在业务高峰期拔掉服务器电源是一种怎样的体验?
大家好,我是冰河~~
不怕神一样的对手,就怕猪一样的队友,我经历了一次在业务高峰期毫无防备的情况下,被队友“拔”掉了服务器电源的“惨痛”经历。
当时的我在外面玩的正起劲,突然一个电话打来:“冰河,你在哪?服务器突然不能访问了!”。我:“又有什么情况啊?”。“我不小心踩到服务器电源连接的插线板了,服务器断电了,重启时提示无法启动”。我心里一万个无语,问:”是哪台服务器断电了“。“我不小心踩到那个小插线板的开关了,连接到这个插线板的服务器都断电了”。我:尼玛,那是数据库啊,我去。。。
于是我赶紧飞奔回公司,开始了苦逼的数据恢复过程。。。
文章已收录到:
https://github.com/sunshinelyz/technology-binghe
https://gitee.com/binghe001/technology-binghe
解决主库问题
主库问题重现
回到公司一看,断电的是公司的消息服务子系统数据库,数据库共3台,一种两从,并采用了分库分表的方式存储数据。我首先把三台服务器启动好,发现主数据库的进程无法启动,两台从数据库同步主库数据的状态异常。按照顺序,我先看主数据库的日志信息,发现MySQL的错误日志中输出了如下信息。
-----------------------------------------161108 23:36:45 mysqld_safe Starting mysqld daemon with
databases from /usr/local/mysql/var2021-02-28 23:36:46 0 [Warning] TIMESTAMP with implicit DEFAULT
value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation
for more details).2021-02-28 23:36:46 5497 [Note] Plugin 'FEDERATED' is disabled.2021-02-28 23:36:46
7f11c48e1720 InnoDB: Warning: Using innodb_additional_mem_pool_size is DEPRECATED. This option may be
removed in future releases, together with the option innodb_use_sys_malloc and with the InnoDB's
internal memory allocator.2021-02-28 23:36:46 5497 [Note] InnoDB: Using atomics to ref count buffer
pool pages2021-02-28 23:36:46 5497 [Note] InnoDB: The InnoDB memory heap is disabled2021-02-28
23:36:46 5497 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins2021-02-28 23:36:46 5497
[Note] InnoDB: Memory barrier is not used2021-02-28 23:36:46 5497 [Note] InnoDB: Compressed tables
use zlib 1.2.32021-02-28 23:36:46 5497 [Note] InnoDB: Using CPU crc32 instructions2021-02-28 23:36:46 5497 [Note] InnoDB: Initializing buffer pool, size = 16.0M2021-02-28 23:36:46 5497 [Note] InnoDB:
Completed initialization of buffer poolInnoDB: Database page corruption on disk or a failedInnoDB:
file read of page 5.InnoDB: You may have to recover from a backup.2021-02-28 23:36:46 7f11c48e1720
InnoDB: Page dump in ascii and hex (16384 bytes): len 16384; hex
7478d078000000050000000000000000000000000f271f4d000700000000000000000000000000000000001b4000000000000
000000200f20000000000000006000000000000002d000000000000002e000000000000002f0000000000000030000000000(
省略很多类似代码)InnoDB: End of page dump2021-02-28 23:36:46 7f11c48e1720 InnoDB: uncompressed page,
stored checksum in field1 1954074744, calculated checksums for field1: crc32 993334256, innodb
