语音信号特征处理--Fbank\MFCC
目录
-
- 数字信号处理基础
-
- 模拟信号转化为数字信号(ADC)
- 频率混叠
- 奈奎斯特采样定理
- 离散傅里叶变换
- Fbank和MFCC特征提取
-
-
- step1:预加重
- step2:加窗分帧
- step3:DFT
- step4:梅尔滤波器组和对数操作
- 动态特征计算
-
- 总结
- Fbank和MFCC样例代码
代码地址:(6.1号发布)
数字信号处理基础
模拟信号转化为数字信号(ADC)
现实生活中遇到的大多数信号都是连续信号,而计算机只能处理离散信号,因此需要通过采样量化转化为数字信号。
以正弦波为例, x ( t ) = s i n ( 2 π f 0 t ) x(t)=sin(2\pi f_0t) x(t)=sin(2πf0t),其中 f 0 f_0 f0是信号本身的频率,单位Hz。若我们对其每间隔 t s t_s ts秒进行一次采样,并使用一定范围的离散数值表示采样值,则得到采样后信号 x ( n ) = s i n ( 2 π f 0 n t s ) x(n)=sin(2\pi f_0nt_s) x(n)=sin(2πf0nts), t s t_s ts为采样周期, f s = 1 / t s f_s=1/t_s fs=1/ts采样频率, n = 0 , 1... n=0,1... n=0,1...为离散整数序列。
问题:如果给定一个正弦波采样后的序列,可以唯一恢复出一个连续的正弦波吗?
频率混叠
不同频率的正弦波,经采样后,完全有可能出现相同的离散信号,为什么?
x ( n ) = sin ( 2 π f 0 n t s ) = sin ( 2 π f 0 n t s + 2 π m ) = sin ( 2 π ( f 0 + m n t s ) n t s ) \begin{aligned} & x(n)=\sin \left(2 \pi f_{0} n t_{s}\right) \\ =& \sin \left(2 \pi f_{0} n t_{s}+2 \pi m\right) \\ =& \sin \left(2 \pi\left(f_{0}+\frac{m}{n t_{s}}\right) n t_{s}\right) \end{aligned} ==x(n)=sin(2πf0nts)sin(2πf0nts+2πm)sin(2π(f0+ntsm)nts)
如果 m = k n m=kn m=kn,k为整数(一般为常数),因为n为整数,m也是整数,若m=kn满足,则k必须为整数。替换以上公式为:
x ( n ) = sin ( 2 π ( f 0 + k f s ) n t s ) \mathrm{x}(\mathrm{n})=\sin \left(2 \pi\left(\mathrm{f}_{0}+\mathrm{kf}_{\mathrm{s}}\right) \mathrm{nt}_{\mathrm{s}}\right) x(n)=sin(2π(f0+kfs)nts)
从公式可以看出原始频率 f 0 f_0 f0和 f 0 + k f s f_0+kf_s f0+kfs两个信号对应的离散信号是相同的。这种现象是频率混叠,也解释了上述的问题。如何避免频率混叠?
奈奎斯特采样定理
采样频率大于信号中最大频率的两倍, f s / 2 ≥ f m a x f_s / 2 \geq f_{max} fs/2≥fmax,即原始信号的一个周期内,至少要采样两个点,才能有效杜绝频率混叠问题。
问题:对一个采样率为16k的离散信号进行下采样,下采样到8k,为什么需要首先进行低通滤波?
