2021-03-17~18 大数据课程笔记 day56day57

@R星校长
1 基础概念和Kylin简介
1.1 OLTP与OLAP
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。
1.1.1 OLTP
OLTP(On-Line Transaction Processing):联机事务处理,OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。主要用于业务类系统,主要供基层人员使用,进行一线业务操作。
OLTP表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的OLTP系统有电子商务系统、银行、证券等,如美国eBay的业务数据库,就是很典型的OLTP数据库。
1.1.2 OLAP
OLAP(On-Line Analytical Processing):联机分析处理,OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP数据分析的目标是探索并挖掘数据价值,作为企业高层进行决策的参考。
OLAP分析处理是一种共享多维信息的快速分析技术;OLAP利用多维数据库技术使用户从不同角度观察数据;OLAP用于支持复杂的分析操作,侧重于对管理人员的决策支持,可以满足分析人员快速、灵活地进行大数据量的复杂查询的要求,并且以一种直观、易懂的形式呈现查询结果,辅助决策。
事实表和维度表:
事实表:发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。例如,一个按照地区、产品、月份划分的销售量和销售额的事实表如下: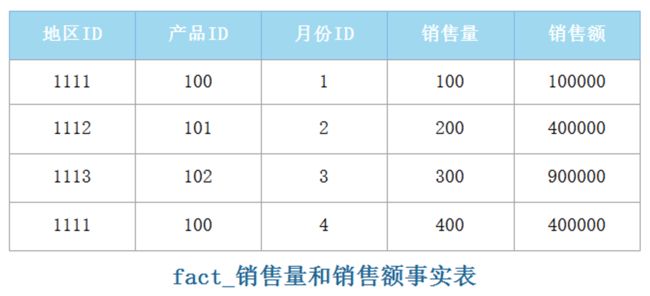
维度表:对事实表中事件的要素的描述信息。维度表包含了维度的每个成员的特定名称。维度成员的名称称为“属性”(Attribute),假设“产品ID”维度表中有3种产品,例如: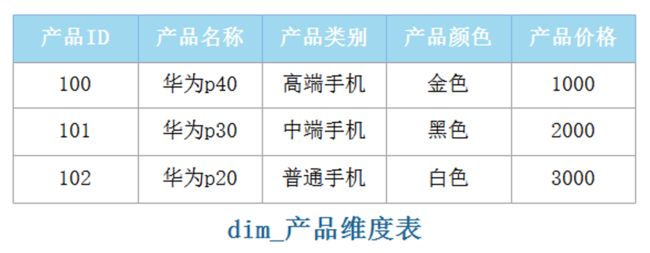
OLAP基本概念:
变量(度量):变量是数据度量的指标,是数据的实际意义,描述数据是什么?例如:人员信息表中的“工资”信息。一般度量列都是可以统计的数值类型列。
维度:描述与业务主题相关的一组属性。例如:“性别”,“时间”等。一个维度往往有多个层次,例如:时间维度分为年、季度、月和日等层次。地区维度可以包含:国家、地区、省、市、县等。
事实:不同维度在某一取值下的度量。可以理解成维度+变量构成了事实。
OLAP特点:
(1)快速性:用户对OLAP的快速反应能力有很高的要求。系统应能在5秒内对用户的大部分分析要求做出反应。
(2)可分析性:OLAP系统应能处理与应用有关的任何逻辑分析和统计分析。
(3)多维性:多维性是OLAP的关键属性。系统必须提供对数据的多维视图和分析,包括对层次维和多重层次维的完全支持。
(4)信息性:不论数据量有多大,也不管数据存储在何处,OLAP系统应能及时获得信息,并且管理大容量信息。
OLAP分类: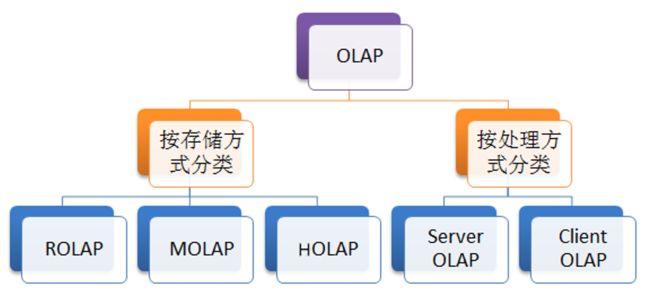
按照存储方式分类分为以下几类:
ROLAP (Relational OLAP):ROLAP使用关系数据库存储管理数据仓库,以关系表存储多维数据,有较强的可伸缩性。其中维数据存储在维表中,而事实数据和维ID则存储在事实表中,维表和事实表通过主外键关联。
MOLAP (Multidimension OLAP): MOLAP支持数据的多维视图,采用多维数据组存储数据,它把维映射到多维数组的下标或下标的范围,而事实数据存储在数组单元中,从而实现了多维视图到数组的映射,形成了立方体的结构。
HOLAP(Hybrid OLAP):HOLAP是混合型OLAP, 表示基于混合数据组织的OLAP实现,如低层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活性。特点是将明细数据保留在关系型数据库的事实表中,但是聚合后数据保存在Cube中,查询效率比ROLAP高,但性能低于MOLAP。
按照处理方式分类:
Server OLAP:绝大多数的OLAP系统都属于此类,Server OLAP在服务端的数据库上建立多维数据立方体,由服务端提供多维分析,并把最终结果呈现给用户。
Client OLAP:所相关立方体数据下载到本地,由本地为用户提供多维分析,从而保证在网络故障时仍然能正常工作。
OLAP基本操作: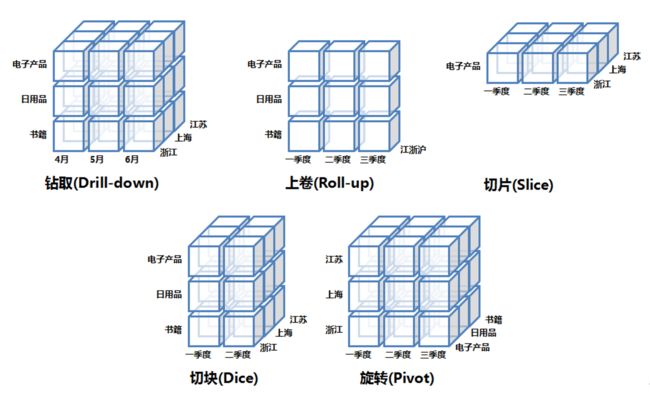
钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对第二季度的总销售数据进行钻取来查看第二季度4、5、6每个月的消费数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择第一季度到第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
1.1.3 OLTP与OLAP的关系
从功能角度来看,OLTP负责基本业务的正常运转,而业务数据积累时所产生的价值信息则被OLAP不断呈现,企业高层通过参考这些信息会不断调整经营方针,也会促进基础业务的不断优化,这是OLTP与OLAP最根本的区别。
1.2 数据分析模型
OLAP分析中,根据事实表和维度表的关系,可以将数据分析模型分为星型模型和雪花模型。在设计数仓时,就应该考虑数据应该按照星型模型还是雪花模型进行组织。
1.2.1 星型模型
当所有的维度表都由连接键连接到事实表时,结构图如星星一样,这种分析模型就是星型模型。如下图,星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在下图中,时间维中存在A年1季度1月,A年1季度2月两条记录,那么A年1季度被存储了2次,存在冗余。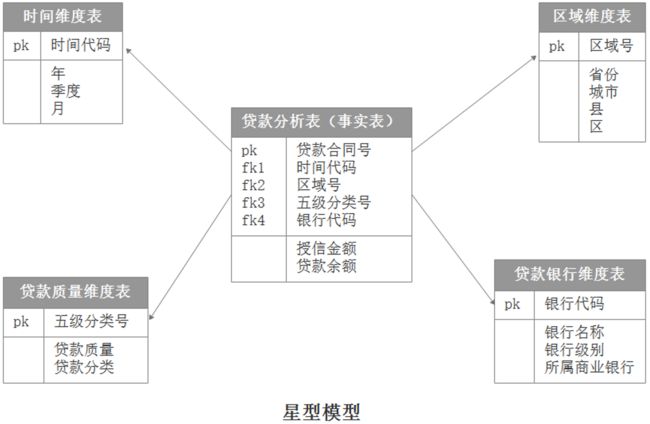
1.2.2 雪花模型
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其结构图就像雪花连接在一起,这种分析模型就是雪花模型。如下图,雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表。如下图中,将地域维表又分解为国家,省份,城市等维表。它的优点是:通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能,雪花型结构去除了数据冗余。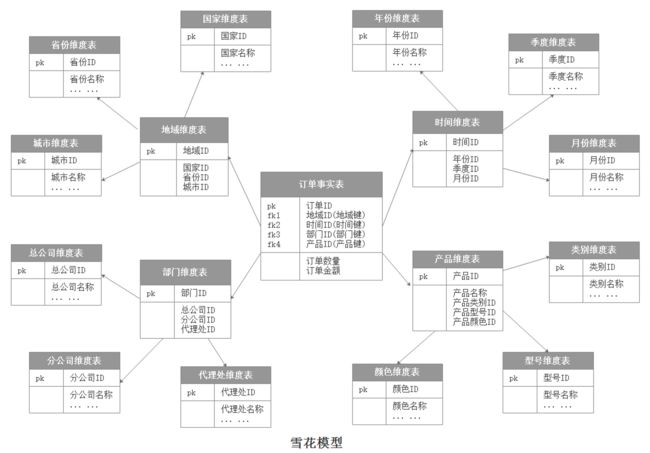
星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
1.3 联机数据分析(OLAP)问题
问题:数据规模决定要选择高效的处理技术:
北京电信用户规模超过两千万,每天入库的原始数据超过三百亿条。经过处理后入库的数据是3TB,而集群规模是400TB存储;每天执行的任务超过800个,其中大概有 600-700 个是属于临时产生的任务(查询情况多变,比如开发或者测试人员进行数据测试,或者临时统计某些需求生成报表等),且要求响应速度快,所以集群很繁忙。如果不选择高效的数据处理技术,将无法满足分析需求。如下图所示:
问题:数据查询需求的困境:
分析人员、优化人员对数据的临时性查询越来越多,探索性数据需求越来越旺盛,需要找到一个方法来满足这类需求。首先,可以寻求固定化报表方式解决,可以做很多报表放在 MySQL 里供查询。但这样做非常不灵活,开发周期缓慢,而且经常出现需求变更和需求不明确的情况,所以报表只适用于固定化场景的情况。
