论文阅读理解 - Panoptic Segmentation 全景分割
论文阅读理解 - Panoptic Segmentation 全景分割
[Paper]
摘要
新的任务场景 —— 全景分割 Panoptic Segmentation:
统一了实例分割(Instance Segmentation) 和语义分割(Semantic Segmentation).
实例分割 - 检测每个 object instance,并进行分割;
语义分割 - 对每个像素分类.
新的评价指标 —— panoptic quality(PQ) measure
basic 算法 —— 结合实例分割和语义分割的全景分割方法,输出全景结果.
新的研究方向.
CV 以往主要关注于 things - 可数的 objects (countable obects),如 people, animals, tools 等.
而对于 stuff - 相同或相似纹理或材料的不规则区域,如 grass,sky,road 等的关注较少.
关于 Stuff 的研究主要是以语义分割的进行,如 Figure 1b. 其目的是,通过对图片中每一个像素分类,来确定不规则、无组织、不可数的 stuff;语义分割方法是将 thing categories 作为 stuff.
关于 Things 的研究可以作为目标检测或实例分割进行,如Figure 1c. 其目的是,通过检测每个 object,并以 bounding box 或 segmentation mask 的方式描述.
问题:
Can there be a reconciliation between stuff and things?
Is there a simple problem formulation that gracefully encompasses both tasks?
And what would a unified visual recognition system look like?
新的任务场景 - 全景分割 Panoptic Segmentation(PS)
全景(panoptic) - 对视野内所有物体进行描述”including everything visible in one view”
全景分割 - 图片内的每个像素都必须分配 semantic label 和 instance id. 如 Figure 1d.
相同 label 和相同 id 的像素属于相同 object;忽略 stuff labels 的 instance id.

Figure1. (a) 给定图片;(b)语义分割 groundtruth,逐像素的 class labels;(c)实例分割 groundtruth,逐 object 的 mask 和 class label;(d) 全景分割 groundtruth,逐像素的 class labels 和 instance labels. PS 将语义分割和实例分割泛化,对图片中的每一个可见 object 和 region 进行辨别与描述.
全景分割与实例分割,语义分割的不同:
- 对比语义分割,全景分割需要区分不同的 object instances;对于 FCN-based 方法具有挑战性.
- 对比实例分割,全景分割必须是非重叠的(non-overlapping);对于 region-based 方法具有挑战性.
- 全景分割需要同时识别 stuff 和 things.
全景分割度量评价.
全景分割的尝试研究,结合语义分割和实例分割两种独立的研究,采用一系列的后处理方法,将二者的结果进行合并(本质上是,NMS 的复杂形式). 给出初步的全景分割 baseline.
1. 全景分割
1.1 PS 定义
给定 L L 个语义 Categotries 的集合: L:={1,...,L} L := { 1 , . . . , L } ,
全景分割算法的目标是:将图片的每一个像素 i i 映射到一个 pair (li,zi)∈L×N ( l i , z i ) ∈ L × N .
其中, li l i - 像素 i i 的语义 class; zi z i - 像素 i i 的 instance id.
全景分割算法的输出是以 instances 为基本单元,而不是像素,并用于后续的分割结果度量评价.
图片的 groundtruth 标注也采用相同方式处理.
1.2 Stuff 和 Thing Labels
语义 label 集包括两个子集: LSt L S t 和 LTh L T h ,且 L=LSt∪LTh L = L S t ∪ L T h , LSt∩LTh=⊘ L S t ∩ L T h = ⊘ .
LSt L S t 和 LTh L T h 分别表示 stuff labels 和 thing labels.
如果像素的 label 为 li∈LSt l i ∈ L S t ,则其对应的 instance id zi z i 是不相关的.
即,对于 stuff categories,所有的像素都属于同一 instance(如都是 sky);否则,具有相同 (li,zi) ( l i , z i ) 的所有像素属于同一 instance (如都是 car),其中 li∈LTh l i ∈ L T h . 反之,属于同一 instance 的所有像素必须具有相同的 (li,zi) ( l i , z i ) .
1.3 与语义分割区别
相同之处:
均需要对图像的每个像素设定 semantic label.
如果 groundtruth 未指定 instances 信息,或者所有的 categories 都是 stuff,二者相同.
不同之处:
当有 thing categories 时,图片中有多个 instances 时,则二者有区别.
1.4 与实例分割区别
- 实例分割 - 对图片中的每个 object 进行分割,允许 objects 重叠(overlapping);
- 全景分割 - 图片每个像素只有一个 semantic label 和 一个 instance id. 不允许重叠.
1.5 Confidence scores
类似于语义分割,而不同于实例分割,全景分割不需要每个 segment 的confidence scores.
