多领域多轮问答调研报告3
多领域多轮问答调研报告3
目录
-
- 多领域多轮问答调研报告3
- 一、相关背景
-
- 1.1. 单领域
- 1.2. 多领域
-
- 1.2.1 综述
- 1.2.2 多领域DST方法与挑战
- 1.3. 数据集
-
- 1.3.1. 技术综述
- 1.3.2.MultiWOZ
- 1.3.3.SGD
- 1.4 评价指标
-
- 1.4.1 传统指标
- 1.4.2 多领域DST指标
- 二、模式引导范式(Schema-Guided)
-
- 2.1 背景
- 2.2 模式引导范式
- 三、运行在MultiWOZ上的业内模型
-
- 3.1 综述
- 3.2 fixed-vocabulary-based DST
- 3.3 open-vocabulary-based DST
- 3.4 各模型的论文纵览
- 3.5 DS-DST
- 3.6 SOM-DST
- 四、前景分析
- 附 录
-
- A.ConvLab
- B.Models
一、相关背景
1.1. 单领域
所谓的多领域,是对传统的单领域而言的。
单领域,或者说限定域面向任务/目标型的问答机器人,在学术和工业界目前已经取得了极大的发展,其基本思路是以完成特定任务为目标,任务的完成要经历多轮对话。任务型对话系统可以看做多步决策求取reward(对话目标完成情况)最大化的问题,即强化学习(具体地,策略学习)问题。
这里用户输入或系统响应的语义表示称为动作(action),用户输入和历史对话信息称为对话状态(state),以完成任务为目标。其核心组建是对话状态跟踪(DST,dialogue state tracking),用于在对话进行时识别用户的目标和请求。对话状态跟踪(DST)是任务型问答的核心组件,用于在对话的每一轮估计用户的goal或者request。对话中出现的动作被抽象为意图(intent)+槽位(slot)的表示结构,意图就是问答系统支持的相对独立的模糊目标,槽位相当于数据表中的列(属性)或知识库中的实体,通过槽位解析和填充来逐渐具体化用户的意图,这就是所谓的结构化语义表示。传统的单领域DST中,对话状态被表示为本体中存在的每个槽位的所有可能值上的分布。在上述逻辑下,核心的工作就是为问答机器人设计合适的意图和槽位的模式(Schema)。对于传统的单领域问答而言,模式的设计相对简易,因为意图和槽位都是针对服务(或API)深度定制的。
1.2. 多领域
1.2.1 综述
但是,随着问答服务“体量”的日益增长,一些大型的问答机器人(比如Google Assistant)不得不面临跨领域服务的问题。这些问答系统需要支持种类不断增多的大量服务,把跨领域的大量服务集成在一起,这就是所谓的多领域问答。一个性能优良的多领域问答模型,首先,应能够支持多种服务(称为DST的复杂性挑战);其次,能够尽可能地简化新服务的追加整合的过程,以降低维护的工作量(称为DST的可扩展性挑战)。
在多领域问答系统中,一个完整的对话可能涉及一个或多个领域,系统要识别并实现用户发出的前后相继、彼此制约的多个意图(intent),解析来自多种服务的槽位。一个简单的例子是,用户计划在看完电影后在电影院附近预订一个餐厅,这里就包含了两个领域(Movie和Rrestaurant)的三种意图(book_movie,find_restaurant,reserve_restaurant),而Movie领域中的时间和地点槽位值需要在用户意图切换中以某种方式转交给Rrestaurant领域的相关槽位。把一系列待实现的意图称为“场景”(scenario),一次完整的对话就是完成一种场景。
为达到这个目的,有很多的挑战需要解决,首先是数据集的缺乏,其次是设计模式的改进。从数据层面上讲,大型的跨服务的问答机器人所面对的规模和复杂性,呼唤着我们制作体量上和结构化设计上能与其相匹配的合适数据集,对此,目前已经产生了两个重要的多领域多服务问答数据集——MultiWOZ,以及SGD,其中MultiWOZ上已经吸引了很多研究人员来挑战它们的问答模型。从设计模式上讲,传统的对话状态跟踪被扩展到本体(ontology)更大的多领域,即多领域对话状态跟踪(multi-domain dialogue state tracking),或者多领域任务完成型跟踪(Multi-Domain Task-Completion Track)。这一任务需要开发人员模式上的创新。
经过调研,业内研究团队在MultiWOZ数据集上的DST应用是较多的,而SGD上的则较少。MultiWOZ数据集第一次把对话状态的层次化结构(hierarchical structure)表示成了domain, slot, value的三层形式,使任务型问答迈向更真实的跨领域场景。但是,潜在的问题是,目前并不存在可用于处理MultiWOZ数据集的统一方式,包括测试集的处理和性能评价过程,毕竟MultiWOZ本身还是一个正在被不断更新、维护的新生事物。比如,有很多团队就把MultiWOZ的7个领域砍掉了2个(Police和hospital),然后仅在5个领域进行模型设计和训练。
