低纬度的切片 arr2d[:2,1:] Out[232]: array([[2, 3], [5, 6]])切片中需要注意的点:如果你传递了一个数值给数组的切片,数值被传递给了整个切片,区别于Python的内建列表,数组的切片是原数组的视图,这意味着数组并不是被复制了,任何对视图的修改都会反映到原数组上。如果实在需要数组切片的拷贝而不是一份视图的话,就必须的显式地复制这个数组,例如arr[5:8].copy(),相当于对数组进行了赋值操作。但是当切片数组整个发生改变,则不会对原数组有影响。
import numpy as np a = np.arange(15) a Out[202]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]) a[5] Out[203]: 5 #对数组切片赋值 a[5:8]=100 #这里可以看到原数组发生了改变 a Out[205]: array([ 0, 1, 2, 3, 4, 100, 100, 100, 8, 9, 10, 11, 12, 13, 14]) #改变切片的整个数组,不会影响原数组 mylist=np.array([0,1,2,3,4,50,60,70,8,9]) mylist Out[538]: array([ 0, 1, 2, 3, 4, 50, 60, 70, 8, 9]) list_slice=mylist[5:8] list_slice Out[540]: array([50, 60, 70]) list_slice=[777,888,999] mylist Out[542]: array([ 0, 1, 2, 3, 4, 50, 60, 70, 8, 9]) list_slice Out[543]: [777, 888, 999] #给切片列表赋值,影响原数组 mylist Out[546]: array([ 0, 1, 2, 3, 4, 50, 60, 70, 8, 9]) mylist=np.array([0,1,2,3,4,50,60,70,8,9]) list_slice=mylist[5:8] list_slice[0] Out[549]: 50 list_slice[0]=100 mylist Out[551]: array([ 0, 1, 2, 3, 4, 100, 60, 70, 8, 9]) -
ndarray数组的运算
-
数组与标量之间的运算,数组与标量之间的运算作用于数组的每一个元素
b = np.arange(24).reshape((2,3,4)) b Out[206]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) a.mean() Out[207]: 11.5 """ #用法:mean(matrix,axis=0) 其中 matrix为一个矩阵,axis为参数 以m * n矩阵举例: axis 不设置值,对 m*n 个数求均值,返回一个实数,如果矩阵第一个元素为0,则是最后一个元素的平均值,第一个元素不为0是最后一个元素+1的平均值 axis = 0:压缩行,对各列求均值,返回 1* n 矩阵,要在维度上看待 axis =1 :压缩列,对各行求均值,返回 m *1 矩阵 -
NumPy中的一元函数
#np.abs(X),np.fabs(X):计算数组各元素的绝对值 #np.sqrt(X):计算数组各元素的平方根 #np.square(X):计算数组各元素的平方 #np.log(X) np.log10(X),np.log2(X) #np.ceil(X),np.floor(X) #np.rint(X):计算数组各元素的四舍五入的值 #np.modf(X):将数组个元素的小数和整数部分以两个独立数组形式返回 #np.cos(X),np.cosh(X) #np.sin(X),np.sinh(X) #np.tan(X),np.tanh(X) #计算数组各元素的普通型和双曲型三角函数 #np.exp(X):计算数组各元素的以e为底指数值 #np.sign(X):计算数组各元素的符号值,1(+),0,-1(-) ###实例 import numpy as np a = np.arange(24).reshape((2,3,4)) #利用square求平方根 np.square(a) Out[227]: array([[[ 0, 1, 4, 9], [ 16, 25, 36, 49], [ 64, 81, 100, 121]], [[144, 169, 196, 225], [256, 289, 324, 361], [400, 441, 484, 529]]], dtype=int32) #利用sqrt求开方 np.sqrt(a) Out[228]: array([[[0. , 1. , 1.41421356, 1.73205081], [2. , 2.23606798, 2.44948974, 2.64575131], [2.82842712, 3. , 3.16227766, 3.31662479]], [[3.46410162, 3.60555128, 3.74165739, 3.87298335], [4. , 4.12310563, 4.24264069, 4.35889894], [4.47213595, 4.58257569, 4.69041576, 4.79583152]]]) ###modf 函数的使用 np.modf(np.sqrt(a)) Out[229]: (array([[[0. , 0. , 0.41421356, 0.73205081], [0. , 0.23606798, 0.44948974, 0.64575131], [0.82842712, 0. , 0.16227766, 0.31662479]], [[0.46410162, 0.60555128, 0.74165739, 0.87298335], [0. , 0.12310563, 0.24264069, 0.35889894], [0.47213595, 0.58257569, 0.69041576, 0.79583152]]]), array([[[0., 1., 1., 1.], [2., 2., 2., 2.], [2., 3., 3., 3.]], [[3., 3., 3., 3.], [4., 4., 4., 4.], [4., 4., 4., 4.]]])) #注意对数组的任何一元运算,都不会对本身的数组造成影响,而是新生成了一个数组 a Out[230]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) -
NumPy中的二元函数
+ - * / ** 两个数组各元素进行对应运算 np.maximum(X,Y) np.fmax() np.minimun(X,Y) np.fmin() 元素级的最大值/最小值计算 np.copysign(X,Y):将数组y中各元素的符号赋值给数组X对应元素 > < >= <= == !=:算术比较,产生布尔型数组 ############################################### import numpy as np a = np.arange(24).reshape((2,3,4)) b = np.sqrt(a) #a>b 算术比较,产生布尔型数组 a > b Out[236]: array([[[False, False, True, True], [ True, True, True, True], [ True, True, True, True]], [[ True, True, True, True], [ True, True, True, True], [ True, True, True, True]]]) #np.maximum(a,b)的使用 np.maximum(a,b) Out[238]: array([[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]], [[12., 13., 14., 15.], [16., 17., 18., 19.], [20., 21., 22., 23.]]]) #np.fmax(a,b),返回较大的数组 np.fmax(a,b) Out[239]: array([[[ 0., 1., 2., 3.], [ 4., 5., 6., 7.], [ 8., 9., 10., 11.]], [[12., 13., 14., 15.], [16., 17., 18., 19.], [20., 21., 22., 23.]]])
-
2.3.6NumPy的数组的运算
数组之所以重要是因为它允许你进行批量操作而无需任何for循环,NumPy用户称这种特性为向量化,任何两个等尺寸数组之间的算术操作都应用了逐元素操作的方式。
不同尺寸数组之间的操作,将会用到广播特性。
NumPy数组运算分为以下四种
-
数组于数组的算术运算
相同尺寸的数组进行算术运算,是逐个元素进行相应的运算,需要注意的是,使用’*‘是将同一位置上的元素相乘,对于矩阵的乘法运算,需要使用’@'符号或者调用’dot’方法
补充:矩阵的乘法,只有当矩阵A的列数等于矩阵B的行数的时候,才能进行计算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FS50m5Zy-1596355463886)(C:\myNote\data_analyse\python_code\矩阵的乘法.PNG)]
a = np.array([[1,1],[1,1]]) b = np.array([[2,0],[3,4]]) print("同一位置元素相乘") 同一位置元素相乘 print(a*b) [[2 0] [3 4]] print("矩阵相乘") 矩阵相乘 print(a@b) [[5 4] [5 4]] print(a.dot(b)) [[5 4] [5 4]] -
数组于标量进行运算
-
数组与数组的关系运算
-
数组与标量的关系运算
import numpy as np
arr = np.array([[1,2,3,4,5],[1,2,3,4,5]])
arr * arr
Out[194]:
array([[ 1, 4, 9, 16, 25],
[ 1, 4, 9, 16, 25]])
arr2 =np.array([[2,3,4,5,6],[2,3,4,5,6]])
#同尺寸之间的数组之间的比较,会产生一个布尔值数组
arr2 > arr
Out[199]:
array([[ True, True, True, True, True],
[ True, True, True, True, True]])
2.3.7NumPy的索引
2.3.7.1索引,切片,迭代
与Python列表相似,一维数组可以被索引,切片和迭代
import numpy as np
a = np.arange(10)
a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
#通过下标选择元素
a[5]
Out[59]: 5
#通过切片选择元素
a[3:8]
Out[60]: array([3, 4, 5, 6, 7])
#通过切片设置步长选择元素
a[::2]
Out[61]: array([0, 2, 4, 6, 8])
#迭代
for i in a:
print(i*5)
0
5
10
15
20
25
30
35
40
45
对于多维数组,每个轴上可以有一个索引,并以逗号形式分割
import numpy as np
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12]).reshape(3,4)
a
Out[66]:
array([[ 1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12]])
#按照下标选取元素
a[1,0]
Out[67]: 5
#按行切片选择指定列,先按行切片选择前0,1,2三行,在指定第二列
a[0:3,2]
Out[68]: array([ 3, 7, 11])
#按行切片,选择所有列
a[0:2,:]
Out[69]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])
#按列切片,选择所有行
a[:,1:3]
Out[70]:
array([[ 2, 3],
[ 6, 7],
[10, 11]])
#如果提供的索引少于轴的数量会被认为是完整的切片
a[2]#等价于a[2,:]对列进行切片选择第三行
Out[71]: array([ 9, 10, 11, 12])
#NumPy支持用三个点"..."来表示剩下的轴,加入一个多维数组有五个轴
a[1,..]#等同于a[1,:,:,:,:]
#三维数组切片
a = np.array([1,2,3,4,5,6,7,8,9,10,11,12]).reshape(2,3,2)
a
array([[[ 1, 2],
[ 3, 4],
[ 5, 6]],
[[ 7, 8],
[ 9, 10],
[11, 12]]])
a[1,:,:]
Out[76]:
array([[ 7, 8],
[ 9, 10],
[11, 12]])
a[1,...]
Out[77]:
array([[ 7, 8],
[ 9, 10],
[11, 12]])
#对多维数组的迭代是针对第一个轴来完成的,如果我们要遍历多维数组的所有元素,则需要访问数组的flat属性
for i in a.flat:
print(i)
1
2
3
4
5
6
7
8
9
10
11
12
for row in a:
print(row)
[[1 2]
[3 4]
[5 6]]
[[ 7 8]
[ 9 10]
[11 12]]
2.3.7.2布尔索引
布尔值数组的长度必须和数组轴索引的长度一致,可以使用切片或者整数值,对布尔值数组进行混合和匹配。使用布尔值索引选择数组的时候,总是生成数据的拷贝,即使返回的数组并没有任何变化。Python的关键字 and 和 or 对布尔值数组并没有用,请使用&(and)和|(or)来代替。通过布尔索引我们可以筛选数据。
import numpy as np
a = np.arange(12).reshape(3,4)
a
Out[164]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
#简单写法
a[a>4]
Out[165]: array([ 5, 6, 7, 8, 9, 10, 11])
#标准写法
b = a>4
b
Out[167]:
array([[False, False, False, False],
[False, True, True, True],
[ True, True, True, True]])
a[b]
Out[168]: array([ 5, 6, 7, 8, 9, 10, 11])
2.3.7.3神奇索引
神奇索引式Python中的术语,用于描述使用整数数组进行数据索引。
2.3.7.4高级索引
NumPy提供了比常规Python序列更多的索引功能,除了通过整数和切片进行索引外,数组还可以通过其他整数数组,布尔及ix()函数进行索引。
-
通过数组索引
原始数组是一维的,使用二维数组进行索引,最终结果是二维的,原始数组是二维的,也是用二维数组进行索引,最终结果是三维的,因此使用二维数组索引,最终结果会在原始数组的基础上提升一个维度。一维对一维还是一维,对多维数组进行索引,给出的索引数组将从原始数组的第一个维度上进行取值。其实就是因为只给了一个索引值,所以是在第一个维度上取值,假如给了两个索引值,则要求两个索引值的个数要相同
#一维数组 import numpy as np a = np.arange(12) #轴的数量 a.ndim 1 #使用一维数组进行索引 b = np.array([1,1,3,4]) a[b] Out[140]: array([1, 1, 3, 4]) #在一维数组上使用二维数组进行索引 c = np.array([[2,3],[5,6]]) c.ndim Out[142]: 2 a[c] #可以看到维度上升 Out[144]: array([[2, 3], [5, 6]]) #多维数组的操作 import numpy as np data = np.array([[0,0,0,99],[168,0,0,23],[0,198,0,78],[0,0,23,64],[121,0,88,36]]) data.ndim Out[147]: 2 data Out[148]: array([[ 0, 0, 0, 99], [168, 0, 0, 23], [ 0, 198, 0, 78], [ 0, 0, 23, 64], [121, 0, 88, 36]]) index = np.array([[1,2,3,4],[0,2,1,3]]) #在二维数组上使用二维索引,可以看到维度的提升 data[index] Out[150]: array([[[168, 0, 0, 23], [ 0, 198, 0, 78], [ 0, 0, 23, 64], [121, 0, 88, 36]], [[ 0, 0, 0, 99], [ 0, 198, 0, 78], [168, 0, 0, 23], [ 0, 0, 23, 64]]]) data[index].ndim Out[151]: 3 #给两个索引数组 import numpy as np a = (np.arange(16)*2).reshape(4,4) a Out[153]: array([[ 0, 2, 4, 6], [ 8, 10, 12, 14], [16, 18, 20, 22], [24, 26, 28, 30]]) b = np.array([[0,1],[2,3]]) c = np.array([[1,2],[3,3]]) #使用两个多维数组进行索引按照axis=0 axis=1 1对1 a[b,c] Out[162]: array([[ 2, 12], [22, 30]]) -
通过ix()函数索引
NumPy提供了ix()函数来构造索引,与一般的整数索引逻辑不同,该函数的第一个参数是列表类型,表示取行,第二个函数也是列表类型,表示取列。
import numpy as np a = np.arange(10).reshape(2,5) a Out[169]: array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]) #使用ix进行索引,第一个列表代表的是行,第二个列表代表的是列,和a[[],[]]效果是一样的 b = np.ix_([0,1],[2,3]) b Out[172]: (array([[0], [1]]), array([[2, 3]])) a[b] Out[173]: array([[2, 3], [7, 8]])
2.3.8NumPy的形状操作
2.3.8.1更改形状
更改形状分两种,一种是更改完形状后形成了新的数组对象,一种是不会形成新的数组对象
-
形成新的数组对象
- ravel():将多维数组转为一维数组
- reshape():将数组转为指定的形状
import numpy as np a = np.floor(10*np.random.random((4,5))) a.shape Out[86]: (4, 5) #将数组修改为指定的形状,生成了新的数组对象 c=a.reshape(2,10) array([[3., 8., 3., 2., 1., 2., 6., 2., 5., 7.], [3., 5., 0., 6., 6., 5., 8., 0., 3., 9.]]) #将多维数组转为一维数组 d = a.ravel() Out[90]: array([3., 8., 3., 2., 1., 2., 6., 2., 5., 7., 3., 5., 0., 6., 6., 5., 8., 0., 3., 9.]) -
保持原数组不变
resize():此方法可以避免创建新的数组,在不需要重用数组对象的情况下,建议使用resize()以节省内存空间。
a = np.arange(12).reshape(3,4) a Out[93]: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]]) a.resize(4,3) #可以看到a发生了改变, a Out[95]: array([[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8], [ 9, 10, 11]])
2.3.8.2数组堆叠
堆叠就是将多个数组沿不同的轴叠在一起
- hstack((a,b)):水平堆叠
- vstack((a,b)):垂直方向堆叠
import numpy as np
a = np.arange(20).reshape(2,10)
b = np.arange(20).reshape(2,10)
#沿垂直方向堆叠
c = np.vstack((a,b))
Out[97]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19],
[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]])
a
Out[98]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]])
#沿水平方向堆叠
d = np.hstack((a,b))
d
Out[100]:
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 1, 2, 3, 4, 5,
6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 10, 11, 12, 13, 14, 15,
16, 17, 18, 19]])
2.3.8.3矩阵拆分
矩阵拆分其实就是数组堆叠的逆向操作,以上面的数据作为例子
#水平方向拆分
data = np.hsplit(d,2)
#可以看到有两个数组对象了
[array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]]),
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]])]
#垂直方向拆分
data2 = np.vsplit(c,2)
Out[104]:
[array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]]),
array([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]])]
2.3.9数组的转置和换轴
2.4副本,浅拷贝和深拷贝
在对数组进行处理的过程中,有的操作会创建新数组,如切片,有的则不会,如将一个数组赋值给另一个变量。
2.4.1副本
在Python中,可变对象是作为引用进行传递的,因此简单的赋值操作不会创建数据的副本。
import numpy as np
a = np.arange(12)
b =a
#可以看到a,b是完全一样的对象
id(a)
Out[106]: 2129275591456
id(b)
Out[107]: 2129275591456
if b is a:
print("a和b是完全一样的对象")
else:
print("a和b不是完全一样的对象")
a和b是完全一样的对象
2.4.2浅拷贝
浅拷贝是指两个数组对象不同,但是数据是共享的,调用view方法并对数组进行切片,可以创建一个对象的浅拷贝副本。有点类似视图。地址不一样,但是数据是共享的。
import numpy as np
a = np.arange(12)
b = a.view()
id(a)
Out[110]: 2129275400880
id(b)
Out[111]: 2129275401280
if b is a:
print("a和b是完全一样的对象")
else:
print("a和b不是完全一样的对象")
a和b不是完全一样的对象
a
Out[113]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
b
Out[114]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
a[5]=100
#浅拷贝因为数据是共享的,所以改变a的值,b的值也发生了变化
a
Out[116]: array([ 0, 1, 2, 3, 4, 100, 6, 7, 8, 9, 10, 11])
b
Out[117]: array([ 0, 1, 2, 3, 4, 100, 6, 7, 8, 9, 10, 11])
2.4.3深拷贝
深拷贝是根据原来的数组创建一个完全独立的副本。在数组上调用copy()方法,完成深拷贝。地址不同,数据不同,你走你的阳关道,我走我的独木桥,互相之间没有联系。
import numpy as np
a = np.arange(12)
b = a.copy()
id(a)
Out[122]: 2129275486976
id(b)
Out[123]: 2129275489616
a
Out[124]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
b
Out[125]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
a[5]=100
a
Out[127]: array([ 0, 1, 2, 3, 4, 100, 6, 7, 8, 9, 10, 11])
b
Out[128]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
2.5数据的存取与函数
2.5.1数据的CSV文件存取
csv(Comma-Separated value ,逗号分隔值),是一种常见的问价格式,用来批量存储数据
-
CSV文件的保存
np.savetxt(frame,array,fmt='%.18e',delimiter=None) frame:文件,字符串或者产生器,可以是.gz或者.bz2的压缩文件 array:存入文件的数组 fmt:写入文件的格式,例如:%d %.2f %.18e delimiter:分割字符串,默认是任何空格 ############################### a = np.arange(100).reshape((5,20)) np.savetxt('a.csv',a,fmt='%d',delimiter=',') -
CSV文件的读取