2046145943, none 3735928559, stored checksum in field2 1139795846, calculated checksums for field2:
crc32 993334256, innodb 1606613742, none 3735928559, page LSN 0 254222157, low 4 bytes of LSN at page end 254221236, page number (if stored to page already) 5, space id (if created with >= MySQL-4.1.1
and stored already) 0InnoDB: Page may be a transaction system pageInnoDB: Database page corruption on disk or a failedInnoDB: file read of page 5.InnoDB: You may have to recover from a backup.InnoDB: It
is also possible that your operatingInnoDB: system has corrupted its own file cacheInnoDB: and
rebooting your computer removes theInnoDB: error.InnoDB: If the corrupt page is an index pageInnoDB:
you can also try to fix the corruptionInnoDB: by dumping, dropping, and reimportingInnoDB: the
corrupt table. You can use CHECKInnoDB: TABLE to scan your table for corruption.InnoDB: See also
http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.htmlInnoDB: about forcing
recovery.InnoDB: Ending processing because of a corrupt database page.2021-02-28 23:36:46
7f11c48e1720 InnoDB: Assertion failure in thread 139714288817952 in file buf0buf.cc line 4201InnoDB: We intentionally generate a memory trap.InnoDB: Submit a detailed bug report to
http://bugs.mysql.com.InnoDB: If you get repeated assertion failures or crashes, evenInnoDB:
immediately after the mysqld startup, there may beInnoDB: corruption in the InnoDB tablespace. Please refer toInnoDB: http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.htmlInnoDB: about
forcing recovery.03:36:46 UTC - mysqld got signal 6 ;This could be because you hit a bug. It is also possible that this binaryor one of the libraries it was linked against is corrupt, improperly
built,or misconfigured. This error can also be caused by malfunctioning hardware.We will try our best
to scrape up some info that will hopefully helpdiagnose the problem, but since we have already
crashed,something is definitely wrong and this may
fail.key_buffer_size=16777216read_buffer_size=262144max_used_connections=0max_threads=1000thread_coun
t=0connection_count=0It is possible that mysqld could use up tokey_buffer_size + (read_buffer_size +
sort_buffer_size)*max_threads = 798063 K bytes of memoryHope that's ok; if not, decrease some
variables in the equation.Thread pointer: 0x0Attempting backtrace. You can use the following
information to find outwhere mysqld died. If you see no messages after this, something wentterribly