显然,由于用户在对话过程会一次或多次地发生领域切换(domain transition),所以领域需要和槽值一起进行嵌入编码,与context联合输入训练。在多领域DST,对话状态state被表示为< domain, slot, value >形式的三元组,相当于两个pair。前面的“领域-槽位”对表征当前对话回合的active domain or intent,而后面的“槽-值”对代表了requested slots的values。DST模块既需要跟踪slot-value pairs,还需要跟踪slot-value pairs属于哪一个domain。在多领域问答的研究早期,研究团体基于传统的slot-level的思想,把领域名称和槽位名称合并看做combined slot,从而能够继承传统的slot-value pairs体系来考虑跨领域问答的挑战。此时,多领域挑战可以看作是rich-set of slot types的问题,即如何在本体中存在的预定义槽位数较多的情况下提高DST的效率的问题。
一个多领域对话状态跟踪的例子:
1.2.2 多领域DST方法与挑战
多领域DST可以大致分成两大类:fixed-vocabulary方法,与open-vocabulary方法。fixed-vocabulary方法是传统的单领域任务型问答中的方法,基本思想是预定义一个所以可能的槽值的本体(ontology of possible slot values),在这个本体上运行状态跟踪机制,优点是让系统流畅地预测那些未出现在给定对话历史中的槽值,缺陷是死板,必须在训练阶段为每一个领域定义潜在的槽值大列表,代表模型有HJST,FJST,SUMBT等。open-vocabulary方法最初的思想来自SpanPtr,目的是在缺失预定义本体的情况下实现状态跟踪,并处理未知的槽值。这种方法的基本思想是基于每轮的状态(源序列)派生候选集,能从对话历史中灵活地抽取或生成槽值,但是要努力预测出对话历史中未出现的槽值。代表模型TRADE、DSTreader、COMER等。当然也有一些模型结合了上面两种方式,例如DS-DST(Dual Strategy DST)、HyST,SpanPtr-New。
此外,在单领域中,(slot, value)的解析可以在一轮内完整,但是在多领域中,完整解析(domain, slot, value)三元组可能需要跨越多轮,这就引入turns交际的问题(multi-turn mapping problem)。TRADE对此的解决方法有context-enhanced slot gate和copy mechanism。
多领域DST的另一个挑战是如何跨领域知识共享(share tracking knowledge across domains),相关的别名有Zero/Few-Shot and Continual Learning。因为不同的领域里的槽位的values是可以共享的,解决这个挑战,有助于应对ontology中新value或新domain的追加这一问题。
应该说,多领域问答方面的研究越来越受到重视,学术界为此开发了一个叫做ConvLab的多领域对话系统平台,以帮助开发者方便地运行问答模型运行和测试性能,鼓励研究人员在此领域设计更多的问答模型。
1.3. 数据集
1.3.1. 技术综述
问答系统毕竟是数据密集型的。为了解决对话样本语料库问题,学术界大体上有两种数据集的制作思想:WOZ型,机器对机器型。
-
WOZ型:经典的方法,由两个人分别扮演用户agent和系统agent,用户agent给出其要满足的目标,系统agent连接实体数据库,返回首选项,通过众包的形式获取数据。目前主要的WOz型数据集包括WOZ2.0,FRAMES,Multi-WOZ等,其中Multi-WOZ是WOZ2.0向多领域的尝试,包括7个领域,8483场对话,目前最新的版本是2.1。
-
机器对机器型:即基于模拟的方法。在过去,机器对机器指的就是基于对话模板生成数据,有自然性、多样性和鲁棒性不足的缺陷。不过,2018年谷歌的M2M取得了极大的成果。M2M只需要开发者提供一个任务纲要(Task Schema)和一个 API 客户端,然后就能利用一个与领域无关的对话生成器,自动生成对话大纲(及标注),最后通过简单的人工改写,将对话大纲转换为自然对话。由于annotations、slot span是自动生成的,这大大减少了数据收集成本。今年九月谷歌又推出了SGD,规模超过了市面上所有的WOZ型数据集。
数据集对比: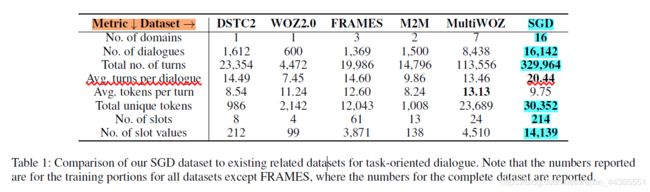
归根到底,目前的多领域数据集就只有multiwoz2.1和SGD两个。业内的多领域应用的实践也都是基于这两个数据集上运行和评估性能的。
1.3.2.MultiWOZ
过去的WOZ型数据集有数据量小、缺少适当的注释、缺少多领域样本等不足,而MultiWOZ数据集是传统单领域WOZ向多领域的尝试,目前最新版本是MultiWOZ 2.1。MultiWOZ是一个具有标注的来自于人人对话的跨越多个领域和主题的数据集,包含了3406个单域对话和7032个多域对话。MultiWOZ也是为旅游目的而定制的,包括七个领域。每段对话涉及1到5个领域。数据集中的全部本体如下图所示,展示了动作类型以及全体slot,上角标表示它们属于哪些域。