np.loadtxt(frame,dtype=np.float,delimiter=None,unpack=False) frame:文件,字符串或产生器 dtype:数据类型,可选 unpack:如果为True,读入属性将分别写入不同的变量 ###################### import numpy as np b = np.loadtxt('a.csv',dtype=np.float,delimiter=',') #unpack属性默认为False b Out[245]: array([[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16., 17., 18., 19.], [20., 21., 22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38., 39.], [40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51., 52., 53., 54., 55., 56., 57., 58., 59.], [60., 61., 62., 63., 64., 65., 66., 67., 68., 69., 70., 71., 72., 73., 74., 75., 76., 77., 78., 79.], [80., 81., 82., 83., 84., 85., 86., 87., 88., 89., 90., 91., 92., 93., 94., 95., 96., 97., 98., 99.]]) #unpack=True的情况,读入属性分别写入不同的变量 c = np.loadtxt('a.csv',dtype=np.float,delimiter=',',unpack=True) c Out[247]: array([[ 0., 20., 40., 60., 80.], [ 1., 21., 41., 61., 81.], [ 2., 22., 42., 62., 82.], [ 3., 23., 43., 63., 83.], [ 4., 24., 44., 64., 84.], [ 5., 25., 45., 65., 85.], [ 6., 26., 46., 66., 86.], [ 7., 27., 47., 67., 87.], [ 8., 28., 48., 68., 88.], [ 9., 29., 49., 69., 89.], [10., 30., 50., 70., 90.], [11., 31., 51., 71., 91.], [12., 32., 52., 72., 92.], [13., 33., 53., 73., 93.], [14., 34., 54., 74., 94.], [15., 35., 55., 75., 95.], [16., 36., 56., 76., 96.], [17., 37., 57., 77., 97.], [18., 38., 58., 78., 98.], [19., 39., 59., 79., 99.]]) -
CSV文件的局限性
csv只能有效的存储一维和二维数组,np.savetxt() np.loadtxt()只能有效存取一维和二维数组
2.5.2任意维度的数据的存取
-
任意维度数据的存储
# a.tofile(frame,sep='',format='%s') ###实例 a = np.arange(100).reshape(5,10,2) a.tofile('b.dat',sep=',',format='%d') ##将文件存储为二进制文件,有利于节约空间 -
任意维度数据的取出
# np.fromfile(frame,dtype=float,count=-1,sep=''),count 代表读入元素的个数,-1,代表读入整个文件 ##实例 #count=-1 读取整个文件 a = np.arange(100).reshape((5,10,2)) a.tofile("b.dat",sep=",",format='%d') c = np.fromfile("b.dat",dtype=np.int,sep=",") c Out[258]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99]) #读取50个元素 count=50 d = np.fromfile("b.dat",dtype=np.float,count=50,sep=',') d Out[261]: array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13., 14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25., 26., 27., 28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38., 39., 40., 41., 42., 43., 44., 45., 46., 47., 48., 49.])注意事项:使用tofile fromfile读取的时候需要知道存入文件时的数组的维度和元素类型,否则得到的就是一个一维数组
2.5.3NumPy文件的便捷存取
-
便捷存取
#np.save(fname,array) 或者 np.savez(fname,array) fname:文件名,以.npy为扩展名,压缩文件为.npz ##实例 #1.使用np.save(fname,array)方法 import numpy as np a = np.arange(24).reshape((2,3,4)) np.save("a.npy",a) #使用np.savez(fname,array) np.savez("a.npz",a) #fname建议带上对应的.npy npz -
便捷取出
#np.load(fname) ##实例 np.load("a.npy") Out[275]: array([[[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]], [[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]]) -
注意事项,如果需要保存的文件在其他文件系统也能打开,推荐使用np.tofile 或者np.fromfile 方法来进行存取。np.save和np.load 保存的是.npy格式的数据
2.6NumPy的随机数函数
NumPy的随机数函数子库random子库
#rand(d0,d1,...dn):根据d0-dn创建随机数数组,浮点数,[0,1),均匀分布,d0-dn
指的就是shape
#randn(d0,d1,...,dn):根据d0-dn创建随机数数组,标准正态分布
#randint(low,high,shape):根据shape创建随机整数或整数数组,范围是[low,high)
#seed(s):随机数种子,s是给定的种子值
#shuffle(a):根据数组a的第一轴(列)进行随排列,改变数组X
#permutation(a):根据数组a的第一轴产生一个新的乱序数组,不改变数组X
#choice(a[,size,replace,p]):从一维数组a中以概率p抽取元素,形成size形状新数组,replace表示是否可以重用
#uniform(low,high,size):产生具有均匀分布的数组,low起始值,high结束值,size形状
#normal(loc,scale,size):产生具有正态分布的数组,loc均值,scale标准差,size形状
#poisson(lam,size):产生具有泊松分布的数组,lam随机时间发生率,size形状
#####实例####
#rand的使用
a = np.random.rand(2,2)
a
Out[279]:
array([[0.58467172, 0.52604961],
[0.66992895, 0.4591032 ]])
#randint
b = np.random.randint(0,23,(2,3,4))
b
Out[286]:
array([[[20, 1, 1, 18],
[18, 22, 7, 9],
[ 9, 3, 17, 18]],
[[21, 19, 7, 15],
[20, 11, 2, 6],
[16, 5, 15, 3]]])
#randn的使用
c = np.random.randn(2,2)
c
Out[288]:
array([[ 0.56321604, 0.05785039],
[-1.03794464, 0.25471528]])
#seed(s):
2.7NumPy的统计函数
#sum(a,axis=None):根据给定轴axis计算数组a相关元素之和,axis整数或元组
#mean(a,axis=None):根据给定轴axis计算数组a相关元素的期望,axis整数或元组
#average(a,axis=None,weights=None):根据给定轴axis计算数组a相关元素的加权平均值
#std(a,axis=None):根据给定轴axis计算数组a相关元素的标准差
#var(a,axis=None):根据给定轴axis计算数组a相关元素的方差
#min(a) max(a):计算数组a中的元素最小最大值,注意np.max np.min 和np.amax(),np.amin()是同名函数两者是一样的
#argmin(a) argmax(a):计算数组a中元素的最小值,最大值的降一维后的下标
#unravel_index(index,shape):根据shape将一维下标index转换成多维下标
#ptp(a):计算数组a中元素最大值与最小值的差
#median(a):计算数组a中元素的中位数(中值)
- 最大值与最小值函数-amax,amin
x = np.array([[3,5,1],[6,2,9],[3,4,8]])
x
Out[567]:
array([[3, 5, 1],
[6, 2, 9],
[3, 4, 8]])
np.max(x)
Out[568]: 9
np.min(x)
Out[569]: 1
np.amax(x)
Out[570]: 9
#求数组的最小值
np.amin(x)
Out[571]: 1
#求每一列的最大值
np.amax(x,axis=0)
Out[572]: array([6, 5, 9])
#求每一行的最大值
np.amax(x,axis=1)
Out[573]: array([5, 9, 8])
#求每一列的最小值
np.amin(x,axis=0)
Out[574]: array([3, 2, 1])
#求每一行的最小值
np.amin(x,axis=1)
Out[575]: array([1, 2, 3])
np.max(x,axis=0)
Out[576]: array([6, 5, 9])
- 求最大值与最小值之差函数–ptp
import numpy as np
x = np.array([[3,5,1],[6,2,9],[3,4,8]])
np.ptp(x)
Out[579]: 8
np.subtract(np.amax(x),np.amin(x))
Out[580]: 8
x
Out[582]:
array([[3, 5, 1],
[6, 2, 9],
[3, 4, 8]])
np.ptp(x,axis=0)
Out[583]: array([3, 3, 8])
np.ptp(x,axis=1)
Out[584]: array([4, 7, 5])
np.max(x,axis=1)-np.min(x,axis=1)
Out[585]: array([4, 7, 5])
- 统计百分位函数-percentile
import numpy as np
x = np.array([[3,5,1],[6,2,9],[3,4,8]])
#最小值
np.percentile(x,0)
Out[587]: 1.0
#有50%的数大于4
np.percentile(x,50)
Out[588]: 4.0
np.mean(x)
Out[589]: 4.555555555555555
#最大值
np.percentile(x,100)
Out[590]: 9.0
np.percentile(x,80)
Out[591]: 6.800000000000001
x
Out[592]:
array([[3, 5, 1],
[6, 2, 9],
[3, 4, 8]])
#在每一列上大于50%的数
np.percentile(x,50,axis=0)
Out[593]: array([3., 4., 8.])
- 中位数media 和平均数mean
import numpy as np
x = np.array([[3,5,1],[6,2,9],[3,4,8]])
x
Out[595]:
array([[3, 5, 1],
[6, 2, 9],
[3, 4, 8]])
#求纵的中位数
np.median(x)
Out[596]: 4.0
#求每一列的中位数
np.median(x,axis=0)
Out[597]: array([3., 4., 8.])
#求每一行的中位数
np.median(x,axis=1)
Out[599]: array([3., 6., 4.])
#求总的平均数
np.mean(x)
Out[600]: 4.555555555555555
#求每一列的平均数
np.mean(x,axis=0)
Out[602]: array([4. , 3.66666667, 6. ])
#求每一行的平均数
np.mean(x,axis=1)
Out[603]: array([3. , 5.66666667, 5. ])
-
加权平均函数-average
在没有权重的情况下,averge()和mean()等效。
import numpy as np
x = np.array([78,89,56,70,90])
np.average(x)
Out[606]: 76.6
np.mean(x)
Out[607]: 76.6
w = np.array([5,3,2,1,4])
#weights 为权重,x为每一项的值
np.average(x,weights=w)
Out[609]: 79.93333333333334
-
方差函数var与标准差函数std
统计中的方差是每个样本值与全体样本值的平均数之差的平方值的平均数。表示一组数据的离散程度。方差是衡量源数据和期望值相差的度量值。
import numpy as np
x = np.array([5,6,2,7,9,4])
x
Out[611]: array([5, 6, 2, 7, 9, 4])
np.var(x)
Out[612]: 4.916666666666667
np.std(x)
Out[613]: 2.217355782608345
x = np.array([[1,4,5],[7,3,6],[5,8,2]])
np.var(x)
Out[615]: 4.6913580246913575
x
Out[616]:
array([[1, 4, 5],
[7, 3, 6],
[5, 8, 2]])
np.std(x)
Out[617]: 2.165954298846436
np.var(x,axis=0)
Out[618]: array([6.22222222, 4.66666667, 2.88888889])
np.std(x,axis=0)
Out[619]: array([2.49443826, 2.1602469 , 1.69967317])
2.8排序函数
-
sort
sort函数,sort(a,axis=-1,kind=‘quicksort’,order=None),默认情况下使用的是快速排序,在kind里可以指定quicksort,mergesort,heapsort分别表示快速排序,合并排序,堆排序,同样axis默认是-1,即沿着数组的最后一个轴进行排序,也可以取不同的axis轴,或axis=None代表采用扁平化的方式作为一个向量进行排序。另外order字段,对于结构化的数组可以指定按照某个字段进行排序。
import numpy as np x = np.array([[3,9,5],[4,2,8],[6,2,7]]) x Out[621]: array([[3, 9, 5], [4, 2, 8], [6, 2, 7]]) #排序 np.sort(x) Out[622]: array([[3, 5, 9], [2, 4, 8], [2, 6, 7]]) #采用扁平化向量进行排序,将数组中的所有元素取出,并返回一维数组,ravel()返回的也是一维数组 np.sort(x,axis=None) Out[623]: array([2, 2, 3, 4, 5, 6, 7, 8, 9]) #指定0轴进行排序 np.sort(x,axis=0) Out[624]: array([[3, 2, 5], [4, 2, 7], [6, 9, 8]]) #指定1轴排序 np.sort(x,axis=1) Out[625]: array([[3, 5, 9], [2, 4, 8], [2, 6, 7]])注意:sort方法有两个,一个是数组对象上的,另一个是np模块上的,在数组对象上调用sort会对数组本身进行排序,调用np模块上的sort,则会返回该数组对象的副本,意味着创建一个新的数组,这个数组是默认排了序的。
-
lexsort
lexsort方法并不具备排序功能。调用该方法返回的是参数中最后一个数据内各个元素的排序位置,就是最后一个参数,按照从小到大排序,然后最后一个参数各个元素在排序中的位置
import numpy as np a = [7,6,5,4,3,10,12,15] b = [9,4,0,4,0,2,1,7] #数组a从小到大排序后,[7,6,5,4,3,10,12,15]对应排序后的索引 ind = np.lexsort((b,a)) ind Out[177]: array([4, 3, 2, 1, 0, 5, 6, 7], dtype=int64)
2.9练习题
题目一:
题目:假设一个团队有5名成员,用NumPy统计他们语文,英语和数学的平均成绩,最小成绩,最大成绩,方差和标准差,然后按照总成绩排序,得出名词,输出成绩
name chinese math english
mike 95 80 78
alice 87 90 80
greem 93 78 72
brown 89 95 84
brian 60 90 89
import numpy as np
stutype = np.dtype({
'names':['name','chinese','math','english'],
'formats':['S32','i','i','i','i']})
student = np.array([('mike',95,80,78),
('alice',87,90,80),
('green',93,78,72),
('brown',89,95,84),
('brian',60,90,89)],dtype=stutype)
chinese =student[:]['chinese']
math = student[:]['math']
english = student[:]['english']
def show(name, subject):
print("{} | {:^6.2f} | {:^6.1f} | {:^6.1f} | {:^6.2f} | {:^6.2f}".format(name, np.mean(subject), np.amax(subject), np.amin(subject), np.var(subject), np.std(subject)))
print('科目 | 平均分 | 最高分 | 最低分 | 方差 | 标准差')
show('语文', chinese)
show('数学', math)
show('英语', english)
科目 | 平均分 | 最高分 | 最低分 | 方差 | 标准差
语文 | 84.80 | 95.0 | 60.0 | 161.76 | 12.72
数学 | 86.60 | 95.0 | 78.0 | 42.24 | 6.50
英语 | 80.60 | 89.0 | 72.0 | 32.64 | 5.71
print()
print("姓名 | 语文 | 数学 | 英语 | 总分")
rankings = sorted(students, key=lambda x: x[1]+x[2]+x[3])
for ranking in rankings:
print("{:5s}|{:^6d}|{:^6d}|{:^6d}|{:^6d}".format(ranking['name'].decode('utf-8'), ranking['chinese'], ranking['math'], ranking['english'], ranking['chinese'] + ranking['math'] + ranking['english']))
题目二:
二维随机数组取绝对值
import numpy as np
data = np.random.randn(4,6)
data
Out[641]:
array([[ 0.95593331, -1.24321394, -0.41298119, 0.1510108 , -0.19547011,
0.0179664 ],
[ 0.54345952, 0.88116353, -1.134722 , 0.84811375, -1.05799666,
-1.61739266],
[-0.24910339, 0.39643505, 1.73386551, -1.03293167, 0.2068804 ,
-1.21637953],
[-0.10236568, 2.19339136, -1.3658328 , -0.18960368, -1.02919397,
0.35779655]])
x=data[data<0]
x=-x
#因为改变的是切片数组的全部,所以这里可以看到,没有影响到原数组
data
Out[644]:
array([[ 0.95593331, -1.24321394, -0.41298119, 0.1510108 , -0.19547011,
0.0179664 ],
[ 0.54345952, 0.88116353, -1.134722 , 0.84811375, -1.05799666,
-1.61739266],
[-0.24910339, 0.39643505, 1.73386551, -1.03293167, 0.2068804 ,
-1.21637953],
[-0.10236568, 2.19339136, -1.3658328 , -0.18960368, -1.02919397,
0.35779655]])
data[data<0]=x
data
Out[646]:
array([[0.95593331, 1.24321394, 0.41298119, 0.1510108 , 0.19547011,
0.0179664 ],
[0.54345952, 0.88116353, 1.134722 , 0.84811375, 1.05799666,
1.61739266],
[0.24910339, 0.39643505, 1.73386551, 1.03293167, 0.2068804 ,
1.21637953],
[0.10236568, 2.19339136, 1.3658328 , 0.18960368, 1.02919397,
0.35779655]])
方法二:利用np.abs()函数取绝对值
import numpy as np
data = np.random.randn(4,6)
data
Out[650]:
array([[-0.85783135, -0.35697099, 0.59453269, -0.02407261, -0.21333584,
-1.4332221 ],
[ 0.97727582, 0.46054766, 0.19163158, 1.48421142, 2.26340499,
1.48558869],
[ 0.25387725, 0.06926861, 0.39742798, 1.00818912, 0.64062271,
2.54294398],
[ 1.55840775, -0.43021727, -0.45668688, -0.19822388, -0.41936749,
-0.32265377]])
np.abs(data)
Out[651]:
array([[0.85783135, 0.35697099, 0.59453269, 0.02407261, 0.21333584,
1.4332221 ],
[0.97727582, 0.46054766, 0.19163158, 1.48421142, 2.26340499,
1.48558869],
[0.25387725, 0.06926861, 0.39742798, 1.00818912, 0.64062271,
2.54294398],
[1.55840775, 0.43021727, 0.45668688, 0.19822388, 0.41936749,
0.32265377]])
题目三:求解三元一次方程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oAhCI2HE-1596355463888)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1594301731451.png)]
2.10NumPy的梯度函数
梯度:连续值之间的变化率,即斜率
XY坐标轴连续三个x坐标对应Y轴值:a,b,c,其中b的梯度是:(c-a)/2
#np.gradient(f):计算数组f中元素的梯度,当f为多维的时候,返回每个维度的梯度
##实例
2.11NumPy的数学函数
- add:加法
- subtract:减法
- multiply:乘法
- divide:除法(/带小数点的除法)
- power:幂运算
- remainder:模运算
import numpy as np
a = np.arange(1,10,2)
a
Out[554]: array([1, 3, 5, 7, 9])
b = np.linspace(2,10,5)
b
Out[556]: array([ 2., 4., 6., 8., 10.])
print("a+b=",np.add(a,b))
a+b= [ 3. 7. 11. 15. 19.]
print("a-b=",np.subtract(a,b))
a-b= [-1. -1. -1. -1. -1.]
print("a*b=",np.multiply(a,b))
a*b= [ 2. 12. 30. 56. 90.]
print("a/b=",np.divide(a,b))
a/b= [0.5 0.75 0.83333333 0.875 0.9 ]
print("a**b=",np.power(a,b))
a**b= [1.0000000e+00 8.1000000e+01 1.5625000e+04 5.7648010e+06 3.4867844e+09]
print("a mod b=",np.remainder(a,b))
a mod b= [1. 3. 5. 7. 9.]