根据奈奎斯特定律,采样率为16k的离散信号中可能存在频率不超过8k的信号,下采样到8k,音频中只允许存在最大频率不超过4kHz的信号,所以需要首先进行低通滤波,过滤掉超过4kHz的信号。
离散傅里叶变换
DFT将时域信号变换到频域,分析信号中频率成分,时域离散且周期的吸纳后可以进行DFT,非周期离散信号需要进行周期延拓。
DFT定义:给定一个长度为N的时域离散信号x(n),对应的离散频域序列X(m)为: X ( m ) = ∑ n = 0 N − 1 x ( n ) e − j 2 π n m / N , m = 0 , 1 , 2 , … N − 1 \mathrm{X}(\mathrm{m})=\sum_{\mathrm{n}=0}^{\mathrm{N}-1} \mathrm{x}(\mathrm{n}) \mathrm{e}^{-\mathrm{j} 2 \pi \mathrm{nm} / \mathrm{N}}, \quad \mathrm{m}=0,1,2, \ldots N-1 X(m)=∑n=0N−1x(n)e−j2πnm/N,m=0,1,2,…N−1。其中, m = 0 , 1 , 2... N − 1 m=0,1,2...N-1 m=0,1,2...N−1为频率索引,X(m)为DFT的第m个输出。
根据欧拉公式,DFT的公式还可以为:
X ( m ) = ∑ n = 0 N − 1 x ( n ) [ cos ( 2 π n m N ) − j sin ( 2 π n m N ) ] \mathrm{X}(\mathrm{m})=\sum_{\mathrm{n}=0}^{\mathrm{N}-1} \mathrm{x}(\mathrm{n})\left[\cos \left(\frac{2 \pi \mathrm{nm}}{\mathrm{N}}\right)-\mathrm{j} \sin \left(\frac{2 \pi \mathrm{nm}}{\mathrm{N}}\right)\right] X(m)=n=0∑N−1x(n)[cos(N2πnm)−jsin(N2πnm)]
DFT本质上是一个线性变换: X ⃗ = F x ⃗ \vec{X}=\boldsymbol{F} \vec{x} X=Fx
[ X ( 0 ) X ( 1 ) X ( 2 ) ⋮ X ( N − 1 ) ] = [ 1 1 ⋯ 1 1 e − j 2 π / N ⋯ e − j 2 π ( N − 1 ) / N 1 e − j 2 π ⋅ 2 / N ⋯ e − j 2 π ⋅ 2 ( N − 1 ) / N ⋮ ⋮ ⋮ ⋮ 1 e − j 2 π ⋅ ( N − 1 ) / N ⋯ e − j 2 π ⋅ ( N − 1 ) ( N − 1 ) / N ] [ x ( 0 ) x ( 1 ) x ( 2 ) ⋮ x ( N − 1 ) ] \left[\begin{array}{c} X(0) \\ X(1) \\ X(2) \\ \vdots \\ X(N-1) \end{array}\right]=\left[\begin{array}{cccc} 1 & 1 & \cdots & 1 \\ 1 & e^{-j 2 \pi / N} & \cdots & e^{-j 2 \pi(N-1) / N} \\ 1 & e^{-j 2 \pi \cdot 2 / N} & \cdots & e^{-j 2 \pi \cdot 2(N-1) / N} \\ \vdots & \vdots & \vdots & \vdots \\ 1 & e^{-j 2 \pi \cdot(N-1) / N} & \cdots & e^{-j 2 \pi \cdot(N-1)(N-1) / N} \end{array}\right]\left[\begin{array}{c} x(0) \\ x(1) \\ x(2) \\ \vdots \\ x(N-1) \end{array}\right] ⎣⎢⎢⎢⎢⎢⎡X(0)X(1)X(2)⋮X(N−1)⎦⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎡111⋮11e−j2π/Ne−j2π⋅2/N⋮e−j2π⋅(N−1)/N⋯⋯⋯⋮⋯1e−j2π(N−1)/Ne−j2π⋅2(N−1)/N⋮e−j2π⋅(N−1)(N−1)/N⎦⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎡x(0)x(1)x(2)⋮x(N−1)⎦⎥⎥⎥⎥⎥⎤
DFT性质:
- 对称性,对于实数信号有, X ( m ) = X ∗ ( N − m ) \mathrm{X}(\mathrm{m})=\mathrm{X}^{*}(\mathrm{~N}-\mathrm{m}) X(m)=X∗( N−m)。
证明:
X ( N − m ) = ∑ n = 0 N − 1 x ( n ) e − j 2 π n ( N − m ) / N \mathrm{X}(\mathrm{N}-\mathrm{m})=\sum_{\mathrm{n}=0}^{\mathrm{N}-1} \mathrm{x}(\mathrm{n}) \mathrm{e}^{-\mathrm{j} 2 \pi \mathrm{n}(\mathrm{N}-\mathrm{m}) / \mathrm{N}} X(N−m)=∑n=0N−1x(n)e−j2πn(N−m)/N