注意在MultiWOZ 2中,“slot”这个词指的是领域名称和槽位名称的concatenation,即combined slot,省去了领域与槽位间从属关系的表达,形如(Domaini- Slotj, Valuek)的结构。
MultiWOZ 2.0和2.1中槽位词表对比:

MultiWOZ本身还是一个正在被不断更新、维护的新生事物。一些研究团队在MultiWOZ上运行模型时,会砍掉2个领域(Police和hospital),然后仅在5个领域进行模型设计和训练。内部5个领域的对比图:
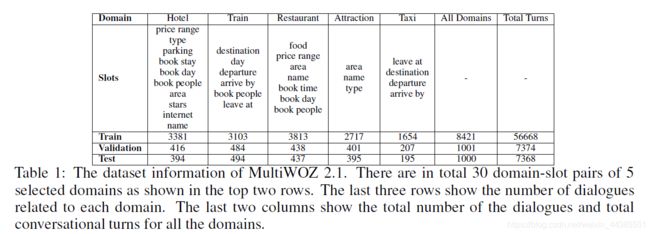
MultiWOZ相关模型实现:https://github.com/budzianowski/multiwoz
MultiWOZ数据集地址:http://dialogue.mi.eng.cam.ac.uk/index.php/corpus/
MultiWOZ 2.1数据集地址:http://dialogue.mi.eng.cam.ac.uk/index.php/corpus/
1.3.3.SGD
2019年9月,谷歌发布了论文《Towards Scalable Multi-domain Conversational Agents:The Schema-Guided Dialogue Dataset》。SGD数据集是目前公开可用的、最大的任务型对话数据集,是第一个涵盖多个领域并为每个域提供多个API的数据集。训练集中包含了属于16个领域的26种服务,共16000个对话。
现存数据集不仅覆盖的领域太少,而且它们为每一个领域定义一个静态API,但是在现实中,一个领域是存在多种服务(功能重叠、接口异构)。而SGD数据集拥有空前多的领域种类(17种),且每个领域的服务有若干个,如下图,Media领域内有4种意图,2种服务,分别称为Media_1和Media_2。

模型下载地址:schema_guided_dst
数据集的下载地址:github.com/google-researchdatasets/dstc8-schema-guided-dialogue
更多详情:我的博客
1.4 评价指标
多领域问答的性能评价指标简单介绍如下:
1.4.1 传统指标
传统的任务型问答系统的衡量指标包括任务完成度指标(Task-completion metrics)、词重叠评价指标等。人工评估结果也是很重要的方法。
任务完成度指标,包括Inform(实体匹配率,entity matching rate)和Success(客观任务成功率,objective task success rate)。Inform衡量了系统提供恰当实体的能力。Success衡量系统回答所有被请求属性(requested attributes)的能力。通过确定每个对话结束时实际选择的实体是否与用户指定的任务相匹配来计算实体匹配率。如果(1)所提供的实体匹配,且(2)系统回答来自用户的所有相关信息请求,则对话被标记为成功。
词重叠评价指标,目前基本就是BLEU分数。BLEU本身来自机器翻译领域,用于衡量一条翻译的生成响应与真实响应的相似性,后来问答系统借用了这个指标。
1.4.2 多领域DST指标
就多领域DST而言,如何衡量多领域对话状态跟踪的性能,目前也有很多的流派和争议。目前一种比较常用的评价指标叫作联合准确率,Joint accuracy。
联合准确率用于评估联合状态跟踪的性能。对每一回合,当且仅当全部的< domain, slot, value > 三元组被正确预测时,认为对话状态预测正确,联合准确率等于1,否则等于0。
除了联合准确率以外,槽位准确率(Slot accuracy)也常常被用作衡量多领域DST的指标之一。槽位准确率关注的是slot-level的预测能力,对一个(domain, slot, value),当且仅当 domain-slot pair的value被正确预测时, 认为这个单个的slot预测正确。
通过比较表述可知,联合准确率的提升比槽位准确率更困难,也更加重要。纵览截止今年10月的现有多领域问答模型,联合准确率基本还处在30%到50%的区间上下,而槽位准确率很早就达到了97%以上。
联合准确率在不同论文中会叫各种名字,如联合状态准确率(joint state accuracy)、联合目标准确率(joint goal accuracy)等,含义是相同的。
在COMER的论文中,另外存在一套更加细致的,对domain,slot,value层层递进地衡量准确率的指标。分别定义联合领域准确率(joint domain accuracy,简记为JD ACC.)、联合域-槽准确率(joint domain-slot accuracy,简记为JDS ACC.)和联合目标准确率(joint goal accuracy,简记为JG ACC.)。JD ACC.表示所有领域预测正确的概率,JDS ACC.表示所有领域及槽位正确的概率。
那么,给定正确领域,slots被正确预测的概率就是 J D S A C C . J D A C C . \dfrac {JDS\ ACC.}{JD\ ACC.} JD ACC.JDS ACC.