2.12单元小结
文件的存取
-
CSV文件
np.loadtxt()
np.savetxt()
-
多维数据存取
a.tofile() np.fromfile()
np.save() np.savez() np.load
随机函数
-
np.random.rand() ;np.random.randn();np.random.randint();np.random.seed();
np.random.shuffle();np.random.permutation();np.random.choice()
NumPy的统计函数
- np.sum() np.min() np.mean() np.max() np.average() np.argmin() np.std() np.argmax() np.var() np.unravel_index() np.median() np.ptp()
NumPy的梯度函数
- np.gradient()
2.13NumPy总结
在本章我们主要要掌握以下五个方面的知识
- NumPy基础
- 数据的属性
- 数据类型
- 创建数组的方法
- 基本操作
- 索引,切片和迭代
- 形状操作
- 更改形状
- 数据堆叠
- 矩阵拆分
- 副本,浅拷贝和深拷贝
- 副本
- 浅拷贝
- 深拷贝
- 高级索引
- 通过数组索引
- 通过布尔索引
- 通过ix()函数索引
- 排序统计
- 排序
- 统计
第四章图像的数组表示
4.1RGB色彩模式
图像一般使用RGB色彩模式,即每个像素点的颜色由红®,绿(G),蓝(B)组成
RGB三个颜色通道的变化和叠加得到各种颜色,三种颜色的取值范围为0-255
RGB形成的颜色包括了人类实例所能感知的所有颜色
4.2PIL库
PIL库是一个具有强大图像处理能力的第三方库,在命令行下的安装方法:pip install pillow
PIL库的导入:from PIL import Image Image是PIL库代表一个图像的类(对象)
图像可以是一个由像素组成的二维矩阵,每个元素是一个RGB值
4.2.1图像的数组表示
from PIL import Image
import numpy as np
im = np.array(Image.open("C:/myNote/data_analyse/python_code/a.jpg"))
#输出对象的尺度,和每个元素的元素类型
print(im.shape,im.dtype)
#(454, 680, 3) uint8
#由此可以看出图像是一个三维数组,维度分别是高度,宽度(行)和像素RGB值
#rgb 共680行,454层
#注意地址只能写/ 不能写\?
#np.array 除了可以将元组和列表转为ndarray数组,也可以将图像转为ndarray数组
4.2.2图像的变换
变换的流程
- 读入图像
- 获取像素RGB值
- 对像素RGB进行修改得到一个新的数组
- 修改后保存为新的文件
图像变换的实例
例子一
from PIL import Image
import numpy as np
#1.读入图像,使用Image.open()方法
a = np.array(Image.open("C:/myNote/data_analyse/python_code/a.jpg"))
print(a.shape,a.dtype)
#将每个RGB值取反
b =[255,255,255] -a
#调用数组b的astype方法,创建一个新的数组,并修改b的dtype属性,Image.fromarray() 返回一个图片对象
im =Image.fromarray(b.astype('uint8'))
#保存修改后的图片
im.save("C:/myNote/data_analyse/python_code/a1.jpg")
例子二
from PIL import Image
impot numpy as np
#打开图片,并转换为数组
a = np.array(Image.open("C:/myNote/data_analyse/python_code/a.jpg").convert('L'))
#输出a 的尺度和元素类型
print(a.shape,a.dtype)#(454, 680) uint8 可以看出经过convert后 数组a成为了一个二维数组,每个像素点由一位组成
#对转换后的图片数组进行像素操作
b=255-a
im =Image.fromarray(b.astype('uint8'))
#保存图片
im.save("C:/myNote/data_analyse/python_code/a2.jpg")
例子三图像的区间变换
from PIL import Image
import numpy as np
#打开图片
a = np.array(Image.open("C:/myNote/data_analyse/python_code/a.jpg").convert('L'))
#输出a的尺度和元素类型
print(a.shape,a.dtype)
#区间变换
c = (100/255)*a+150
#保存
im = Image.fromarray(c.astype('uint8'))
im.save("C:/myNote/data_analyse/python_code/a3.jpg")
例子四图像的像素平方
from PIL import Image
import numpy as np
#打开图片
a = np.array(Image.open("C:/myNote/data_analyse/python_code/a.jpg").convert('L'))
#像素的平方
d = 255*(a/255)**2
im = Image.fromarray(d.astype('uint8'))
#保存图片
im.save("C:/myNote/data_analyse/python_code/a4.jpg")
4.2.3Image中convert(model)函数的讲解
convert()是图像实例对象的一个方法,接受一个model参数,用于指定一种色彩模式,共有9中色彩模式,也就是model参数的值
- 1:1位像素,黑白,每个字节一个像素存储
- L:8位像素,黑白,二维数组
- P:8位像素,使用调色板映射到任何其他的模式
- RGB:3*8位像素,真彩色
- RGBA:带透明度掩模的真彩色
- CMYK:分色
- YCbCr:3*8位像素,彩色视频格式
- I:32位有符号整数像素
- F:32位浮点像素
4.24图像的手绘效果案例
手绘效果几个特征
- 黑白灰色
- 边界线条较重
- 相同或相近色彩趋于白色
- 略有光源效果
手绘效果实例分析
梯度的重构:利用像素之间的梯度值和虚拟深度值对图像进行重构,根据灰度变化来模拟人类视觉的明暗程度
图像的手绘效果代码
from PIL import Image
import numpy as np
#将图像设置成灰色
a = np.array(Image.open("C:\\myNote\\data_analyse\\python_code\\b.jpg").convert('L')).astype('float')
#(0-100),设置深度
depth = 10.
#取图像灰度的梯度值
grad = np.gradient(a)
#分别取横纵图像的梯度值,depth归一化
grad_x,grad_y = grad
grad_x = grad_x*depth/100.
grad_y =grad_y*depth/100.
A = np.sqrt(grad_x**2 + grad_y**2 +1.)
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1./A
#光源的俯视角度,弧度值
vec_el = np.pi/2.2
#光源的方位角度,弧度值
vec_az = np.pi/4.
#光源对X轴的影响
dx = np.cos(vec_el)*np.cos(vec_az)
#光源对y轴的影响
dy = np.cos(vec_el)*np.sin(vec_az)
#光源对Z轴的影响
dz = np.sin(vec_el)
#光源归一化
b = 255*(dx*uni_x+dy*uni_y+dz*uni_z)
#为避免数据越界,将生成的灰度值裁剪至0-255之间
b = b.clip(0,255)
#重构图像
im =Image.fromarray(b.astype('uint8'))
#保存图像
im.save("C:\\myNote\\data_analyse\\python_code\\b1.jpg")
第五章数据可视化之Matplotlib
5.1可视化视图分类
-
按照数据之间的关系分类
-
比较
比较数据间各类别的关系,或者是它们随时间变化的趋势,比如折线图
-
联系
查看两个或两个以上变量的关系,比如散点图
-
构成
每个部分占整体的百分比,或者随着时间的百分比变化,比如饼图
-
分布
关注单个变量或者多个变量的分布情况,比如直方图
-
-
按照变量的个数分类
-
单变量分析
一次只关注一个变量
-
多变量分析
一张图上可以查看两个以上变量的关系
-
-
常见的可视化视图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AfHfSnka-1596355463890)(C:\myNote\data_analyse\python_code\常见的可视化视图.PNG)]
Matplotlib是Python优秀的数据可视化第三方库
5.2Matplotlib库的使用
Matplotlib库是由各种可视化类构成的,内部结构复杂,受Matlab启发,matplotlib.pyplot是绘制各类可视化图形的命令的子库,相当于快捷方式。
导入
import matplotlib.pyplot as plt
#牛刀小试
importmatplotlib.pyplot as plt
#plt.plot()只有一个输入列表或者数组时,参数被当作Y轴,X轴以自动索引自动生成
plt.plot([3,1,4,5,2])
#给Y轴起个名字
plt.ylabel("Grade")
#将文件进行保存,文件默认为PNG格式,可以通过dpi修改输出质量,dpi指的是每一英寸的像素点
plt.savefig('test',dpi=600)
plt.show()
######################################################
#Matplotlib小测综合
import matplotlib.pyplot as plt
#注意这两个列表必须保证维度相同,当plt.plot(X,y)由两个参数以上是,按照X轴(第一个列表)和Y轴(第二个列表)绘制数据点
plt.plot([0,2,4,6,8],[3,1,4,5,2])
plt.ylabel("Grade")
#代表X轴范围[-1,10],Y轴范围[0,6]
plt.axis([-1,10,0,6])
plt.savefig('test1',dpi=600)
plt.show()
5.3pyplot的绘图区域
subplot:在全局绘图区域中创建一个分区体系,并定位到一个子绘图区域
#plt.subplot(nrows,ncols,plot_number)
以下例子中总共分为6块,横轴(X)分为三块,切两刀,纵轴分两块,切一刀,从左上方开始一次排序
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mpyhEMrw-1596355463892)(C:\myNote\data_analyse\python_code\pyplot的绘图区域.PNG)]
import numpy as np
import matplotlib.pyplot as plt
def f(t):
return np.exp(-t)*np.cos(2*np.pi*t)
a = np.arange(0.0,5.0,0.02)
plt.subplot(211)
plt.plot(a,f(a))
plt.subplot(2,1,2)
plt.plot(a,np.cos(2*np.pi*t2),'r--')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DKTTf5vx-1596355463893)(C:\myNote\data_analyse\python_code\pyplot的绘图区域1.PNG)]
5.4pyplot的plot()函数
格式
plt.plot(x,y,format_string,**kwargs)
X:x轴数据,列表或数组,可选,当绘制多条曲线的时候,各曲线的x不能省略
Y:Y轴数据,列表或数组,注意X轴和Y轴的维度要一致
format_string:控制曲线的格式字符串,可选
**kwargs:第二组或更多(x,y,format_string)
color:控制颜色,color='green'
linestyle:线条风格,linestyle='dashed'
marker:标记风格,marker='o'
markerfacecolor:标记颜色,markfacecolor='blue'
markersize:标记尺寸,markersize=20
绘制多条曲线例子
import matplotlib.pyplot as plt
import numpy as np
a = np.arange(10)
#总共四条曲线
plt.plot(a,a*1.5,a,a*2.5,a,a*3.5,a,a*4.5)
plt.ylabel("Grade")
plt.savefig("C:\\myNote\\data_analyse\\python_code\\test",dpi=600)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4PBx6ri-1596355463895)(C:\myNote\data_analyse\python_code\test.png)]format_string:控制曲线的格式字符串,可选由颜色字符,风格字符和标记字符组成
-
颜色字符
'b': 'm':洋红色 magenta 'g': 'y' 'r' 'K':黑色 'c':青绿色 cyan 'w':白色 '#008000':RGB某颜色 '0.8':灰度值字符串 -
风格字符
'-':实线 '--':破折线 '-.':点划线 ':':虚线 """:无线条 -
标记字符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4ACSosui-1596355463896)(C:\myNote\data_analyse\python_code\标记字符.PNG)]
format_string的实例
import matplotlib.pyplot as plt
import numpy as np
#生成0-9的数组
a = np.arange(10)
plt.plot(a,a*1.5,'y-h',a,a*2.5,'cH-.',a,a*3.5,'mo--',a,a*4.5,'s')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DyLH1yth-1596355463898)(C:\myNote\data_analyse\python_code\format_string实例.png)]
5.5pyplot的中文显示
-
第一种方法:rcParams修改字体实现,这样修改是全局的效果
rcParams的属性
- ‘font.family’:用于显示字体的名字
- ‘font.style’:字体风格,正常’normal’或斜体’italic’
- ‘font.size’:字体大小,整数字号或者’large’,‘x-small’
中文字体的种类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2Met4g8K-1596355463900)(C:\myNote\data_analyse\python_code\中文字体的种类.PNG)]
import matplotlib.pyplot as plt import matplotlib #设置字体为雅黑 matplotlib.rcParams['font.family']='SimHei' #设置字体风格为斜体 matplotlib.rcParams['font.style']='italic' #设置字号large matplotlib.rcParams['font.size']=20 #红色破折线 plt.plot([3,1,4,5,2],'r--') plt.ylabel("纵轴值") plt.xlabel("横轴值") plt.savefig('test',dpi=600) plt.show() -
pyplot的中文显示:第二种方法(推荐使用)
在有中文输出的地方,增加一个属性
fontpropertiesimport numpy as np import matplotlib.pyplot as plt a = np.arange(0.0,5.0,0.02) plt.xlabel("横轴:时间",fontproperties='SimHei',fontsize=20) plt.ylabel("纵轴:振幅",fontproperties="SimHei",fontsize=20) plt.plot(a,np.cos(2*np.pi*a),"r--") plt.show()
5.6pyplot的文本显示函数
- plit.xlabel():对x轴增加文本标签
- plt.ylabel():对轴增加文本标签
- plt.title():对图形整体增加文本标签
- plt.text():在任意位置增加文本
- plt.annotate():在图形中增加带箭头的注解
import numpy as np
import matplotlib.pyplot as plt
a = np.arange(0.0,5.0,0.02)
plt.plot(a,np.cos(2*np.pi*a),"r--")
plt.xlabel("横轴:时间",fontproperties='SimHei',fontsize=15,color='green')
plt.ylabel("纵轴:振幅",fontproperties='SimHei',fontsize=15)
plt.title(r'正弦波实例$y=cos(2\pi x)$',fontproperties='SimHei',fontsize=25)
#$...$指的是Latex一种基于tex的排版系统,在x=2 y=1的坐标位置上做标记
plt.text(2,1,r'$\mu=100$',fontsize=15)
plt.axis=([-1,6,-2,2])
#plt.grid(True)=plt.grid(1)显示网格线1=True
plt.grid(True)
plt.show()
########################################
import numpy as np
import matplotlib.pyplot as plt
a = np.arange(0.0,5.0,0.02)
plt.plot(a,np.cos(2*np.pi*a))
plt.xlabel("横轴:时间",fontproperties='SimHei',fontsize=25,color='green')
plt.ylabel("纵轴:振幅",fontproperties='SimHei',fontsize=25)
plt.title(r'正弦波实例$y=cos(2\pi x)$',fontproperties='SimHei',fontsize=25)
#plt.annotate(r'$\mu=100$',xy=(2,1),xytext(3,1.5),arrowprops= dict(facecolor='black',shrink=0.1,width=2))
plt.axis=([-1,6,-2,2])
plt.grid(1)
plt.show()
5.7pyplot的子绘图区域
plt.subplot2grid()
例子:
import matplotlib.pyplot as plt
#3行3列,从0行0列开始,列合并3列
ax1 = plt.subplot2grid((3,3),(0,0),colspan=3)
#3行3列的总大小。从第二行开始(0为第一行),列合并2
ax2 = plt.subplot2grid((3,3),(1,0),colspan=2)
#第三列开始行合并2
ax3 =plt.subplot2grid((3,3),(1,2),rowspan=2)
ax4 = plt.subplot2grid((3,3),(2,0))
ax5 =plt.subplot2grid((3,3),(2,1))
plt.title('pyplot子绘图区域',fontproperties='SimHei',color='green')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bcVfAqMi-1596355463902)(C:\myNote\data_analyse\python_code\pyplot的子绘图区域.png)]
GridSpec类
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
gs = gridspec.GridSpec(3,3)
ax = plt.subplot(gs[0,:])
ax2 = plt.subplot(gs[1,:-1])
ax3 = plt.subplot(gs[1:,-1])
ax4 =plt.subplot(gs[2,0])
ax5 = plt.subplot(gs[2,1])
#此图的效果和上面的图效果一样
5.8单元小结
Matplotlib库的入门,介绍了pyplot子库的使用,
5.9pyplot的基础图表函数
pyplot的基础图标函数
plt.plot(x,y,fmt,..):绘制一个坐标图
plt.boxplot(data,notch,position):绘制一个箱型图
plt.bar(left,height,width,bottom):绘制一个条形图
plt.barh(width,bottom,left,height):绘制一个横向条形图
plt.polar(theta,r):绘制极坐标图
plt.pie(data,explode):绘制饼图
plt.psd(x,NFFT=256,pad_to,Fs):绘制功率谱密度图
plt.specgram(x,NFFT=256,pad_to,F):绘制谱图
plt.cohere(x,y,NFFT=256,Fs):绘制X-Y的相关性函数
plt.scatter(x,y):其中x,y长度要相等
plt.step(x,y,where):绘制步阶图
plt.hist(x,bins,normed):绘制直方图
plt.contour(X,Y,Z,N):绘制等值图
plt.vlines():绘制垂直图
plt.stem(x,Y,linefmt,markerfmt):绘制柴火图
plt.plot_date():绘制数据日期
5.9.1饼图的绘制
饼图的常见属性
plt.pie(x,lexplode,labels=None…)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gxHt6C9R-1596355463904)(C:\myNote\data_analyse\python_code\饼图的常见属性.PNG)]
import matplotlib.pyplot as plt
#将饼图分为四个部分,每部分的名称
labels ='Frogs','Hogs','Dogs','Logs'
#每个部分的大小,合计100
sizes =[15,30,45,10]
#第二个部分往外突出0.1
explode =(0,0.1,0,0)
plt.pie(sizes,explode=explode,labels=labels,autopct='%1.1f%%',shadow=False,startangle=90)
#要为圆形饼图使用plt.axis('equal'),默认为椭圆形
plt.axis('equal')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dBRaFsQ9-1596355463905)(C:\myNote\data_analyse\python_code\饼图.PNG)]
5.9.2直方图的绘制
直方图常见的参数属性
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-667dIGZr-1596355463906)(C:\myNote\data_analyse\python_code\直方图常见的参数属性.PNG)]
import numpy as np
import matplotlib.pyplot as plt
#设置随机因子
np.random.seed(0)
#均值和标准差
mu,sigma =100,20
a = np.random.normal(mu,sigma,size=100)
#alpha指的是透明度,0-1之间
plt.hist(a,20,normed=1,histtype='stepfilled',facecolor='b',alpha=0.75)
plt.title('Histogram')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EIEgLwz7-1596355463907)(C:\myNote\data_analyse\python_code\直方图.PNG)]
5.9.3极坐标图的绘制
import numpy as np
import matplotlib.pyplot as plt
N =20
theta = np.linspace(0.0,2*np.pi,N,endpoint=False)
radii = 10*np.random.rand(N)
width = np.pi/4*np.random.rand(N)
ax = plt.subplot(111,projection='polar')
bars =ax.bar(theta,radii,width=width,bottom=0.0)
for r,bar in zip(radii,bars):
bar.set_facecolor(plt.cm.viridis(r/10.))