使用 Hive 和 Spark Sql 可以满足探索性数据分析的需求,但 Hive 速度较慢,Spark Sql 对内存资源要求很高,多并发下出现资源瓶颈问题,并且SparkSQL的代码维护成本相对高。如果应用的场景是数据来源固定,但是查询不固定且要求速度时,就需要寻求新的技术解决。
总结以上两大问题,目前OLAP(On-Line Analytical Processing)联机分析处理的特点是:1).数据量大并且要求查询速度快时,计算时间成本高。2).SparkSQL速度快,但内存需求大,代码维护成本高。3).固定化报表方式无法应对查询需求不定、多样的分析需求。
1.4 什么是 Kylin&Kylin 的架构原理
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。Apache Kylin令使用者仅需三步,即可实现超大数据集上的亚秒级查询:
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准SQL通过ODBC、JDBC或RESTFUL API进行查询,仅需亚秒级响应时间即可获得查询结果。

Kylin 数据处理原理及架构原理:
kylin 的核心思想是预计算,kylin对多维分析可能用到的度量进行预计算,将高维复杂的聚合计算,多表连接等操作转换成预计算结果,将计算好的结果保存成Cube,存储于Hbase中,供查询时直接访问。预计算过程需要很长时间,但是一旦结果计算出来,再次查询只是获取结果集合的过程,不需要额外再次浪费集群资源进行长时间查询,这种以空间换取时间的处理数据模式决定了Kylin拥有很好的快速查询、高并发能力。
Kylin是一个MOLAP(多维联机数据分析)系统,最常用的是将Hive中的数据进行预计算,利用Hadoop的Mapreduce或者Spark分布式计算框架来实现。Kylin获取的数据表是星型数据结构的,目前建模时,只支持一张事实表,多张维度表,假设业务需求比较复杂,可以考虑在Hive中进行预处理生成一张宽表来处理。
对于Hive中的维度表和事实表,根据我们指定的维度列来构建cube,cube是所有维度的组合,任一维度的组合称为cuboid,即:cube中包含所有的cuboid。理论上来说,一个N维的cube,会有2的N次方种维度组合(cuboid)。举例:假设一个cube包含time、country、city、location四个维度,那么就有16中cuboid组合。通过计算框架的计算将OLAP分析的cube数据存储在Hbase中,方便后期实现多维数据集的交互式快速查询。
上图中是Kylin整体架构原理图,其中:
REST Server:提供Restful接口,可以通过此接口来创建、构建、刷新、合并Cube等相关操作。同时也可以通过Restful接口实现SQL查询。
Query Engine:目前Kylin使用开源的Calcite框架来实现SQL解析,用户发出SQL查询之后,可以通过Query Engine来将SQL Query语句转换成SQL语法树,也就是逻辑计划。
Routing:负责将解析SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在Hbase中,这部分查询时可以在秒级甚至是毫秒级完成,除此之外,还有一些操作需要使用原始数据(存储在HDFS上)通过Hive查询,这部分查询的延迟比较高。
Metadata:Kylin中有大量的元数据信息,包括cube的定义、星型模型的定义、job和执行job的输出信息、模型的维度信息等等。Kylin的元数据存储在Hbase中,存储的格式是Json字符串。
Cube Build Engine:立方体构建模块是所有模块的基础,主要负责Kylin预计算中创建cube,创建的过程是首先通过Hive读取原始数据,然后通过MR或者Spark计算生成Htable,最后将数据加载到Hbase表中。
2 Kylin 安装使用
2.1 Kylin 安装要求
软件要求:Hadoop2.7+,Hive0.13-1.2.1+,Hbase:1.1+,JDK1.8+,只能安装到Linux上,选择CentOS6.5+。
硬件要求:运行 Kylin 的服务器的最低配置为4core CPU,16GB内存和100 GB 磁盘。对于高负载的场景,建议使用 24 core CPU,64GB内存或更高的配置。这里我们使用虚拟机每台节点配置为3G内存和4 core CPU,至少保证要有2G内存和2core CPU。
Hadoop 环境:Kylin依赖于Hadoop集群处理大量的数据集。需要准备一个配置好 HDFS,YARN,MapReduce,Hive, HBase,Zookeeper 和其他服务的 Hadoop 集群供 Kylin 运行。Kylin可以在Hadoop集群的任意节点启动,可以在Master节点上运行Kylin,但是为了稳定性,建议将Kylin部署到一个干净的Hadoop client节点上,该节点上要保证有Hadoop、Hive、Hbase即可,并且当前节点和集群中其他节点可以免密访问。
2.2 Kylin 安装
2.2.1 Kylin 安装前环境准备
这里由于资源问题,我们选择安装单节点的Kylin。由于安装Kylin的节点必须安装Hadoop,Hive,Hbase所以这里选择mynode3安装Kylin。
Kylin的运行原理依赖Hadoop体系中的Yarn,Yarn集群中默认每台nodemanager节点的core和内存分别为8core和8G内存,我们实际的虚拟机没有这么多core和内存资源,需要相应的调低core和内存,在每台nodemanager节点yarn-site.xml中配置如下信息:
1. #在mynode3、mynode4、mynode5节点的yarn-site.xml中追加如下内容:
2.
3. <property>
4. <name>yarn.log-aggregation-enablename>
5. <value>truevalue>
6. property>
7.
8. <property>
9. <name>yarn.nodemanager.resource.memory-mbname>
10. <value>4096value>
11. property>
12.
13. <property>
14. <name>yarn.nodemanager.resource.cpu-vcoresname>
15. <value>4value>
16. property>
17.
18. <property>
19. <name>yarn.nodemanager.vmem-check-enabledname>
20. <value>falsevalue>
21. property>
由于后期Kylin运行过程中需要开启任务的日志管理,所以需要在Kylin的安装节点mynode3上配置mapreduce日志管理,配置mynode3节点路径$HADOOP_HOME/etc/hadoop下的mapred-site.xml,在文件中添加如下配置:
1. #在mynode3节点上配置mapred-site.xml,追加如下内容:
2.
3. <property>
4. <name>mapreduce.jobhistory.addressname>
5. <value>mynode3:10020value>
6. property>
7.
8. <property>
9. <name>mapreduce.jobhistory.webapp.addressname>
10. <value>mynode3:19888value>
11. property>
2.2.2 Kylin 安装
1. 从官网https://kylin.apache.org/download/中下载kylin安装
这里选择的是apache-kylin-2.5.2-bin-hbase1x.tar.gz版本。