2. Panoptioc Quality
全景分割精度评价设计原则:
Completeness
完整性- 全景分割的关键性度量,包括 segmentation quality,检测 precision 和 recall.
Interpretability
可解释性 - 能够明确地表示其意义.
Simplicity
简单性 - 易于定义和实现. 能够进行快速计算.
提出全景分割的评价标准: Paniptic Quality(PQ).
PQ 计算预测的全景分割与 groundtruth 的差异. 主要包括两步:
- instance matching 实例匹配
- 给定 mathes,计算PQ.
2.1 Instance Matching
如果预测 segment 和 groundtruth segment 的 IOU > 0.5,则二者匹配(match).
再加上全景分割的非重叠属性(non-overlapping property),即可得到唯一的匹配(unique matching):与每个 ground truth segment 最多有一个匹配的预测 segment.
Theorem1.
给定图片的一个预测分割和 groundtruth 分割,每个 groundtruth 分割最多只能有一个对应的预测分割,且其 IoU 必须严格大于 0.5.
证明:
记 g g - groundtruth segment; p1 p 1 和 p2 p 2 - 两个 predicted segments,且 p1∩p2=⊘ p 1 ∩ p 2 = ⊘ (non-overlap); |p1∪p2|≥|g| | p 1 ∪ p 2 | ≥ | g | .
则有:
IoU(pi,g)=|pi∩g||pi∪g|≤|pi∩g||g|,i∈{ 1,2} I o U ( p i , g ) = | p i ∩ g | | p i ∪ g | ≤ | p i ∩ g | | g | , i ∈ { 1 , 2 }
由 p1∩p2=⊘ p 1 ∩ p 2 = ⊘ ,有 |p1∩g|+|p2∩g|≤|g| | p 1 ∩ g | + | p 2 ∩ g | ≤ | g | .
对 i∈{ 1,2} i ∈ { 1 , 2 } , 有:
IoU(p1,g)+IoU(p2,g)≤|p1∩g|+|p2∩g||g|≤1 I o U ( p 1 , g ) + I o U ( p 2 , g ) ≤ | p 1 ∩ g | + | p 2 ∩ g | | g | ≤ 1
因此,如果 IoU(p1,g)≥0.5 I o U ( p 1 , g ) ≥ 0.5 ,则 IoU(p2,g)<0.5 I o U ( p 2 , g ) < 0.5 .
即:只有一个预测 segment 与 groundtruth segment 的 IoU 严格大于 0.5.
Theorem 1 给出了全景分割度量评价需要的两种特点:
- 简单有效 - segment 是唯一且易于计算的.
- 可解释且易于理解
2.2 PQ 计算
先分别对每一类计算 PQ,再计算所有类的平均值. 对于类别不平衡问题,PQ 不敏感.
对于每一类,唯一匹配原则将 predicted 和 groundtruth segment 分成三个集:true positives(TP) - 匹配的 segments pairs,false positives(FP) - 不匹配的 predicted segments 和 false negatives(FN) - 不匹配的 grountruth segments. 如 Figure 2.
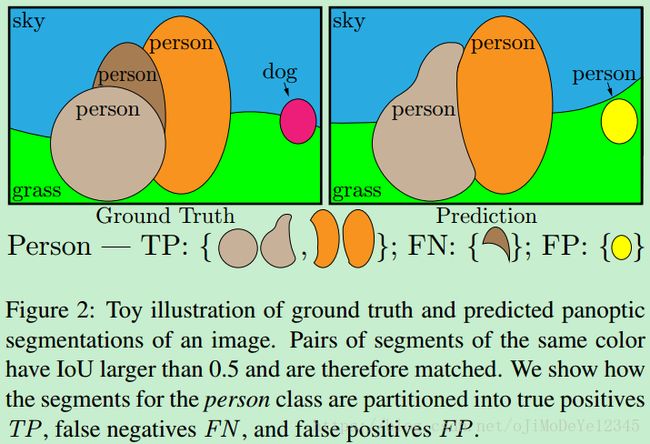
Figure 2. 图片全景分割的 groundtruth 和 predicted 结果. 相同颜色的 segments pairs 的 IoU 大于 0.5,被匹配到. 这里给出了 person 类的 segments 划分为 TP、FN 和 FP 的例子.
给定 TP、FP 和 FN, PQ 定义如下:
PQ=∑(p,g)∈TPIoU(p,g)|TP|+12|FP|+12|FN| P Q = ∑ ( p , g ) ∈ T P I o U ( p , g ) | T P | + 1 2 | F P | + 1 2 | F N |
∑(p,g)∈TPIoU(p,g) ∑ ( p , g ) ∈ T P I o U ( p , g ) 是匹配 segments 的平均 IoU;
12|FP|+12|FN| 1 2 | F P | + 1 2 | F N | 是惩罚(penalize) 没有匹配的 instances.
