【知识图谱系列】解耦Transformation和Propagation的深度图神经网络
作者:CHEONG
公众号:AI机器学习与知识图谱
研究方向:自然语言处理与知识图谱
本文介绍一篇解耦合Transformation和Propagation操作的自适应深度图神经网络模型DAGNN(KDD 2020),介绍DAGNN模型核心点和模型思路,完整汇报ppt获取请关注公众号回复关键字:DAGNN
一、Motivation
1. Over-fitting: 在CNN卷积神经网络中,若CNN网络结构过于复杂过于Deep,且数据量有限的情况下,便会出现Over-fitting问题,Over-fitting就是指模型对于训练数据过度学习,学习到训练数据本身而不是训练数据的规律,导致无法在测试集上准确预测的情况。
2. Over-Smoothing: 在GNN图神经网络中,由于图本身结构上节点与节点之间相互连接的特性,并且图神经网络一般是通过邻域汇聚或随机游走的方式进行表征学习,因此当图网络一旦变深,便会出现Over-Smoothing问题,Over-Smoothing指的是随着图神经网络加深,学习到的节点表征越来越相似,以至于无法区分,模型效果也将大幅下降。且在图网络中一般2 Layers时效果最佳。因此如何在DeepGNN中既能学到更深层次信息又能避免Over-Smoothing显得至关重要。
3. DeepGNN的必要性: 通常对于少标签半监督节点分类任务,或是少特征半监督节点分类任务,DeeperGNN便较为重要,在特征较少时,便想通过多跳传递能学到更多有效信息。
二、 Definition
1. 量化Over-Smoothing指标
首先明确Over-Smoothing是指随着图神经网络变深学习到的节点表征逐渐相似而无法区分。如下公式所示,本文定义用欧几里得距离表示节点i和节点j之间的相似度D(x_i,x_j ),用SVM_i表示节点i和其他所有节点的相似度,而SVM_G表示图中任意两点之间的相似度,作为整个图的是否Over-Smoothing的评估指标。理想状况下,如果图完全Over-Smoothing,则认为图中所有节点表征完全相似,则SVM_G则趋近0。

2. 接下来通过实验看SVM_G指标随着图神经网络层次的加深,如何变化?横坐标代表模型层数,可以看到在模型层数为2层是,Test Accuracy达到最好效果,从3层开始模型效果开始下降。而Smoothness Metric Value SVM_G 随着层数增加因为逐渐Over-Smoothing,所以SVM_G值逐渐减小,最后趋向于一个小且非0的定值。之所以不是趋向0也是因为节点本身特征区别等节点自身因素。

三、Method
本文针对Over-Smoothing问题进行理论分析,提出了DAGNN模型,包含两个主要的创新点:
1、Transformation和Propagation解耦合:传统GCN模型的Transformation和Propagation操作是交替进行的,DAGNN模型解耦了Transformation和Propagation操作;
2、自适应深度感受野Adaptive Adjustment:文中提出Over-Smoothing被证明只有当propagation操作时使用非常大的感受野large receptive fields才会影响模型性能,因此本文提出了Deep Adaptive GNN,自适应的从large receptive fields中学习有用的信息。
为了加深对模型的理解,我们先来看一下Transformation和Propagation解耦合的具体含义和操作方式。
1、Transformation操作: Transformation操作指的就是MLP操作,torch.nn.Linear线性映射操作;
2、Propagation操作: Propagation操作指的是图中的邻居节点往中心节点汇聚的操作,最简单的实现方式是AH,A指的是图的邻接矩阵,H指的是图的特征矩阵。
3、 传统GCN模型Transformation操作和Propagation操作是耦合在一起交替计算的,口说无凭,直接上代码简单明了。