bar.set_alpha(0.5)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-esoVUsXP-1596355463909)(C:\myNote\data_analyse\python_code\极坐标图的绘制.PNG)]
5.9.4散点图的绘制
import numpy as np
import matplotlib.pyplot as plt
fig,ax =plt.subplots()
ax.plot(10*np.random.randn(100),10*np.random.randn(100),'o')
ax.set_title('Simple Scatter')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-any47l9q-1596355463910)(C:\myNote\data_analyse\python_code\散点图的绘制.PNG)]
5.9.5实训引力波的绘制
在物理学中,引力波是因为时空弯曲对外以辐射形式传播的能量,爱因斯坦基于广义相对论预言了引力波的存在。
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
#从配置文档中读取时间相关数据
rate_h,hstrain=wavfile.read(r"C:\\myNote\\data_analyse\\Gravitational_wave\\H1_Strain.wav","rb")
rate_l,lstrain =wavfile.read(r"C:\\myNote\data_analyse\\Gravitational_wave\\L1_Strain.wav","rb")
reftime,ref_H1 = np.genfromtxt("C:\\myNote\\data_analyse\\Gravitational_wave\\wf_template.txt").transpose
#读取应变数据
htime_interval =1/rate_h
ltime_interval =1/rate_l
htime_len =hstrain.shape[0]/rate_h
htime =np.arange(-htime_len/2,htime_len/2,htime_interval)
ltime_len = lstrain.shape[0]/rate_l
ltime =np.arange(-ltime_len/2,ltime_len/2,ltime_interval)
#绘制H1 Strain
fig = plt.figure(figsize=(12,6))#创建一个大小为12*6的绘图空间
plth = fig.add_subplot(221)
plth.set_xlabel("Time(seconds)")
plth.set_ylabel("H1 Strain")
plth.set_title("H1 Strain")
#绘制L1 Strain &Template
pltl =fig.add_subplot(222)
pltl.plot(ltime,lstrain,'g')
pltl.set_xlabel('Time(seconds)')
pltl.set_ylabel('L1 Strain')
pltl.set_title('L1 Strain')
pltref =fig.add_subplot(212)
pltref.plot(reftime,ref_H1)
pltref.set_xlabel('Time(seconds)')
pltref.set_ylabel('Template Strain')
pltref.set_title('Template')
fig.tight_layout()
fig.tight_layout()
plt.savefig("C:\\myNote\\data_analyse\\Gravitational_wave\\Gravitational_Waves_Original.PNG")
plt.show()
plt.close(fig)
第六章Pandas入门
在数据分析工作中,Pandas使用频率很高,一方面是因为Pandas提供的基础数据结构DataFrame与JSON契合度高,转换起来方便,对于不太复杂的日常数据清理工作,通常几句Pandas代码就可以对数据进行规整。
Pandas是Python第三方库,提供高性能易用数据类型和分析工具,Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用。
Pandas库的理解
两个数据数据:Series(序列),DataFrame(数据帧)
两种数据结构的比较
-
序列
序列是一维数组,是包含同种数据类型的数组,其中数据类型可以是整数型,浮点型,大小固定
-
数据帧
数据帧是二维数组,可以理解成一个二维的表格,包含多个列,每一列的内部数据类型相同,列于列之间的类型可以不同,大小可变。
基于上述数据类型的各类操作:基本操作,运算操作,特征类操作,关联类操作。
Pandas库和NumPy的理解:
NumPy:是基础数据类型,关注的数据的结构表达,维度:数据间关系
Pandas:扩展的数据类型,关注数据的应用表达,表达是数据与索引之间关系。
6.1Series类型
Series类型是由一组数据多个相关的数据的索引组成的,默认中的自动索引是从0开始的。Series是个定长的字典序列,存储时相当于两个ndarray,这是与字典结构最大的不同,因为字典结构里,元素个数是不固定的。
注意:Series元素的类型可以不一致,就像NumPy的数组,元素类型可以不同。
Series类型的两个重要属性:index 与 value,index默认是从0开始的整数序列,当然也可以子集指定索引。
序列包含两个对象:索引和数据。Pandas调用Series方法创建序列,Series方法包含多个参数,其中常用的参数有
- data:用于创建序列对象的原始数据,可以是列表,字典等数据结构
- index:索引也称为标签,通过索引可以确定序列中具体的元素,类似于访问数组元素的下标。
- dtype:序列中的数据类型,如果在创建的时候没有指定数据类型,该方法将自动推断类型。
- copy:是否创建数据副本,默认为False
6.1.1Series类型的创建
-
Python列表,index与列表元素个数一致,可以不写,默认从0号索引开始
#Pandas库的导入 import pandas as pd #从列表创建Series类型,没写索引index属性的话。索引默认从0开始。 a = pd.Series([9,8,7,6]) a Out[12]: 0 9 1 8 2 7 3 6 dtype: int64 ############################################################## #指定索引为a,b,c,d,索引元素如果和Series元素个数不相等的话会报错 b = pd.Series([9,8,7,6],index=['a','b','c','d']) b Out[14]: a 9 b 8 c 7 d 6 dtype: int64 -
标量值,index表达Series类型的尺寸,表达Series类型的元素个数,建议都要要写
import pandas as pd #标量值创建Series类型数据,index不建议省略,否则Series元素个数就是一个,默认索引为0。 a =pd.Series(25,index=[0,1,2,3,4]) a Out[20]: 0 25 1 25 2 25 3 25 4 25 dtype: int64 ########################################## import pandas as pd b = pd.Series(25) b Out[23]: 0 25 dtype: int64 -
Python字典,键值对中的键是索引,index从字典中进行选择操作
import pandas as pd #使用字典创建Series类型 d = pd.Series({ 'a':9,'b':8,'c':7}) d Out[25]: a 9 b 8 c 7 dtype: int64 #使用index,指定索引,注意这里的输出顺序是按照索引顺序来的,如果对应索引位置上的键没有对应的值,则为NAN e =pd.Series({ 'a':9,'b':8,'c':7},index=['d','c','b','a']) e Out[27]: d NaN c 7.0 b 8.0 a 9.0 dtype: float64 -
ndarray数组,索引和数据都可以通过ndarray类型创建
import numpy as np import pandas as pd n = pd.Series(np.arange(5)) n Out[31]: 0 0 1 1 2 2 3 3 4 4 dtype: int32 ###索引和数据都通过ndarray创建 m = pd.Series(np.arange(5),index=np.arange(9,4,-1)) m Out[33]: 9 0 8 1 7 2 6 3 5 4 dtype: int32 -
其他函数,range()函数等。
6.1.2Series类型的基本操作
-
Series类型包括index和value两个部分
#.index 获得索引 .value 获得数据 import pandas as pd b = pd.Series([9,8,7,6],index=['a','b','c','d']) #.index 获得索引 b.index Out[45]: Index(['a', 'b', 'c', 'd'], dtype='object') #.values 获得数据 b.values Out[46]: array([9, 8, 7, 6], dtype=int64) #通过索引获取指定的元素,自动索引和自定义的索引是并存的但是两套索引不能混用 b['b']#8 b[1]#8 #这种混用的方法是错误的 b[['c','d',0]] b[['c','c','a']] Out[55]: c 7 d 6 a 9 dtype: int64 -
Series类型的操作类似ndarray类型
- 索引方法相同,采用[]
- NumPy中运算和操作可用于Series类型
- 可以通过自定义的列表进行切片
- 可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
import pandas as pd #索引方法相同,采用[] b = pd.Series([9,8,7,6],['a','b','c','d']) b['b'] Out[61]: 8 #使用自动索引进行切片,注意和使用自定义索引切片的区别,不知道是不是Bug?照道理b[:3]的切片结果应该是b[:'d'],切片还是尽量使用自动索引切片吧 b[:3] Out[62]: a 9 b 8 c 7 dtype: int64 b[:'d'] Out[63]: a 9 b 8 c 7 d 6 dtype: int64 b[:'c'] Out[64]: a 9 b 8 c 7 dtype: int64 #NumPy中的运算符用于Series类型 #计算中位值 b[b>b.median()] Out[65]: a 9 b 8 dtype: int64 #计算以e为底的指数值 np.exp(b) Out[68]: a 8103.083928 b 2980.957987 c 1096.633158 d 403.428793 dtype: float64 -
Series类型的操作类似Python字典类型
- 通过自定义索引进行访问
- 保留字in操作
- 使用.get()方法
import pandas as pd b = pd.Series([9,8,7,6],index=['a','b','c','d']) #注意这个index=可以省略,直接这样写,但是要注意,如果索引个数和元素个数不对等,还是会报错的 #b =pd.Series([9,8,7,6],['a','b','c','d']) #通过自定义的索引访问 b['b']#8 #保留字in操作,注意如果使用的自定义的索引,使用in是判断索引对应的值是否在Series中,如果使用的是自动索引是判断的是内容在不在Series中,所以0 in b 返回的是False 'c' in b #True 0 in b#False #若没有f 索引则返回100,若存在索引对应的值则返回对应的值 b.get('f',100)#100 b.get('d',100)#6 b.get(3,100)#6 -
Series类型的对齐操作
Series类型在运算中会自动对齐不同索引的数据。
import pandas as pd a = pd.Series([1,2,3], ['c','b','e']) b = pd.Series([9,8,7,6], ['a','b','c','d']) #计算出来的结果是浮点型,如果任意一个对应的索引没有值则生成NAN,比如这里只有c d 索引值对应的,那么就只有c d 有值,索引取并值 a+b Out[91]: a NaN b 10.0 c 8.0 d NaN e NaN dtype: float64 -
Series类型的name属性
Series对象可以随时修改并立刻生效,Series对象和索引都可以有一个名字,存储在属性.name中
import pandas as pd b = pd.Series([9,8,7,6],['a','b','c','d']) b.name b.name="Series对象" b.index.name="索引列" b Out[97]: 索引列 a 9 b 8 c 7 d 6 Name: Series对象, dtype: int64 #修改name属性,改完立即生效 b.name="大帅哥" b 索引列 a 9 b 8 c 7 d 6 Name: 大帅哥, dtype: int64 #修改b,c索引对应的值 b['b','c']=100 b Out[101]: 索引列 a 9 b 100 c 100 d 6 Name: 大帅哥, dtype: int64
6.1.3Series类型的总结
Series是一维带标签的数组,标签指的是数组,掌握Series类型的创建方法,可以从标量,数组,列表,字典和其他函数创建,Series基本操作类似ndarray和字典,根据索引对齐。
6.2DataFrame类型
DataFrame类型是由共用相同索引的一组列组成的。可以看成是由相同索引的Series组成的字典类型。
DataFrame是一个由表格型的数据类型,每列值类型可以不同,DataFrame既有行索引,也有列索引,DataFrame常用于表达二维数据,但也可以表达多维数据。
轴用来为超过一维数组定义的属性,二维数据拥有两个轴,第0轴沿着行的方向的方向垂直向下,第1轴沿着列的方向水平延伸。1代表横轴,方向从左到右,0代表纵轴,方向从上到下,当axis=1时,数据的变化时横向的,体现出列的增加或者减少,反之当axis=0,数据的变化时纵向的,体现出行的增加或减少。
DataFrame的索引分为行,和列索引
- 行索引(index),行索引是默认的0,1,2,3,4,也可以自己定义
- 列索引(columns),列索引是用户自定义的,
DataFrame常用的参数
- data:用于创建数据帧对象的原始数据,可以是字典,序列等数据结构或其他的数据帧
- index:数据帧的索引
- columns:一个数组,包含列名称
- dtype:序列中的数据类型,如果在创建的时候没有指定数据类型,该方法将自动推断类型
- copy:是否创建数据副本,默认为False
注意:行索引和列索引要区分numpy中的axis=0 和axis=1,我们堆NumPy数值进行计算时,指明axis=0是指针对列进行计算,体现的是列的数据变化,axis=1体现的是行的数据变化。行索引用index标识,colums标识列索引。
6.2.1DataFrame类型的创建
-
二维ndarray对象创建
import numpy as np import pandas as pd d = pd.DataFrame(np.arange(10).reshape(2,5)) d Out[105]: 0 1 2 3 4 0 0 1 2 3 4 1 5 6 7 8 9 -
由一维ndarray,列表,字典,元组或Series构成的字典
import pandas as pd dt ={ 'one':pd.Series([1,2,3],index=['a','b','c']), 'two':pd.Series([9,8,7,6],index=['a','b','c','d'])} d = pd.DataFrame(dt) d Out[109]: one two a 1.0 9 b 2.0 8 c 3.0 7 d NaN 6 #设置列索引 pd.DataFrame(dt,index=['b','c','d'],columns=['two','three']) Out[110]: two three b 8 NaN c 7 NaN d 6 NaN -
Series类型
-
其他的DataFrame类型
-
DataFrame的练习
import pandas as pd d1 ={ '城市':['北京','上海','广州','深圳','沈阳'], '环比':[101.5,101.2,101.3,102.0,100.1], '同比':[120.7,127.3,119.4,140.9,101.4], '定基':[121.4,127.8,120.0,145.5,101.6]} d = pd.DataFrame(d1,index=['c1','c2','c3','c4','c5']) d Out[114]: 城市 环比 同比 定基 c1 北京 101.5 120.7 121.4 c2 上海 101.2 127.3 127.8 c3 广州 101.3 119.4 120.0 c4 深圳 102.0 140.9 145.5 c5 沈阳 100.1 101.4 101.6 #index=0行索引 d.index Out[115]: Index(['c1', 'c2', 'c3', 'c4', 'c5'], dtype='object') #列索引 d.columns Out[116]: Index(['城市', '环比', '同比', '定基'], dtype='object') #值 d.values array([['北京', 101.5, 120.7, 121.4], ['上海', 101.2, 127.3, 127.8], ['广州', 101.3, 119.4, 120.0], ['深圳', 102.0, 140.9, 145.5], ['沈阳', 100.1, 101.4, 101.6]], dtype=object)
6.2.2DataFrame值的获取
-
通过行索引,列索引获取某一行的数据
from Pandas import DataFrame df1 = DataFrame(data) df1 Out[660]: Chinese Math English 0 89 78 90 1 67 90 67 2 89 63 87 3 65 75 80 4 84 80 87 #通过行索引获取一行的数据,注意要使用.loc获取行的数据。 df1.loc[1,:] Out[661]: Chinese 67 Math 90 English 67 Name: 1, dtype: int64 #通过列索引获取一列的数据 df1['Chinese'] Out[663]: 0 89 1 67 2 89 3 65 4 84 Name: Chinese, dtype: int64 -
通过行索引和列索引获取某个元素的值,使用.loc获取指定的某个元素。
注意:DataFrame和NumPy中获取指定元素的方法是不同的。
df2 Out[670]: Chinese Math English Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 df2.loc['Mike','Math'] Out[671]: 78
6.2.3DataFrame中数据的访问
-
行操作
- 选择行
调用loc方法,通过传入行名称来选取行,若是行没有指定索引可以通过传入行索引参数,也能获取到对应行的数据
- 添加行
调用append方法给数据帧添加新行
- 删除行
调用drop方法删除行,若是行名称有重复的,则删除多行
import pandas as pd #选择行 Series ={ "name":pd.Series(["Wilson","Bruce","Chelsea"],index=["user1","user2","user3"]), "age":pd.Series([15,24,19],index=["user1","user2","user3"]), "gender":pd.Series(["man","man","women"],index=["user1","user2","user3"])} df = pd.DataFrame(Series) df Out[192]: name age gender user1 Wilson 15 man user2 Bruce 24 man user3 Chelsea 19 women #选取第一行的数据 df.loc["user1"] Out[194]: name Wilson age 15 gender man Name: user1, dtype: object #在没有指定行名称的时候才可以使用以下情况 #df.loc[0] #添加行,使用append方法 df1 = { "name":["Justin"],"age":[18],"gender":["man"]} df1 = pd.DataFrame(df1) df = df.append(df1) df Out[208]: name age gender user1 Wilson 15 man user2 Bruce 24 man user3 Chelsea 19 women 0 Justin 18 man #删除行,若是行名有重复则删除多行,注意如果在添加的时候不指明索引,则默认是0号索引,后续添加的都是0号索引,后面我们可以更改索引名称 df = df.drop(0) df Out[217]: name age gender user1 Wilson 15 man user2 Bruce 24 man user3 Chelsea 19 women -
列操作
对列的操作就容易多了,通过df[“列名”]或者df[索引值]即可获取对应的列,直接在df对象上设置新列名即可添加新列,若要删除列,调用df.pop(列名)就可以了
import pandas as pd Series ={ "name":pd.Series(["Wilson","Bruce","Chelsea"],index=["user1","user2","user3"]), "age":pd.Series([15,24,19],index=["user1","user2","user3"]), "gender":pd.Series(["man","man","women"],index=["user1","user2","user3"])} df = pd.DataFrame(Series) #添加新列 df["height"] = pd.DataFrame(pd.Series(["180cm","165cm","172cm"],index=["user1","user2","user3"])) df Out[221]: name age gender height user1 Wilson 15 man 180cm user2 Bruce 24 man 165cm user3 Chelsea 19 women 172cm #删除列,注意df.pop()返回的被删除的列 df.pop("height") Out[229]: user1 180cm user2 165cm user3 172cm Name: height, dtype: object df Out[230]: name age gender user1 Wilson 15 man user2 Bruce 24 man user3 Chelsea 19 women #df.info(),查看数据帧的具体信息 df.info() <class 'pandas.core.frame.DataFrame'> Index: 3 entries, user1 to user3 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 name 3 non-null object 1 age 3 non-null int64 2 gender 3 non-null object dtypes: int64(1), object(2) memory usage: 176.0+ bytes
6.2.4索引重置
-
重命名索引
调用rename方法可以将行列索引重命名,需要在rename中指定要修改的是轴还是列。该方法常用于原始数据统计完毕后,需要将列名根据业务进行调整的情况。
-
索引重建
调用reindex方法可以将原来的数据帧的索引重建。reindex方法常用于对多个数据帧进行联合操作时,将它们的行列数和名称按照规则转换。调用reindex方法,在行上满足index范围的索引将被选出,对于在原始数据帧上不存在的行和列,则使用NaN填充。
-
使索引个其他数据帧保持一致
调用reindex_like方法会将df2的列应用到df1上,df1中不存在的列将使用“NaN”补齐。
#重命名索引 df Out[235]: name age gender user1 Wilson 15 man user2 Bruce 24 man user3 Chelsea 19 women df = df.rename(index={ "user1":"第一行","user2":"第二行","user3":"第三行"},columns={ "name":"姓名","age":"年龄","gender":"性别"}) df Out[237]: 姓名 年龄 性别 第一行 Wilson 15 man 第二行 Bruce 24 man 第三行 Chelsea 19 women #索引重建 df = df.reindex(index=["user1","user2","user3"],columns=["name","age","gender"]) df Out[239]: name age gender user1 NaN NaN NaN user2 NaN NaN NaN user3 NaN NaN NaN #使索引与其他数据帧保持一致,有点类似表结构的复制 Series1 ={ "name":pd.Series(["Wilson","Bruce","Chelsea"]), "age":pd.Series([15,24,19]), "math_score":pd.Series([70,68,85])} Series2 ={ "name":pd.Series(["Wilson","Bruce","Chelsea"]), "age":pd.Series([15,24,19]), "score":pd.Series([70,68,85])} df1 = pd.DataFrame(Series1) df2 = pd.DataFrame(Series2) df1 = df1.reindex_like(df2) #可以看到df1的表结构和df2的表结构是一致的了 df1 Out[241]: name age score 0 Wilson 15 NaN 1 Bruce 24 NaN 2 Chelsea 19 NaN