同理,给定正确(领域和)槽位,values被正确预测的概率就是 J G A C C . J D S A C C . \dfrac {JG\ ACC.}{JDS\ ACC.} JDS ACC.JG ACC.
上述指标可以用于衡量DST模型domain prediction、slot prediction和value prediction的能力。
为了衡量在相同本体复杂性下,DST模型的运行效率,COMER模型的研究团队还在他们的论文中提出了推断时间复杂度(inference time complexity,ITC)的概念,以衡量不同DST模型对话状态预测的效率。ITC指的是完成一次对话状态预测,需要inference多少次。显然ITC是越小越好。SOM-DST继承并改良了ITC的思想,详情见3.6。下图是各种模型的ITC复杂度对比。注意此处的slot指combined slot。
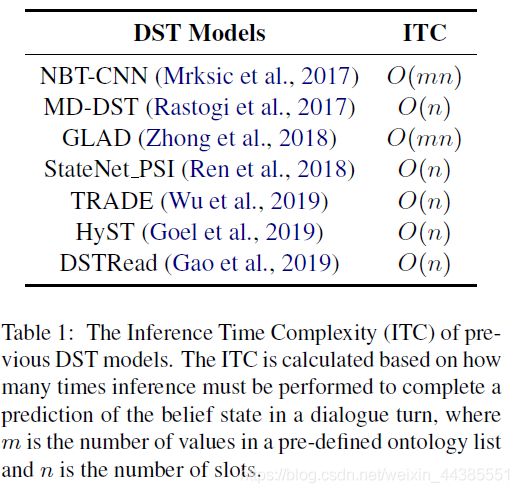
二、模式引导范式(Schema-Guided)
2.1 背景
就多领域问答系统的研究现状而言,模式引导范式思想相对超前,目前除了谷歌自己外,尚未发现有研究团队使用SGD数据集来构建问答模型,所以这一部分就从简了。
模式引导范式提出的背景如下:
问答模型需要支持多种服务,传统思想是,定义一个大型的统一主模式(master schema),来列出所有受支持的功能及其参数,将开发者给出的所有服务集成到一起。但是,这样的模式仅适用于跨领域种类较少的简单场景,当领域种类增多,模式中的意图、槽位设计的复杂性会越来越高,所以想要开发出能涵盖所有case的通用模式是不现实的;另一方面,即使开发成功,一个对所有已有服务联合建模了的模式是不易扩展的,而理想的多领域问答模型应该能够轻松支持新服务的加入。
在今年9月谷歌发布的论文《Towards Scalable Multi-domain Conversational Agents:The Schema-Guided Dialogue Dataset》中,作者提出了模式引导(Schema-Guided)的方法作为替代方案,允许集成新的服务。
Schema-Guided对话系统抛弃了主模式,而是为每一个服务定制一个模式(模式元素包括可支持的槽位、意图,以及配套自然语言描述),虚拟助手采用一个领域无关的统一模型,然后根据这些模式元素进行预测。同一对话的相同对话状态表示在两种不同服务中可以由很不同的表现。这种统一模型利于有利于在不同服务中相似概念之间的常识表示,而使用模式的分布式表示可以对训练数据中不存在的新服务进行操作。
与谷歌的SGD数据集配套的模型在这篇论文《BERT-DST Scalable End-to-End Dialogue State Tracking with Bidirectional Encoder Representations from Transformer》里。SGD的对话状态跟踪就叫Schema-Guided Dialogue State Tracking。
2.2 模式引导范式
针对传统master schema的局限性,论文团队提出了schema-guided paradigm(模式引导范式)。这种设置使用一个对所有服务和领域共享的单一模型进行预测,有助于跨领域跨服务地表示和转移共享知识,使得可以有效地跨领域跨服务地共享知识。对于向服务中添加新的意图或槽位这样的改变更鲁棒。
除了之外,SGD还就一些过去忽略的问题作出了重要的贡献:
第一,多领域问答所面临的一个重大挑战就是如何在不添加新的标注数据(引入新的意图、槽位、槽值)的情况下,实现新服务的高效扩展,也就是在zero-shot settings(零样本环境,即没有针对新服务和API的训练数据)上的泛化能力。对此,论文团队在SGD验证集中准备了unseen的意图或服务,unseen指的是不存在于训练集中,未参与训练。这样训练出来的模型,可以泛化到unseen服务中,并且对API变化鲁棒型更高。
第二,M2M的收集数据的方法虽然自动化程度大幅提升,但是依然依赖众包对模板话语进行改写。SGD参考并改良了M2M收集数据的思想,由于领域种类更多,论文团队优化了对话模拟器,在模拟自动机( simulation automaton)中未包含任何特定于领域的约束,所有特定于领域的约束是编码在schema和scenario中的, 这样使得我们可以方便地在跨领域和服务时使用模拟器。模板话语的定义更加逼近自然语言,减轻众包人员改写的工作量。对于多领域对话,还确定了在切换意图时槽值可能会转交的槽位组合
第三,为了反映真实世界的服务的约束,论文团队对槽位设置了一些其他的限制,包括可分类性限制和时序依赖性限制。前者比方说,对于日期、时间、电影歌曲这种会定期添加新值的槽位,专门将它们识别为不可分类(non-categorical)槽位,而不专门为其维护一个包含所有可能槽值的列表集合。后者则是考虑了真实世界中对调用服务时对槽位组合的要求,例如餐厅预订API在检索餐厅之前,应该要求用户指定位置。所以,一个服务所支持的不同服务调用应指定一组必需的槽位,如果这些必需槽位未指定具体指,系统就不允许调用此意图。