2. 上传至节点mynode3路径/software/下,并解压
1. #将kylin安装包进行解压
2. tar -zxvf apache-kylin-2.5.2-bin-hbase1x.tar.gz
3.
3. 在mynode3节点上配置Kylin的环境变量
1. #进入/etc/profile,在最后添加如下内容
2. export KYLIN_HOME=/software/apache-kylin-2.5.2-bin-hbase1x
3. export PATH=$PATH:$KYLIN_HOME/bin
4.
5. #执行如下命令,使profile文件生效
6. source /etc/profile
4. 需要在安装kylin的mynode3节点中配置HIVE_CONF环境变量,Kylin启动会检查对应的hive-site.xml文件。
1. #进入/etc/profile,在最后添加如下内容
2. export HIVE_CONF=$HIVE_HOME/conf
3. #执行如下命令,使profile文件生效
4. source /etc/profile
5. 启动HDFS集群,同时在mynode1节点启动Hive metastore服务,在mynode4中start-hbase.sh启动Hbase集群。
mynode1:50070检查HDFS集群是否启动成功。
mynode4:16010检查Hbase集群是否启动成功。
6. 在mynode3节点上启动mr历史日志服务器
1. #在mynode3节点上启动mr历史日志服务器
2. mr-jobhistory-daemon.sh start historyserver
启动成功后,可以登录mynode3:19888 webui界面来检查是否配置成功。
7. 运行$KYLIN_HOME/bin/check-env.sh脚本来进行环境检测
这里的环境监测就是检查当前节点是否可以访问hadoop集群,是否可以访问hive元数据,是否可以访问Hbase。
8. 启动Kylin
运行$KYLIN_HOME/bin/kylin.sh start脚本来启动Kylin。
9. 访问webui页面
Kylin 启动后您可以通过浏览器 http://
初始用户名和密码是 ADMIN/KYLIN。服务器启动后,您可以通过查看 $KYLIN_HOME/logs/kylin.log 获得运行时日志。
输入对应的访问地址,出现如下页面说明Kylin安装成功。
2.3 导入样例 cube
Kylin 提供了一个创建样例Cube 脚本,脚本会创建五个样例Hive表,运行 K Y L I N H O M E / b i n / s a m p l e . s h , 此 脚 本 会 向 H i v e 默 认 库 中 导 入 五 个 样 例 表 , 并 且 在 K y l i n 中 创 建 “ l e a r n k y l i n ” 工 程 。 这 里 我 们 运 行 {KYLIN_HOME}/bin/sample.sh,此脚本会向Hive默认库中导入五个样例表,并且在Kylin中创建“learn_kylin”工程。这里我们运行 KYLINHOME/bin/sample.sh,此脚本会向Hive默认库中导入五个样例表,并且在Kylin中创建“learnkylin”工程。这里我们运行{KYLIN_HOME}/bin/sample.sh脚本,导入“learn-kylin”工程:
1. #进入$HBASE_HOME/bin下执行如下命令
2. sample.sh
执行脚本之后,最后会提示:“Restart Kylin Server or click Web UI => System Tab => Reload Metadata to take effect”,进入kylin的webui,点击“System”->“Reload Metadata”,刷新元数据。

当元数据重新刷新之后,点击“model”,会发现Project中导入了“learn-kylin”工程。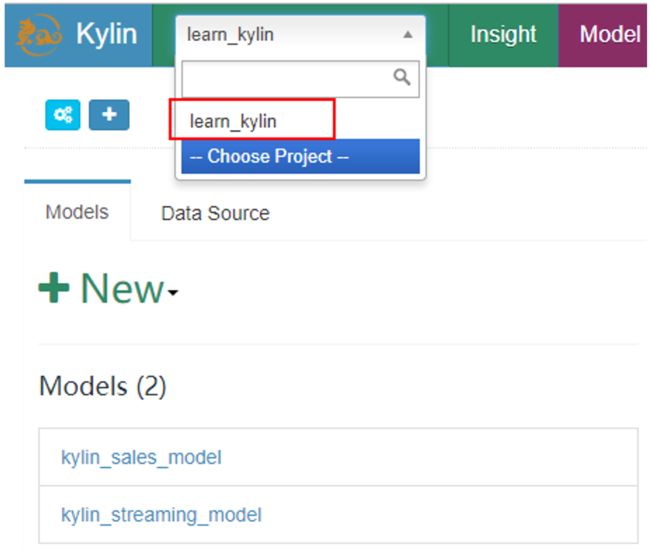
2.4 Kylin 集群模式部署
Kylin 实例是无状态的服务,运行时的状态信息存储在 HBase metastore 中。 出于负载均衡的考虑,您可以启用多个共享一个 metastore 的 Kylin 实例,使得各个节点分担查询压力且互为备份,从而提高服务的可用性。下图描绘了 Kylin 集群模式部署的一个典型场景:
如果您需要将多个 Kylin 节点组成集群,请确保他们使用同一个 Hadoop 集群、HBase集群。然后在每个节点的配置文件$KYLIN_HOME/conf/kylin.properties 中执行下述操作:
1) 配置相同的kylin.metadata.url值,即配置所有的 Kylin 节点使用同一个 HBase metastore。
2) 配置Kylin 节点列表kylin.server.cluster-servers,包括所有节点(包括当前节点),当事件变化时,接收变化的节点需要通知其他所有节点(包括当前节点)。
3) 配置Kylin节点的运行模式kylin.server.mode,参数值可选all, job, query中的一个,默认值为 all。job 模式代表该服务仅用于任务调度,不用于查询;query模式代表该服务仅用于查询,不用于构建任务的调度;all 模式代表该服务同时用于任务调度和 SQL 查询。
为了达到更好的稳定性和最佳的性能,建议进行读写分离部署,将 Kylin 部署在两个集群上,如下:
1) 一个Hadoop集群用作Cube 构建,这个集群可以是一个大的、与其它应用共享的集群;
2) 一个HBase集群用作SQL查询,通常这个集群是专门为Kylin配置的,节点数不用像 Hadoop 集群那么多,HBase 的配置可以针对 Kylin Cube 只读的特性而进行优化。
读写分离这种部署策略是适合生产环境的最佳部署方案。
3 Kylin 配置
-
kylin.metadata.url
指定元数据库路径,默认值为 kylin_metadata@hbase -
kylin.metadata.sync-retries
指定元数据同步重试次数,默认值为 3 -
kylin.env.hdfs-working-dir
指定 Kylin 服务所用的 HDFS 路径,默认值为 /kylin,请确保启动 Kylin 实例的用户有读写该目录的权限 -
kylin.env
指定 Kylin 部署的用途,参数值可选DEV,QA,PROD,默认值为DEV,在 DEV 模式下一些开发者功能将被启用。开发环境为DEV,测试环境为QA,生产环境为PROD -
kylin.env.zookeeper-base-path
指定Kylin服务所用的ZooKeeper路径,默认值为/kylin。kylin构建cube的一些字典和任务元数据会存放在Hbase依赖的zookeeper中 -
kylin.server.mode
指定Kylin实例的运行模式,参数值可选 all,job,query,默认值为all,job 模式代表该服务仅用于任务调度,不用于查询;query 模式代表该服务仅用于查询,不用于构建任务的调度;all 模式代表该服务同时用于任务调度和 SQL 查询。 -
kylin.web.query-timeout
设置webui提交任务超时时间,默认为300秒 -
kylin.source.hive.client
指定 Hive 命令行类型,参数值可选 cli 或 beeline,默认值为 cli -
kylin.storage.hbase.table-name-prefix
指定向Hbase中存储结果数据表前缀,默认值为 KYLIN_ -
kylin.storage.hbase.namespace