= ∑ n = 0 N − 1 x ( n ) e − j 2 π n N / N e j 2 π n m / N = ∑ n = 0 N − 1 x ( n ) e − j 2 π n e j 2 π n m / N =\sum_{\mathrm{n}=0}^{\mathrm{N}-1} \mathrm{x}(\mathrm{n}) \mathrm{e}^{-\mathrm{j} 2 \pi \mathrm{n} \mathrm{N} / \mathrm{N}} \mathrm{e}^{\mathrm{j} 2 \pi \mathrm{nm} / \mathrm{N}}=\sum_{\mathrm{n}=0}^{\mathrm{N}-1} \mathrm{x}(\mathrm{n}) \mathrm{e}^{-\mathrm{j} 2 \pi \mathrm{n}} \mathrm{e}^{\mathrm{j} 2 \pi \mathrm{nm} / \mathrm{N}} =∑n=0N−1x(n)e−j2πnN/Nej2πnm/N=∑n=0N−1x(n)e−j2πnej2πnm/N
因为 e − j 2 π n = cos ( 2 π n ) − j sin ( 2 π n ) = 1 \mathrm{e}^{-\mathrm{j} 2 \pi \mathrm{n}}=\cos (2 \pi \mathrm{n})-\mathrm{j} \sin (2 \pi \mathrm{n})=1 e−j2πn=cos(2πn)−jsin(2πn)=1
故X ( N − m ) = ∑ n = 0 N − 1 x ( n ) e j 2 π n m / N = X ∗ ( m ) (\mathrm{N}-\mathrm{m})=\sum_{\mathrm{n}=0}^{\mathrm{N}-1} \mathrm{x}(\mathrm{n}) \mathrm{e}^{\mathrm{j} 2 \pi \mathrm{nm} / \mathrm{N}}=\mathrm{X}^{*}(\mathrm{~m}) (N−m)=∑n=0N−1x(n)ej2πnm/N=X∗( m)
这个性质很重要,DFT之后的离散频率序列的幅度具有对称性,因此在进行N点DFT之后,只需要保留前N/2+1个点。语音信号特征提取时,一般使用512点DFT,由于对称性,我们只需保留前257个有效点。
-
X(m)实际上表示的是"谱密度",通俗的讲即单位带宽上有多少信号存在。如果对一个幅度为A实正弦波进行N点DFT,则DFT之后,对应频率上的幅度M和A之间的关系是: M = A 2 N = A N 2 M=\frac{A}{\frac{2}{N}}=\frac{A N}{2} M=N2A=2AN。
-
DFT的线性。如果 x s u m ( n ) = x 1 ( n ) + x 2 ( n ) \mathrm{x}_{\mathrm{sum}}(\mathrm{n})=\mathrm{x}_{1}(\mathrm{n})+\mathrm{x}_{2}(\mathrm{n}) xsum(n)=x1(n)+x2(n), 则对应的频域上有: X s u m ( m ) = X 1 ( m ) + X 2 ( m ) \mathrm{X}_{\mathrm{sum}}(\mathrm{m})=\mathrm{X}_{1}(\mathrm{~m})+\mathrm{X}_{2}(\mathrm{~m}) Xsum(m)=X1( m)+X2( m)
-
时移性。对x(n)左移k个采样点, 得至 1 x shift ( n ) = x ( n − k ) 1 \mathrm{x}_{\text {shift }}(\mathrm{n})=\mathrm{x}(\mathrm{n}-\mathrm{k}) 1xshift (n)=x(n−k), 对 x shift ( n ) \mathrm{x}_{\text {shift }}(\mathrm{n}) xshift (n) 进行DFT,有 X shift ( m ) = e j 2 π k m N X ( m ) \mathrm{X}_{\text {shift }}(\mathrm{m})=\mathrm{e}^{\frac{\mathrm{j} 2 \pi \mathrm{km}}{\mathrm{N}}} \mathrm{X}(\mathrm{m}) Xshift (m)=eNj2πkmX(m)。
频率分辨率: f s / N f_s / N fs/N,表示最小的频率间隔。当N越大时,频率分辨率越高,在频域上,第m个点表示的分析频率为: f analysis ( m ) = m N f s \mathrm{f}_{\text {analysis }}(\mathrm{m})=\frac{\mathrm{m}}{\mathrm{N}} \mathrm{f}_{\mathrm{s}} fanalysis (m)=Nmfs。从这个角度,我们可以理解为X(m)的幅值体现了原信号中频率成分为 m N f s \frac{\mathrm{m}}{\mathrm{N}} \mathrm{f}_{\mathrm{s}} Nmfs的信号强度。
为了提高DFT频率轴的分辨率,而不影响原始信号的频率成分。我们可以将时域长度为N的信号补0,增加信号的长度,从而提高频率轴的分辨率。如,在语音特征提取阶段,对于16k采样率的信号,一帧语音信号长度为400个采样点,为了进行512的FFT,通常将400个点补0,得到512个采样点,最后只需要前257个点。
快速傅里叶变换,基本思想是把原始信号的N点序列,以此分解成一系列的短序列。充分利用DFT计算式中指数因子具有的对称性和周期性,进而求出这些短序列相应的DFT并进行适当组合,达到删除重复计算,减少乘法运算和简化结构的目的。
Fbank和MFCC特征提取
提取流程:

Fbank和MFCC特征目前仍是主要使用的特征,虽然有些工作尝试在语音识别任务上对波形建模,但是效果并没有超过基于频域的特征。
step1:预加重
-
为什么需要预加重?