wrong...stack_bottom = 0 thread_stack 0x40000/usr/local/mysql/bin/mysqld(my_print_stacktrace+0x35)
[0x8e64b5]/usr/local/mysql/bin/mysqld(handle_fatal_signal+0x41b)
[0x652fbb]/lib64/libpthread.so.0(+0xf7e0)[0x7f11c44c77e0]/lib64/libc.so.6(gsignal+0x35)
[0x7f11c315d625]/lib64/libc.so.6(abort+0x175)
[0x7f11c315ee05]/usr/local/mysql/bin/mysqld[0xa585c5]/usr/local/mysql/bin/mysqld[0xa6c7b4]/usr/local/
mysql/bin/mysqld[0xa6cbc7]/usr/local/mysql/bin/mysqld[0xa5bce2]/usr/local/mysql/bin/mysqld[0xa1e2ba]/usr/local/mysql/bin/mysqld[0xa0bf60]/usr/local/mysql/bin/mysqld[0x95a427]/usr/local/mysql/bin/mysqld(_Z24ha_initialize_handlertonP13st_plugin_int+0x48)
[0x58f788]/usr/local/mysql/bin/mysqld[0x6e4a36]/usr/local/mysql/bin/mysqld(_Z11plugin_initPiPPci+0xb3e)
[0x6e826e]/usr/local/mysql/bin/mysqld[0x582d85]/usr/local/mysql/bin/mysqld(_Z11mysqld_mainiPPc+0x4d8)
[0x587d18]/lib64/libc.so.6(__libc_start_main+0xfd)
[0x7f11c3149d5d]/usr/local/mysql/bin/mysqld[0x57a019]The manual page at
http://dev.mysql.com/doc/mysql/en/crashing.html containsinformation that should help you find out
what is causing the crash.161108 23:36:46 mysqld_safe mysqld from pid file
/usr/local/mysql/var/VM_241_49_centos.pid
ended------------------------------------------------------------------------------
主库问题分析
从日志中可以看出是innodb引擎出了问题。日志里提示到 http://dev.mysql.com/doc/refman/5.6/en/forcing-innodb-recovery.html查看强制恢复的方法。在mysql的配置文件my.cnf里找到 [mysqld]字段下,添加 innodb_force_recovery=1:
[mysqld]innodb_force_recovery = 1
如果innodb_force_recovery = 1不生效,则可尝试2——6几个数字
然后重启mysql,重启成功。然后使用mysqldump或 pma 导出数据,执行修复操作等。修复完成后,把该参数注释掉,还原默认值0。
配置文件的参数:innodb_force_recovery
innodb_force_recovery影响整个InnoDB存储引擎的恢复状况。默认为0,表示当需要恢复时执行所有的恢复操作(即校验数据页/purge undo/insert buffer merge/rolling back&forward),当不能进行有效的恢复操作时,mysql有可能无法启动,并记录错误日志;
innodb_force_recovery可以设置为1-6,大的数字包含前面所有数字的影响。当设置参数值大于0后,可以对表进行select,create,drop操作,但insert,update或者delete这类操作是不允许的。
- (SRV_FORCE_IGNORE_CORRUPT):忽略检查到的corrupt页。
- (SRV_FORCE_NO_BACKGROUND):阻止主线程的运行,如主线程需要执行full purge操作,会导致crash。
- (SRV_FORCE_NO_TRX_UNDO):不执行事务回滚操作。
- (SRV_FORCE_NO_IBUF_MERGE):不执行插入缓冲的合并操作。
- (SRV_FORCE_NO_UNDO_LOG_SCAN):不查看重做日志,InnoDB存储引擎会将未提交的事务视为已提交。
- (SRV_FORCE_NO_LOG_REDO):不执行前滚的操作。
主库解决方案
一般修复方法参考:
第一种方法
建立一张新表:
create table demo_bak #和原表结构一样,只是把INNODB改成了MYISAM。
把数据导进去
insert into demo_bak select * from demo;
删除掉原表:
drop table demo;
注释掉 innodb_force_recovery 之后,重启。
重命名:
rename table demo_bak to demo;
最后改回存储引擎:
alter table demo engine = innodb
第二种方法
另一个方法是使用mysqldump将表格导出,然后再导回到InnoDB表中。这两种方法的结果是相同的。
备份导出(包括结构和数据):
mysqldump -uroot -p123 test > test.sql
还原方法1:
use test;source test.sql
还原方法2(系统命令行):
mysql -uroot -p123 test < test.sql;
注意,CHECK TABLE命令在InnoDB数据库中基本上是没有用的。
第三种方法
(1)配置my.cnf
配置innodb_force_recovery = 1或2——6几个数字,重启MySQL
(2)导出数据脚本
mysqldump -uroot -p123 test > test.sql
导出SQL脚本。或者用Navicat将所有数据库/表导入到其他服务器的数据库中。
注意:这里的数据一定要备份成功。然后删除原数据库中的数据。
(3)删除ib_logfile0、ib_logfile1、ibdata1
备份MySQL数据目录下的ib_logfile0、ib_logfile1、ibdata1三个文件,然后将这三个文件删除
(4)配置my.cnf
将my.cnf中innodb_force_recovery = 1或2——6几个数字这行配置删除或者配置为innodb_force_recovery = 0,重启MySQL服务
(5)将数据导入MySQL数据库
mysql -uroot -p123 test < test.sql; 或者用Navicat将备份的数据导入到数据库中。
此种方法下要注意的问题:
- ib_logfile0、ib_logfile1、ibdata1这三个文件一定要先备份后删除;
- 一定要确认原数据导出成功了
- 当数据导出成功后,删除原数据库中的数据时,如果提示不能删除,可在命令行进入MySQL的数据目录,手动删除相关数据库的文件夹或者数据库文件夹下的数据表文件,前提是数据一定导出或备份成功。
这里,我使用的是第三种方法恢复了主数据库的数据。
接下来,我们再来看看从数据库数据的恢复。
解决从库问题
主从复制原理
这里,我就简单的说下MySQL数据库的主从复制原理。
MySQL主从复制原理,也称为A/B原理。
(1) Master 将数据改变记录到二进制日志(binary log)中,也就是配置文件 log-bin 指定的文件, 这些记录叫做二进制日志事件(binary log events);
(2) Slave 通过 I/O 线程读取 Master 中的 binary log events 并写入到它的中继日志(relay log);
(3) Slave 重做中继日志中的事件,把中继日志中的事件信息一条一条的在本地执行一次,完 成数据在本地的存储,从而实现将改变反映到它自己的数据(数据重放)。
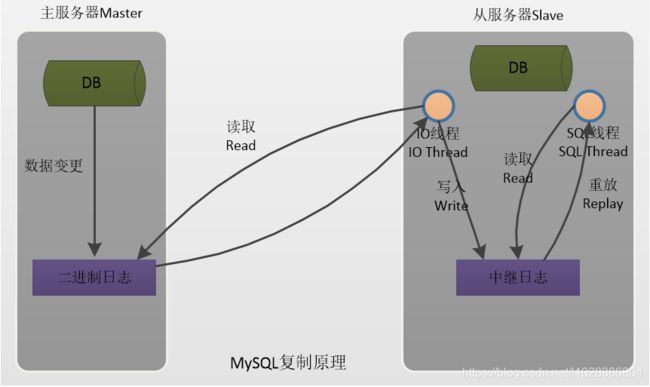
复制过滤可以让你只复制服务器中的一部分数据,有两种复制过滤:
(1) 在 Master 上过滤二进制日志中的事件;
(2) 在 Slave 上过滤中继日志中的事件。如下:
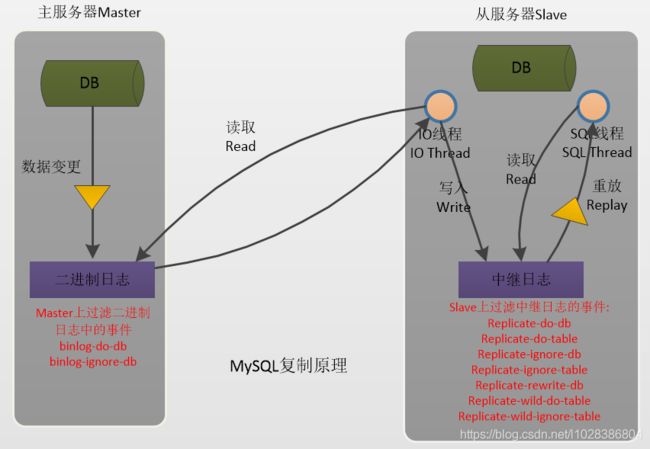
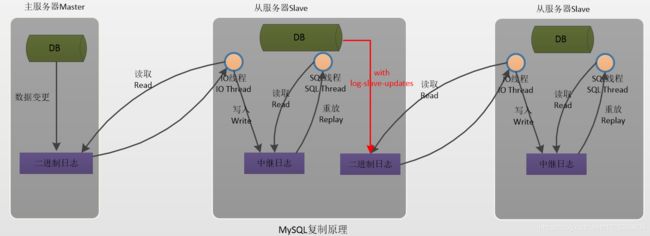
relay_log配置中继日志,log_slave_updates表示slave将复制事件 写进自己的二进制日志.当设置log_slave_updates时,你可以让slave扮演其它slave的master.此时,slave把sql线程执行的事件写进自己的二进制日志(binary log)然后,它的slave可以获取这些事件并执行它。如下图所示(发送复制事件到其它的Slave):
从库问题重现
恢复主库的数据后,向主库中插入了一批测试数据,大概有1000条,但是插入数据后,从库迟迟没有将数据同步过来。于是我先登录主库,执行如下命令。
mysql>show processlist;
查看下进程是否Sleep太多。发现很正常。
再查看下主库的状态。
show master status;
也正常。
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
再到从库上查看从库的状态。
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: No
发现是Slave不同步了。这里,如果主从数据库版本一致或不一致又会存在两种解决方案。
主从版本一致解决方案
下面介绍两种解决方法
方法一:忽略错误后,继续同步
该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况
解决:
stop slave;
#表示跳过一步错误,后面的数字可变
set global sql_slave_skip_counter =1;
start slave;
之后再用mysql> show slave status\G 查看
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
ok,现在主从同步状态正常了。。。
方式二:重新做主从,完全同步