指定 HBase 存储默认的 namespace,默认值为 default
4 Kylin 使用
4.1 名词解释
cuboid:维度的任意组合。
cube:所有的维度组合,包含所有的cuboid。
4.2 创建cube
4.2.1 新建项目
- 由顶部菜单栏进入 Model 页面,然后点击 Manage Projects。

- 点击“+Project”按钮添加一个新的项目。
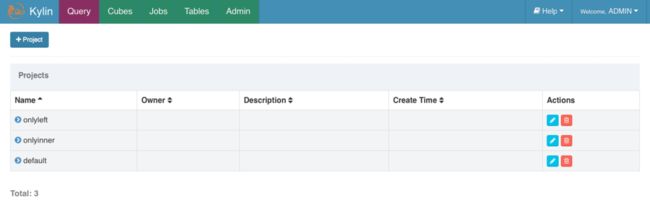
- 填写下列表单并点击submit按钮提交请求。
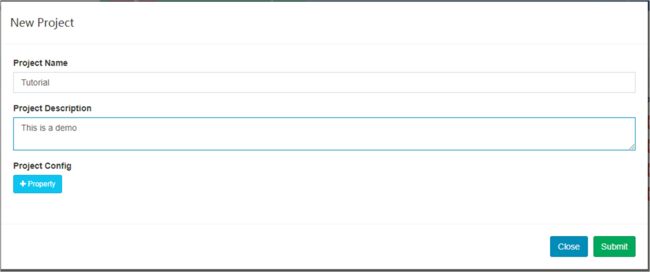
- 成功后,底部会显示通知。

4.2.2 同步 Hive 表
- 在顶部菜单栏点击 Model,然后点击左边的Data Source标签,它会列出所有加载进 Kylin 的表,点击 Load Table 按钮。

- 输入表名并点击 Sync 按钮提交请求。
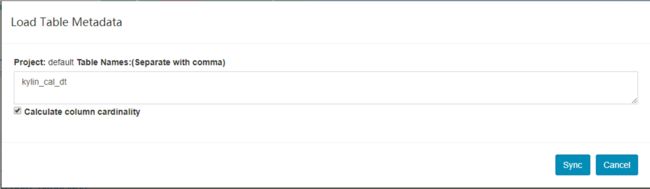
- 【可选】如果你想要浏览 hive 数据库来选择表,点击 Load Table From Tree 按钮。

- 【可选】展开数据库节点,点击选择要加载的表,然后点击 Sync 按钮。
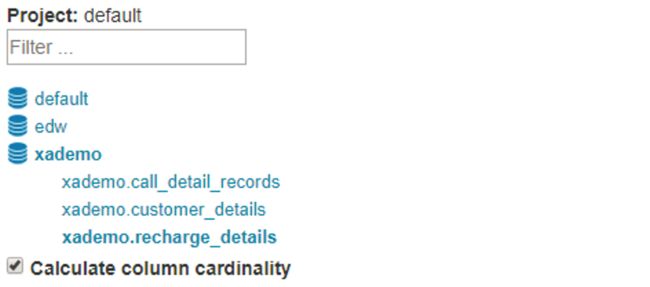
- 成功的消息将会弹出,在左边的 Tables 部分,新加载的表已经被添加进来。点击表将会展开列。
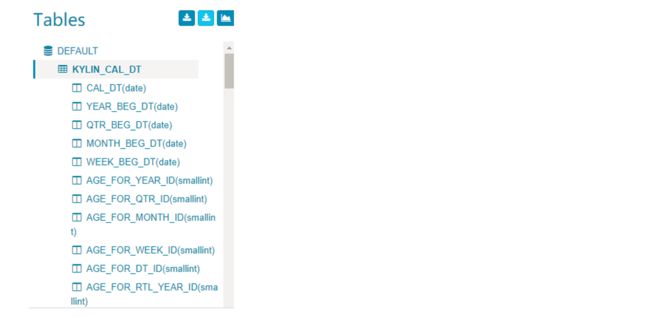
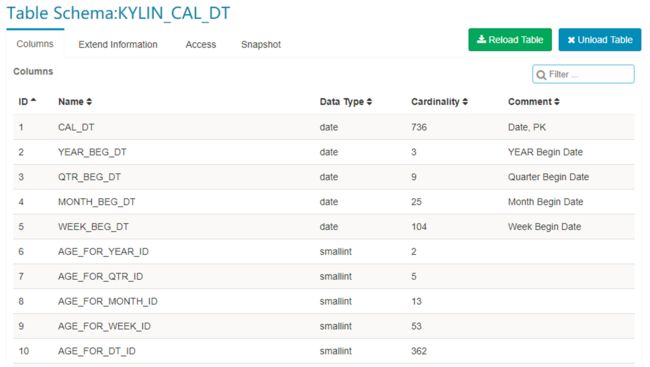
- 在后台,Kylin 将会执行 MapReduce 任务计算新同步表的基数(cardinality),任务完成后,刷新页面并点击表名,基数值将会显示在表信息中。
4.2.3 新建 Data Model
创建 cube 前,需定义一个数据模型。数据模型定义了一个星型(star schema)或雪花(snowflake schema)模型。一个模型可以被多个 cube 使用。
1.点击顶部的 Model ,然后点击 Models 标签。点击 +New 按钮,在下拉框中选择 New Model。
2.输入 model 的名字和可选的描述。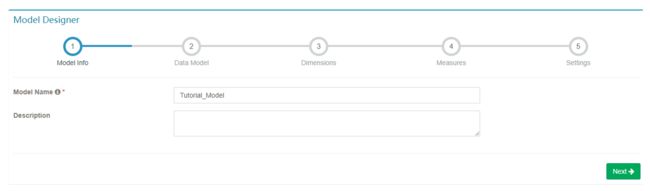
3.在 Fact Table 中,为模型选择事实表。
4.【可选】点击 Add Lookup Table 按钮添加一个 lookup 表。选择表名和关联类型(内连接或左连接)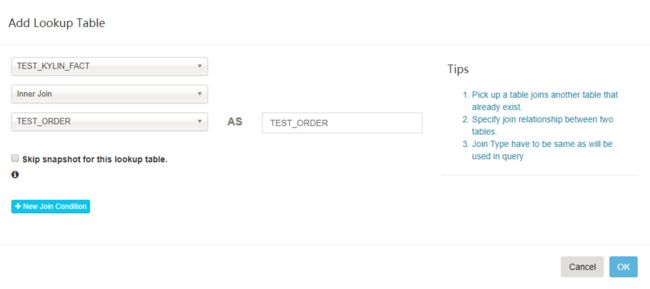
5.点击 New Join Condition 按钮,左边选择事实表的外键,右边选择 lookup 表的主键。如果有多于一个 join 列重复执行。
6.点击 “OK”,重复4,5步来添加更多的 lookup 表。完成后,点击 “Next”。
7.Dimensions 页面允许选择在子 cube 中用作维度的列,然后点击Columns列,在下拉框中选择需要的列。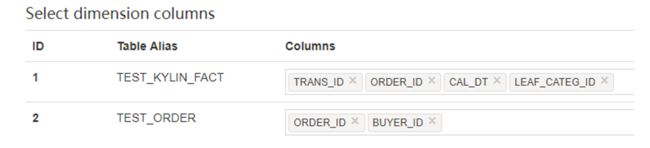
8.点击 “Next” 到达 “Measures” 页面,选择作为 measure 的列,其只能从事实表中选择。
9.点击 “Next” 到达 “Settings” 页面,如果事实表中的数据每日增长,选择 Partition Date Column 中相应的 日期列以及日期格式,否则就将其留白。
10.【可选】选择是否需要 “time of the day” 列,默认情况下为 No。如果选择 Yes, 选择 Partition Time Column 中相应的 time 列以及 time 格式
11.【可选】如果在从 hive 抽取数据时候想做一些筛选,可以在 Filter 中输入筛选条件。
12.点击 Save 然后选择 Yes 来保存 data model。创建完成,data mod就会列在左边 Models 列表中。
4.2.4 新建 Cube
创建完 data model,可以开始创建 cube。点击顶部 Model,然后点击Models 标签。点击 +New 按钮,在下拉框中选择 New Cube。
步骤 1. Cube 信息
选择 data model,输入 cube 名字;点击 Next 进行下一步。cube 名字可以使用字母,数字和下划线(空格不允许)。Notification Email List 是运用来通知job执行成功或失败情况的邮箱列表。Notification Events 是触发事件的状态。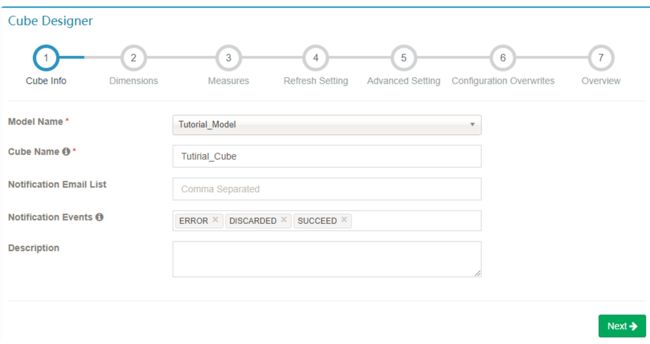
步骤2. 维度
点击 Add Dimension,在弹窗中显示的事实表和 lookup 表里勾选输入需要的列。Lookup 表的列有2个选项:“Normal” 和 “Derived”(默认)。“Normal” 添加一个普通独立的维度列,“Derived” 添加一个 derived 维度,derived 维度不会计算入 cube,将由事实表的外键推算出。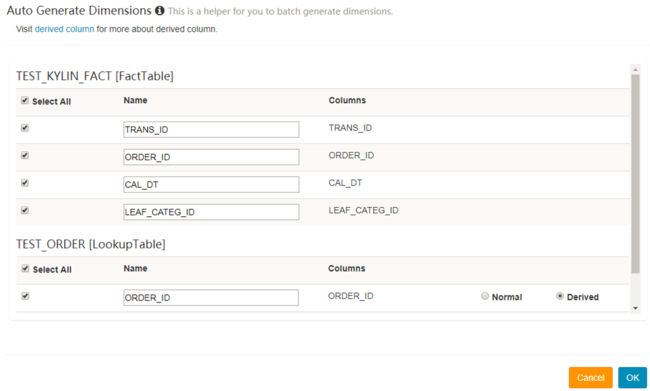
选择所有维度后点击 “Next”。
步骤3. 度量
1.点击 +Measure 按钮添加一个新的度量。
2.根据它的表达式共有8种不同类型的度量:SUM、MAX、MIN、COUNT、COUNT_DISTINCT TOP_N, EXTENDED_COLUMN 和 PERCENTILE。请合理选择 COUNT_DISTINCT 和 TOP_N 返回类型,它与 cube 的大小相关。
- SUM
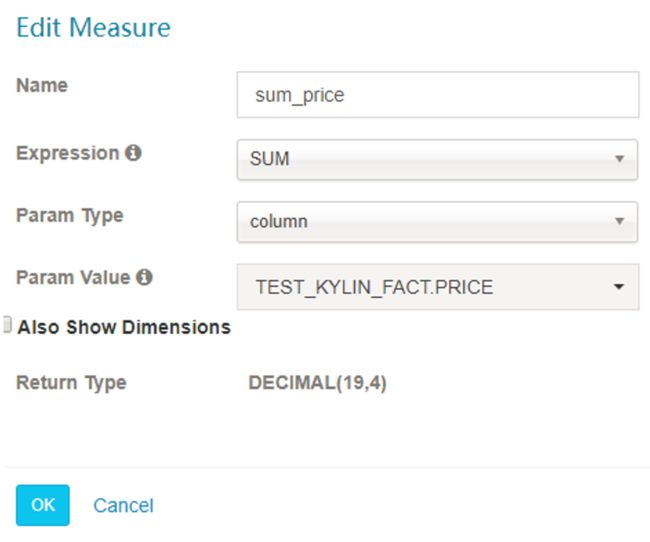
- MIN
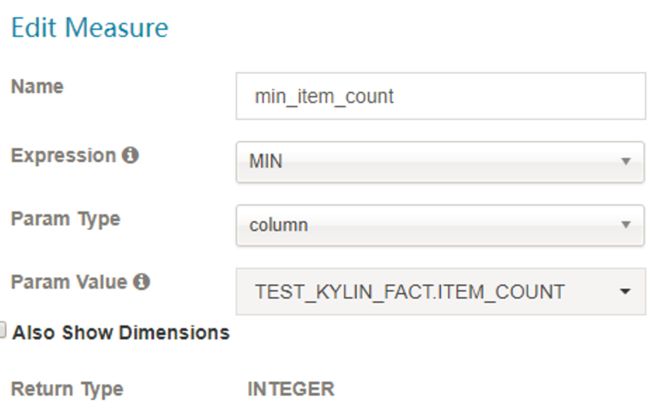
- MAX

- COUNT
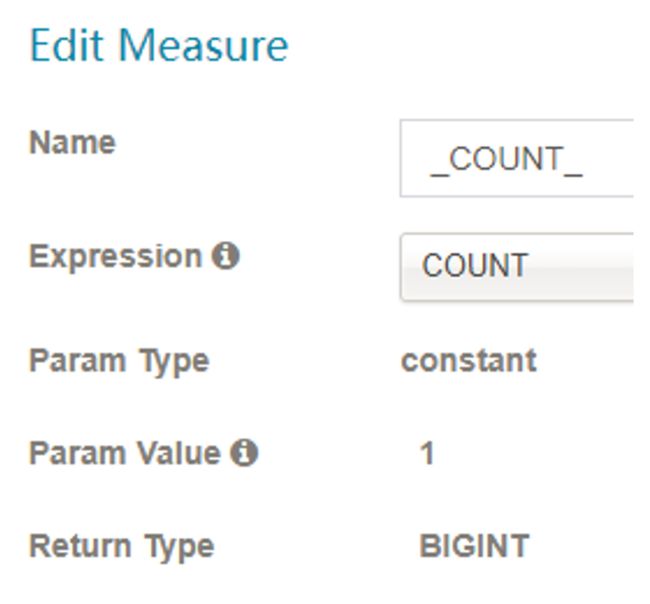 - DISTINCT_COUNT
- DISTINCT_COUNT
这个度量有两个实现:
1) 近似实现 HyperLogLog,选择可接受的错误率,低错误率需要更多存储
2) 精确实现 bitmap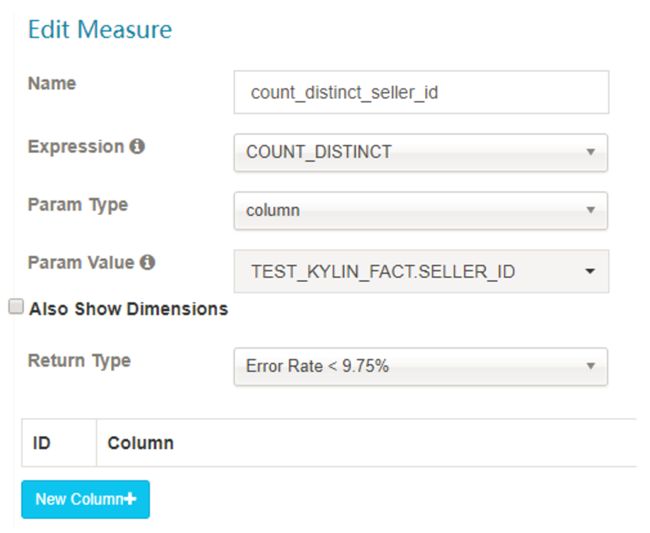
注意:distinct 是一种非常重的数据类型,和其他度量相比构建和查询会更慢。
- TOP_N
TopN 度量在每个维度结合时预计算,它比未预计算的在查询时间上性能更好;需要两个参数:一是被用来作为 Top 记录的度量列,Kylin 将计算它的 SUM 值并做倒序排列;二是 literal ID,代表最 Top 的记录,例如 seller_id;
合理的选择返回类型,将决定多少 top 记录被监察:top 10, top 100, top 500, top 1000, top 5000 or top 10000。
注意:如果您想要使用 TOP_N,您需要为 “ORDER | SUM by Column” 添加一个 SUM 度量。例如,如果您创建了一个根据价格的总和选出 top100 的卖家的度量,那么也应该创建一个 SUM(price) 度量。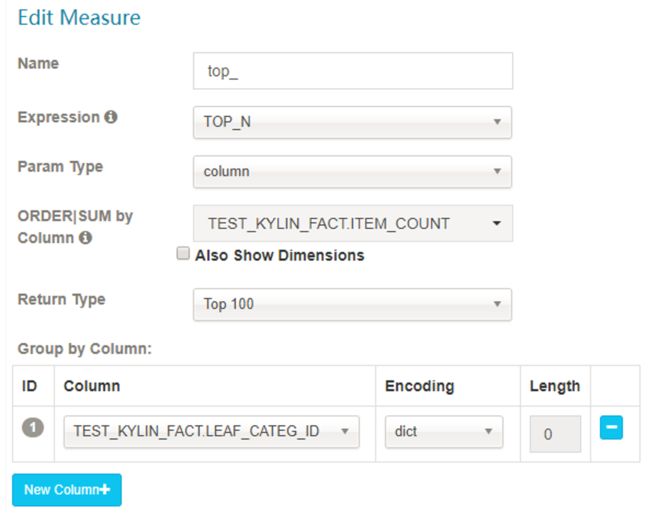
- EXTENDED_COLUMN
Extended_Column 作为度量比作为维度更节省空间。一列和另一列可以生成新的列。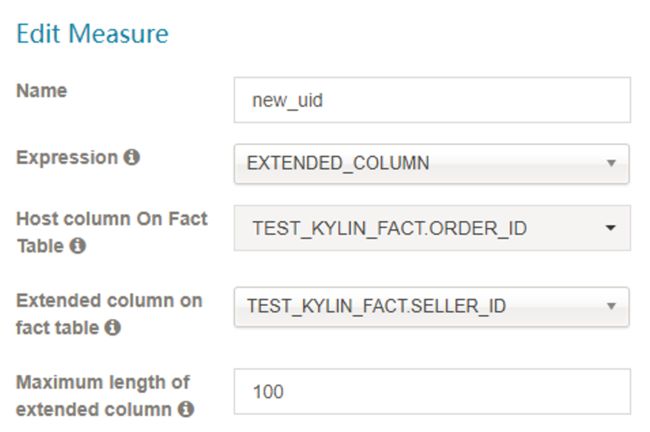
- PERCENTILE
Percentile 代表了百分比。100为最合适的值。
步骤4. 更新设置
这一步骤是为增量构建 cube 而设计的。
-
