opencv把图片转换成二进制_码鸭日记OpenCV项目实战人脸检测(三)
上篇文章提到过,如果想提高识别率,主要可以采取两种方法:利用OpenCV来进行个人的模型训练,或者利用更高精度的dlib来进行检测。
此篇文章主要讲述如何利用OpenCV来训练个人的模型。
由于haarcascades的人脸数据模型是基于大众的,由于人脸的差异,当对个人进行人脸测试时难免会出现漏判误判。这时我们为了提高准确性可以利用OpenCV来训练一个属于自己的模型.
环境搭建
1, 在编写代码之前,需要引入numpy包。NumPy(Numerical Python)是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵。
一般的python需要手动引入,即pip list numpy。但是如果安装了anaconda来作为解释器,由于其内部自带numpy,Spyder等工具,无需手动引入。
注意的是,安装anaconda后,需要在系统环境中更改路径,以及在pycharm中更换解释器。具体操作如下:
属性---控制面板---高级系统设置---环境变量---编辑环境变量
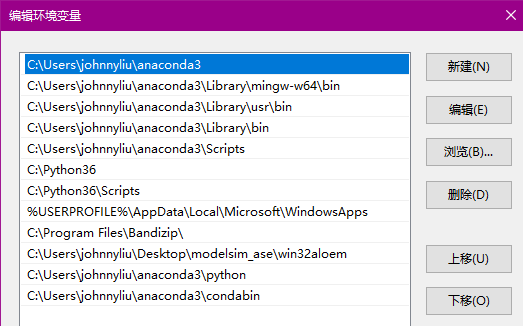
将anaconda的环境配置如上。
点击环境变量的path---点击编辑,在末尾添加如下路径。
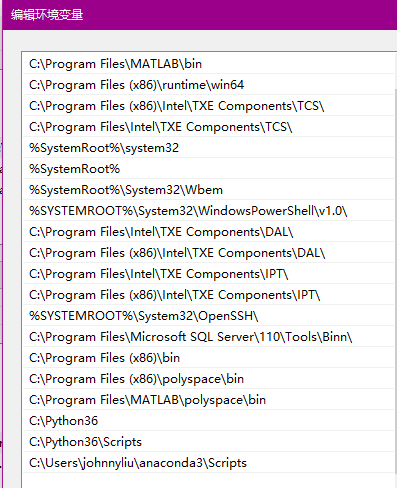
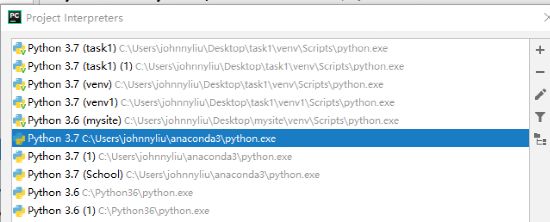
打开pycharm---settings---project interpreter---add---选择anaconda中python.exe的地址
2,PIL(Python Imaging Library)是Python中一个强大的图像处理库,但目前其只支持到Python2.7。本人所使用的python版本是3.6.