三、运行在MultiWOZ上的业内模型
3.1 综述
经过调研,业内研究团队在MultiWOZ 2.1数据集上的DST应用是较多的,而SGD上的则较少。由于MultiWOZ 2.1拥有跨领域的对话和槽值转换,吸引了大量的研究团队。目前而言,MultiWOZ还是一个较新的数据集,所以并没有一个如何使用它的统一的数据预处理标准。目前,在MultiWOZ 2.1上,基于相同的预处理方式,性能最好的基线模型是DS-DST和SOM-DST。
对于多领域DST,在早期,由于单领域问答已经取得了巨大成功,而多领域DST的挑战尚未被明确总结出来,彼时的跨领域问答数据集涉及的领域数量尚少(2到3个),所以,学术界最初是基于传统的slot-level的思想来考虑跨领域问答的,把所面临的挑战看做是一个本体太大的rich-set of slot types的问题,即本体中存在的预定义槽位数更多的情况下如何提高DST的效率。此外,也有研究团队尝试从domain-level和slot-level两个层次训练多领域DST模型(ML-BST),但由于深度建模而饱受争议。
多领域DST大致可以分为fixed-vocabulary与open-vocabulary两大流派。
3.2 fixed-vocabulary-based DST
fixed-vocabulary-based DST:(或predefined ontology-based方法、检索式方法),即固定词表/基于预定义本体的方法。这种方法是传统的单领域任务型问答中的传统方法。基本思想是,预定义一个所以可能的槽值的本体(ontology of possible slot values),在这个本体上运行状态跟踪(分类)机制。
由于这种方法能够让系统流畅地预测那些未出现在给定对话历史中的槽值,简化任务,所以在DSTC2、WOZ 2等单领域数据集上的测试中取得了杰出的表现,SOTA模型是GLAD与GCE。GCE基于GLAD,但是GCE通过删除插槽特定的recurrent层和self-attention层,简化了GLAD的encoder。
但是,这种方法的缺陷也是很明显的,主要问题是死板,必须在训练阶段为每一个领域定义潜在的槽值大列表,这个是很困难的;其次,计算的复杂性会随着需要跟踪的预定义槽位数量的增加而增加;第三,难以应对unseen slot values问题(事实上,近期提出的predefined ontology-based DST模型通常都会把槽值分成训练集内可见的槽值与验证集中的槽值)。因此,当涉及本体庞大的多领域问答时,此问题会更加严重。
针对多领域问答的大量槽位,研究人员对传统单领域DST模型进行了种种改进,产生了FJST、HJST、SUMBT等多种可以适用multiwoz 2数据集上的问答系统,但是,它们的性能整体上弱于同时期的open-vocabulary-based DST模型,现今越来越成为open-vocabulary方法的陪衬。例如,HyST在HJST基础上引入open-vocabulary的思想。
目前,fixed-vocabulary-based DST的最新模型是SUMBT,利用BERT作为对话上下文和slot-value pairs的编码器,在编码后对每个候选slot-value pair进行评分。后来,DS-DST参考了SUMBT,和SUMBT共同代表fixed-vocabulary-based DST的最好性能。
3.3 open-vocabulary-based DST
open-vocabulary-based DST:(或open-vocabulary candidate-generation DST,生成式方法)。又名“生成式”方法,最初的思想来自SpanPtr,目的是在缺失预定义本体的情况下实现状态跟踪,并处理未知的槽值。这种方法的基本思想是基于每轮的状态(源序列)派生候选集,相当于序列生成问题。这种方法从对话历史中灵活地抽取或生成槽值,但是要努力预测出对话历史中未出现的槽值。在解决unseen slot values问题上有所成果,但是DST的运行效率低,因为它们要在每一轮对话的一开始预测对话状态。由于open-vocabulary-based DST的槽值生成思想极大解决了对本体的依赖,所以在多领域问答上大受欢迎,目前已经成为重要的研究热点。
生成式方法的思想最初萌芽于SpanPtr。提出SpanPtr的那篇论文将该模型运行在DSTC2等单领域数据集上。SpanPtr是基于指针网络(pointer-network,PtrNet)的模型,通过每个domain-slot pair的起始指针和终止指针来寻找text spans。由于目前多领域DST的复杂性挑战主要的问题在于slot ontology规模大,以及需要跟踪训练集中unseen的槽值,所以SpanPtr的思想逐渐被引入到多领域DST中,催生了TRADE、COMER等在MultiWOZ 2数据集上性能优秀的多领域DST模型。此系列的模型发掘了encoder-decoder framework的潜力,引入了BERT结构、拷贝机制(copy mechanisms)等思想。
