beaninfo详解源码解析 java_Java集合框架之二:LinkedList源码解析
走过路过不要错过
点击蓝字关注我们
LinkedList底层是通过双向循环链表来实现的,其结构如下图所示:
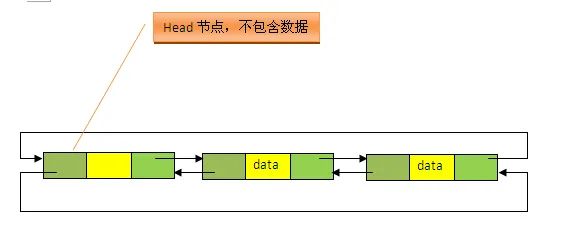
链表的组成元素我们称之为节点,节点由三部分组成:前一个节点的引用地址、数据、后一个节点的引用地址。LinkedList的Head节点不包含数据,每一个节点对应一个Entry对象。下面我们通过源码来分析LinkedList的实现原理。
1、Entry类源码:
private static class Entry {
E element; Entry next; Entry previous; Entry(E element, Entry next, Entry previous) {
this.element = element; this.next = next; this.previous = previous; } }Entry类包含三个属性,其中element存放业务数据;next存放后一个节点的信息,通过next可以找到后一个节点;previous存放前一个节点的信息,通过previous可以找到前一个节点。
2、LinkedList的构造方法:LinkedList提供了两个带不同参数的构造方法。
1) LinkedList(),构造一个空列表。
2) LinkedList(Collection extends E> c),构造一个包含指定 collection 中的元素的列表,这些元素按其 collection 的迭代器返回的顺序排列。
private transient Entry header = new Entry(null, null, null); //声明一个空的Entry对象private transient int size = 0; //集合中节点的个数public LinkedList() {
header.next = header.previous = header; //构造一个双向循环链表,header的前驱节点和后置节点都指向header自己}public LinkedList(Collection extends E> c) {
this(); //调用不带参数的构造方法,创建一个空的循环链表 addAll(c); //调用addAll方法将Collection的元素添加到LinkedList中}当调用不带参数的构造方法,header的前驱节点和后置节点都指向header自己,构成了一个双向循环的链表。如下图所示:
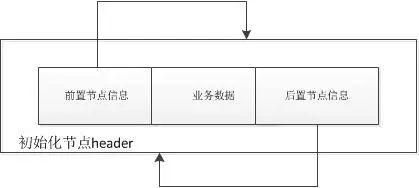
当调用带集合参数的构造方法生成LinkedList对象时,会先调用不带参数的构造方法创建一个空的循环链表,然后调用addAll方法将集合元素添加到LinkedList中。
3、向集合中添加元素:LinkedList提供了多种不同的add方法向集合添加元素。
1) add(E e),将指定元素添加到此列表的结尾。
2) add(int index, E element),在此列表中指定的位置插入指定的元素。
3) addAll(Collection extends E> c),添加指定 collection 中的所有元素到此列表的结尾,顺序是指定 collection 的迭代器返回这些元素的顺序。
4) addAll(int index, Collection extends E> c),将指定 collection 中的所有元素从指定位置开始插入此列表。
5) addFirst(E e),将指定元素插入此列表的开头。
6) addLast(E e),将指定元素添加到此列表的结尾。
通过源码来分析其底层的实现原理:
public boolean add(E o) {
addBefore(o, header); return true;}private Entry addBefore(E o, Entry e) {
Entry newEntry = new Entry(o, e, e.previous); //创建的对象newEntry的数据为o,后置节点为header,前驱节点为header.previous即header本身 newEntry.previous.next = newEntry; //newEntry.previous即为header,也就是header.next = newEntry,把header的后置节点设置为newEntry newEntry.next.previous = newEntry; //newEntry.next即header,也就是header.previous = newEntry,经过以上步骤header节点和newEntry节点形成闭环 size++; //节点数加1 modCount++; return newEntry;}通过以上源码分析可知,add(E elment)方法新添加一个元素element时,在LinkedList底层首先创建一个Entry类型的对象newEntry,并把元素element存放在newEntry中,同时把newEntry的前驱节点设置为header,后置节点也设置为header。接下来,将header节点的后置节点设置为newEntry,将header的前驱节点也设置为newEntry,并且节点数size加1。通过以上操作,节点header和节点newEntry形成闭环(双向循环链表)。其示意图如下:
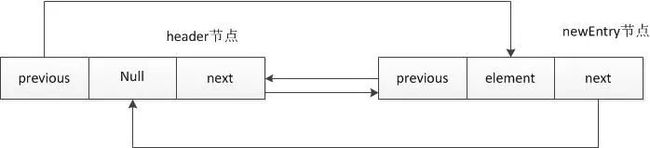
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));//调用addBefore将元素插入指定的位置}add(int index, E element)方法的实现原理与add(E elment)方法类似,都是调用addBefore方法实现,其本质还是生成一个新的Entry对象,然后修改指定位置的节点的前驱节点信息以及后置节点信息,这里就不再赘述了。
public boolean addAll(Collection extends E> c) {
return addAll(size, c);}public boolean addAll(int index, Collection extends E> c) {
if (index < 0 || index > size) //检查参数index是否合法 throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); Object[] a = c.toArray(); //返回一个包含Collection集合所有元素的Object[] int numNew = a.length; if (numNew==0) //如果需要插入的元素为0,则返回false,表示没有元素需要插入 return false; modCount++; //否则插入元素,链表修改次数加1 Entry successor = (index==size ? header :entry(index)); //获取index位置的节点。插入位置如果等人size,则在头节点header处插入,否则在获取的index处插入 Entry predecessor = successor.previous; //获取节点的前驱节点,插入时需要修改此节点的next for (int i=0; i Entry e = new Entry((E)a[i], successor, predecessor); //创建一个Entry对象 predecessor.next = e; //将新插入的节点的前一个节点的next指向当前节点 predecessor = e; //将新插入的节点赋值给predecessor,相当于指针向后移,实现循环 } successor.previous = predecessor; //将断开的index处的节点的previous指向插入的最后一个节点 size += numNew; //修改节点个数 return true; }public void addFirst(E o) {
addBefore(o, header.next);}public void addLast(E o) {
addBefore(o, header);}从源码可知,这两个方法都是调用addBefore(E e, Entry entry)方法实现,插入节点的示意图如下:

结合addBefore(E e, Entry entry)方法不难理解addFirst(E e)只需要在header下一个节点之前插入即可;addLast(E e)只需要在header之前插入,因为在循环链表中,header前一个节点也是链表的最后一个节点。
4、获取LinkedList中的元素:
1) get(int index),返回此列表中指定位置处的元素。
2) getFirst(),返回此列表的第一个元素。
3) getLast(),返回此列表的最后一个元素。
public E get(int index) {
return entry(index).element;}private Entry entry(int index) { //获取双向链表指定位置的节点 if (index < 0 || index >= size) //检查参数index合法性,当指定的位置index小于零或大于集合容量,抛出异常 throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); Entry e = header; if (index < (size >> 1)) { //获取index处的节点,当index小于链表长度的1/2,则从前向后查找;否则从后向前查找。这样能提供查找效率。 for (int i = 0; i <= index; i++) e = e.next; } else {
for (int i = size; i > index; i--) e = e.previous; } return e;} public E getFirst() {
if (size==0) throw new NoSuchElementException(); return header.next.element; //返回header节点的下一个节点。 }public E getLast() {
if (size==0) throw new NoSuchElementException(); return header.previous.element; //返回header节点的前一个节点,由于是双向循环链表,header前一个节点也是链表的最后一个节点。 }从LinkedList底层链表的实现原理可知,LinkedList集合的查找操作是从header节点开始的。可以从header节点开始从前向后一个一个节点顺序查找或者从后向前依次顺序查找。而ArrayList的查找操作则是直接获取数组下标处的元素,因此查询效率更高。