当使用命令pip install pil时,系统报错:Could not find a version that satisfies the requirement PIL (from versions: ), No matching distribution found for PIL。
意思就是说pil 和我当前的版本不匹配。在用另外的安装语句如--user 或者加入镜像源后依然失败。
这时注意,我们应该安装的是pillow,Pillow是PIL的一个派生分支,但如今已经发展成为比PIL本身更有用的图像处理库。利用语句 pip install pillow,安装成功。
使用语句from pil import image 来对此模块进行调用。
3,OpenCV--contrib-python安装
注意OpenCV不能代替OpenCV-contrib。OpenCV Contrib是OpenCV的扩展模块,包含了许多最新的以及可能还没有正式发布有待进一步完善的算法,可以理解为是OpenCV的扩展包。此项目中的LBPHFaceRecognizer_create()就为contrib中的函数。使用pip install OpenCV-contrib-python来进行安装。如果报错,则可以换位另外一种安装方法:安装下载的.whl文件,注意.whl文件需要与自身机型环境所匹配。例如我下载了opencv_python‑3.2.0‑cp36‑cp36m‑win_amd64.whl,这个名字标识了三部分内容:cp35,cp35m和win_amd64。cp35表示Python是3.6版本,win_amd64是表示安装的Python是64bit的。随后在cmd界面中输入以下语句:“pip install 文件路径\opencv_python‑3.2.0‑cp35‑cp35m‑win_amd64.whl”。如果报错,检查下pip的版本是否为最新,或者使用pip install --user 地址来进行尝试。理论知识
1,LBPHFaceRecognizer介绍
对于训练个人模型并进行人脸识别,目前有很多可用方法,比如OpenCV自带的EigenFaceRecognizer(基于PCA降维) , FisherFaceRecognizer(基于LDA降维),LBPHFaceRecognizer(基于LBPH特征)。再如faceNet深度网络模型(128个特征输出)加分类器(如SVM)方式。
目前我们需要应用的场景是结果好,对于硬件要求不是很高,方便更新模型,低成本的方式。因此我选择了OpenCV自带的LBPHFaceRecognizer算法,这种算法优点是不会受到光照、缩放、旋转和平移的影响,最大的好处就是对电脑自身配置要求不高,通用化非常好。
2,LBPF
2.1 原始LBP算子
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于或等于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理特征。如下图所示:
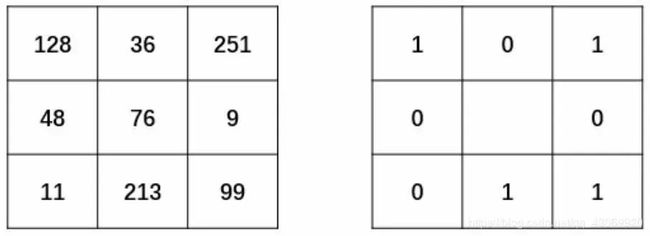
完成二值化以后,任意指定一个开始位置,将得到的二值结果进行序列化,组成一个8位的二进制数。例如,从当前像素点的正上方开始,以顺时针为序得到二进制序列“01011001”。 最后,将二进制序列“01011001”转换为所对应的十进制数“89”,作为当前中心点的像素值,如下图所示。
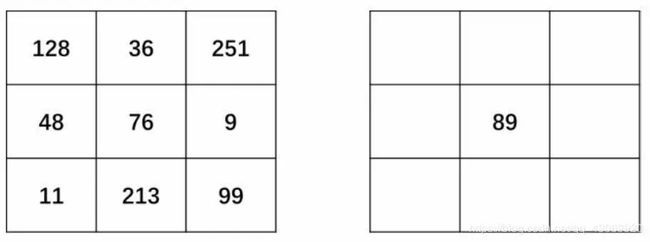
原始的LBP提出后,研究人员不断对其提出了各种改进和优化。
2.2 圆形LBP算子
基本的 LBP算子的最大缺陷在于它只覆盖了一个固定半径范围内的小区域,这显然不能满足不同尺寸和频率纹理的需要。为了适应不同尺度的纹理特征,Ojala等对LBP算子进行了改进,将3×3邻域扩展到任意邻域,并用圆形邻域代替了正方形邻域,改进后的LBP算子允许在半径为R的圆形邻域内有任意多个像素点,从而得到了诸如半径为R的圆形区域内含有P个采样点的LBP算子,圆形邻域可以用(P, R)表示,其中P表示圆形邻域内参与运算的像素点个数,R表示邻域的半径。OpenCV中正是使用圆形LBP算子,下图示意了圆形LBP算子:
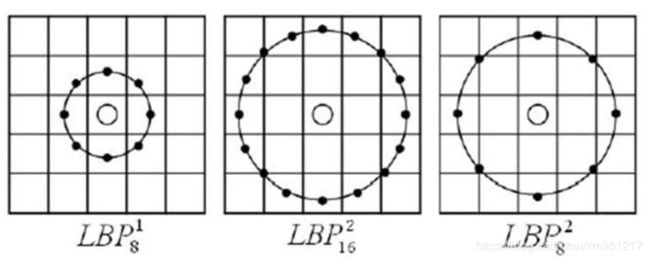
2.3 旋转不变模式
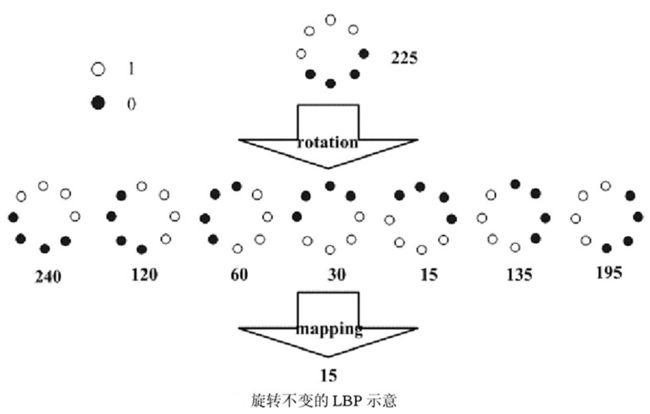
从LBP的定义可以看出,LBP算子是灰度不变的,但却不是旋转不变的,图像的旋转就会得到不同的LBP值。Maenpaa等人又将LBP算子进行了扩展,提出了具有旋转不变性的LBP算子,即不断旋转圆形邻域得到一系列初始定义的LBP值,取其最小值作为该邻域的LBP值。下图给出了求取旋转不变LBP的过程示意图,图中算子下方的数字表示该算子对应的LBP值,图中所示的8种LBP模式,经过旋转不变的处理,最终得到的具有旋转不变性的LBP值为15。也就是说,图中的8种LBP模式对应的旋转不变的LBP码值都是00001111。
2.4 等价模式
一个LBP算子可以产生不同的二进制模式,对于半径为R的圆形区域内含有P个采样点的LBP算子将会产生P2种模式。很显然,随着邻域集内采样点数的增加,二进制模式的种类是急剧增加的。例如:5×5邻域内20个采样点,有2^20=1,048,576种二进制模式。如此多的二值模式无论对于纹理的提取还是对于纹理的识别、分类及信息的存取都是不利的。为了解决二进制模式过多的问题,提高统计性,Ojala提出了采用一种“等价模式”(Uniform Pattern)来对LBP算子的模式种类进行降维。Ojala等认为,在实际图像中,绝大多数LBP模式最多只包含两次从1到0或从0到1的跳变。因此,Ojala将“等价模式”定义为:当某个局部二进制模式所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该局部二进制模式所对应的二进制就成为一个等价模式类。如00000000(0次跳变),00000110(含一次从0到1的跳变和一次1到0的跳变),10001111(先由1跳到0,再由0跳到1,共两次跳变)都是等价模式类。除等价模式类以外的模式都归为另一类,称为混合模式类,例如10010111(共四次跳变)。
通过这样的改进,二进制模式的种类大大减少,模式数量由原来的2^P种减少为P(P-1)+2+1种,其中P表示邻域集内的采样点数,等价模式类包含P(P-1)+2种模式,混合模式类只有1种模式。对于3×3邻域内8个采样点来说,二进制模式由原始的256种减少为59种,这使得特征向量的维数更少,并且可以减少高频噪声带来的影响。
2.5 LBP特征用于检测的原理
显而易见的是,上述提取的LBP算子在每个像素点都可以得到一个LBP“编码”,那么,对一幅图像(记录的是每个像素点的灰度值)提取其原始的LBP算子之后,得到的原始LBP特征依然是“一幅图片”(记录的是每个像素点的LBP值),如图所示:
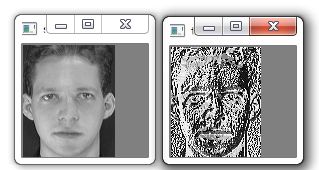
原图对比LBP图
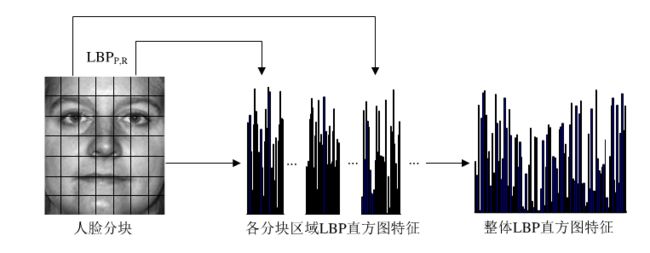
如果将以上得到的LBP图直接用于人脸识别,其实和不提取LBP特征没什么区别,在实际的LBP应用中一般采用LBP特征谱的统计直方图作为特征向量进行分类识别,并且可以将一幅图片划分为若干的子区域,对每个子区域内的每个像素点都提取LBP特征,然后,在每个子区域内建立LBP特征的统计直方图。如此一来,每个子区域,就可以用一个统计直方图来进行描述,整个图片就由若干个统计直方图组成,这样做的好处是在一定范围内减小图像没完全对准而产生的误差,分区的另外一个意义在于我们可以根据不同的子区域给予不同的权重,比如说我们认为中心部分分区的权重大于边缘部分分区的权重,意思就是说中心部分在进行图片匹配识别时的意义更为重大。 例如:一幅100*100像素大小的图片,划分为10*10=100个子区域(可以通过多种方式来划分区域),每个子区域的大小为10*10像素;在每个子区域内的每个像素点,提取其LBP特征,然后,建立统计直方图;这样,这幅图片就有10*10个子区域,也就有了10*10个统计直方图,利用这10*10个统计直方图,就可以描述这幅图片了。之后,我们利用各种相似性度量函数,就可以判断两幅图像之间的相似性了.