6.2.5数据帧的遍历
Pandas提供了多种方法遍历一个数据帧
-
以namedtuples方式遍历行
在数据帧对象上调用itertuples()方法可以遍历每一行。循环变量“item”是“
”类型,访问具体值的时候,使用item.age. import pandas as pd series ={ "name":pd.Series(["Wilson","Bruce","Chelsea"]), "age":pd.Series([15,24,19]), "math_score":pd.Series([98,88,80]), "en_score":pd.Series([70,68,85])} df1 = pd.DataFrame(series) for item in df1.itertuples(): print(item) Pandas(Index=0, name='Wilson', age=15, math_score=98, en_score=70) Pandas(Index=1, name='Bruce', age=24, math_score=88, en_score=68) Pandas(Index=2, name='Chelsea', age=19, math_score=80, en_score=85) for item in df1.itertuples(): print(item.age) 15 24 19 df1 Out[246]: name age math_score en_score 0 Wilson 15 98 70 1 Bruce 24 88 68 2 Chelsea 19 80 85 -
以tuple方式遍历行
在数据帧上调用tuple方法,可以设置两个循环变量,一个为行索引,另一个为该行对应的值。值的组成形式是列名和具体的值,类型是“
” #借用上个例子中的数据帧 df1 = pd.DataFrame(series) for key,val in df1.iterrows(): print("行索引:",key,"值:",val) print("----------------------------") 行索引: 0 值: name Wilson age 15 math_score 98 en_score 70 Name: 0, dtype: object ---------------------------- 行索引: 1 值: name Bruce age 24 math_score 88 en_score 68 Name: 1, dtype: object ---------------------------- 行索引: 2 值: name Chelsea age 19 math_score 80 en_score 85 Name: 2, dtype: object ---------------------------- -
以tuple方式的遍历列
#借用上个用例的DataFrame for key,val in df1.iteritems(): print("列名称:",key,"值:",val) print("--------------") 列名称: name 值: 0 Wilson 1 Bruce 2 Chelsea Name: name, dtype: object -------------- 列名称: age 值: 0 15 1 24 2 19 Name: age, dtype: int64 -------------- 列名称: math_score 值: 0 98 1 88 2 80 Name: math_score, dtype: int64 -------------- 列名称: en_score 值: 0 70 1 68 2 85 Name: en_score, dtype: int64 --------------
总结
遍历行有两个方法:itertuples(),iterrows()
遍历列有一个方法:iteritems()
6.2.5.6自定义函数
按操作对象的粒度不同,Pandas提供了3种方式在数据帧上使用系统自带的或者用户自定义的函数。
-
针对行或列,apply方法
调用apply方法,传入自定义函数,通过axis指定对行操作还是对列操作。当axis=1时,item代表一行数据,每一个值使用item[“列名”]进行访问,当axis=0时,item代表的是一列数据,由于df1对象没有设置行名称,因此对每一个值使用默认的行索引进行访问。
import pandas as pd import numpy as np series ={ "name":pd.Series(["Wilson","Bruce","Chelsea"]), "age":pd.Series([15,24,19]), "math_score":pd.Series([98,88,80]), "en_score":pd.Series([70,68,85])} df1 = pd.DataFrame(series) #定义自定义函数 def f(item,p1,p2): item["math_score"]=item["math_score"]+p1 item["en_score"]=item["en_score"]+p2 return item #调用自定义函数 df = df1.apply(f,axis=1,args=(10,20)) df Out[255]: name age math_score en_score 0 Wilson 15 108 90 1 Bruce 24 98 88 2 Chelsea 19 90 105 df1 Out[256]: name age math_score en_score 0 Wilson 15 98 70 1 Bruce 24 88 68 2 Chelsea 19 80 85 -
针对元素
调用applymap方法可以对数据帧上的每一个元素进行行的操作。
import pandas as pd import numpy as np series ={ "name":pd.Series(["Wilson","Bruce","Chelsea"]), "age":pd.Series([15,24,19]), "math_score":pd.Series([98,88,80]), "en_score":pd.Series([70,68,85])} df1 = pd.DataFrame(series) #定义自定义函数 def f(item): if isinstance(item,int): return item+10 elif isinstance(item,str): return "hello"+item df = df1.applymap(f) df Out[259]: name age math_score en_score 0 helloWilson 25 108 80 1 helloBruce 34 98 78 2 helloChelsea 29 90 95 df1 Out[260]: name age math_score en_score 0 Wilson 15 98 70 1 Bruce 24 88 68 2 Chelsea 19 80 85 -
针对整个数据帧
调用pipe方法,将会传入当前的整个数据帧对象,一般情况下,如是需要处理一个数据帧对象的整行或者整列,推荐使用pipe方法。注意pipe改变的整个数据帧,并不是返回一个新的数据帧,原来的数据帧也发生了改变。
import pandas as pd import numpy as np series ={ "name":pd.Series(["Wilson","Bruce","Chelsea"]), "age":pd.Series([15,24,19]), "math_score":pd.Series([98,88,80]), "en_score":pd.Series([70,68,85])} df1 = pd.DataFrame(series) #定义自定义函数 def f(df,p1,p2): df["math_score"]=df["math_score"]+p1 df["en_score"]=df["en_score"]+p2 return df #使用pipe,方法,该方法将接受一个回调函数f df = df1.pipe(f,10,20) df Out[269]: name age math_score en_score 0 Wilson 15 108 90 1 Bruce 24 98 88 2 Chelsea 19 90 105 #可以看到原来的数据帧也发生了变化 df1 Out[270]: name age math_score en_score 0 Wilson 15 108 90 1 Bruce 24 98 88 2 Chelsea 19 90 105
6.3Pandas库的数据类型操作
-
重新索引
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RmZbaJcx-1596355463912)(C:\myNote\data_analyse\python_code\reindex.PNG)]
#.reindex()能够改变或者重排Series和DataFrame索引 d =d.reindex(index=['c5','c4','c3','c2','c1']) d Out[133]: 城市 环比 同比 定基 c5 沈阳 100.1 101.4 101.6 c4 深圳 102.0 140.9 145.5 c3 广州 101.3 119.4 120.0 c2 上海 101.2 127.3 127.8 c1 北京 101.5 120.7 121.4 d = d.reindex(columns=['城市','同比','环比','定基']) d Out[135]: 城市 同比 环比 定基 c5 沈阳 101.4 100.1 101.6 c4 深圳 140.9 102.0 145.5 c3 广州 119.4 101.3 120.0 c2 上海 127.3 101.2 127.8 c1 北京 120.7 101.5 121.4 #增加索引 newc = d.columns.insert(4,'新增') newd = d.reindex(columns=newc,fill_value=200) newd Out[138]: 城市 同比 环比 定基 新增 c5 沈阳 101.4 100.1 101.6 200 c4 深圳 140.9 102.0 145.5 200 c3 广州 119.4 101.3 120.0 200 c2 上海 127.3 101.2 127.8 200 c1 北京 120.7 101.5 121.4 200 -
索引类型常用的方法
Series和DataFrame的索引都是Index类型,Index对象是不可修改的类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HZ4jg8H7-1596355463913)(C:\myNote\data_analyse\python_code\索引类型常用的方法.PNG)]
d
Out[139]:
城市 同比 环比 定基
c5 沈阳 101.4 100.1 101.6
c4 深圳 140.9 102.0 145.5
c3 广州 119.4 101.3 120.0
c2 上海 127.3 101.2 127.8
c1 北京 120.7 101.5 121.4
nc =d.columns.delete(2)
nc
Out[142]: Index(['城市', '同比', '定基'], dtype='object')
ni =d.index.insert(5,'c0')
#向前填充
nd = d.reindex(index=ni,columns=nc)
nd
Out[154]:
城市 同比 定基
c5 沈阳 101.4 101.6
c4 深圳 140.9 145.5
c3 广州 119.4 120.0
c2 上海 127.3 127.8
c1 北京 120.7 121.4
c0 NaN NaN NaN
-
删除指定的索引对象
d Out[155]: 城市 同比 环比 定基 c5 沈阳 101.4 100.1 101.6 c4 深圳 140.9 102.0 145.5 c3 广州 119.4 101.3 120.0 c2 上海 127.3 101.2 127.8 c1 北京 120.7 101.5 121.4 d.drop(['c5','c4']) Out[156]: 城市 同比 环比 定基 c3 广州 119.4 101.3 120.0 c2 上海 127.3 101.2 127.8 c1 北京 120.7 101.5 121.4 #删除纵列的时候,记得加上axis d.drop('同比',axis=1) Out[158]: 城市 环比 定基 c5 沈阳 100.1 101.6 c4 深圳 102.0 145.5 c3 广州 101.3 120.0 c2 上海 101.2 127.8 c1 北京 101.5 121.4 #一般情况下默认删除就是横列,所以在删除横列的时候可以不加axis,但是建议在删除索引的时候都加上,横列axis=0,纵列axis=1 d.drop(c5,axis=0) Out[160]: 城市 同比 环比 定基 c4 深圳 140.9 102.0 145.5 c3 广州 119.4 101.3 120.0 c2 上海 127.3 101.2 127.8 c1 北京 120.7 101.5 121.4
6.4Pandas的算术运算法则
算术运算根据杭列索引值,补齐后进行运算,运算默认产生浮点数,补齐时缺项填充NaN(空值),二维和一维,一维和零维间为广播运算,采用±*/符号进行的二元运算产生新的对象。
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4))
b = pd.DataFrame(np.arange(20).reshape(4,5))
a + b
Out[165]:
0 1 2 3 4
0 0.0 2.0 4.0 6.0 NaN
1 9.0 11.0 13.0 15.0 NaN
2 18.0 20.0 22.0 24.0 NaN
3 NaN NaN NaN NaN NaN
a*b
Out[166]:
0 1 2 3 4
0 0.0 1.0 4.0 9.0 NaN
1 20.0 30.0 42.0 56.0 NaN
2 80.0 99.0 120.0 143.0 NaN
3 NaN NaN NaN NaN NaN
数据类型的算术运算
方法形式的运算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-osfYft2z-1596355463914)(C:\myNote\data_analyse\python_code\Pandas方法形式的运算.PNG)]
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4))
a
Out[169]:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
b =pd.DataFrame(np.arange(20).reshape(4,5))
b
Out[168]:
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
b.add(a,fill_value=100)
0 1 2 3 4
0 0.0 2.0 4.0 6.0 104.0
1 9.0 11.0 13.0 15.0 109.0
2 18.0 20.0 22.0 24.0 114.0
3 115.0 116.0 117.0 118.0 119.0
a.mul(b,fill_value=0)
Out[170]:
0 1 2 3 4
0 0.0 1.0 4.0 9.0 0.0
1 20.0 30.0 42.0 56.0 0.0
2 80.0 99.0 120.0 143.0 0.0
3 0.0 0.0 0.0 0.0 0.0
#fill_value 参数替代NaN,替代后参与运算
不同维度的广播运算,一维Series默认在轴1参与运算,使用运算方法可以时一维Series参与轴0运算。
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5))
c =pd.Series(np.arange(4))
Out[173]:
0 0
1 1
2 2
3 3
dtype: int32
c-10
Out[174]:
0 -10
1 -9
2 -8
3 -7
dtype: int32
b-c
Out[175]:
0 1 2 3 4
0 0.0 0.0 0.0 0.0 NaN
1 5.0 5.0 5.0 5.0 NaN
2 10.0 10.0 10.0 10.0 NaN
3 15.0 15.0 15.0 15.0 NaN
#使用sub,进行减法运算
b.sub(c,axis=0)
Out[176]:
0 1 2 3 4
0 0 1 2 3 4
1 4 5 6 7 8
2 8 9 10 11 12
3 12 13 14 15 16
比较运算法则
比较运算只能比较相同索引的元素,不进行补齐,二维和一维,一维和零维之间为广播运算,采用> < >= <= == !=等符号进行的二元运算产生布尔对象
#同维度运算,尺寸一致
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4))
d = pd.DataFrame(np.arange(12,0,-1).reshape(3,4))
a>d
Out[181]:
0 1 2 3
0 False False False False
1 False False False True
2 True True True True
a == d
Out[182]:
0 1 2 3
0 False False False False
1 False False True False
2 False False False False
#不同维度,广播运算,默认在1轴
c = pd.Series(np.arange(4))
Out[185]:
0 1 2 3
0 False False False False
1 True True True True
2 True True True True
c >0
Out[186]:
0 False
1 True
2 True
3 True
dtype: bool
6.5数据处理流程
了解了Series与DataFrame这两个数据结构后,我们就可以从数据处理的流程角度来看他们的使用方法。
数据处理流程包括以下几个流程:
- 数据的导入和输出
- 数据清洗
- 数据统计
- 数据表合并
此外在介绍一种基于SQL方式打开Pandas
6.5.1数据的导入和输出
-
导入excel 文件
使用pd.read_excel()读取excel文件,在使用DataFrame转换为DataFrame类型
import pandas as pd from pandas import DataFrame score = pd.DataFrame(pd.read_excel("C:\\myNote\\data_analyse\\score.xlsx")) score Out[681]: 姓名 语文 数学 英语 0 张红 90 67 85 1 李刚 89 76 90 2 王亚磊 76 56 85 3 吴文燕 80 98 78 4 龙小云 78 80 79 -
导入csv文件
使用pd.read_csv(),方法跟read_excel类似
-
将数据帧导出成excel文件
使用DataFrame的to_excel方法,同理导出为csv文件就使用to_csv方法
当然,还可以将数据帧导出成各种格式的文件,比如csv、html、json等等
data ={'Chinese':[89,67,89,65,84],'Math':[78,90,63,75,80],'English':[90,67,87,80,87]} df2 =DataFrame(data,index=['Mike','Alice','Frank','Brown','Smith']) df2 Out[684]: Chinese Math English Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 df2.to_excel("C:\\myNote\\data_analyse\\score_table.xlsx")
6.5.2数据清洗
数据清洗涉及到以下几个方面
-
删除数据帧中不必要的行或列
使用DataFrame中的drop(index=?)删除行,drop(columns=[?])删除列,或者pop(),注意删除后得到的是一个新的对象,不是源DataFrame类型并未改变
df2 Out[686]: Chinese Math English Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 #删除Mike所在的行 df1 =df2.drop(index='Mike') df1 Out[688]: Chinese Math English Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 #删除Chinese所在的列 df3= df2.drop(columns='Chinese') df3 Out[690]: Math English Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 #可以看到源DataFrame对象并未改变 df2 Out[691]: Chinese Math English Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 -
重命名列名
函数:rename(columns=new_names,inplce=True),
- 参数inplce设置为True,直接在原数据帧上修改列名
- 参数inplce设置为False,元数据帧列名不变,在返回的数据帧上修改列名,如果参数不设置,默认是False
df2 Out[695]: Chinese Math English Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 #设置inplace参数为False df3 =df2.rename(columns={ 'Chinese':'Yuwen','Math':'Shuxue','English':'Yingyu'},inplace=False) #inplace参数不设置默认是False df4 =df2.rename(columns={ 'Chinese':'Yuwen','Math':'Shuxue','English':'Yingyu'}) df3 Out[698]: Yuwen Shuxue Yingyu Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 df4 Out[699]: Yuwen Shuxue Yingyu Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 #inplace参数设置为False,原数据帧没有发生变化 df2 Out[700]: Chinese Math English Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 #inplace参数设置为True df5 =df2.rename(columns={ 'Chinese':'Yuwen','Math':'Shuxue','English':'Yingyu'},inplace=True) df5 #inplace参数设置为True,可以看到原数据帧发生了变化 df2 Out[703]: Yuwen Shuxue Yingyu Mike 89 78 90 Alice 67 90 67 Frank 89 63 87 Brown 65 75 80 Smith 84 80 87 -
去掉重复的行
数据采集中可能存在重复的行,使用drop_duplicates()就能自动去掉重复的行,注意调用这个方法不改变原来的数据帧,只是在返回的数据帧上对数据
import pandas as pd from pandas import DataFrame df1 =DataFrame(pd.read_excel("C:\\myNote\\data_analyse\\score_test.xlsx")) #调用DataFrame的drop_duplicates()删除重复行 df1_temp = df1.drop_duplicates() df1_temp Out[709]: 姓名 语文 数学 英语 0 张红 90 67 85 1 李刚 89 76 90 2 王亚磊 76 56 85 3 吴文燕 80 98 78 4 龙小云 78 80 79 #可以看到源数据帧并未发生改变 df1 Out[710]: 姓名 语文 数学 英语 0 张红 90 67 85 1 李刚 89 76 90 2 王亚磊 76 56 85 3 吴文燕 80 98 78 4 龙小云 78 80 79 5 龙小云 78 80 79 #将改变后的数据帧导出转为excel文件 df1_temp.to_excel("C:\\myNote\\data_analyse\\score_test_result.xlsx") -
更改格式
-
更改数据格式(类型)
使用astype()函数来规范数据格式