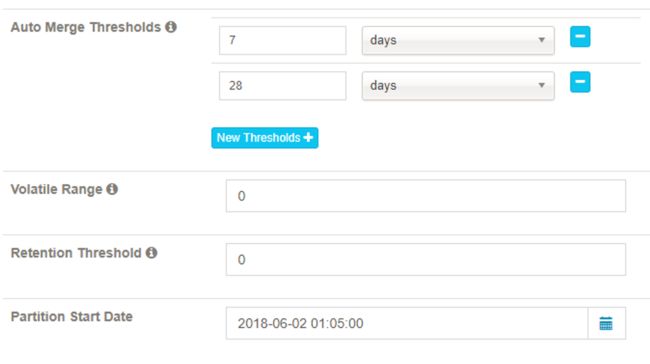
Auto Merge Thresholds: 自动合并小的 segments 到中等甚至更大的 segment。如果不想自动合并,删除默认2个选项。
-
Volatile Range: 默认为0,会自动合并所有可能的 cube segments,或者用 ‘Auto Merge’ 将不会合并最新的 [Volatile Range] 天的 cube segments。
-
Retention Threshold: 只会保存 cube 过去几天的 segment,旧的 segment 将会自动从头部删除;0表示不启用这个功能。
-
Partition Start Date: cube 的开始日期.
步骤5. 高级设置 -
Aggregation Groups: Cube 中的维度可以划分到多个聚合组中。默认 kylin 会把所有维度放在一个聚合组,当维度较多时,产生的组合数可能是巨大的,会造成 Cube 爆炸;如果你很好的了解你的查询模式,那么你可以创建多个聚合组。在每个聚合组内,使用 “Mandatory Dimensions”, “Hierarchy Dimensions” 和 “Joint Dimensions” 来进一步优化维度组合。
-
Mandatory Dimensions: 必要维度,用于总是出现的维度。例如,如果你的查询中总是会带有 “ORDER_DATE” 做为 group by 或 过滤条件, 那么它可以被声明为必要维度。这样一来,所有不含此维度的 cuboid 就可以被跳过计算。
-
Hierarchy Dimensions: 层级维度,例如 “国家” -> “省” -> “市” 是一个层级;不符合此层级关系的 cuboid 可以被跳过计算,例如 [“省”], [“市”]. 定义层级维度时,将父级别维度放在子维度的左边。
-
Joint Dimensions:联合维度,有些维度往往一起出现,或者它们的基数非常接近(有1:1映射关系)。例如 “user_id” 和 “email”。把多个维度定义为组合关系后,所有不符合此关系的 cuboids 会被跳过计算。
-
Rowkeys: 是由维度编码值组成。”Dictionary” (字典)是默认的编码方式; 字典只能处理中低基数(少于一千万)的维度;如果维度基数很高(如大于1千万), 选择 “false” 然后为维度输入合适的长度,通常是那列的最大长度值; 如果超过最大值,会被截断。请注意,如果没有字典编码,cube 的大小可能会非常大。
你可以拖拽维度列去调整其在 rowkey 中位置; 位于rowkey前面的列,将可以用来大幅缩小查询的范围。通常建议将 mandantory强制维度放在开头,然后是在过滤 ( where 条件)中起到很大作用的维度;如果多个列都会被用于过滤,将高基数的维度(如 user_id)放在低基数的维度(如 age)的前面, 这样防止数据在Hbase中有倾斜。 -
Mandatory Cuboids: 维度组合白名单。确保你想要构建的 cuboid 能被构建。
-
Cube Engine: cube 构建引擎。有两种:MapReduce 和 Spark。如果你的 cube 只有简单度量(SUM, MIN, MAX),建议使用 Spark。如果 cube 中有复杂类型度量(COUNT DISTINCT, TOP_N),建议使用 MapReduce。
-
Advanced Dictionaries: “Global Dictionary” 是用于精确计算 COUNT DISTINCT 的字典, 它会将一个非 integer的值转成 integer,以便于 bitmap 进行去重。如果你要计算 COUNT DISTINCT 的列本身已经是 integer 类型,那么不需要定义Global Dictionary。Global Dictionary 会被所有 segment 共享,因此支持在跨 segments 之间做上卷去重操作。请注意,Global Dictionary 随着数据的加载,可能会不断变大。
“Segment Dictionary” 是另一个用于精确计算 COUNT DISTINCT 的字典,与 Global Dictionary 不同的是,它是基于一个 segment 的值构建的,因此不支持跨 segments 的汇总计算。如果你的 cube 不是分区的或者能保证你的所有 SQL 按照 partition_column 进行 group by, 那么你应该使用 “Segment Dictionary” 而不是 “Global Dictionary”,这样可以避免单个字典过大的问题。
请注意:”Global Dictionary” 和 “Segment Dictionary” 都是单向编码的字典,仅用于 COUNT DISTINCT 计算(将非 integer 类型转成 integer 用于 bitmap计算),他们不支持解码,因此不能为普通维度编码。 -
Advanced Snapshot Table: 为全局 lookup 表而设计,提供不同的存储类型。
-
Advanced ColumnFamily: 如果有超过一个的COUNT DISTINCT 或 TopN 度量, 你可以将它们放在更多列簇中,以优化与HBase 的I/O。
步骤6. 重写配置
Kylin 允许在 Cube 级别覆盖部分 kylin.properties 中的配置,你可以在这里定义覆盖的属性。如果你没有要配置的,点击 Next 按钮。
步骤7. 概览 & 保存
你可以概览你的 cube 并返回之前的步骤进行修改。点击 Save 按钮完成 cube 创建。
恭喜,到此为止,cube 创建完成。
4.3 构建cube
我们这里以sample.sh导入的“learn-kylin”工程为例构建cube。
4.3.1 构建cube
1. 在Models页面中,点击 cube 栏右侧的Action下拉按钮并选择Build操作。
2. 选择后会出现一个弹出窗口,点击 Start Date 或者 End Date 输入框选择这个增量 cube 构建的起始日期。
可以在hive中查询下kylin_sales表中的最大最小时间:
1. select min(part_dt) from kylin_sales; #结果为:2012-01-01
2. select max(part_dt) from kylin_sales; #结果为:2014-01-01
这里设置Start Date为2012-01-01,End Date为2013-01-01,并提交任务,提交之后,在monitor中可以看到可以看到job执行。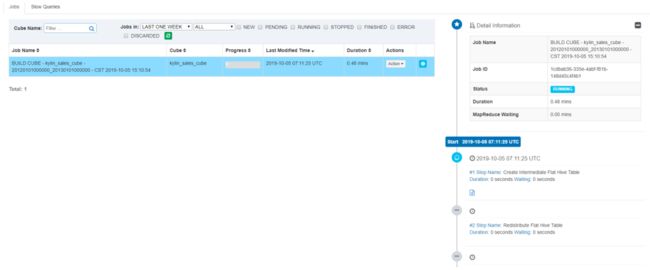
3. 新建的 job 是 “pending” 状态;一会儿,它就会开始运行并且你可以通过刷新 web 页面或者点击刷新按钮来查看进度。
4. 等待 job 完成。期间如要放弃这个 job,点击 Actions->Discard 按钮。
5. 等到job 100%完成,cube 的状态就会变为 “Ready”,意味着它已经准备好进行 SQL 查询。在Model页,找到 cube,然后点击 cube 名展开消息,在 “Storage” 标签下,列出 cube segments。每一个 segment 都有 start/end 时间;Hbase 表的信息也会列出。如果有更多的源数据,重复以上的步骤将它们构建进 cube。每次构建会生成一个Segment。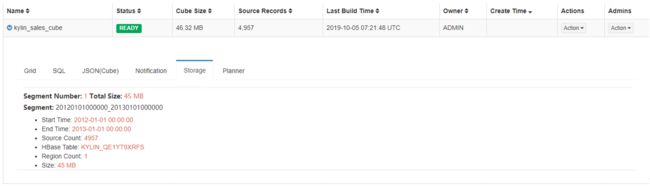
6. 查询SQL,测试速度
分别在Hive和Kylin中执行如下SQL语句:
1. select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt
2.