综上,LBP被运用于计算机人脸识别领域时,提取出来的人脸特征通常是以LBP直方图向量进行表达的。这个特征向量代表原来的人脸图像,可以用来描述整体图像。提取特征主要步骤如下:
1. 对预处理后的人脸图像进行分块
2. 对分块后的各小块图像区域进行LBP特征提取变换
3. 使用LBP直返图向量作为人脸特征的描述。
3,相关函数介绍
在OpenCV中,可以用函数cv2.face.LBPHFaceRecognizer_create()生成LBPH识别器实例模型,然后应用cv2.face_FaceRecognizer.train()函数完成训练,最后在采用cv2.face_ FaceRecognizer.predict()函数完成人脸识别。
3.1 .LBPHFaceRecognizer_create
该函数的语法格式为:cv2.face.LBPHFaceRecognizer_create( [, radius[, neighbors [,grid_x[, grid_y[, threshold]]]]])其中全部的参数含义如下:radius:半径值,默认值为1。neighbors:邻域点的个数,默认采用8邻域,根据需要可以计算更多的邻域点。grid_x:将LBP特征图像划分为一个个单元格时,每个单元格在水平方向上的像素个数。该参数值默认为8,即将LBP特征图像在行方向上以8个像素为单位分组。grid_y:将LBP特征图像划分为一个个单元格时,每个单元格在垂直方向上的像素个数。该参数值默认为8,即将LBP特征图像在列方向上以8个像素为单位分组。threshold:在预测时所使用的阈值。如果大于该阈值,就认为没有识别到任何目标对象。3.2 cv2.face_FaceRecognizer.train()函数cv2.face_FaceRecognizer.train()对每个参考图像计算LBPH,得到一个向量。每个人脸都是整个向量集中的一个点。该函数的语法格式为:None = cv2.face_FaceRecognizer.train( src, labels )式中各个参数的含义为:src:训练图像,用来学习的人脸图像。labels:标签,人脸图像所对应的标签。该函数没有返回值。3.3 cv2.face_FaceRecognizer.predict()函数cv2.face_FaceRecognizer.predict()对一个待测人脸图像进行判断,寻找与当前图像距离最近的人脸图像。与哪个人脸图像最近,就将当前待测图像标注为其对应的标签。当然,如果待测图像与所有人脸图像的距离都大于函数cv2.face.LBPHFaceRecognizer_ create()中参数threshold所指定的距离值,则认为没有找到对应的结果,即无法识别当前人脸。该函数的语法格式为:label, confidence = cv2.face_FaceRecognizer.predict( src )式中参数与返回值的含义如下。src:需要识别的人脸图像; label:返回的识别结果标签;confidence:返回的置信度评分。置信度评分用来衡量识别结果与原有模型之间的距离。0表示完全匹配。通常情况下,认为小于50的值是可以接受的,如果该值大于80则认为差别较大。代码实现
一,人脸数据收集
此步的目的是为后期的工作收集所需样本。调用计算机的摄像头来录取视频,并保存截图供后期训练。
主要有以下几个注意事项:
1.在运行该程序前,请先创建一个Facedata文件夹并将程序放在此文件夹下。
2.程序运行过程中,会提示输入id,请从0开始输入,即第一个人的脸的数据id为0,第二个人的脸的数据id为1,运行一次可收集一张人脸的训练数据。