提高信号高频部分的能量,高频信号在传递过程中,衰减较快,但是高频部分又蕴含很多对语音识别有利的特征。
预加重滤波器是一个一阶高通滤波器,给定时域输入信号 x [ n ] x[n] x[n],预加重之后的信号为: y [ n ] = x [ n ] − α x [ n − 1 ] y[n]=x[n]-\alpha x[n-1] y[n]=x[n]−αx[n−1],其中 0.9 ≤ α ≤ 1.0 0.9\leq \alpha \leq 1.0 0.9≤α≤1.0。
通俗解释:如果信号x是低频信号(变化缓慢),那么 x [ n ] x[n] x[n]和 x [ n − 1 ] x[n-1] x[n−1]的值应该很接近,当 α \alpha α接近1的时候, x [ n ] − α x [ n − 1 ] x[n]-\alpha x[n-1] x[n]−αx[n−1]接近0,此信号的幅度将大大抑制;如果信号x是高频信号(变化很快),那么 x [ n ] x[n] x[n]和 x [ n − 1 ] x[n-1] x[n−1]的值相差很大, x [ n ] − α x [ n − 1 ] x[n]-\alpha x[n-1] x[n]−αx[n−1]的值不会趋近0,此信号的幅度还能保持。
step2:加窗分帧
- 为什么需要加窗分帧?
- 语音信号是非平稳信号,其统计属性是随着时间变化的,以汉语为例,一句话中包含很多声母和韵母,不同的拼音,发音的特点也是明显不一样。
- 语音信号又具有短时平稳的特性,比如一个声母或者韵母,往往只会持续几十到几百毫秒,在一个发音单元里,语音信号表现出明显的稳定性,规律性。
- 在进行语音识别的时候,对于一句话,识别的过程是以较小的发音单元(音素,字,字节)为单位进行识别,因此采用滑动窗口提取短时片段。
一般对于采样率为16kHz的信号,帧长、帧移一般为25ms、10ms。
分帧的过程,在时域上,即用一个窗函数和原始信号进行相乘, y [ n ] = w [ n ] x [ n ] y[n]=w[n]x[n] y[n]=w[n]x[n],常见的窗函数有矩形窗、汉明窗等。
问题:为什么不直接使用矩形窗?