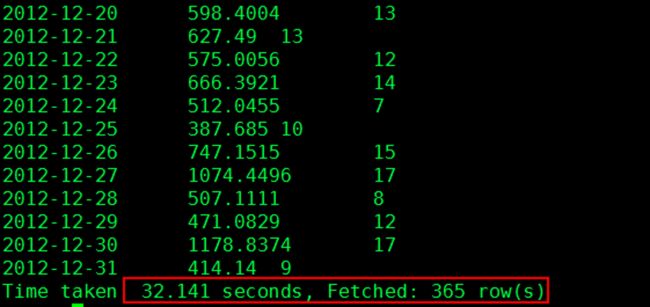
Hive中执行时,需要加上对应的时间,SQL语句如下:
1. select part_dt, sum(price) as total_sold, count(distinct seller_id) as sellers from kylin_sales where part_dt >=to_date('2012-01-01 00:00:00') and part_dt < to_date('2013-01-01 00:00: 00') group by part_dt order by part_dt;
2.
结果和时间如下:
在Kylin中执行如下语句,结果如下: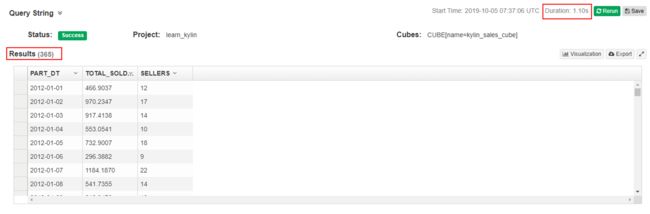
4.3.2 cube 执行流程
- 构建一个中间平表(Hive Table):将Model中的fact表和look up表构建成一个大的Flat Hive Table。
- 重新分配Flat Hive Tables。
- 从事实表中抽取维度的Distinct值。
- 对所有维度表进行压缩编码,生成维度字典。
- 计算和统计所有的维度组合,并保存,其中,每一种维度组合,称为一个Cuboid。
- 创建HTable。
- 构建最基础的Cuboid数据。
- 利用算法构建N维到0维的Cuboid数据。
- 构建Cube。
- 将Cuboid数据转换成HFile。
- 将HFile直接加载到HBase Table中。
- 更新Cube信息。
- 清理Hive。
4.3.3 合并 Segment
这里重新build cube,选择时间为2013-01-01 00:00:00 至2014-01-01 00:00:00。如下图示: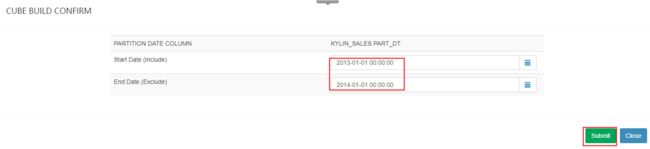
会生成新的job,可以在monitor页面查看,等待新的任务执行完成之后,可以点击Cube查看当前cube有两个Segment,这里每个Segment对应Hbase中的一张表。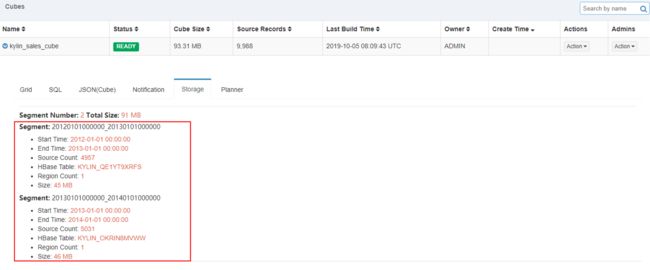
再次执行查询SQL时,将会扫描这两个Segment,也就是会扫描Hbase中两张表,这样如果Segment很多时,需要将多个Segment进行合并,会使多个Hbase表进行合并到一张Hbase表中,这样再次查询时,只需要扫描一张Hbase表即可。
合并Segment:
- 点击Cube对应的Action -> Merge:
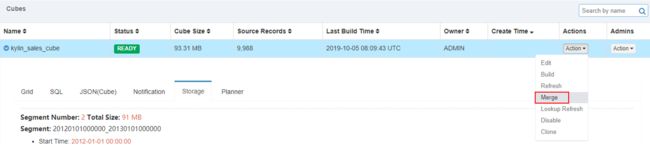
- 选择需要合并的 Segment 片段,点击 Submit
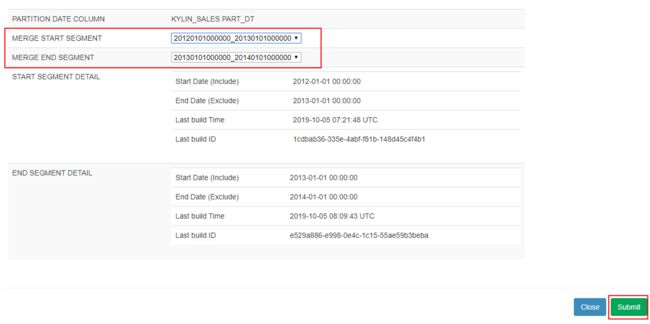
- submit之后生成新的job,执行完成之后,查看新的Segment。
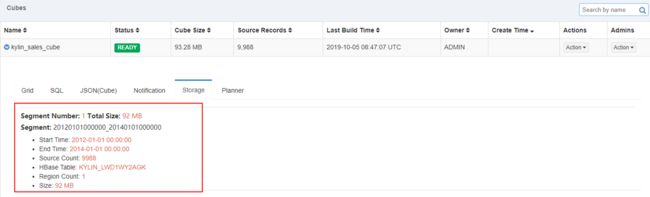
Segment合并之后,会将原来的合并的Segment段全部删除。
4.3.4 job 监控
在Monitor页面,点击job详情按钮查看显示于右侧的详细信息。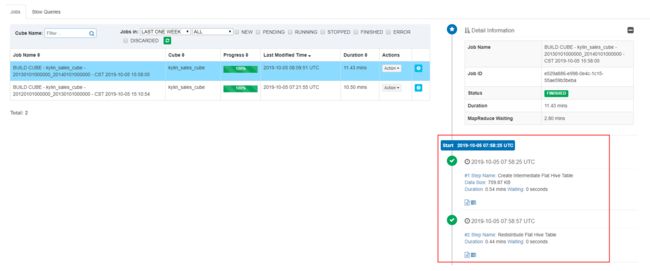
job 详细信息为跟踪一个 job 提供了它的每一步记录。你可以将光标停放在一个步骤状态图标上查看基本状态和信息。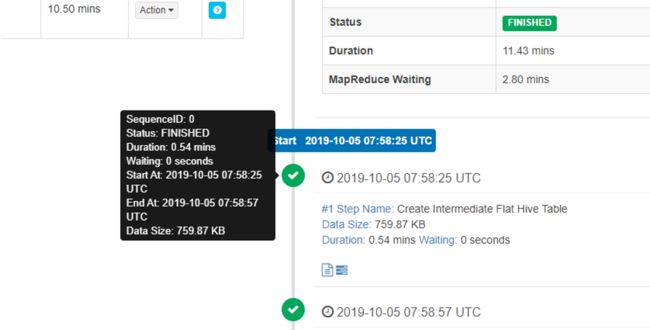
5 Kylin 构建 Cube 算法
Kylin中Cube的思想是用空间换时间, 通过预先的计算,把索引及结果存储起来,以换取查询时候的高性能。在Kylin v1.5以前,Kylin中的Cube只有一种算法:layered cubing,也称逐层算法,它是逐层由底向上,把所有组合算完的过程。Kylin v1.5以后,推出Fast Cubing,也称快速数据立方算法,是一个新的Cube算法。
5.1 layered cubing
5.1.1 基于 MR
这个算法的对cube的计算就像它的名字一样是按layer进行的。
以一个n维cube(即事实表有n个维度)为例:
player-1:以source data(源数据)为基础计算出一个n维的cuboid;
player-2:以上一层的n维cuboid维基础,计算出n个n-1维的cuboid;
… …
player-k+1:以上一层的n-k+1维cuboid为基础,计算出n!/[(n-k)!k!]=个n-k维的cuboid;
… …
player-n+1:以上一层的1维cuboid为基础,计算出1个0维的cuboid。
如下图: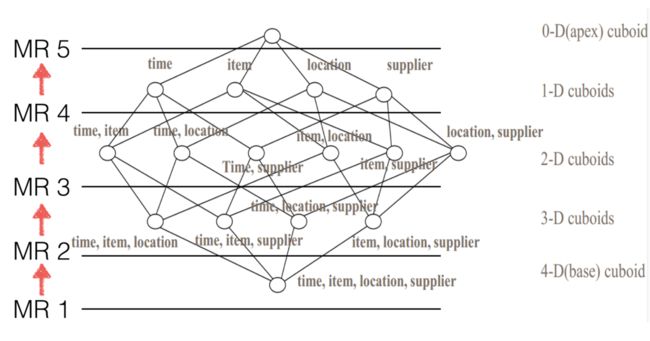
用官网上一个4维cube的例子来说明一下具体过程。
在player-1,根据源数据得到1个4-D的cuboid;然后cong中任意取出三个维度得到4个3-D cuboids;接着从3-D cuboids出发,任意取出其中两个维度得到6个2-D cuboids;再以2-D cuboids为基础,任意取出其中一个维度得到4个1-D cuboids;最后根据1-D cuboids 计算出一个0-D cuboid。
此算法的 Mapper 和 Reducer 都比较简单。Mapper以上一层Cuboid的结果(Key-Value对)作为输入。由于Key是由各维度值拼接在一起,从其中找出要聚合的维度,去掉它的值成新的Key,并对Value进行操作,然后把新Key和Value输出,进而Hadoop MapReduce对所有新Key进行排序、洗牌(shuffle)、再送到Reducer处;Reducer的输入会是一组有相同Key的Value集合,对这些Value做聚合计算,再结合Key输出就完成了一轮计算。
优点:这个算法的原理很清晰,主要就是利用了MR,sorting、grouping、shuffing全部由MR完成,开发人员只需要关注cubing的逻辑,由于hadoop的成熟,该算法的运行很稳定。
缺点:cube的维度越高,需要的MR任务越多(n-D cube 至少需要n 个MR)太多的shuffing操作(mapper端不做聚合,所有在下一层中具有相同维度的值有combiner 和reducer聚合),对hdfs读写比较多(每一层MR的结果会写到hdfs然后下一层MR从hdfs 读取数据)。
5.1.2 基于 Spark
“by-layer” Cubing把一个大任务划分为许多步骤,每一步骤的计算依赖于上一个步骤的输出结果,所以当某一个步骤的计算出现问题时,可以再次读取上一步骤的结果重新计算,而不用从头开始。使得“by-layer” Cubing算法稳定可靠,当换到spark上时,便保留了这个算法。因此在spark上这个算法也被称为“By layer Spark Cubing”。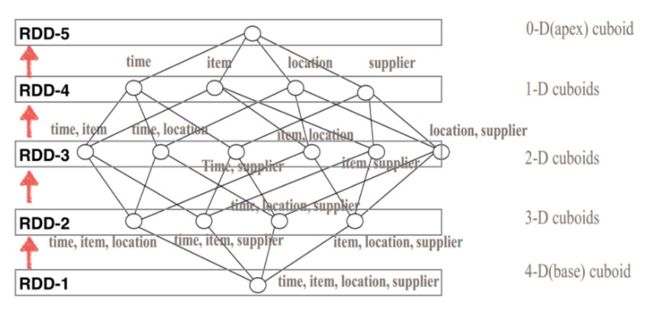
如上图所示,与在MR上相比,每一层的计算结果不再输出到hdfs,而是放在RDD中。由于RDD存储在内存中,从而有效避免了MR上过多的读写操作。
性能对比: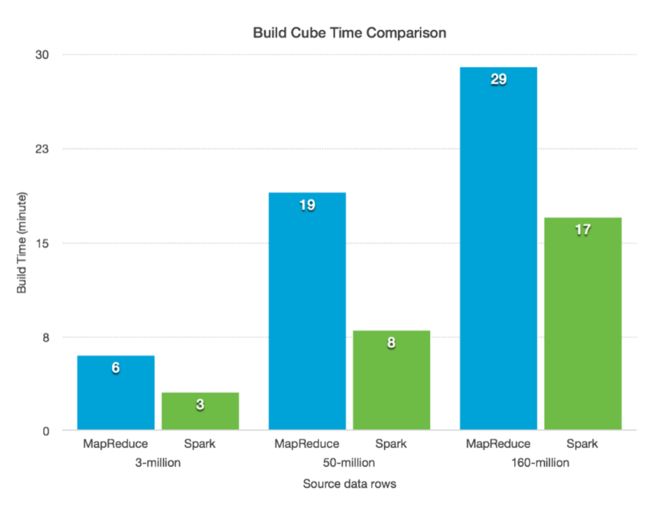
5.2 Fast cubing
快速Cube算法(Fast Cubing)是麒麟团队对新算法的一个统称,它还被称作“逐段”(By Segment) 或“逐块”(By Split) 算法。