该方法适用于主从库数据相差较大,或者要求数据完全统一的情况
解决步骤如下:
(1)先进入主库,进行锁表,防止数据写入
使用命令:
mysql> flush tables with read lock;
注意:该处是锁定为只读状态,语句不区分大小写
(2)进行数据备份
#把数据备份到mysql.bak.sql文件
mysqldump -uroot -p -hlocalhost > mysql.bak.sql
这里注意一点:数据库备份一定要定期进行,可以用shell脚本或者python脚本,都比较方便,确保数据万无一失。
(3)查看master 状态
mysql> show master status;
+-------------------+----------+--------------+-------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+-------------------------------+
| mysqld-bin.000001 | 3260 | | mysql,test,information_schema |
+-------------------+----------+--------------+-------------------------------+
1 row in set (0.00 sec)
(4)把mysql备份文件传到从库机器,进行数据恢复
scp mysql.bak.sql [email protected]:/tmp/
(5)停止从库的状态
mysql> stop slave;
(6)然后到从库执行mysql命令,导入数据备份
mysql> source /tmp/mysql.bak.sql
(7)设置从库同步,注意该处的同步点,就是主库show master status信息里的| File| Position两项
change master to master_host = '192.168.128.100', master_user = 'rsync', master_port=3306, master_password='', master_log_file = 'mysqld-bin.000001', master_log_pos=3260;
(8)重新开启从同步
mysql> start slave;
(9)查看同步状态
mysql> show slave status\G
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
(10)回到主库并执行如下命令解除表锁定。
UNLOCK TABLES;
如果主从数据库的版本是一致的,以上述方式回复从数据库是没啥问题的,如果主从数据库版本不一致的话,以上述方式回复主从数据库可能还会存在问题。
主从版本不一致解决方案
如果MySQL主库和从库的版本不一致时,使用 show slave status \G命令查看从库状态时可能会看到如下所示的信息。
Slave_IO_Running: Yes
Slave_SQL_Running: No
……
Last_Errno: 1755
Last_Error: Cannot execute the current event group in the parallel mode. Encountered event Gtid, relay-log name ./mysql-relay.000002, position 123321 which prevents execution of this event group in parallel mode. Reason: The master event is logically timestamped incorrectly...
注意如下的输出信息。
Last_Errno: 1755
Last_Error: Cannot execute the current event group in the parallel mode. Encountered event Gtid, relay-log name ./mysql-relay.000002, position 123321 which prevents execution of this event group in parallel mode. Reason: The master event is logically timestamped incorrectly...
这是由于主库使用的是MySQL5.6,从库使用的是MySQL5.7,数据库版本不一致引起的。
从MySQL官网搜索1755的报错看到是并行复制bug导致的报错。想要解决的办法也很简单,直接关掉并行复制即可。
stop slave;
set global slave_parallel_workers=0;
start slave;
如果从库还是存在问题,则可按照主从版本一致的方案来恢复从库的数据。
这里,附加一个MySQL官方文档对于1755错误码的描述。
https://bugs.mysql.com/bug.php?id=71495
经过大半天和半个晚上的数据恢复,数据库总算是恢复了,不过这次的教训也挺惨痛的。为了避免再次出现类似的事故,我后来将数据库做成了异地多活,后面再把数据库异地多活的方案分享给大家!
好了,今天就到这儿吧,我是冰河,大家有啥问题可以在下方留言,也可以加我微信:sun_shine_lyz,我拉你进群,一起交流技术,一起进阶,一起进大厂~~