3.采集的人脸数量设定为1000,采集时间大约为四分钟。适量增加数量可以提高判定的准确性,但是时间也会相应的增加。经过多次试验,此数值个人建议在700~1200.
具体代码如下:
import cv2
import os
# 笔记本内置摄像头参数为0,如果有其他的摄像头可以调整参数为1,2
cap = cv2.VideoCapture(0)
face_detector = cv2.CascadeClassifier('C:\\Users\\johnnyliu\\Desktop\\task1\\facefiles\\haarcascades\\haarcascade_frontalface_default.xml')#输入用户id:数字,0,1,2....
face_id = input('\n enter user id:')
print('\n Initializing face capture. Look at the camera and wait ...')#目标采集一千张人脸图片,采用变量count来计数
count = 0
while True: # 从摄像头读取图片 ok, img = cap.read() # 转为灰度图片 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 检测人脸 faces = face_detector.detectMultiScale(gray, 1.3, 5) #检测到一张脸,记录脸部位置数据,框出脸部位置,count加一 for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+w), (255, 0, 0)) count += 1 # 保存图像 规定地址,名称,图片格式 cv2.imwrite("C:\\Users\\johnnyliu\\Desktop\\task1\\facefiles\\user" + str(face_id) + '.' + str(count) + '.jpg', gray[y: y + h, x: x + w]) cv2.imshow('image', img) # 保持画面的持续。# 通过esc键可提前退出摄像 k = cv2.waitKey(0) if k == 27: break# 得到1000个样本后退出摄像 elif count >= 1000: break
#销毁窗口,关闭摄像头
cap.release()
cv2.destroyAllWindows()注:cv2.imwrite(filename,img) 即将截取的人脸灰度图gray[y: y + h, x: x + w]保存到facefiles\user里,命名格式为:用户id+图片序号,图片为jpg格式。
二,人脸数据训练
在执行前,需要在data文件夹中创建users子文件夹,用于存放采集的人脸灰度图像。
还需要创建face_trainer文件夹,用于训练好的模型trainer.yml 。
import numpy as np
from PIL import Image
import os
import cv2
__all__ = [cv2]
#采集的照片所在的路径
path = 'C:\\Users\\johnnyliu\\Desktop\\task1\\facefiles\\data\\user'#创建LBPH识别器开始训练
recognizer = cv2.face.LBPHFaceRecognizer_create()#调用cascade分类器来识别图中的人脸
detector = cv2.CascadeClassifier("C:\\Users\\johnnyliu\\Desktop\\task1\\facefiles\\haarcascades\\haarcascade_frontalface_default.xml")#该函数将读取所有的训练图像,从每个图像检测人脸并将返回两个相同大小的列表,分别为脸部样本信息和用户名