该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;下图解释了此流程。新算法的核心思想是清晰简单的,就是最大化利用Mapper端的CPU和内存,对分配的数据块,将需要的组合全都做计算后再输出给Reducer;由Reducer再做一次合并(merge),从而计算出完整数据的所有组合。如此,经过一轮Map-Reduce就完成了以前需要N轮的Cube计算。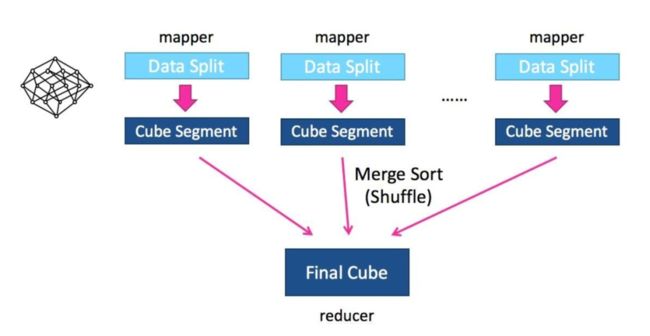
在Mapper内部也可以有一些优化,下图是一个典型的四维Cube的生成树;第一步会计算Base Cuboid(所有维度都有的组合),再基于它计算减少一个维度的组合。基于parent节点计算child节点,可以重用之前的计算结果;当计算child节点时,需要parent节点的值尽可能留在内存中; 如果child节点还有child,那么递归向下,所以它是一个深度优先遍历。当有一个节点没有child,或者它的所有child都已经计算完,这时候它就可以被输出,占用的内存就可以释放。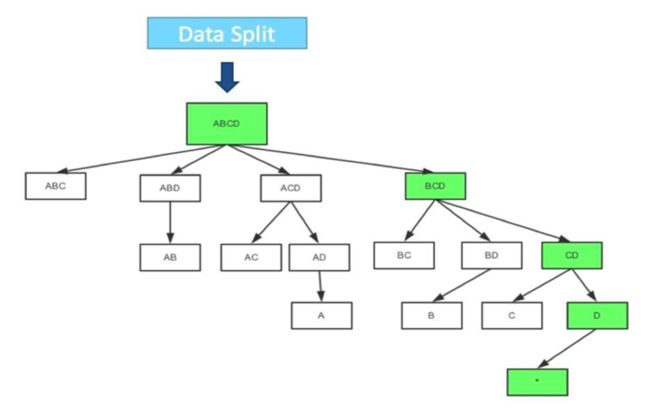
如果内存够的话,可以多线程并行向下聚合。如此可以最大限度地把计算发生在 Mapper 这一端,一方面减少 shuffle 的数据量,另一方面减少 Reducer 端的计算量。
优点:总的IO量比以前大大减少。此算法可以脱离Map-Reduce而对数据做Cube计算,故可以很容易地在其它场景或框架下执行,例如Streaming 和Spark。
缺点:代码比以前复杂了很多,由于要做多层的聚合,并且引入多线程机制,同时还要估算JVM可用内存,当内存不足时需要将数据暂存到磁盘,所有这些都增加复杂度。对 Hadoop 资源要求较高,用户应尽可能在 Mapper 上多分配内存;如果内存很小,该算法需要频繁借助磁盘,性能优势就会较弱。在极端情况下(如数据量很大同时维度很多),任务可能会由于超时等原因失败。
5.3 算法选择
用户无需担心使用什么算法构建cube,Kylin会自动选择合适的算法。Kylin在计算Cube之前对数据进行采样,在“fact distinct”步,利用HyperLogLog模拟去重,估算每种组合有多少不同的key,从而计算出每个Mapper输出的数据大小,以及所有Mapper之间数据的重合度,据此来决定采用哪种算法更优。
- 如果每个Mapper之间的key交叉重合度较低,fast cubing更适合;因为Mapper端将这块数据最终要计算的结果都达到了,Reducer只需少量的聚合。另一个极端是,每个Mapper计算出的key跟其它 Mapper算出的key深度重合,这意味着在reducer端仍需将各个Mapper的数据抓取来再次聚合计算;如果key的数量巨大,该过程IO开销依然显著。对于这种情况,Layered-Cubing更适合。
- 在对上百个Cube任务的时间做统计分析后,Kylin选择了7做为默认的算法选择阀值(参数kylin.cube.algorithm.auto.threshold):如果各个Mapper的小Cube的行数之和,大于reduce后的Cube行数的8倍(各个Mapper的小Cube的行数之和 / reduce后的Cube行数 > 7),采用Layered Cubing, 反之采用Fast Cubing(本质就是各个Mapper之间的key重复度越小,就用Fast Cubing,重复度越大,就用Layered Cubing)
6 Kylin 构建 Cube 实战
6.1 向 Hive 中导入数据
根据“CreateData.java”文件生成对应的事实表,然后执行SQL语句将对应的维度表和事实表导入到Hive中。
维度表region_tbl,数据如下:
1. G01|北京
2. G02|江苏
3. G03|浙江
4. G04|上海
5. G05|广州
6.
维度表city_tbl,数据如下:
1. G01|G0101|朝阳
2. G01|G0102|海淀
3. G02|G0201|南京
4. G02|G0202|宿迁
5. G03|G0301|杭州
6. G03|G0302|嘉兴
7. G04|G0401|徐汇
8. G04|G0402|虹口
9. G05|G0501|广州
10. G05|G0502|珠海
11.
事实表web_access_fact_tbl数据内容举例如下:
1. 2019-08-01|L3H1WG60WD9IELX6YL|G04|G0401|2187|Mac OS|4
2. 2019-08-29|9MOYSWCVLBJ7E3GB6J|G05|G0501|1729|Android 5.0|4
3. 2019-08-18|EGCC46W3OO5CW2Q9W8|G05|G0502|3968|Android 5.0|2
4. 2019-08-22|8MFUQGRE028ZR304FT|G03|G0302|7327|Android 5.0|3
5. 2019-08-26|YB0GXNMF59CBC49CZ3|G05|G0502|8874|Android 5.0|9
6. 2019-08-22|X9MPZ2OX2U10S3DO17|G01|G0101|4771|Mac OS|9
7. 2019-08-07|BYXUH2FZQ36ZNM6YJS|G04|G0402|6601|Mac OS|9
8. ... ...
9.
在Hive中创建对应的表,将数据导入到Hive中,执行如下命令:
1. create table web_access_fact_tbl
2. (
3. day date,
4. cookieid string,
5. regionid string,
6. cityid string,
7. siteid string,
8. os string,
9. pv bigint
10. )
11. row format delimited fields terminated by '|' stored as textfile;
12.
13. load data local inpath '/software/test/fact_data.txt' into table web_access_fact_tbl;
14.
15. create table region_tbl
16. (
17. regionid string,
18. regionname string
19. )
20. row format delimited fields terminated by '|' stored as textfile;
21.
22. load data local inpath '/software/test/region.txt' into table region_tbl;
23.
24. create table city_tbl
25. (
26. regionid string,
27. cityid string,
28. cityname string
29. )
30. row format delimited fields terminated by '|' stored as textfile;
31.
32. load data local inpath '/software/test/city.txt' into table city_tbl;
33.