4、 了解了传统GCN模型Transformation和Propagation交替实现的方式,大概也能想一下如果解耦二者便是:先Transformation再Propagation操作,或者先Propagation再Transformation操作,而本文DAGNN模型便是前者,而另一篇论文Grand则是使用的后者,也在DeepGNN取得了很好的效果。
如上图所示展示了DAGNN模型结构,从模型图再理解一下模型的两大创新点实现方式。
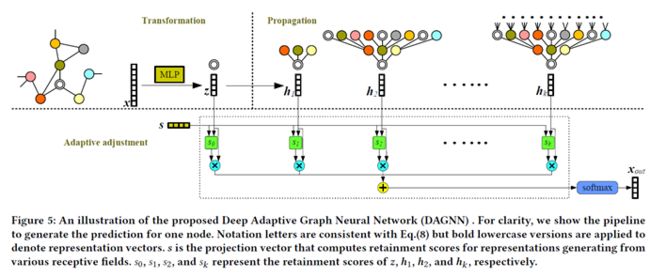
1、 先看图中虚线上半部分的模型图,将Transformation和Propagation解耦合,初始节点特征X输入后先通过Transformation操作,即MLP得到输出z(官方给的实现代码中是先通过两次MLP操作);再将z进行k次的Propagation操作;也就是先Transformation操作再Propagation操作;
2、 接着看虚线下半部分模型图,自适应选择感受野信息,将Propagation过程得到的中间输出h_i通过一个可学习参数s进行自适应选择每次Propagation输出的h_i,参数s相当于一个Attention权重,可以给每层的h_i赋予一个权值,最终加和后通过softmax函数得到输出x_out
下图是整个DAGNN模型的实现公式,我们从公式角度再来更加深入的理解一下。

X是初始特征,A ̂是归一化的邻接矩阵,A ̂=D ̃^(-1/2) 〖A ̃D ̃〗^(-1/2),其中D ̃=D+I,A ̃=A+I;先将初始特征X过MLP得到映射后的特征矩阵Z,当前的Z只包含节点本身信息而无结构信息;再和A ̂进行k次的Propagation操作得到H_l,H_l 包含了l层的结构信息;接下来要将所有l层的信息汇聚起来,最简单的方式当然是直接加和或者直接取最后一层信息作为最终输出,但DAGNN模型希望模型能够自适应的学习0-k层信息。
因此引入了可学习参数s,来学习0-k层的权重大小S ̃,再进行有权加和S ̃H,而DAGNN具体实现方式是先将0-k层的表征stack在一起得到H,引入小s参数,通过两步变换得到权重S ̃,最后一步再进行有权加和经过softmax函数得到最终输出X_out
四、Code
1、 DAGNN模型实现思路也很简单,核心代码如下图所示,官网提供代码获取地址:
https://github.com/divelab/DeeperGNN

五、Conclusion
1、 在Cora、CiteSeer和PubMed三个引文数据上DAGNN模型都获得了最佳的效果。

2、 因为是半监督节点分类实验,因此训练集取得标签数目是可控的,本文还采样不同比例标签的训练数据做实验对比,结果显示训练数据中标签越多,实验结果越好。

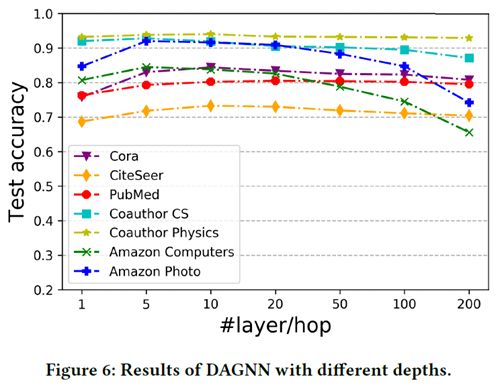
3、 本文将DAGNN模型层数从1-200层均做了实验对比,从图中可以看出,大致在5层时模型取得最优效果,这点说明随着层数叠深,DAGNN模型在一定程度上缓解了Over-Smoothing问题且学到了更多有效信息。但随着5层之后模型效果逐渐下降,这点说明DAGNN模型只是缓解而未完全解决,模型层数过深时仍然会出现Over-Smoothing问题。
六、往期精彩
【知识图谱系列】Over-Smoothing 2020综述
【知识图谱系列】知识图谱的神经符号逻辑推理
【知识图谱系列】知识图谱表示学习综述 | 近30篇优秀论文串讲
【知识图谱系列】探索DeepGNN中Over-Smoothing问题
【知识图谱系列】动态时序知识图谱EvolveGCN
【知识图谱系列】多关系神经网络CompGCN
【面经系列】八位硕博大佬的字节之旅
各大AI研究院共35场NLP算法岗面经奉上
【机器学习系列】机器学习中的两大学派
干货 | Attention注意力机制超全综述
干货 | NLP中的十个预训练模型
干货|一文弄懂机器学习中偏差和方差
FastText原理和文本分类实战,看这一篇就够了
Transformer模型细节理解及Tensorflow实现
GPT,GPT2,Bert,Transformer-XL,XLNet论文阅读速递
机器学习算法篇:最大似然估计证明最小二乘法合理性
Word2vec, Fasttext, Glove, Elmo, Bert, Flair训练词向量教程+数据+源码
汇报完整版ppt可通过关注公众号后回复关键词:DAGNN 来获得,有用就点个赞呗