Redis学习记录2(消息队列,主从复制,哨兵,集群)
相关面试题:去https://blog.csdn.net/u010682330/article/details/81043419看看
Redis 发布订阅
关注频道
subscribe channal [channal1] [channal2]
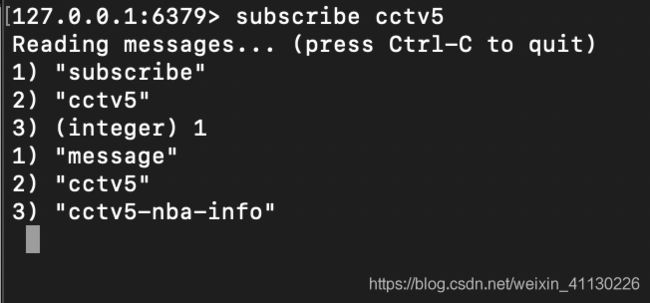
发送消息
publish channal msg

应用场景
构建实时消息系统,比如普通的即时聊天等功能
将redis发布订阅模式用做消息队列和rabbitmq的区别:
可靠性
redis :没有相应的机制保证消息的可靠消费,如果发布者发布一条消息,而没有对应的订阅者的话,这条消息将丢失,不会存在内存中;
rabbitmq:具有消息消费确认机制,如果发布一条消息,还没有消费者消费该队列,那么这条消息将一直存放在队列中,直到有消费者消费了该条消息。
但是redis比rabbitMQ快一些,因为redis存在内存中
Redis 持久化

在平时使用时应尽量主动设置,更新key的expire时间,主动剔除不活跃的旧数据,有助于提升查询性能。
redis 因为存在内存中,高效,但是断电就会丢失数据
RDB
是redis默认的持久化机制
相当于一种快照的状态,就是讲内存中的数据已快照的方式写入到二进制文件中,默认的文件名为dump.rdb
优点:
保存数据极快,还原数据极快
适用于灾难备份
缺点
小内存机器不适合使用,RDB机制符合要求就会照快照,RDB会占用很大一部分内存来照快照。

AOF
由于快照方法是在一定间隔时间做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。你每次做一次写函数,redis都会通过write函数追加到文件中,默认是appendonly.aof。当redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个函数库的内容
缺点
aof带来了一个问题,持久化文件会越来越大,例如我们用incr 命令100次,文件中保存了所有的100条命令,其中99条是没用的。占硬盘
rdb 在制定时间间隔内,将内存中的数据通过快照存入磁盘,数据恢复的时候可以直接读取文件,此时redis会重新开一个线程,主线程还可以读写
redis aof只保存修改数据库的命令,默认是不开启的,appendonly.aof纯文本文件
配置项:
appdendfsync:
no:每隔30秒一次,不安全但是很快
always:每次写入都记录,很安全但是慢一些
everysec:每秒一次,均衡,默认的
auto_aof_write_min_size:允许重写的最小aof文件大小,默认64m,如果aof文件大于64M,自动开始重写,去掉无关的记录,自动开始重写
aof文件中记录的是set $2 key valuer
aof可以和rdb一起用,重启redis时默认先读aof文件
redis的aof太大如何优化
执行BGREWRITEAOF命令对redis的AOF进行重写
AOF重写:
(1) 随着AOF文件越来越大,里面会有大部分是重复命令或者可以合并的命令(100次incr = set key 100)
(2) 重写的好处:减少AOF日志尺寸,减少内存占用,加快数据库恢复时间。
实时同步
对强一致性比较高的,应采用实时同步方案,即查询缓存查询不到再从db中查询,保存到缓存,更新缓存是,先更新数据库,再将缓存设置过期。建议不要去更新缓存内容
如果数据修改了,缓存也要修改或者让缓存key消失