加窗的过程实际上是在时域上将信号截断,窗函数与信号在时域相乘,就等于对应的频域表示进行卷积,矩形窗主瓣窄,但是旁瓣较大,将其与原始信号的频域进行卷积会导致频率泄露。
step3:DFT
将上一步分帧后的语音帧,由时域变换到频域,取DFT系数的模,得到谱特征。
过程:
-
加窗分帧
-
将每一帧信号进行DFT(FFT),如第t帧,DFT系数为 X t ( m ) X_t(m) Xt(m),m=0,1,…N
-
将每一帧DFT的系数按照时间顺序排列,得到一个矩阵 Y ∈ C T ∗ N , Y \in C^{T * N}, \quad Y∈CT∗N, 且 Y [ t , m ] = X t ( m ) Y[\mathrm{t}, \mathrm{m}]={X}_{\mathrm{t}}(\mathrm{m}) Y[t,m]=Xt(m)
-
语谱图是一个三维图,横轴表示时间(t),纵轴表示频率,颜色的深浅表示当前频点上幅度的大小。
step4:梅尔滤波器组和对数操作
-
DFT得到了每个频带上信号的能量,但是人耳对频率的感知不是等间隔的,近似于对数函数。
-
将线性频率转化为梅尔频率,梅尔频率和线性频率的转换关系: mel ( f ) = 2595 log 10 ( 1 + f 700 ) \operatorname{mel}(\mathrm{f})=2595 \log _{10}\left(1+\frac{\mathrm{f}}{700}\right) mel(f)=2595log10(1+700f)
-
梅尔三角滤波器:根据起始频率、中间频率和截止频率,确定各滤波器系数:
f i l t e r b a n k m ( k ) = { k − f ( m − 1 ) f ( m ) − f ( m − 1 ) , f ( m − 1 ) ≤ k < f ( m ) f ( m + 1 ) − k f ( m + 1 ) − f ( m ) , f ( m ) < k ≤ f ( m + 1 ) filterbank _{m}(k)=\left\{\begin{array}{l} \frac{k-f(m-1)}{f(m)-f(m-1)}, f(m-1) \leq k

梅尔滤波器组设计:
-
确定滤波器个数P
-
根据采样率 f s f_s fs,DFT点数N,滤波器个数P,在梅尔域上等间隔的产生每个滤波器的起始频率、中间频率和截止频率,注意,上一个滤波器的中间频率为下一个滤波器的起始频率。
-
将梅尔域上每个三角滤波器的起始、中间和截止频率转换为线性频率域,并对DFT之后的谱特征进行滤波,得到P个滤波器组能量,进行log操作,得到Fbank特征。
MFCC特征在Fbank特征的基础上继续进行IDFT变换等操作。
倒谱分析
频域信号可以分解为谱包络和谱细节的乘积,不同因素的谱包络和共振峰具有区分性。 X [ m ] = H [ m ] E [ m ] X[m]=H[m]E[m] X[m]=H[m]E[m]。
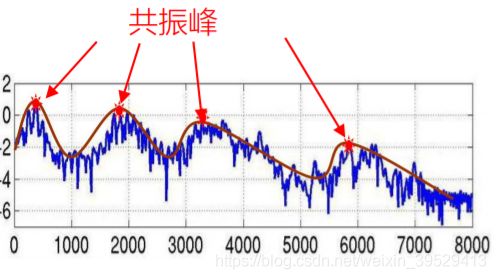

步骤:
-
∣ X [ m ] ∣ = ∣ H [ m ] ∣ ∣ E [ m ] |X[m]| = |H[m]||E[m] ∣X[m]∣=∣H[m]∣∣E[m]
-
l o g ∣ X [ m ] ∣ = l o g ∣ H [ m ] ∣ + l o g ∣ E [ m ] ∣ log|X[m]| = log|H[m]| + log|E[m]| log∣X[m]∣=log∣H[m]∣+log∣E[m]∣
-
两边进行IDFT(此处为DCT变换)
-
IDFT之后的第1~K个点,为k维MFCC特征, c [ k ] = ∑ m = 0 N − 1 ( log ∣ X [ m ] ∣ ) e j 2 π m k / N c[k]=\sum_{m=0}^{N-1}(\log |X[m]|) e^{j 2 \pi m k / N} c[k]=∑m=0N−1(log∣X[m]∣)ej2πmk/N。
取log有两个目的:1. 人耳对信号感知是近似对数的;2. 对数使特征对输入信号的扰动不敏感。
动态特征计算
- 一阶差分,类比速度:
Δ ( t ) = c ( t + 1 ) − c ( t − 1 ) 2 \Delta(\mathrm{t})=\frac{\mathrm{c}(\mathrm{t}+1)-\mathrm{c}(\mathrm{t}-1)}{2} Δ(t)=2c(t+1)−c(t−1)
- 二阶差分,类比加速度:
Δ Δ ( t ) = Δ ( t + 1 ) − Δ ( t − 1 ) 2 \Delta \Delta(\mathrm{t})=\frac{\Delta(\mathrm{t}+1)-\Delta(\mathrm{t}-1)}{2} ΔΔ(t)=2Δ(t+1)−Δ(t−1)
- 能量计算: e = ∑ x 2 [ n ] \mathrm{e}=\sum \mathrm{x}^{2}[\mathrm{n}] e=∑x2[n]
总结
MFCC一般常用39维:
- 12维原始MFCC
- 12维 Δ \Delta Δ
- 12维 Δ Δ \Delta \Delta ΔΔ
- 1维能量