df2 Out[721]: Yuwen Shuxue Yingyu Mike 89.0 78 90 Alice 67.0 90 67 Frank 89.0 63 87 Brown 65.0 75 80 Smith 84.0 80 87 df3 = df2.drop(columns='Yuwen') df3 Out[723]: Shuxue Yingyu Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 col1 = df3['Shuxue'].astype(np.float) col2 = df3['Yingyu'].astype(np.float) #注意改变数据类型后要将改变数据类型的列横向进行拼接 df4 =pd.concat([col1,col2],axis=1) df4 Out[727]: Shuxue Yingyu Mike 78.0 90.0 Alice 90.0 67.0 Frank 63.0 87.0 Brown 75.0 80.0 Smith 80.0 87.0 df5 =pd.concat([col1,col2],axis=0) df5 Out[729]: Mike 78.0 Alice 90.0 Frank 63.0 Brown 75.0 Smith 80.0 Mike 90.0 Alice 67.0 Frank 87.0 Brown 80.0 Smith 87.0 dtype: float64 #可以看到原数据帧的数据类型还是没有发生改变,我们要将改变数据类型的列拼接成一个新的数据帧,.loc[],DataFrame中查看指定的元素 type(df3.loc['Mike','Shuxue']) Out[734]: numpy.int64 -
大小写转换
由三个函数upper(),lower(),title(),这里的大写写转换指的是索引名称的大小写转换
df3 Out[735]: Shuxue Yingyu Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 #将列名全部改为大写 df3.columns=df3.columns.str.upper() df3 Out[737]: SHUXUE YINGYU Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 #将行索引改为小写 df3.index=df3.index.str.lower() df3 Out[739]: SHUXUE YINGYU mike 78 90 alice 90 67 frank 63 87 brown 75 80 smith 80 87 #将行索引改为首字母大写 df3.index=df3.index.str.title() df3 Out[741]: SHUXUE YINGYU Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 -
数据间的空格
有时先将数据转换成str类型,是为了方便对数据进行操作,比如要删除数据间的空格,就可以使用strip()函数
#先将数据转换为str类型 df3 Out[748]: Shuxue Yingyu Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 #将数学这一列转为str类型 df3['Shuxue'] = df3['Shuxue'].astype(np.str) #将英语这一类转为str类型,注意这里提供了了一种类型转换的新思路,有别于拼接成一个新的数据帧 df3['Yingyu'] = df3['Yingyu'].astype(np.str) df3['Shuxue'] = df3['Shuxue'].map(str.strip) df3 Out[753]: Shuxue Yingyu Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 type(df3.loc['Mike','Shuxue']) Out[755]: str #此外我们还可以使用strip函数来删除特定的字符 df3 Out[756]: Shuxue Yingyu Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 df3['Shuxue'].str.strip('0') Out[757]: Mike 78 Alice 9 Frank 63 Brown 75 Smith 8 Name: Shuxue, dtype: object #可以看出其实很多操作并不会对原始的数据帧进行改变,而是返回一个新的数据帧,如果要对原始的数据帧进行改变,可以使用指定赋值 df3 Out[758]: Shuxue Yingyu Mike 78 90 Alice 90 67 Frank 63 87 Brown 75 80 Smith 80 87 df3['Shuxue'] = df3['Shuxue'].str.strip('0') df3 Out[760]: Shuxue Yingyu Mike 78 90 Alice 9 67 Frank 63 87 Brown 75 80 Smith 8 87
-
-
查找空值
数据源可能存在有些字段是NaN的情况,可以利用pandas的isnull函数来查找。如果要知道哪一列存在空值,可以利用df.isnull().any()函数
import pandas as pd from pandas import DataFrame df = DataFrame(pd.read_excel("C:\\myNote\\data_analyse\\score.xlsx")) df Out[762]: 姓名 语文 数学 英语 0 张红 90.0 67.0 85.0 1 李刚 89.0 76.0 90.0 2 王亚磊 76.0 56.0 85.0 3 吴文燕 80.0 98.0 78.0 4 龙小云 NaN NaN NaN df.isnull() Out[764]: 姓名 语文 数学 英语 0 False False False False 1 False False False False 2 False False False False 3 False False False False 4 False True True True #如果想知道哪一列存在空值,可以利用df.isnull().any()函数 df.isnull().any() Out[765]: 姓名 False 语文 True 数学 True 英语 True dtype: bool -
使用apply函数对数据进行清洗
-
应用系统自带函数
apply函数是Pandas中自由度非常高的函数,使用频率也十分高。要掌握。
#使用常规方式调用方法 df3 Out[768]: Shuxue Yingyu Mike 78 90 Alice 9 67 Frank 63 87 Brown 75 80 Smith 8 87 #将列索引大写 df3.columns = df3.columns.str.upper() df3 Out[770]: SHUXUE YINGYU Mike 78 90 Alice 9 67 Frank 63 87 Brown 75 80 Smith 8 87 #将列名改为首字母大写 df3.columns = df3.columns.str.title() df3 Out[772]: Shuxue Yingyu Mike 78 90 Alice 9 67 Frank 63 87 Brown 75 80 Smith 8 87 #使用apply()函数 ##df3.columns = df3.cloumns.apply(str.upper),这种写法是错误的,apply()函数是针对元素内容的,不是针对列名的 df = DataFrame(pd.read_excel("C:\\myNote\\data_analyse\\score_table_test.xlsx")) df Out[781]: Name Chinese Math English 0 Mike 89 78 90 1 Alice 67 90 67 2 Frank 89 63 87 3 Brown 65 75 80 4 Smith 84 80 87 #使用apply()函数将Name列的内容全部大写 df['Name'] = df['Name'].apply(str.upper) df Out[784]: Name Chinese Math English 0 MIKE 89 78 90 1 ALICE 67 90 67 2 FRANK 89 63 87 3 BROWN 65 75 80 4 SMITH 84 80 87 -
应用自定义函数
#定义一个提分20%的函数 def increase(x): return x*1.2 df Out[788]: Name Chinese Math English 0 MIKE 89 78 90 1 ALICE 67 90 67 2 FRANK 89 63 87 3 BROWN 65 75 80 4 SMITH 84 80 87 df['Chinese'] = df['Chinese'].apply(increase) df Out[790]: Name Chinese Math English 0 MIKE 106.8 78 90 1 ALICE 80.4 90 67 2 FRANK 106.8 63 87 3 BROWN 78.0 75 80 4 SMITH 100.8 80 87 #定义一个函数,添加一个新字段Score,计算三科的加权平均值 def add_score(df,w1,w2,w3): w = w1+w2+w3 df['Score'] =(df['Chinese']*w1+df['Math']*w2+df['English']*w3)/w return df df1 =df.apply(add_score,axis=1,args=(1,4,5)) df1 Out[794]: Name Chinese Math English Score 0 MIKE 106.8 78 90 86.88 1 ALICE 80.4 90 67 77.54 2 FRANK 106.8 63 87 79.38 3 BROWN 78.0 75 80 77.80 4 SMITH 100.8 80 87 85.58
-
-
添加行和添加列
-
添加新行
newrow =DataFrame([['Green',89,67,98]],columns=['Name','Chinese','Math','English']) #ignore_index=True索引连续 df = df.append(newrow,ignore_index=True) df Out[801]: Name Chinese Math English 0 MIKE 106.8 78 90 1 ALICE 80.4 90 67 2 FRANK 106.8 63 87 3 BROWN 78.0 75 80 4 SMITH 100.8 80 87 5 Green 89.0 67 98 #ignore_index=False 索引不连续 df = df.append(newrow,ignore_index=False) df Out[803]: Name Chinese Math English 0 MIKE 106.8 78 90 1 ALICE 80.4 90 67 2 FRANK 106.8 63 87 3 BROWN 78.0 75 80 4 SMITH 100.8 80 87 5 Green 89.0 67 98 0 Green 89.0 67 98 -
在某行后插入新行
在Alice之后插入新行
df Out[804]: Name Chinese Math English 0 MIKE 106.8 78 90 1 ALICE 80.4 90 67 2 FRANK 106.8 63 87 3 BROWN 78.0 75 80 4 SMITH 100.8 80 87 5 Green 89.0 67 98 0 Green 89.0 67 98 above = df[:2] below = df[2:] above Out[807]: Name Chinese Math English 0 MIKE 106.8 78 90 1 ALICE 80.4 90 67 below Out[808]: Name Chinese Math English 2 FRANK 106.8 63 87 3 BROWN 78.0 75 80 4 SMITH 100.8 80 87 5 Green 89.0 67 98 0 Green 89.0 67 98 newrow =DataFrame([['Brain',56,63,90]],columns=['Name','Chinese','Math','English']) #原理就是拆分两部分,将新行插入 df =above.append(newrow,ignore_index=True).append(below,ignore_index=True) df Out[813]: Name Chinese Math English 0 MIKE 106.8 78 90 1 ALICE 80.4 90 67 2 Brain 56.0 63 90 3 FRANK 106.8 63 87 4 BROWN 78.0 75 80 5 SMITH 100.8 80 87 6 Green 89.0 67 98 7 Green 89.0 67 98 -
添加新列
#添加新列 df['Average']=(df['Chinese']+df['Math']+df['English'])/3 df Out[816]: Name Chinese Math English Average 0 MIKE 106.8 78 90 91.600000 1 ALICE 80.4 90 67 79.133333 2 Brain 56.0 63 90 69.666667 3 FRANK 106.8 63 87 85.600000 4 BROWN 78.0 75 80 77.666667 5 SMITH 100.8 80 87 89.266667 6 Green 89.0 67 98 84.666667 7 Green 89.0 67 98 84.666667
-
6.5.3数据统计
在数据清洗之后,我们就要对数据进行统计了。Pandas和NumPy一样,都有常用的统计函数,如果遇到空值NaN,会自动排除。注意的是这些统计函数默认都是axis=0,对所有的列进行相关计算计算
Pandas中常用的统计函数
- count():统计个数,空值NaN不计算
- descibe():一次性输出多个统计指标,包括count,mean,std,min,max等
- min():最小值
- max():最大值
- sum():总和
- mean():平均值
- median():中位数
- var():方差
- std():标准差
- argmin():统计最小值的索引位置
- argmax():统计最大值的索引位置
- idxmin():统计最小值的索引位置
- idxmax():统计最大值的索引位置
df
Out[817]:
Name Chinese Math English Average
0 MIKE 106.8 78 90 91.600000
1 ALICE 80.4 90 67 79.133333
2 Brain 56.0 63 90 69.666667
3 FRANK 106.8 63 87 85.600000
4 BROWN 78.0 75 80 77.666667
5 SMITH 100.8 80 87 89.266667
6 Green 89.0 67 98 84.666667
7 Green 89.0 67 98 84.666667
#统计个数
df.count()
Out[818]:
Name 8
Chinese 8
Math 8
English 8
Average 8
dtype: int64
#descibe()函数,该函数是个大礼包,对数据有个全面的了解
df.describe()
Out[819]:
Chinese Math English Average
count 8.000000 8.000000 8.000000 8.000000
mean 88.350000 72.875000 87.125000 82.783333
std 17.127672 9.553421 10.063193 7.034044
min 56.000000 63.000000 67.000000 69.666667
25% 79.800000 66.000000 85.250000 78.766667
50% 89.000000 71.000000 88.500000 84.666667
75% 102.300000 78.500000 92.000000 86.516667
max 106.800000 90.000000 98.000000 91.600000
#方差函数
df.var()
Out[820]:
Chinese 293.357143
Math 91.267857
English 101.267857
Average 49.477778
dtype: float64
#中位数函数
df.median()
Out[821]:
Chinese 89.000000
Math 71.000000
English 88.500000
Average 84.666667
dtype: float64
6.5.4数据表合并
准备数据
import pandas as pd
from pandas import DataFrame
a = DataFrame({
'Name':['Mike','Alice','Brian','Smith','Green'],'Score':[99,78,67,93,85]})
b = DataFrame({
'Name':['Howard','Alice','Ada','Smith','Black'],'score':[90,78,81,93,97]})
a
Out[824]:
Name Score
0 Mike 99
1 Alice 78
2 Brian 67
3 Smith 93
4 Green 85
b
Out[825]:
Name score
0 Howard 90
1 Alice 78
2 Ada 81
3 Smith 93
4 Black 97
两个数据表要进行合并要使用merge()函数,有以下5中形式:
-
基于指定列进行连接
c = pd.merge(a,b,on='Name') c Out[827]: Name Score score 0 Alice 78 78 1 Smith 93 93 -
inner内连接
inner内连接是merge()函数的默认情况,基于公共键进行连接,因为a,b公共键是Name,其实就是基于Name的内连接
d =pd.merge(a,b,how='inner') d Out[831]: Name Score score 0 Alice 78 78 1 Smith 93 93 -
left连接
left连接十一第一个DataFrame为主,第二个DataFrame为辅的连接
a Out[832]: Name Score 0 Mike 99 1 Alice 78 2 Brian 67 3 Smith 93 4 Green 85 e = pd.merge(a,b,how='left') e Out[834]: Name Score score 0 Mike 99 NaN 1 Alice 78 78.0 2 Brian 67 NaN 3 Smith 93 93.0 4 Green 85 NaN -
right连接
right连接是以第二个DataFrame为主,第一个DataFrame为辅的连接
b Out[835]: Name score 0 Howard 90 1 Alice 78 2 Ada 81 3 Smith 93 4 Black 97 f = pd.merge(a,b,how='right') f Out[837]: Name Score score 0 Alice 78.0 78 1 Smith 93.0 93 2 Howard NaN 90 3 Ada NaN 81 4 Black NaN 97 -
outer外连接
外连接相当于两个DataFrame求并集
g = pd.merge(a,b,how='outer') g Out[839]: Name Score score 0 Mike 99.0 NaN 1 Alice 78.0 78.0 2 Brian 67.0 NaN 3 Smith 93.0 93.0 4 Green 85.0 NaN 5 Howard NaN 90.0 6 Ada NaN 81.0 7 Black NaN 97.0
6.6用SQL方式打开Pandas
Pandas的DataFrame数据类型可以让我们像处理数据表一样进行操作,比如数据表的增删改查,都可以用Pandas工具来完成,但是命令太多,我们其实可以使用自己更加熟练的SQL语句来对数据表进行操作。
利用pandassql工具可以采用SQL语句操作数据表。pandasql主要函数sqldf,接受两个参数:SQL查询语句和一组环境变量globals()或locals(),这样我们就可以在Python里直接用SQL语句直接操作DataFrame了。
-
安装pandasql工具包
注意如果安装pandasql报错报错内容为当前用户没有写入权限,请使用管理员启动anaconda进行安装,运行conda install pandasql
-
实际操作
from pandasql import sqldf import pandas as pd from pandas import DataFrame df = DataFrame(pd.read_excel("C:\\myNote\\data_analyse\\score_table_test.xlsx")) df Out[5]: Name Chinese Math English 0 Mike 89 78 90 1 Alice 67 90 67 2 Frank 89 63 87 3 Brown 65 75 80 4 Smith 84 80 87 #定义SQL语句,查询姓名为Mike的人员信息 sql = "select * from df where Name='Mike'" #定义匿名函数,采用lambda函数,对sql语句进行处理, pysqldf =lambda sql:sqldf(sql,globals()) #处理SQL语句 pysqldf(sql) Out[11]: Name Chinese Math English 0 Mike 89 78 90 #定义sql语句,查询语文成绩[80,90]之间的人员信息 sql = "select * from df where Chinese>=80 and Chinese<=90" pysqldf(sql) Out[13]: Name Chinese Math English 0 Mike 89 78 90 1 Frank 89 63 87 2 Smith 84 80 87 #暂时还不支持update 和insert 操作,找到原因再补充
6.7练习
对excel表进行数据清洗,同时新增一列‘总和’,计算每个人三科成绩平均成绩
#数据清洗
import pandas as pd
from pandas import DataFrame
df = DataFrame(pd.read_excel("C:\\myNote\\data_analyse\\test2.xlsx"))
#1.删除有NaN的行
print("原表:")
print(df)
for i in range(1,len(df.columns)):
col = df.columns[i]
df =df.drop(index=df[df[col].isnull()].index[0])
print("删除所有NaN的行:")
print(df)
#删除重复的行
df = df.drop_duplicates()
print("删除重复的行:")
print(df)
#计算平均分
df['平均分']=df.mean(axis=1)
print("添加平均值字段")
print(df)
#####################
原表:
姓名 语文 英语 数学
0 张飞 66.0 65.0 NaN
1 关羽 95.0 85.0 98.0
2 赵云 95.0 92.0 96.0
3 黄忠 90.0 88.0 77.0
4 典韦 80.0 90.0 90.0
5 典韦 80.0 90.0 90.0
6 马超 NaN 89.0 74.0
7 曹洪 89.0 78.0 96.0
8 张郃 80.0 67.0 86.0
9 徐晃 85.0 NaN 56.0
删除所有NaN的行:
姓名 语文 英语 数学
1 关羽 95.0 85.0 98.0
2 赵云 95.0 92.0 96.0
3 黄忠 90.0 88.0 77.0
4 典韦 80.0 90.0 90.0
5 典韦 80.0 90.0 90.0
7 曹洪 89.0 78.0 96.0
8 张郃 80.0 67.0 86.0
删除重复的行:
姓名 语文 英语 数学
1 关羽 95.0 85.0 98.0
2 赵云 95.0 92.0 96.0
3 黄忠 90.0 88.0 77.0
4 典韦 80.0 90.0 90.0
7 曹洪 89.0 78.0 96.0
8 张郃 80.0 67.0 86.0
添加平均值字段
姓名 语文 英语 数学 平均分
1 关羽 95.0 85.0 98.0 92.666667
2 赵云 95.0 92.0 96.0 94.333333
3 黄忠 90.0 88.0 77.0 85.000000
4 典韦 80.0 90.0 90.0 86.666667
7 曹洪 89.0 78.0 96.0 87.666667
8 张郃 80.0 67.0 86.0 77.666667
#小技巧
#筛选有缺失值的列:df.isnull().any()
#筛选有缺失值的行:df.isnull().T.any()
#例如这里我们可以应这种方法筛选NaN行号,进行删除
df[df.isnull().T.any()]
Out[45]:
姓名 语文 英语 数学
0 张飞 66.0 65.0 NaN
6 马超 NaN 89.0 74.0
9 徐晃 85.0 NaN 56.0
#得知有空行的行号为0,6,9然后遍历进行删除
df[df.isnull().T.any()].index
Out[46]: Int64Index([0, 6, 9], dtype='int64')
6.8Pandas库入门小结
Series = 索引 + 一维数据
DataFrame = 行列索引 + 二维数据
数据类型和索引的关系,操作索引即操作数据
重新索引,数据删除,算术运算,比较运算,像对待单一数据一样对待Series和DataFrame对象。
使用Pandas可以直接从csv或xlsx等文件中导入数据,以及最终输出到不同类型的文件中,比如csv或excel文件
学习了数据清洗的操作,以及Pandas提供的统计函数,重点掌握统计大礼包函数describe().