主从复制
主也叫master,主要负责修改,从也叫slave,主要负责读,当在master上写了以后,他会自动发给slave,所以slave和master的数据是一样的,所以slave也可以看做是master的备份,
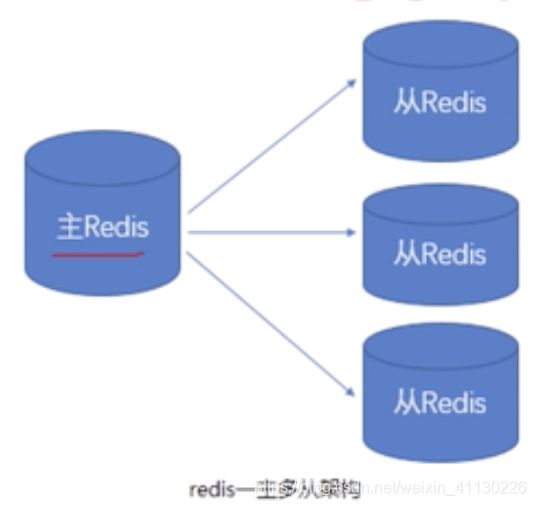
通过修改配置文件来实现:
修改端口号(1025-65535)
导入原来的配置文件,改为后台,端口号,改pidfile(linux 下存储进程id的文件),logfile(日志) dbfilename 二进制数据文件
master配置: slave多配置一行:slave of master的ip+端口号(127.0.0.1 6380)
看主从信息,和集群的一样,info replication

slave 写的时候会提醒你readonly,
master挂掉了,需要冷处理:将一个slave提为主,其他从服务于主
命令:
slaveof no one 将一台升为master
另外的从服务器 slaveof 新主的ip+ 端口号
挂掉的主修好了再启动去当新的master的slave。
哨兵 sentinel
可以自动化的处理redis故障,它不接受用户的数据请求,只是作为其他redis服务器的监控程序
sentinel主要任务有三:
监控:不断检查master和slave 是否正常工作
提醒:如果有redis故障了,可以提醒管理员或者其他程序
自动故障转移:刚才手工处理的那一套,他可以自己做
sentinel至少有三个,而且是奇数个,而且不能因为一个sentinel挂了,其他的都挂了,所以是独立运行的,但是又相互通信,交换监控的信息,哨兵们都监控master,通过master来访问slave,监控采用心跳机制,每隔一定时间(1s),向redis发送一个ping命令,正常redis会返回一个pong,一个哨兵向redis发命令没有回应,他就认为这个redis挂了,他就会投一票,所有的哨兵少数服从多数所以哨兵个数一定是奇数个,一旦满足这个条件,就开始处理故障,先把这个master挂掉,然后再去让一个slave当主,其他slave服务于新master。
哨兵的配置文件是sentinel.conf ,src 下的redis-sentinel就是哨兵的应用

修改端口号,和sentinel monitor mymaster 127.0.0.1 6382 2(2表示票数超过两票就开始故障处理)前台启动
将master关掉,可以看到哨兵们选出了新的master 6384

再重启动6382的话,可以看到哨兵们自动的将它设为6384的slave
高可用
通常描述一个系统经过专门的设计,从而减少停工时间,一直都能用
高并发
保证系统能够同时并行处理很多请求
常用指标 有
响应时间,系统处理一个http请求需要200ms,200ms就是系统响应时间
吞吐量,单位时间内处理的请求数量
**每秒查询率QFS,**每秒响应请求数
并发用户数同时承载正常使用系统功能的用户数量
提高系统并发能力的方式,垂直扩展,水平扩展
垂直扩展:提升单机的处理能力
水平扩展 :只要增加服务器数量。
集群
为什么要集群 redis-cluster?
为了在大流量访问下提供稳定的业务,集群化是存储的必然形态
未来的发展趋势肯定是云计算和大数据的紧密结合
只有分布式架构能满足需求
redis 集群的搭建方案
1twitter 开发的twemproxy
2豌豆荚开发的codis
3 redis官方的redis-cluster
至少需要3个Master +3个Slave才能建立集群,无中心结构,每个节点保存自己的数据和整个集群状态,自己没有的数据去访问别人,每个节点都和其他所有节点连接,没有一个老大,任何一个挂掉了,都可以继续运行。
redis -cluster集群特点
1所有的redis节点彼此互联(ping-pong机制)内部使用二进制协议优化传输速度和带宽。
2节点的fail是通过集群中超过半数的节点检测失效时才生效。不超过半数都正常使用
3客户端直接和节点相连,没有代理proxy,客户端也不需要连接所有节点,只连接一个即可,如果连接的那个没有自己需要的数据,这个节点就会去连接其他节点访问数据。
4redis-cluster吧所有的物理节点映射到[0-16383]slot上,不一定是平均分配,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。cluster负责维护。
5 redis集群预分配好16384个哈希槽,当需要在redis 集群中放置一个key-value对时,redis先对key使用crc16算法算出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0-16383之间的哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同节点。
容错性
指应用程序或硬件从发生的错误中恢复的能力
redis-cluster 投票容错
投票过程是集群中所有的master参入,如果半数以上的master节点与另一个master节点通信超时,就认为这个master节点挂掉了。