5、移除LinkedList中的元素:
1) remove(),获取并移除此列表的头(第一个元素)。
2) remove(int index),移除此列表中指定位置处的元素。
3) remove(Object o),从此列表中移除首次出现的指定元素(如果存在)。
4) removeFirst(),移除并返回此列表的第一个元素。此方法等同于remove()。
5) removeLast(),移除并返回此列表的最后一个元素。
public E remove() {
return removeFirst(); //调用removeFirst()方法。 }public E remove(int index) {
return remove(entry(index)); //调用私有方法remove(Entry e)以及entry(int index)。 }public E removeFirst() {
return remove(header.next); //调用私有方法remove(Entry e)。 }public E removeLast() {
return remove(header.previous); //调用私有方法remove(Entry e)。 }public boolean remove(Object o) {
if (o==null) { 如果要删除的元素内容为null for (Entry e = header.next; e != header; e = e.next) {
if (e.element==null) {
remove(e); //调用私有方法remove(Entry e)。 return true; } } } else {
for (Entry e = header.next; e != header; e = e.next) {
if (o.equals(e.element)) {
remove(e); return true; } } } return false; }private E remove(Entry e) {
if (e == header) throw new NoSuchElementException(); E result = e.element; //保存将要被移除的节点的内容。 e.previous.next = e.next; //将节点e的前驱节点的后继设置为e的后继节点。 e.next.previous = e.previous; //将e的后继节点的前驱设置为e的前驱节点。 e.next = e.previous = null; //将e节点的后继指向以及前驱指向设置为空。 e.element = null; //将e节点的内容清空。 size--; //节点个数减1。 modCount++; //链表操作次数加1。 return result; //返回被删除的节点内容。 }从源码可以看出,移除节点操作最终都是调用私有方法remove(Entry e)。删除某一节点的操作本质上是修改其相关节点的指针信息。其原理如下:
e.previous.next = e.next; //预删除节点e的前驱节点的后继指针指向e的后继节点。
e.next.previous = e.previous; //预删除节点e的后继节点的前驱指针指向e的前驱节点。
清空预删除节点的指针信息以及内容:
e.next = e.previous = null; //清空后继指针和前驱指针的信息。
e.element = null; //清空节点的内容。
通过对以上部分关键源码的分析,我们可以知道LinkedList集合的底层是基于双向循环链表来实现的。链表中维护了一个个Entry对象,Entry对象由三部分组成:previous(前驱指针,指向前驱节点)、element(数据)、next(后继指针,指向后继节点)。对LinkedList集合元素的操作本质上是对链表中维护的Entry对象的操作(修改相关对象的指针信息、数据),明白了这一点,就能很容易的理解LinkedList集合的常用方法的底层实现原理。下面对LinkedList源码有几点总结:
1) LinkedList不是线程安全的。在多线程环境下,可以使用Collections.synchronizedList方法声明一个线程安全的ArrayList,例如:
List list = Collections.sychronizedList(new LinkedList());
2) LinkedList是有序集合。LinkedList的查找操作是从header节点开始的,从前往后或者从后往前依次逐个节点查找,因此查询效率低,而ArrayList可以直接通过下标查找,查询效率高;由于LinkedList集合元素的添加、删除操作只需要修改节点的指针信息,因此添加、删除元素的效率高,而ArrayList的添加、删除操作会涉及大量元素位置的迁移,因此添加、删除元素的效率低。
腾讯、阿里、滴滴后台面试题汇总总结 — (含答案)
面试:史上最全多线程面试题 !
最新阿里内推Java后端面试题
JVM难学?那是因为你没认真看完这篇文章
关注作者微信公众号 —《JAVA烂猪皮》
了解更多java后端架构知识以及最新面试宝典


看完本文记得给作者点赞+在看哦~~~大家的支持,是作者源源不断出文的动力。