此外,DSTreader也是一种生成式DST的方向。DSTreader把状态跟踪看做一个阅读理解(text reading comprehensions)问题,即对“当前的对话状态是什么”给出回答。论文使用了BERT context embedding,学习从对话历史中把槽值抽取成spans。提出DSTreader的那篇论文本身仅运行在WOZ 2.0等模型上。后来,其他研究人员在MultiWOZ 2数据集上测试了DSTreader的性能,虽然性能不佳,但并不可否认它的潜力。
这中间还有一些模型,如NADST和ML-BST,但是都饱受争议,正在under review,且性能不如DS-DST或SOM-DST。
近期,针对多领域问答的挑战,以及以往open-vocabulary模型的考虑不周之处,DS-DST与SOM-DST这两种模型分别提出了一类解决方案,目前,它们是MultiWOZ 2.1上基于相同的预处理方式的性能最好的基线模型。
3.4 各模型的论文纵览
现有的多领域问答模型,包括但不限于:
- Xu and Hu, 2019: 《An end-to-end approach for handling unknown slot values in dialogue state tracking》
这篇论文提出了SpanPtr模型,把index-based pointers network应用到单领域DST中,每个domain-slot pair的起始指针和终止指针来寻找text spans,生成start and end pointers以允许基于索引的拷贝。 - Eric et al.,2019:《Multiwoz 2.1: Multi-domain dialogue state corrections and state tracking baselines》
这篇论文即是发布MultiWOZ 2.1数据集的论文,论文团队提到了两种模型,分别是FJST(Flat Joint State Tracker)和HJST(Hierarchical Joint State Tracker)。FJST是一个编码了整个对话历史的双向LSTM网络,并为每一个state slot的encoded隐藏状态应用了分离的前馈网络,以预测dialog state slot。HJST与FJST相似,但是改用hierarchical RNNs编码对话历史。其中,hierarchical neural network models来自Serban, et al.,2016. - Wu et al., 2019a:《Transferable multi-domain state generator for task-oriented dialogue systems》
这篇论文提出了TRADE(Transferable Dialogue State Generator)模型,这个模型使用一种带有软拷贝机制(soft-gated copy mechanism)的生成式状态跟踪器(generative state tracker)来从话语中生成对话状态,使得当预测到训练中未遇到过的 (domain, slot, value)三元组时,能够实现知识的转移(knowledge transfer)。 - Lee et al., 2019:《Sumbt: Slot-utterance matching for universal and scalable belief tracking》
这篇论文提出了SUMBT模型,利用BERT作为对话上下文和slot-value pairs的编码器,在编码后对每个候选slot-value pair进行评分。后来的DS-DST借用了SUMBT模型。 - Ren et al.,2019:《Scalable and Accurate Dialogue State Tracking via Hierarchical Sequence》
这篇论文针对fixed-vocabulary方法的缺陷,提出了基于open-vocabulary思想的COMER(COnditional MEmory Relation Network)模型。模型由一个带有分层堆叠的解码器的encoder-decoder模型组成,首先生成对话状态中的slot sequences,然后为每一个slot生成对应的value sequences。decoders以对话状态层级结构的深度的规模共享参数,序列编码应用了BERT上下文词向量。 - Goel et al., 2019:《Hyst: A hybrid approach for flexible and accuratedialogue state tracking》