什么时候整个集群不可用
如果集群任意master挂掉,且当前master没有slave,集群进入fail状态,也可以理解为集群的slot映射[0-16383]不完整时进入fail状态,(因为每个master都负责0-16383的一部分映射,你挂了,又没有slave,这一部分都访问不了了,就fail),或者集群超过一半的master挂掉,无论是否有slave,集群都进入fail状态。
redis-cluster节点分配
官方推荐,三个主节点分别是a,b,c,他们可以是一台机器的三个端口,也可以是三台不同的服务器,采用哈希槽hash-slot的方式来分配16384个slot的话,
a :0-5460,5461个
b :5461-10922 5462个
c :10923-16383 5461个 ,一共16384个
如果新增一个d,从abc各个节点前面拿一个
a:1365-5460,4096个
b:6827-10922 ,4096个
c:12288-16383, 4096个
d:0-1364,5461-6826,10923-12287,4096个
redis-cluster 搭建
至少应该有奇数个节点,至少需要3台主机,为了避免一个主机挂掉而没有slave节点而导致整个集群fail,每个至少有一个备份节点,所以至少需要6个机器
真集群:6个集群,每台机器的端口都是6379
假集群:一台服务器6个reids服务,端口号不一致
mac环境下假集群搭建
1 sudo mkdir /usr/local/redis_cluster
2创建6个文件夹在redis_cluster下
然后将etc/redis.conf 拷贝到7001,命令老是失败,我手动去finder中copy的
修改redis.conf
sudo vim redis.conf
将bind ip注释掉,要不他只允许那个ip访问
![]()
将protected-mode 改为no
端口号改为7001
daemonize yes 后台运行
pidfile 改掉端口号,默认配置文件
cluster-enabled yes 启动集群
cluster-config-file nodes-7001.conf
再将redis下的src复制到7001-7006
cp -r ./src /usr/loacl/redis_cluster/7001
启动6个
老是失败,难受
/usr/local/redis_cluster/7001/src/redis-server /usr/local/redis_cluster/7001/redis.conf
/usr/local/redis_cluster/7002/src/redis-server /usr/local/redis_cluster/7002/redis.conf
/usr/local/redis_cluster/7003/src/redis-server /usr/local/redis_cluster/7003/redis.conf
/usr/local/redis_cluster/7004/src/redis-server /usr/local/redis_cluster/7004/redis.conf
/usr/local/redis_cluster/7005/src/redis-server /usr/local/redis_cluster/7005/redis.conf
/usr/local/redis_cluster/7006/src/redis-server /usr/local/redis_cluster/7006/redis.conf
ps -ef |grep redis
查看redis的启动情况
brew update
brew install ruby
sudo gem install redis
将rddis-trib.rb复制到bin中
cp /usr/local/redis-5.0.5/src/rddis-trib.rb /usr/local/bin
在 redis-trib.rb 文件所在目录执行命令:
./redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
不用管哪个是master,那个是slave,redis的内部算法帮你搞定
info replication 看看集群信息,7001是master节点,他的slave节点是7004
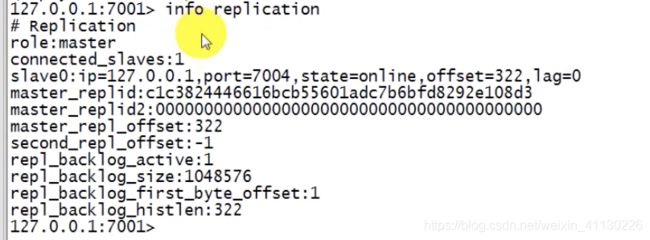
cluster node 查看所有节点信息

最前面那一串就是一个redis节点的节点id,可以看到7001的slave节点id==7004的节点id
所有7004就是7001的slave节点,这个节点id是唯一的
可以看到name这个key对应的hash slot为5798,存在了7002下

可以看到7002下已经有了这个key

看看7002的slave节点7005有没有这个值,应该是有的,可以看到7005节点也是有的,而且查询的时候自动跳到7002上了。说明主节点是做增删改,从节点是查询用的