- 1维能量 Δ e \Delta_e Δe
- 1维能量 Δ Δ e \Delta \Delta_e ΔΔe
MFCC特征一般用于GMM训练,各维度之间相关性小,Fbank特征一般用于DNN训练,端到端语音识别系统中多数使用Fbank特征。
Fbank和MFCC样例代码
Fbank特征提取:
-
确定滤波器组作用的最高频率以及最低频率
-
根据滤波器数量,确定每一个滤波器中心频率大的值
-
将滤波器组中心频率对应的梅尔刻度转化为赫兹刻度
公式: mel ( f ) = 2595 log 10 ( 1 + f 700 ) \operatorname{mel}(f)=2595 \log _{10}\left(1+\frac{f}{700}\right) mel(f)=2595log10(1+700f) <-> f ( m e l ) = 700 ( 1 0 m e l 2595 − 1 ) f(m e l)=700\left(10^{\frac{m e l}{2595}}-1\right) f(mel)=700(102595mel−1)
# step1: 计算梅尔刻度上的中心频率
low_mel_freq = 0
high_mel_freq = 2595 * np.log10(1 + fs / 2.0 / 700)
mel_points = np.linspace(low_mel_freq, high_mel_freq, num_filter + 2)
# step2:获得对应FFT单元的中心频率
freq_points = (700 * (np.power(10., (mel_points / 2595)) - 1)) # Hz刻度
-
将频率与DFT点数对应
-
初始化梅尔滤波器维一个Nxnum_filter的零系数矩阵
filter_edge = np.floor(freq_points * (fft_len + 1) / fs) # 对应到FFT的点数
feats=np.zeros((spectrum.shape[1], num_filter)) # 初始化
-
计算每一个梅尔滤波器的系数:
-
计算每一个滤波器的起始、中心、截止频率
-
计算每一个滤波器中每个频率点所对应的系数
公式:
-
H i ( j ) = { f j − f ( i − 1 ) f ( i ) − f ( i − 1 ) , f ( i − 1 ) ≤ f j < f ( i ) f ( i + 1 ) − f j f ( i + 1 ) − f ( i ) , f ( i ) < f j ≤ f ( i + 1 ) H_{i}(j)=\left\{\begin{array}{l}\frac{f_{j}-f(i-1)}{f(i)-f(i-1)}, f(i-1) \leq f_{j}
for m in range(1, 1 + num_filter):
# 计算每一个滤波器的起始、中心、截止频率
f_left = int(filter_edge[m - 1])
f_center = int(filter_edge[m])
f_right = int(filter_edge[m + 1])
# 计算每一个滤波器中每个频率点所对应的系数
for k in range(f_left, f_center):
feats[k, m - 1] = (k - f_left) / (f_center - f_left)
for k in range(f_center, f_right):
feats[k, m - 1] = (f_right - k) / (f_right - f_center)
- 计算得到Fbank特征:滤波器组的系数和频谱进行加权求和,并对结果取对数
feats = np.dot(spectrum, feats)
feats = np.where(feats == 0, np.finfo(float).eps, feats)
feats = 20 * np.log10(feats)
MFCC特征提取
对每帧Fbank求DCT变化得到MFCC:
m f c c [ k , n ] = ∑ i = 0 n u m − f i l t e r − 1 X [ k , i ] cos ( π n ( 2 i − 1 ) 2 × n u m − f i l t e r ) m f c c[k, n]=\sum_{i=0}^{n u m_{-} f i l t e r-1} X[k, i] \cos \left(\frac{\pi n(2 i-1)}{2 \times n u m_{-} f i l t e r}\right) mfcc[k,n]=i=0∑num−filter−1X[k,i]cos(2×num−filterπn(2i−1))
m f c c [ k , n ] m f c c[k, n] mfcc[k,n]: mfcc第k帧第n个值, X [ k , i ] X[k, i] X[k,i]: Fbank第k帧第i个值。
# from scipy.fftpack import dct
feats = dct(fbank, type=2, axis=1, norm='ortho')[:, 1:(num_mfcc + 1)]