6.2 在 Kylin 中创建项目构建 cub
-
在Kylin中创建project:
点击页面左上方“+”号,add project,创建项目: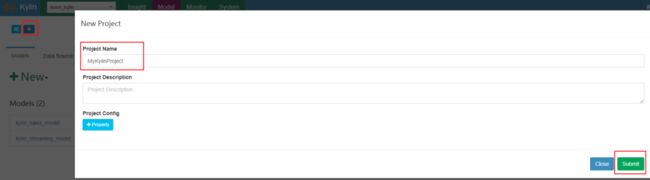
-
给项目DataSource 导入数据:
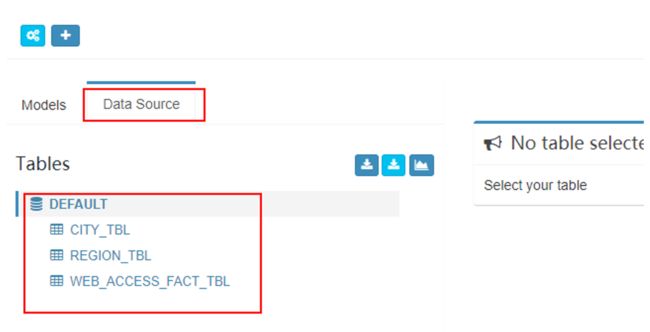
-
创建新的model
在kylin页面左侧点击“new”->“New Model”,输入model名称,点击“Next”: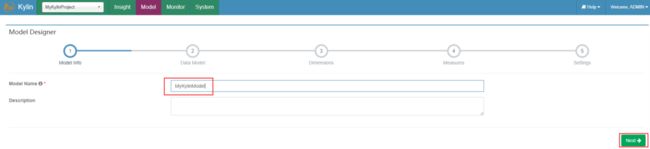 在DataModel中,选择事实表,添加维度表(lookup table),同时指定关联关系,点击“Next”:
在DataModel中,选择事实表,添加维度表(lookup table),同时指定关联关系,点击“Next”: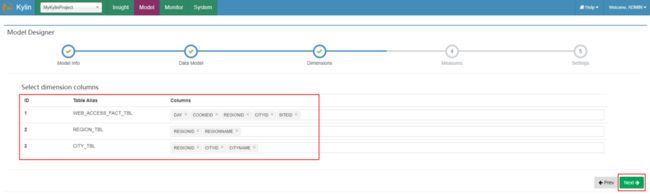
在“Dimensions”页面中,选择每个表的维度信息,注意:在事实表中要预留出某些列是度量信息列,某些列不能即是维度列又是度量列,如下图,选择完成后,点击“Next”: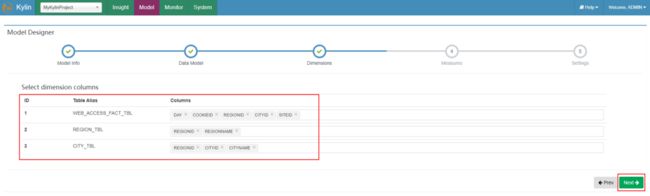
在“Measures”页面中,选择度量信息列,这些列必须出现在事实表中,并且不能是维度列,如下图: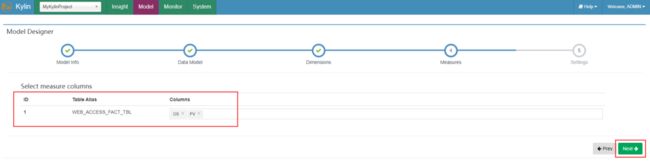
在“settings”页面中,选择分区信息和过滤条件。这里的分区信息指的是按照时间分区,如果没有可以跳过页面设置,点击“Save”保存模型。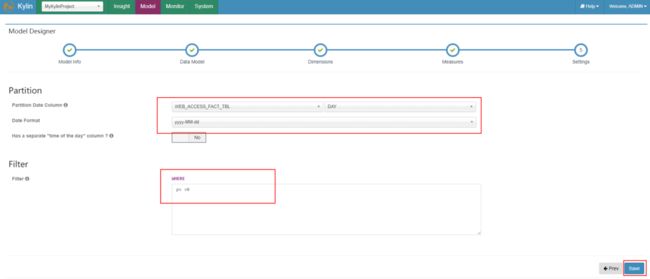
-
模型创建完成之后,创建Cube
点击Kylin页面左上角“New”->“New Cube”,在页面中选择刚刚创建的Model,同时输入Cube名称,点击“Next”: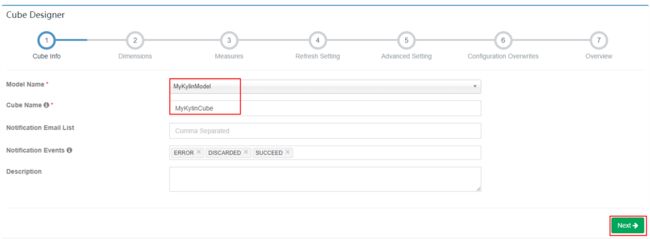
在“Dimensions”页面中,设置维度。点击“Add Dimensions”,注意,在这里如果维度表中的某些列是可以由事实表关联字段推测出来,也就是关联字段,可以选择成“Derived”列,这样,这个列不参与构建维度,可以减少维度。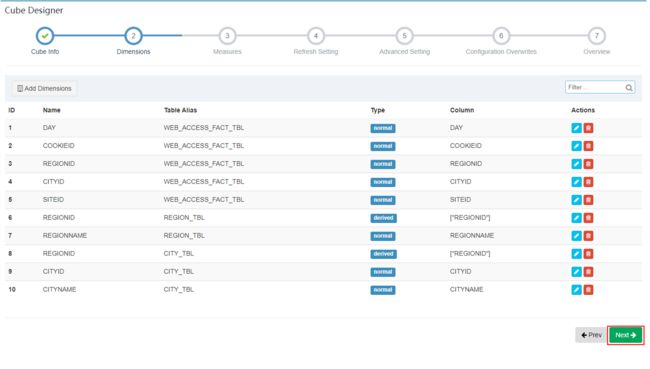
在“Measures”页面中,默认有Count聚合,可以添加其他聚合函数,点击“Next”: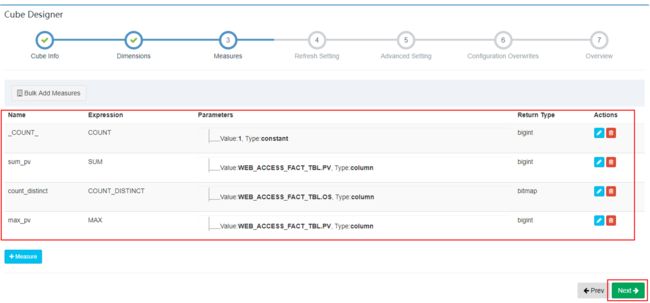
在“Refresh Setting”页面中可以设置segment合并规则,点击“Next”: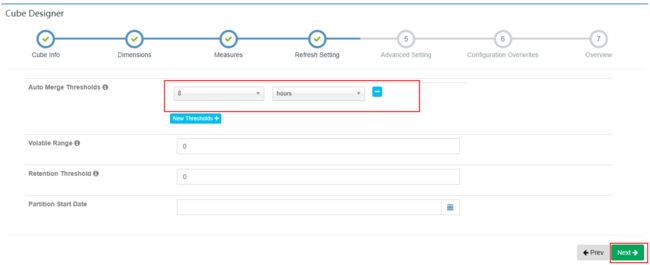
在“Advanced Setting”高级设置中,可以设置必要维度、层级维度、联合维度、执行引擎及rowkey顺序和列族等信息,点击“Next”,在“Configuration Overwrites”中设置配置项,点击“Next”->”Save”,完成Cube构建。 -
构建cube
点击对应cube的“action”->“build”。
6.3 结果 SQL 查询
进入Kylin页面中的“Insight”,查询如下业务,统计每天每个地区每个城市总的pv量和访问系统类别总数
1. select a."DAY",b.regionname,c.cityname,sum(a.pv) as totol_pv,count(distinct a.os) as os_count
2. from web_access_fact_tbl a
3. join region_tbl b on a.regionid=b.regionid
4. join city_tbl c on a.cityid=c.cityid
5. group by a."DAY",b.regionname,c.cityname
6. order by a."DAY",b.regionname
查询结果如下: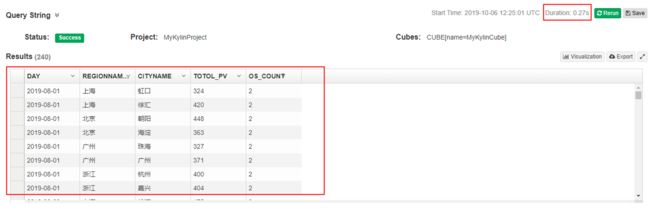
注意:kylin建cube所用的字段最好不要采用kylin 关键字,例如:year, month, day, hour等。否则写SQL时,不太友好。关键词必须全部大写,且被双引号(必须是双引号,单引是自定义常量)包住。
注意构建kylin中model时,事实表和维度表之间的关联是使用的left join 还是 inner join,如果使用left join 在使用kylin时,也应使用left join 进行关联。
7 JDBC访问Kylin
使用Java api连接kylin url格式为:
jdbc:kylin://:/
7.1 使用Statement查询
1. public class KylinDemo {
2.
3. public static void main(String[] args) throws Exception {
4. Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
5. Properties info = new Properties();
6. info.put("user", "ADMIN");
7. info.put("password", "KYLIN");
8. Connection conn = driver.connect("jdbc:kylin://mynode3:7070/learn_kylin", info);
9. Statement state = conn.createStatement();
10. ResultSet rs = state.executeQuery(
11. "select part_dt,sum(price) as total_selled,count(distinct seller_id) as sellers from kylin_sales group by part_dt order by part_dt limit 5 ");
12. while (rs.next()) {
13. System.out.println(rs.getString(1) + "\t" + rs.getString(2) + "\t" + rs.getString(3));
14. }
15. conn.close();
16. }
17. }
18.
7.2 使用PreparedStatement查询
19. public class KylinPreparedDemo {
20.
21. public static void main(String[] args) throws Exception {
22. Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
23. Properties info = new Properties();
24. info.put("user", "ADMIN");
25. info.put("password", "KYLIN");
26. Connection conn = driver.connect("jdbc:kylin://mynode3:7070/learn_kylin", info);
27. PreparedStatement pstmt = conn
28. .prepareStatement("select * from kylin_category_groupings where leaf_categ_id =?");
29. pstmt.setLong(1, 10058);
30. ResultSet rs = pstmt.executeQuery();
31. while (rs.next()) {
32. System.out.println(rs.getString(1) + "\t" + rs.getString(2) + "\t" + rs.getString(3));
33. }
34. }
35. }