所有 segments 的权重一致,与其面积大小无关.
PQ 计算的等价形式:
PQ=∑(p,g)∈TPIoU(p,g)|TP|×|TP||TP|+12|FP|+12|FN| P Q = ∑ ( p , g ) ∈ T P I o U ( p , g ) | T P | × | T P | | T P | + 1 2 | F P | + 1 2 | F N |
可以看作是 Segmentation Quality(SQ) 和 Detection Quality(DQ) 的乘积.
SQ=∑(p,g)∈TPIoU(p,g)|TP| S Q = ∑ ( p , g ) ∈ T P I o U ( p , g ) | T P |
DQ=|TP||TP|+12|FP|+12|FN| D Q = | T P | | T P | + 1 2 | F P | + 1 2 | F N |
SQ 是匹配 objects 的平均 IoU.
DQ 类似于 F1-score,在检测任务中被用到.
PQ=SQ×DQ P Q = S Q × D Q
3. 全景分割数据集
现在仅有的三个同时包括语义分割和实例分割标注的数据集:
Cityscapes
5000 张图片,2975 张 train,500 张 validation, 1525 张 test.
自动驾驶场景;
像素级标注,19 类语义分割,其中 8 类实例级分割.
ADE20k
25k 张图片,20k 张 train, 2k val,3k test.
像素级分割,100 类 thing,50 类 stuff.
Mapillary Vistas
25k 张街景图片, 18k 张 train,2k 张 val,5k 张 test.
像素级分割,28 类 stuff,37 类 thing.
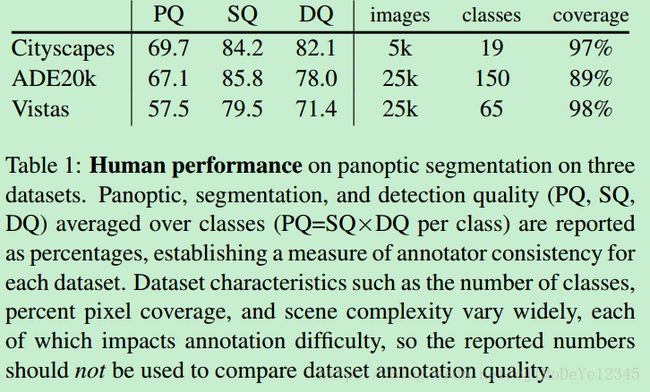
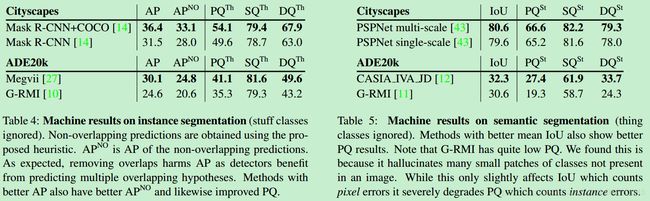
4. Results

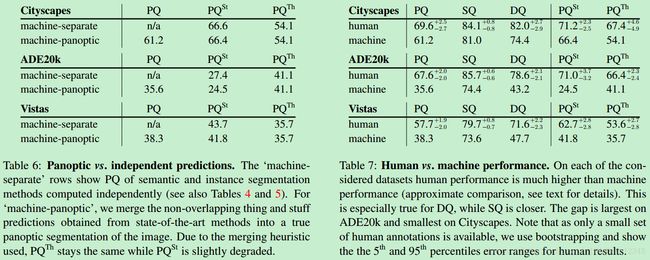
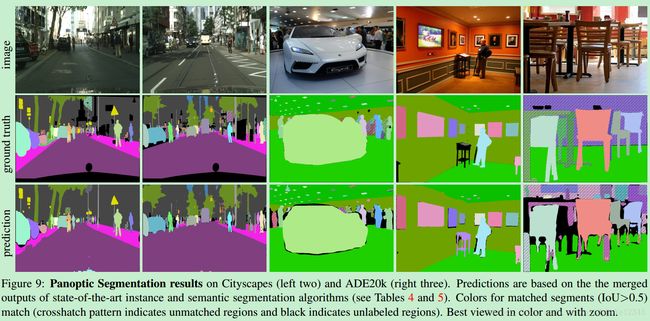
5. 全景分割的前景
全景分割作为计算视觉一个新的任务场景,其前景有待挖掘与探索.
PS baseline 算法仅是结合实例分割和语义分割的输出,其创新方向可有:
- 深度 End-to-end 模型,以同时处理 PS 中的 stuff-and-thing;
- 由于PS 不能有重叠 segments,高层的推理可能有帮助解决. 如 learnable NMS.