【全景分割】Panoptic Segmentation阅读笔记
Introduction
Panoptic:including everything visible in one view
Panoptic Segmentation:为图片内的每个像素分配semantic label 和 instance id

stuff:可数的目标,如:人、动物、车
thing:具有相似纹理或者材料的不规则区域,如:草地、天空、马路
全景分割任务,从任务目标上可以分为 object instance segmentation 子任务与 stuff segmentation 子任务。
全景分割与实例分割,语义分割的不同:
与语义分割不同之处在于:语义分割不需要区分单个目标实例;
与实例分割不同之处在于:全景分割的目标不能重叠(non-overlapping)
Output Format:Stuff and thing labels
L \mathcal{L} L是semantic label 的集合: L : = { 0 , … , L − 1 } \mathcal{L} :=\{0, \dots, L-1\} L:={ 0,…,L−1}
全景分割为每个像素分配两个标签: ( l i , z i ) ∈ L × N \left(l_{i}, z_{i}\right) \in \mathcal{L} \times \mathbb{N} (li,zi)∈L×N
l i l_{i} li表示像素i的semantic class, z i z_{i} zi表示像素i的instance id
L \mathcal{L} L包括两个子集 L S t \mathcal{L}^{\mathrm{St}} LSt和 L T h \mathcal{L}^{\mathrm{Th}} LTh,分别对应stuff和thing标签,且满足如下关系:
L = L S t ∪ L T h \mathcal{L}=\mathcal{L}^{\mathrm{St}} \cup \mathcal{L}^{\mathrm{Th}} L=LSt∪LTh L S t ∩ L T h = ∅ \mathcal{L}^{\mathrm{St}} \cap \mathcal{L}^{\mathrm{Th}}=\emptyset LSt∩LTh=∅
l i ∈ L T h l_{i} \in \mathcal{L}^{\mathrm{Th}} li∈LTh时, ( l i , z i ) \left(l_{i}, z_{i}\right) (li,zi)相同,像素属于同一目标,即具有相同label和id的像素属于同一个目标;
l i ∈ L S t l_{i} \in \mathcal{L}^{\mathrm{St}} li∈LSt时, z i z_{i} zi忽略,即stuff只有semantic class,其instance id被忽略
注意:不是所有的像素都需要有一个semantic label
对于类别之外,或者不确定的像素可以分配一个void label,在检测和评估均被忽略
task metric
1、Theorem 1 unique matching

2、PQ computation
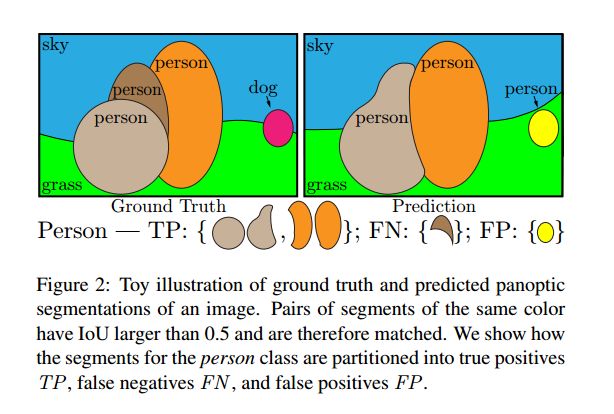
对每个类别,根据unique matching可以将predicted Segments 和 GT Segments分成三个子集:
TP:matched pairs of segments
FP:unmatched predicted segments
FN:unmatched ground truth segments
P Q = ∑ ( p , g ) ∈ T P IoU ( p , g ) ∣ T P ∣ ⎵ segmentation quality (SQ ) × ∣ T P ∣ ∣ T P ∣ + 1 2 ∣ F P ∣ + 1 2 ∣ F N ∣ ⎵ recognition quality (RQ) \mathrm{PQ}=\underbrace{\frac{\sum_{(p, g) \in T P} \operatorname{IoU}(p, g)}{|T P|}}_{\text { segmentation quality (SQ } )} \times \underbrace{\frac{|T P|}{|T P|+\frac{1}{2}|F P|+\frac{1}{2}|F N|}}_{\text { recognition quality (RQ) }} PQ= segmentation quality (SQ ) ∣TP∣∑(p,g)∈TPIoU(p,g)× recognition quality (RQ) ∣TP∣+21∣FP∣+21∣FN∣∣TP∣
RQ: F 1 F_{1} F1 Score
SQ: average IoU of matched segments
dataSet