学习了如何利用Pandasql工具在Pandas里采用sql语句对数据表进行操作。
学习了利用merge函数,将两个数据表合并。
Pandas包与NumPy库配合使用可以发挥巨大的威力。
第七章Pandas数据特征分析
7.1Pandas库的数据排序
对于一组数据可以表达一个或多个含义我们通过摘要(摘要是数据形成有损特征的过程)可以得到数据的基本统计信息(含排序),分布/累计统计,数据特征包括数据的相关性,周期性,然后通过数据挖掘,形成知识。
pandas提供了两种排序方式,一是按照列名排序,而是按照列值排序
按列名排序
.sort_index()
在指定轴上根据索引进行排序,默认升序,格式.sort_index(axis=0,ascending=True)
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5),columns=['a','b','c','d','e'])
b
Out[372]:
a b c d e
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
3 15 16 17 18 19
#降序排列
b.sort_index(ascending=False)
Out[373]:
a b c d e
3 15 16 17 18 19
2 10 11 12 13 14
1 5 6 7 8 9
0 0 1 2 3 4
#对列索引进行排序,降序排列
b.sort_index(axis=1,ascending=False)
Out[374]:
e d c b a
0 4 3 2 1 0
1 9 8 7 6 5
2 14 13 12 11 10
3 19 18 17 16 15
按照列值排序
.sort_values()
在指定轴上根据数值进行排序,默认升序,格式.sort_values(axis=0,ascending=True)
Series.sort_value(axis=0,ascending=True)
DataFrame.sort_values(by,axis=0,ascending=True),by:axis轴上的某个索引或索引列表
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','b','d'])
b
Out[376]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
b 10 11 12 13 14
d 15 16 17 18 19
#第二列降序排列
c = b.sort_values(2,ascending=False)
c
Out[378]:
0 1 2 3 4
d 15 16 17 18 19
b 10 11 12 13 14
a 5 6 7 8 9
c 0 1 2 3 4
c = c.sort_values('a',axis=1,ascending=False)
c
Out[380]:
4 3 2 1 0
d 19 18 17 16 15
b 14 13 12 11 10
a 9 8 7 6 5
c 4 3 2 1 0
注意
在Pandas排序中NaN会同意放到排序的末尾
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4),index=['a','b','c'])
a
Out[383]:
0 1 2 3
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','b','d'])
b
Out[385]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
b 10 11 12 13 14
d 15 16 17 18 19
c = a+b
c
Out[387]:
0 1 2 3 4
a 5.0 7.0 9.0 11.0 NaN
b 14.0 16.0 18.0 20.0 NaN
c 8.0 10.0 12.0 14.0 NaN
d NaN NaN NaN NaN NaN
c.sort_values(2,ascending =False)
Out[388]:
0 1 2 3 4
b 14.0 16.0 18.0 20.0 NaN
c 8.0 10.0 12.0 14.0 NaN
a 5.0 7.0 9.0 11.0 NaN
d NaN NaN NaN NaN NaN
c.sort_values(2,ascending =True)
Out[389]:
0 1 2 3 4
a 5.0 7.0 9.0 11.0 NaN
c 8.0 10.0 12.0 14.0 NaN
b 14.0 16.0 18.0 20.0 NaN
d NaN NaN NaN NaN NaN
7.2Pandas库基本统计分析
基本的统计分析函数
#以下函数都适用于Series和DataFrame类型
.sum:计算数据的综合,按0轴计算,默认都是0轴
.count:计算非NaN值的数量
.mean() .median():计算数据的算术平均值,算术中位数
.var() .std:计算数据的方差,标准差
.min() .max():计算数据的最小值,最大值
.describe():针对0轴(各列)的统计汇总(这是大招)
#以下函数只适用于Series类型
.argmin() .argmax():计算数据最大值,最小值所在位置的索引位置(自动索引)
.idxmin() .idxmax():计算数据最大值,最小值所在位置的索引(自定义索引)
import pandas as pd
a = pd.Series([9,8,7,6],index=['a','b','c','d'])
a
Out[393]:
a 9
b 8
c 7
d 6
dtype: int64
#describe()方法的使用
a.describe()
Out[395]:
count 4.000000
mean 7.500000
std 1.290994
min 6.000000
25% 6.750000
50% 7.500000
75% 8.250000
max 9.000000
dtype: float64
type(a.describe())
Out[396]: pandas.core.series.Series
a.describe()['count']
Out[397]: 4.0
a.describe()['max']
Out[398]: 9.0
######################################################
import pandas as pd
import numpy as np
b =pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
b
Out[402]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
#注意函数执行的结果,针对0轴的执行
b.describe()
Out[403]:
0 1 2 3 4
count 4.000000 4.000000 4.000000 4.000000 4.000000
mean 7.500000 8.500000 9.500000 10.500000 11.500000
std 6.454972 6.454972 6.454972 6.454972 6.454972
min 0.000000 1.000000 2.000000 3.000000 4.000000
25% 3.750000 4.750000 5.750000 6.750000 7.750000
50% 7.500000 8.500000 9.500000 10.500000 11.500000
75% 11.250000 12.250000 13.250000 14.250000 15.250000
max 15.000000 16.000000 17.000000 18.000000 19.000000
#注意DataFrame和Series(b.describe)类型
type(b.describe())
Out[404]: pandas.core.frame.DataFrame
b.describe().max
Out[411]:
<bound method DataFrame.max of 0 1 2 3 4
count 4.000000 4.000000 4.000000 4.000000 4.000000
mean 7.500000 8.500000 9.500000 10.500000 11.500000
std 6.454972 6.454972 6.454972 6.454972 6.454972
min 0.000000 1.000000 2.000000 3.000000 4.000000
25% 3.750000 4.750000 5.750000 6.750000 7.750000
50% 7.500000 8.500000 9.500000 10.500000 11.500000
75% 11.250000 12.250000 13.250000 14.250000 15.250000
max 15.000000 16.000000 17.000000 18.000000 19.000000>
b.describe()[2].max
Out[412]:
<bound method Series.max of count 4.000000
mean 9.500000
std 6.454972
min 2.000000
25% 5.750000
50% 9.500000
75% 13.250000
max 17.000000
Name: 2, dtype: float64>
累计统计分析函数
#适用于Series和DataFrame类型,累计计算
.cumsum():依次给出前1,2.....n个数的和
.cumprod():依次给出前1,2....n个数的积
.cummax():依次给出前1,2....n个数的最大值
.cummin():依次给出前1,2....n个数的最小值
#适用于Series和DataFrame类型,滚动计算(窗口计算)
.rolling(w).sum():依次计算相邻w个元素的和
.rolling(W).mean():依次计算相邻w个元素的算术平均值
.rowlling(w).var():依次计算相邻w个元素的方差
.rolling(w).std():依次计算相邻w个元素的标准差
.rolling(w).min() .max():依次计算相邻w个元素的最小值和最大值
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
b
Out[414]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
b.cumsum()
Out[415]:
0 1 2 3 4
c 0 1 2 3 4
a 5 7 9 11 13
d 15 18 21 24 27
b 30 34 38 42 46
b.cumprod()
Out[417]:
0 1 2 3 4
c 0 1 2 3 4
a 0 6 14 24 36
d 0 66 168 312 504
b 0 1056 2856 5616 9576
b.cummin()
Out[418]:
0 1 2 3 4
c 0 1 2 3 4
a 0 1 2 3 4
d 0 1 2 3 4
b 0 1 2 3 4
b.cummax()
Out[419]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
####累计统计分析函数,滚动计算
import pandas as pd
import numpy as np
b = pd.DataFrame(np.arange(20).reshape(4,5),index=['c','a','d','b'])
b
Out[421]:
0 1 2 3 4
c 0 1 2 3 4
a 5 6 7 8 9
d 10 11 12 13 14
b 15 16 17 18 19
#计算相邻2个数的和
b.rolling(2).sum()
Out[422]:
0 1 2 3 4
c NaN NaN NaN NaN NaN
a 5.0 7.0 9.0 11.0 13.0
d 15.0 17.0 19.0 21.0 23.0
b 25.0 27.0 29.0 31.0 33.0
#计算相邻三个数的和
b.rolling(3).sum()
Out[423]:
0 1 2 3 4
c NaN NaN NaN NaN NaN
a NaN NaN NaN NaN NaN
d 15.0 18.0 21.0 24.0 27.0
b 30.0 33.0 36.0 39.0 42.0
7.3数据的相关分析
相关分析
两个事务之间的相关性
- 正相关:X增大,Y增大,我们说两个变量正相关
- 负相关:X增大,Y减小
- 不相关:X变化(增大,或减小),Y无视
表示两个事物相关性函数
-
协方差
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i1odtwNk-1596355463917)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593854899197.png)]
-
Person相关系数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IKHSEDAF-1596355463918)(C:\Users\Adopat\AppData\Roaming\Typora\typora-user-images\1593854970051.png)]
-
相关分析函数
#适用于Series和DataFrame类型 .cov():计算协方差矩阵 .corr():计算相关系数矩阵,Person,Spearman(),Kendall等系数 -
案例:房价增幅与M2增幅的相关性
import pandas as pd hprice = pd.Series([3.04,22.93,12.75,22.6,12.33],index=['2008','2009','2010','2011','2012']) hprice Out[426]: 2009 3.04 2009 22.93 2010 12.75 2011 22.60 2012 12.33 dtype: float64 m2 = pd.Series([8.18,18.38,9.13,7.82,6.69],index=['2008','2009','2010','2011','2012']) hprice.corr(m2) Out[432]: 0.5239439145220387
7.4本章小结
我们得到一组数据的摘要,可以做以下事情
- 排序 .sort_index() .sort_values()
- 基本统计函数 .describe()
- 累计统计函数 .cum* ,.rolling().*()
- 相关性分析 .corr() .cov()
第八章数据载入,存储及文件格式
8.1文本格式数据的读写
将表格型数据读取为DataFrame对象是pandas的重要特性,下面例举了部分功能函数
read_csv:从文件,URL或文件型对象读取好分割好的数据,逗号是默认分隔符
read_table:从文件,URL或文件型对象中读取好分隔好的数据,制表符('\t')默认分割
read_fwf:从指定宽度格式的文件中读取数据
read_excel:从excel的XLS或XLSX文件中读取表格数据
read_html:从HTML文件中读取所有表格数据
read_json:从JSON字符串中读取数据
read_sql:将SQL查询的结果(使用SQLAlchemy)读取为pandas的DataFrame
read_stata:读取Stata格式的数据集
read_feather:读取Feather二进制格式
一些常用的read_csv 和read_table 参数
path:表明文件系统位置的字符串,URL或文件型对象
sep或delimiter:用于分割每行的字符序列或者正则表达式
header:用作列名的行号,默认是0(第一行),如果没有列名的话,应该为None
names:结果的列名列表,和header=None一起使用
skiprows:从文件的开头起,需要调过的行数或者行号列表
na_values:需要用NA替换的值序列
skip_footer:忽略文件尾部的行数
nrows:从文件开头读入的行数
实例
#read_csv的使用,
import numpy as np
import pandas as pd
df = pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex1.csv")
df
Out[240]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
#使用read_table,并指定分隔符','注意csv默认的分隔符就是',',注意在sep中可以填写正则表达式,因为有的时候,分隔符并不是固定的
pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex1.csv",sep=',')
Out[241]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
#有些文件并不包含表头行,可以让pandas 自动默认分配列名,也可以指定列名
#pandas自动分配列名
pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex2.csv",header=None)
Out[243]:
0 1 2 3 4
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
#指定列名
pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex2.csv",names=['a','b','c','d','message'])
Out[244]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
#读取函数有很多附加的参数可以帮助我们处理各种发生异常的文件,例如我们可以利用skiprows来跳过第一行和第三行和第四行
list(open("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex4.csv"))
Out[249]:
['# hey!\n',
'a,b,c,d,message\n',
'# just wanted to make things more difficult for you\n',
'# who reads CSV files with computers, anyway?\n',
'1,2,3,4,hello\n',
'5,6,7,8,world\n',
'9,10,11,12,foo']
pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex4.csv",skiprows=[0,2,3])
Out[250]:
a b c d message
0 1 2 3 4 hello
1 5 6 7 8 world
2 9 10 11 12 foo
#缺失值的处理是文件解析过程中一个非常重要且常常微妙的部分,通常情况下,缺失值要么不显示(空字符串),要么用一些标识符,默认情况下,pandas使用一些常见的标识符,NA和NULL,na_values选项可以传入一个列表或一组字符串来处理缺失值
list(open("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex5.csv"))
Out[251]:
['something,a,b,c,d,message\n',
'one,1,2,3,4,NA\n',
'two,5,6,,8,world\n',
'three,9,10,11,12,foo']
pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex5.csv",na_values=['NULL'])
Out[252]:
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
8.1.1分块读入文本文件
当处理大型文件或找出正确的参数集来正确处理大文件时,我们需要使用到将文件读取一个小片段或者按一小块遍历文件。两种方法
- nrows:读取前几行
- chunksize:指定chunksize作为每一块的行数
#在尝试大文件之前,我们先对pandas的显示设置进行调整,使之更为紧凑
pd.options.display.max_rows=10
result =pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex6.csv")
result
Out[255]:
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
... ... ... ... ..