这篇论文提出了HyST(Hybrid state tracking)模型,在HJST基础上结合了基于拷贝机制的open-vocabulary generation方法。 - Gao et al.,2019 :《Dialog state tracking: A neural reading comprehension approach》
这篇论文提出DSTreader,把状态跟踪看做一个阅读理解(text reading comprehensions)问题,即对“当前的对话状态是什么”给出回答。模型向BERT模型询问slot问题,然后在对话历史中为每个pre-defined combined slot回答answer span。论文使用了BERT context embedding,学习从对话历史中把槽值抽取成spans。 - Zhang et al., 2019:《Find or Classify Dual Strategy for Slot-Value Predictions on Multi-Domain Dialog State Tracking》
这篇论文提出了DS-DST模型,综合使用了两种DST方法,宣称取得了SOTA效果。 - Kim et al., 2019:《Efficient Dialogue State Tracking by Selectively Overwriting Memory》
这篇论文提出了SOM-DST(Selectively Overwriting Memory for Dialogue State Tracking)模型。它将对话状态看做显式的的大小固定的memory,并提出选择性覆盖机制,宣称在Open vocabulary-based DST中方法中取得了SOTA效果。 - Anonymous 2020a:《end to end multi domain task-oriented dialogue systems with multi level neural belief tracker》
这篇论文提出了ML-BST中,在domain-level和slot-level同时训练DST。
3.5 DS-DST
DS-DST针对open-vocabulary模型的ill-formatted strings问题,想到了一种结合两种DST优势的方法,即把所有slots分成两类,对于picklist-based slots使用predefined ontology-based approach ,而对于 span-based slots, 使用span extraction-based method。
基于跨度的槽位(span-based slots )与基于选项列表的槽位( picklist-based slots):
-
基于选项列表的槽位( picklist-based slots):这种是把domain-slot pairs 看做是picklist-based slots,为其使用predefined ontology-based DST,就是在预定义的可接入本体的条件下,对每一个槽位在候选槽值的列表(candidate-value list)上运行分类算法。论文的中使用的方法类似SUMBT。
-
基于跨度的槽位(span-based slots):这种是把domain-slot pairs看做是span-based slots,在对话上下文中,对每一个槽位,通过寻找text spans来跟踪槽值(从slot span中寻找value)。slots中的values可以通过对话上下文中的起始和终止位置的span来找到。论文中使用的方法类似DSTreader。
论文中分情况具体地训练了三个模型:
• DST-Span: 类似SpanPtr,把所有domain-slot pairs看做span-based slots,其中每一个slot的对应values 被抽取,通过【带有对话上下文中的起始和结束为止text spans (字符串匹配)】
• DST-Picklist: 把所有domain-slot pairs看做picklist-based slots, 其中每一个slot的对应values在candidate-value list中找到。
• DS-DST:都有。
以上模型在MultiWOZ 2.1下的联合准确率对比如下:

DS-DST模型确实取得了优秀的结果,但是,它的性能反而不如完全把domain-slot pairs都看做picklist-based slots的DST-Picklist好,后者依然应该被看做是predefined ontology-based方法。
详情参见我的博客
3.6 SOM-DST
SOM-DST是目前运行在MultiWOZ 2上的最好模型。SOM-DST将对话状态看做显式的的大小固定的memory,并提出选择性覆盖机制,在Open vocabulary-based DST中方法中取得了SOTA效果。