def getImagesAndLabels(path): imagePaths = [os.path.join(path, f) for f in os.listdir(path)]
#定义两个列表,里面存放所有 的脸部信息和用户id
faceSamples = [] ids = []#利用for循环,遍历路径中所有的图片 for imagePath in imagePaths:#将一张图片通过convert函数转换为灰度图, # convert it to grayscale#详细解释见批注 PIL_img = Image.open(imagePath).convert('L') #通过pil.image.open()打开后,将image形式转换为array数组,编码格式为uint8 img_numpy = np.array(PIL_img, 'uint8') id = int(os.path.split(imagePath)[-1].split(".")[1])#调用detectMultiScale函数来检测转换后的img的人脸 faces = detector.detectMultiScale(img_numpy)#检测到后标出人脸的信息,并将人脸的矩形框添加到人脸样本的列表中 for (x, y, w, h) in faces: faceSamples.append(img_numpy[y:y + h, x: x + w]) ids.append(id) return faceSamples, ids
print('Training faces. It will take a few seconds. Wait ...')
faces, ids = ImagesAndLabels(path)
recognizer.train(faces, np.array(ids))#训练结束,将训练好的模型保存于以下位置
recognizer.write(r'C:\Users\johnnyliu\Desktop\task1\facefiles\face_trainer\trainer.yml')
print("{0} faces trained. Exiting Program".format(len(np.unique(ids))))注:
1,对于python的不同版本,facerecognizer的语句格式也不一样。
Python2版本中,createLBPHFaceRecognizer。然而,在python版本三中,语句格式变成了LBPHFaceRecognizer_create()。
2,对于recognizer = cv2.face.LBPHFaceRecognizer_create()
代表创建LBPH识别器并开始训练,由于lbph方法对系统要求不高,且训练速度较快,故选择lbph。当然也可以选择Eigen或者Fisher识别器。
3, PIL_img = Image.open(imagePath).convert('L')
PIL的九种不同模式:1,L,P,RGB,RGBA,CMYK,YCbCr,I,F
模式”1” 为二值图像,非黑即白。
模式“L” 为灰色图像,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。
4, img_numpy = np.array(PIL_img, 'uint8')
将灰度图pil_img通过numpy_array转换为数组形式。图像上的位置和数据每个位置都对应矩阵里的一个值。所以每张图片都是一个多维矩阵组成,转化为nunpy数组就是方便通过矩阵运算来对图像进行修改。
5, facesample代表人脸样本,刚开始是一个空列表,后来里面逐渐添加了人脸区域的数组数据。
三,利用新模型进行训练。
import cv2
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('C:\\Users\\johnnyliu\\Desktop\\task1\\facefiles\\face_trainer\\trainer.yml')