9995 2.311896 -0.417070 -1.409599 -0.515821 L
9996 -0.479893 -0.650419 0.745152 -0.646038 E
9997 0.523331 0.787112 0.486066 1.093156 K
9998 -0.362559 0.598894 -1.843201 0.887292 G
9999 -0.096376 -1.012999 -0.657431 -0.573315 0
[10000 rows x 5 columns]
#使用nrows,读取前几行数据
pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex6.csv",nrows=5)
Out[256]:
one two three four key
0 0.467976 -0.038649 -0.295344 -1.824726 L
1 -0.358893 1.404453 0.704965 -0.200638 B
2 -0.501840 0.659254 -0.421691 -0.057688 G
3 0.204886 1.074134 1.388361 -0.982404 R
4 0.354628 -0.133116 0.283763 -0.837063 Q
#使用chunksize
chunker = pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex6.csv",chunksize=1000)
chunker
Out[258]: <pandas.io.parsers.TextFileReader at 0x2d1ffcde7c8>
#后续可以对chunker进行遍历
8.1.2将数据写入文本格式
使用to_csv方法,常用的参数
- sep,导出的时候指定分隔符
- na_rep,写入文本格式的时候对缺失值进行处理
- 禁止行列标签的写入,index=False,header=False
- 写入列的子集,columns
- Series也有to_csv方法
#默认写入的文件是以','分隔的
data = pd.read_csv("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\\pydata-book-2nd-edition\\examples\\ex5.csv")
data
Out[261]:
something a b c d message
0 one 1 2 3.0 4 NaN
1 two 5 6 NaN 8 world
2 three 9 10 11.0 12 foo
data.to_csv("C:\\myNote\\data_analyse\\out.csv")
#sep指定分隔符,sys.stdout,控制台打印文本的结果
import sys
data.to_csv(sys.stdout,sep='|')
|something|a|b|c|d|message
0|one|1|2|3.0|4|
1|two|5|6||8|world
2|three|9|10|11.0|12|foo
#缺失值在输出时以空字符串出现,对空字符串处理
##data.to_csv("C:\\myNote\\data_analyse\\out.csv",na_rep='NULL')
data.to_csv(sys.stdout,na_rep='NULL')
,something,a,b,c,d,message
0,one,1,2,3.0,4,NULL
1,two,5,6,NULL,8,world
2,three,9,10,11.0,12,foo
#禁止杭列标签写入
data.to_csv(sys.stdout,index=False,header=False)
one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo
#写入子集
data.to_csv(sys.stdout,index=False,columns=['a','b','c'])
a,b,c
1,2,3.0
5,6,
9,10,11.0
8.1.3使用分隔格式
8.1.4JSON数据
JSON(JavaScript Object Notation),已经成为web浏览器和其他应用间通过HTTP请求发送数据的标准格式,它是一种比CSV等表格文本形式更为自由的数据形式。
将JSON字符串转为Python形式,使用json.loads方法,另一方面,json.dumps可以将Python对象转换为JSON:
obj ="""
{"name":"Wes",
"place_lived":["United States","Spain","Germany"],
"pet":null,
"sibling":[{"name":"Scott","age":30,"Pets":["Zeus","Zuko"]},
{"name":"Katie","age":38,"Pets":["Sixes","Stache","Cisco"]}]
}
"""
import json
result = json.loads(obj)
result
{
'name': 'Wes',
'place_lived': ['United States', 'Spain', 'Germany'],
'pet': None,
'sibling': [{
'name': 'Scott', 'age': 30, 'Pets': ['Zeus', 'Zuko']},
{
'name': 'Katie', 'age': 38, 'Pets': ['Sixes', 'Stache', 'Cisco']}]}
asjson = json.dumps(result)
asjson
Out[275]: '{"name": "Wes", "place_lived": ["United States", "Spain", "Germany"], "pet": null, "sibling": [{"name": "Scott", "age": 30, "Pets": ["Zeus", "Zuko"]}, {"name": "Katie", "age": 38, "Pets": ["Sixes", "Stache", "Cisco"]}]}'
pandas.read_json可以自动的将JSON数据集按照指定的次序,转换为Series或DataFrame,默认时将JSON数组中的每一个对象转换为一行。
pd.to_json:是将pandas中的数据导出为JSON
list(open("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\pydata-book-2nd-edition\\examples\\example.json"))
Out[278]:
['[{"a": 1, "b": 2, "c": 3},\n',
' {"a": 4, "b": 5, "c": 6},\n',
' {"a": 7, "b": 8, "c": 9}]\n']
data = pd.read_json("C:\\myNote\\data_analyse\\Python for Data Analysis, 2nd Edition\pydata-book-2nd-edition\\examples\\example.json")
data
Out[277]:
a b c
0 1 2 3
1 4 5 6
2 7 8 9
8.1.5XML和HTML:网络抓取
设计到爬虫,以后再补充。
8.2二进制格式
8.2.1使用HDF5格式
8.2.2读取Microsoft Excel文件
pandas也支持通过ExcelFile类或pandas.read_excel函数来读取存储在Excel文件表格中的数据。这些工具使用附加包xlrd和openpyxl来分别读取XLS和XLSX文件。
8.3与web API交互
许多网站都有公开的API,通过JSON或其他格式提供数据服务,有很多种方式可以利用Python来访问API,一般通过requests包
import requests
url ='https://api.github.com/repos/pandas-dev/pandas/issues'
resp = requests.get(url)
resp
#状态码200代表响应成功
Out[289]: <Response [200]>
#Response响应对象的json方法返回一个包含解析为本地Python对象的JSON的字典
data = resp.json()
data[0]['title']
Out[291]: 'BUG: Segmentation faults in pd.read_csv for large files'
8.4与数据库交互
当从数据库的表中选择数据时,大部分的Python的SQL驱动(PyODBC,psycopg2,MySQLdb,pymssql)返回的都是元组的列表。
为了方便,我们可以使用一个流行的Python SQL工具包,抽象去除了SQL数据库之间的许多常见差异。pandas有一个read_sql函数,允许你从通用的SQLAlchemy连接中轻松的读取数据。
import pandas as pd
import sqlalchemy as sqla
db = sqla.create_engine('sqlite:///mydata.sqlite')
pd.read_sql('select * from test',db)
8.5本章小结
访问数据通常时数据分析的第一步。
第九章数据清洗与准备
9.1处理缺失值
缺失数据在日常分析中是会经常出现的,我们对待缺失值,一般由两种方法,意识过滤缺失值,二是补全缺失值。
在Python中,将缺失值置为NA,意思时not available(不可用),NA数据可以是不存在的数据或者存在但不观察的数据(例如在数据收集过程中出现了问题),当清洗数据用于分析时,对缺失数据本身进行分析以确定数据收集问题或数据丢失导致的数据偏差通常很重要。
NA处理方法
- dropna:
- fillna
- isnull
- notnull:isnull的反函数。
9.1.1过滤缺失值
使用dropna
-
在Series上使用
from numpy import nan as NA import pandas as pd data = pd.Series([1,NA,3.5,NA,7]) data.dropna() Out[312]: 0 1.0 2 3.5 4 7.0 dtype: float64 #等价于 data[data.notnull()] Out[313]: 0 1.0 2 3.5 4 7.0 dtype: float64 -
在DataFrame上使用,注意在DataFrame上使用默认删除的包含缺失值的行。两个重要的参数,how=‘all’,所有值均为NA才删除,axis=1,删除列上包含NA的数据
import pandas as pd from numpy import nan as NA data = pd.DataFrame([[1.,6.5,3.],[1.,NA,NA],[NA,NA,NA],[NA,6.5,3.]]) data Out[322]: 0 1 2 0 1.0 6.5 3.0 1 1.0 NaN NaN 2 NaN NaN NaN 3 NaN 6.5 3.0 #默认删除的是行,带有NA的数据 data.dropna() Out[323]: 0 1 2 0 1.0 6.5 3.0 #参数how=all,删除的是全为na的行 data.dropna(how='all') Out[324]: 0 1 2 0 1.0 6.5 3.0 1 1.0 NaN NaN 3 NaN 6.5 3.0 #删除列上有NA的数据 data.dropna(axis=1) Out[325]: Empty DataFrame Columns: [] Index: [0, 1, 2, 3]
9.1.2补全缺失值
fillna:补全缺失值
fillna函数的参数
value:标量值或字典对象用于填充缺失值
method:插值方法,如果没有其他参数,默认是ffill,默认向前填充
axis:需要填充的轴,默认axis=0
inplace:修改被调用的对象,而不是生成一个备份
limit:用于前向或后向填充时的最大范围。
9.2数据转换
9.2.1删除重复值
DataFrame的duplicated方法返回的是一个布尔值的Series,反映的是每一行是否存在重复,drop_duplicates删除重复的行,如果想基于列去除重复值,请在drop_duplicates中指明列索引。
import pandas as pd
data = pd.DataFrame({
'k1':['one','two']*3+['two'],
'k2':[1,1,2,3,3,4,4]})
data
Out[329]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
data.duplicated()
Out[331]:
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
#使用drop_duplicates()默认是按照行来删除
data.drop_duplicates()
Out[332]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
data['V1']=range(7)
data
Out[334]:
k1 k2 V1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
5 two 4 5
6 two 4 6
#基于列k1去除重复值
data.drop_duplicates(['k1'])
Out[335]:
k1 k2 V1
0 one 1 0
1 two 1 1
9.2.2使用函数或映射进行数据转换
Series的map方法接受一个函数或一个包含映射关系的字典型对象,
#数据准备
import pandas as pd
data = pd.DataFrame({
'food':['bacon','pulled pork','bacon','Pastrami','corned beef','Bacon','pastami','honey ham','nova lox'],'ounces':[4,3,12,6,7.5,8,3,5,6]})
#添加一列食物和肉的对应关系,要添加列直接使用data['列名']=数据(可以是列表)
#准备数据
meat_to_animal ={
'bacon':'pig','pulled pork':'pig','pastrami':'cow','corned beef':'cow','honey ham':'pig','nova lox':'salmon'}
#因为food这一列有大写和小写,所以我们想转换位全部小写,使用str.lower()方法
lowercased = data['food'].str.lower()
lowercased
Out[341]:
0 bacon
1 pulled pork
2 bacon
3 pastrami
4 corned beef
5 bacon
6 pastami
7 honey ham
8 nova lox
Name: food, dtype: object
data['animal'] = lowercased.map(meat_to_animal)
#至此animal列就根据映射关系,成功添加了
data
Out[344]:
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastami 3.0 NaN
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
9.2.3替代值
使用fillna填充缺失值是通用值替换的特殊案例,但是使用replace提供了更为简单灵活的实现。注意替换是新生成了Series类型
data = pd.Series([1.,-999.,2.,-999.,-1000.,3.])
data
Out[346]:
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64
#-999是缺失的标识,我们使用NA来替代这些值
import numpy as np
from numpy import nan as NA
data.replace(-999,np.nan)
Out[350]:
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
data
Out[351]:
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64
#如果想要一次替代多个值,可以传入一个列表的替代值
data.replace([-999,-1000],np.nan)
Out[352]:
0 1.0
1 NaN
2 2.0
3 NaN
4 NaN
5 3.0
dtype: float64
9.2.4重命名轴索引
和Series中的值一样,可以通过函数或某种形式的映射对轴标签进行类似的转换,生成新的且带不同标签的对象。与Series类似,轴索引也有一个map方法。如果你想要创建数据集转换后的版本,并且不修改原有的数据集,一个有用的方法是rename.值得注意的是rename可以结合字典型对象使用,为轴标签的子集提供新的值。
9.2.5离散化和分箱
连续值经常需要离散化,或者分离成箱子进行分析。
- pd.cut():返回的是一个特殊的Categorical对象,他表示每个元素所属的箱号
- pd.value+counts(pd.cut):统计每个箱的数量
#题目要求,我要按照年龄统计每个年龄段的人数,应该怎么处理
#1.假设年龄段为18~25,26~35,36~60 以及61以上的
#代码实现
ages = [20,22,25,27,21,23,37,31,61,45,41,32]
bins =[18,25,35,60,100]
cats = pd.cut(ages,bins)
cats
Out[356]:
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35, 60], (35, 60], (25, 35]]
Length: 12
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
pd.value_counts(cats)
Out[357]:
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
9.2.6检测和过滤异常值
在应用数组上我们经常要考虑过滤和转换异常值。
data = pd.DataFrame(np.random.randn(100,4))
data
Out[360]:
0 1 2 3
0 0.256370 1.206451 -0.250623 -0.490618
1 0.086029 2.734672 0.300791 -0.727023
2 0.910596 -0.596432 0.824077 -1.799165
3 1.847591 1.271328 0.447315 -0.724476
4 1.458175 0.328289 -1.178216 1.040479
.. ... ... ... ...
95 0.699515 0.033444 -0.047757 0.614056
96 0.158687 0.645310 0.397701 0.097307
97 0.065476 0.784990 0.171994 1.789133
98 1.497801 0.636659 0.083449 -1.146317
99 -0.753255 -1.221215 1.540047 -0.508392
[100 rows x 4 columns]
#descibe方法的使用
data.describe()
Out[362]:
0 1 2 3
count 100.000000 100.000000 100.000000 100.000000
mean 0.140489 0.013455 0.018331 0.113191
std 0.887073 0.858852 0.767685 0.943900
min -2.329136 -2.893360 -1.748497 -1.799165
25% -0.555574 -0.459060 -0.511203 -0.547458
50% 0.210579 0.048072 0.074433 0.065043
75% 0.716114 0.489755 0.452930 0.742049
max 2.466170 2.734672 1.602460 2.309753
#找出一列绝对值>3的值
col =data[2]
col[np.abs(col)>3]
Out[364]: Series([], Name: 2, dtype: float64)
9.2.7置换和随机抽样
9.2.8计算指标/虚拟变量
9.3字符串操作
9.3.1字符串对象方法
9.3.2正则表达式
9.3.3pandas中向量话字符串函数
9.4本章小结
第十章数据规整,连接,联合与重塑
10.1分层索引
10.1.1重排序和层级排序
10.1.2按照层级进行汇总统计
10.1.3使用DataFrame的列进行索引
10.2联合与合并数据集
10.2.1数据库风格的DataFrame连接
10.2.2根据索引合并
10.2.3沿轴向连接
10.2.4联合重叠数据
10.3重塑和透视
10.3.1使用多层索引进行重塑
10.3.2将长透视为宽
10.3.3将宽透视为长
10.4本章小结
第十一章用户画像
11.1用户画像
用户画像是指根据用户的属性,用户偏好,生活习惯,用户行为等信息而抽象出来的标签化用户模型。通俗说就是给用户打标签,而标签是通过对用户信息分析而来的高度精炼的特征标识。通过打标签可以利用一些高度概括,容易理解的特征来描述用户,可以让人更容易理解用户,并且可以方便计算机处理。
标签化就是数据的抽象能力
- 互联网下半场精细化运营僵尸长久的主题
- 用户是根本,也是数据分析的出发点
11.2用户画像的准则
- 统一化:同一标识用户ID,如使用手机号,微信号,微博等
- 标签化:给用户打标签,对用户行为进行理解
- 业务化:由用户标签,知道用户关联。
11.2.1用户画像建模步骤
用户画像建模共分为三步:
-
统一化:统一用户的唯一标识,(用户的唯一标识用于用户行为的串联)
-
标签化:给用户打标签,即用户画像
对用户标签话,可以进行用户消费行为分析
- 用户标签:基础信息如性别,年龄,地域等
- 消费标签:消费习惯,购买意向,是否对促销敏感
- 行为标签:时间段,频次,访问路径等
- 内容分析:页面停留时长,内容浏览,分析用户感兴趣的内容
因此用户画像是现实世界中的用户的数学建模
-
业务化:将用户画像,指导业务关联,当得到了精准的用户画像,那么就可以为企业更精准的解决问题,业务推荐等。
11.3用户生命周期
- 获客:拉新,精准营销获取客户,找到优势的宣传渠道。
- 粘客:场景运营,个性化运营,提高用户使用频率,比如说可以通过红包,优惠等方式激励优惠敏感人群
- 留客:流失率的预测,降低流失率,顾客流失率降低5%,公司利润提升25%~85%
11.4用户画像建模过程
按照数据流处理阶段划分用户画像建模的过程,分为三个层,每一层次,都需要打上不同的标签
- 数据层:用户消费行为的标签,打上事实标签,作为数据客观的记录
- 算法层:透过行为算出的用户建模,打上模型标签,作为用户画像的分类
- 业务层:指的是获客,粘客,留客的手段,打上预测标签,作为业务关联的结果。
在建模过程中涉及到的主要技术有:
- 信息检索
- 机器学习
- 统计学
- 大数据存储
- 大数据实时计算
- NLP
11.5标签化的作用
数据挖掘的最终目的不是处理EB级别的大数据,而是理解,使用这些数据挖掘的结果。对数据标签化能让我们快速理解一个用户,一个商品,乃至一个视频内容的特征,从而方便我们去理解和使用数据。而数据标签化实际上考研我们的抽象能力:如何将繁杂的事务简单化。
11.5.1标签的层次性
目前主流的标签体系都是层次化的,如下图所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uLAdLcDw-1596355463920)(C:\myNote\data_analyse\python_code\标签体系的层次化.PNG)]
标签分为好几个打雷,每个大类下进行逐层细分。在构建标签时,我们只需要构建最下层的标签,就能够映射到上面两级标签。上层标签都是抽象的标签集合,一般没有实用意义,只有统计意义。例如我们可以统计有人口属性标签的用户比例,但用户有人口属性标签本身对广告投放没有任何意义。
11.5.2标签构建的优先级
构建的优先级需要综合考虑业务需求,构建难以程度等,业务需求各有不同。这里介绍的优先级排序方法主要依据构建的难易程度和各类标签的依存关系,优先级如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QpnohT93-1596355463921)(C:\myNote\data_analyse\python_code\标签构建的优先级.PNG)]
我们把标签分为三类,这三类标签有较大的差异,构建时用到的技术差别也很大。第一类时人口属性,这类标签比较稳定,一旦建立很长一段时间基本不用更新,标签体系也比较固定。第二类是兴趣属性,这类标签随时间变化很快,标签有很强的时效性,标签体系也不固定;第三类是地理属性,这一类标签的时效性跨度很大,如GPS轨迹标签需要做到实时更新,而常住地标签一般可以几个月不用更新,挖掘的方法和前面两类也大有不同,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dprkkgtl-1596355463923)(C:\myNote\data_analyse\python_code\标签的分类.PNG)]
第十二章用Python来获取数据
12.1获取本地数据
获取本地数据采用open方法,读写文件有三种模式(r,w,a)
#写文件。注意out输出的是字符个数
f =open("C:\\myNote\\data_analyse\\test.py")
f =open("C:\\myNote\\data_analyse\\test.py",'w')
f.write('a=3\n')
Out[58]: 4
f.write('b=4\n')
Out[59]: 4
f.write('sum =a+b\n')
Out[60]: 9
f.write('print(sum)\n')
Out[61]: 11
#关闭流
f.close()
%run C:\\myNote\\data_analyse\\test.py
#读文件
f = open("C:\\myNote\\data_analyse\\test.py",'r')
#遍历文件f 打印内容,end=''不换行打印,print()中end="\n"默认参数是换行的
for line in f:
print(line,end='')
a=3
b=4
sum =a+b
print(sum)
f.close()
#追加文件
f = open("C:\\myNote\\data_analyse\\test.py",'a')
f.write("I love Python\n")
Out[69]: 14
f.close()
f = open("C:\\myNote\\data_analyse\\test.py",'r')
for line in f:
print(line,end='')
a=3
b=4
sum =a+b
print(sum)
I love Python
12.2用Python获取网络数据
网络数据的获取涉及到两个步骤,抓取网页,解析网页内容。
抓取
- urllib内建模块
- urllib.request
- Requests第三方库
- Scrapy框架
解析
- BeautifulSoup库
- re模块
12.2.1利用Requests库抓取网页数据
- Requests库是更简单,方便和人性化的Python HTTP第三方库
- 基本方法:requests.get()–请求指定URL位置的资源,对应HTTP协议的GET方法
练习一百度首页
import requests
r =requests.get("http://www.baidu.com")
print(r.status_code)
200
print(type(r))
<class 'requests.models.Response'>
r.encoding="utf-8"
print(r.url)
http://www.baidu.com/
print(r.headers['content-type'])
text/html
print(r.text)
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> 