cascadePath = "C:\\Users\\johnnyliu\\Desktop\\task1\\facefiles\\haarcascades\\haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath)#加载字体,用于在识别人脸时在屏幕上加上文字。
font = cv2.FONT_HERSHEY_SIMPLEX#设置好与ID号码对应的用户名,如0对应的就是userid=0
idnums = 0
names = ['Allen', 'Bob']
cam = cv2.VideoCapture(0)
minW = 0.1*cam.get(3)
minH = 0.1*cam.get(4)
while True: ret, img = cam.read() gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) faces = faceCascade.detectMultiScale( gray, scaleFactor=1.2, minNeighbors=5, minSize=(int(minW), int(minH)) )#标出人脸区域,并对此区域的人脸进行判断预测,返回两个值,confidence和idnum for (x, y, w, h) in faces: cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2) idnum, confidence = recognizer.predict(gray[y:y+h, x:x+w])#设定一个阈值,判断人脸和模型中的匹配程度, if confidence < 100: idnum = names[idname] confidence = "{0}%".format(round(100 - confidence)) else: id_num = "unknown" confidence = "{0}%".format(round(100 - confidence)) cv2.putText(img, str(id_num), (x+5, y-5), font, 1, (0, 0, 255), 1) cv2.putText(img, str(confidence), (x+5, y+h-5), font, 1, (0, 0, 0), 1) cv2.imshow('camera', img) k = cv2.waitKey(10) if k == 27: break
cam.release()
cv2.destroyAllWindows()检测结果
训练了两个模型,一个是我本人的,另外一个是通过直播的视频所训练的主播的模型。
这里进行人脸识别检测时选定了第二个的模型。
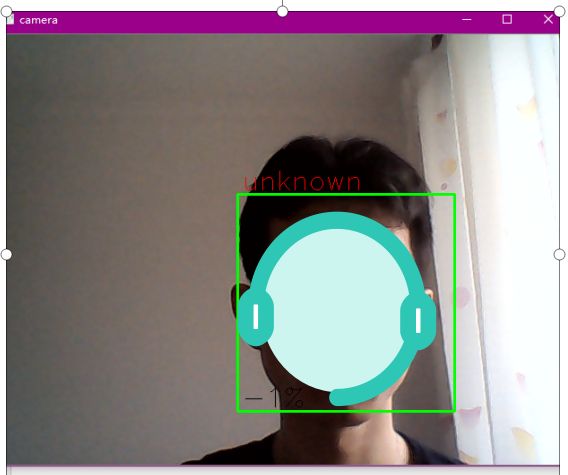
首先是我本人入镜,检测结果为unknown。
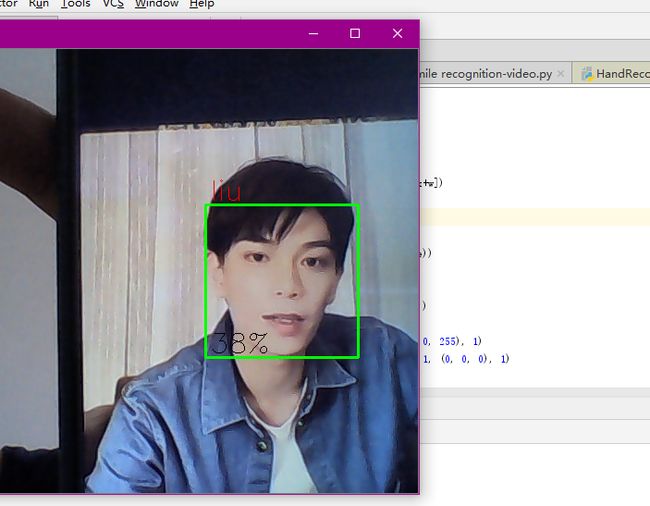
当用手机播放主播的视频时,显示相关度为38%。并将识别人的名字liu打在了屏幕上。
程序漏洞:
此识别也有些许不足,一是采取人脸样本的数量并未测量出一个最佳值。本人试验了多次,当样本过少,或者过多时,都会降低识别的正确率。所以设定一个合适的检测数量十分重要。
另外,本次人脸训练采用的是OpenCV。在识别率上还是有一定的不足,后续可以采用引入dlib来进行训练。
---------------------------------------------------------------------------
YY日记
昨天上午做了酸辣柠檬凤爪,嗯,又是恰柠檬的一天。

不过真的好吃,酸酸辣辣的。

---------------------
下午去了科技馆,有四层