传统的运行在MultiWOZ 2上的Open vocabulary-based DST方法,都是在每一turn为全部slots生成values,计算上效率不高。TRADE模型体现了encoder-decoder framework的潜力,COMER模型通过使用hierarchical decoder(层次堆叠的解码器),以分层的方法解码domains, slots和values,把当前轮对话状态本身生成为target sequence。COMER在slot values子集上生成,一定程度提高了效率,但是没有利用上一轮的对话状态信息。
SOM-DST在沿袭了上述模型的思想之外,显式地提出在slot的最小子集上生成values的方法,从而减少了预测时间复杂度ITC;把DST分解成了两个子任务,tate operation prediction,状态操作预测。预测将在每一个memory slot上运行的operations的类型。slot value generation,槽值生成。生成将新写入memory slots子集的values。这样明确分工的设计,降低了open-vocabulary based setting下DST的难度。此外,SOM-DST利用了上一轮对话状态的信息,降低了DST训练的难度。
operations:共有四种操作,CARRYOVER表示槽值保持不变,其余三个相当于传统的update。
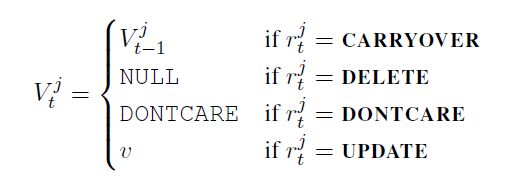 predictor相当于每个slot一个四分类器,判断它的operation。
predictor相当于每个slot一个四分类器,判断它的operation。
generator类似TRADE,使用GRU decoder和拷贝机制,通过context和vocabulary共同决定。
SOM-DST与以往的各种DST模型的联合准确率对比:
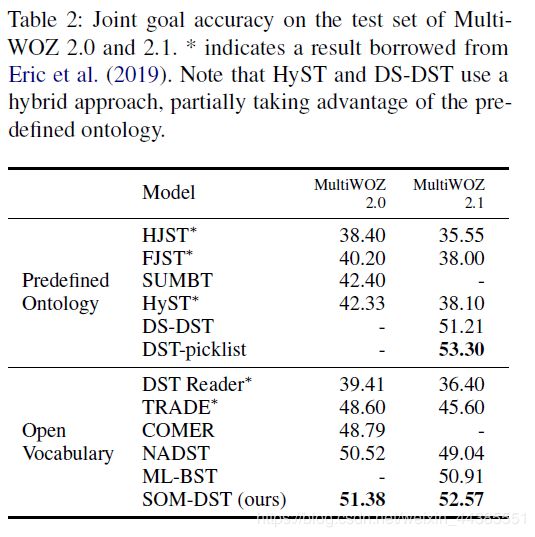
除了在纵向上超越了所有以有的open-vocabulary模型外,SOM-DST还首次实现了MultiWOZ2.1比2.0上表现更好,原因可能是SOM-DST更显式地使用了dialogue state labels作为输入,从而受益于MultiWOZ 2.1上对话状态的标注信息的修正。
除了联合准确率之外,这篇论文的作者还继承并发展了COMER提出的ITC概念,并提出了Domain-Specific Accuracy(特定领域准确率)的评价指标,特定领域准确率指的是predicted dialogue state的子集上计量的准确率。SOM-DST同样在这两个指标上取得了SOTA的性能。
详情参见我的博客
四、前景分析
随着问答服务“体量”的日益增长,多领域问答越来越受到学术界的重视,今年尤其是把多领域面向任务型追踪,作为问答系统的新调整加入到了DSTC8(the Eighth Dialog System Technology Challenge)中,大量的科研团队向这个方向投入了研究。归根到底,目前的多领域数据集就只有MultiWOZ 2.1和SGD两个,其中MultiWOZ 2.1数据集是目前最广泛使用的多领域问答训练数据集,SGD是目前最大规模的多领域问答训练数据集。两个数据集有单领域内的对话也有多领域之间的切换,有单API服务,也有多API服务,其提供了模型框架也有多方面的参考价值。但是,它们也有一些不足之处。比如SGD模型在跨越多个领域的性能上区别还是很大,应该是对于具有相似槽值的可分类槽位,模型很难区分不同的类别,从而导致性能不佳。所以,领域的切换还有很多需要深入考虑的地方。此外,作为任务型对话,对话段落有明确的界限,以完成一个明确的场景(一些列意图的组合)为目标,如何将其与闲聊型机器人集成依然是一个问题,一个主要的挑战是闲聊型对话会对对话历史信息造成干扰。此外MultiWOZ 2.1本身缺少一个业内普遍认可的使用方式,其本身也在不断地维护和修正内部的标注数据,所以依然需要更加到位的发展。目前,在MultiWOZ 2.1上,基于两种方法的多领域DST最好的模型分别是DS-picklist与SOM-DST,但是仅考虑公开了代码的模型的话则分别是SUMBT与COMER。
附 录
A.ConvLab
网址:ConvLab
论文原文:《ConvLab: Multi-Domain End-to-End Dialog System Platform》
参考:使用与介绍
ConvLab是微软美国研究院和清华联合推出了一款开源的多领域端到端对话系统平台,它包括一系列的可复用组件,包括传统pipline系统与端对端神经模型,方便研究者可以快速使用这些可复用的组件搭建实验模型。同时,ConvLab还提供了大量广泛的可训练的统计模型及标注数据。研究人员可以使用上述工具创建各种对话系统,并在同一环境下横向对比不同方法的效果。此外,ConvLab还提供了对端到端模型的人类评测(Amazon Mechanical Turk)和模拟评测。
B.Models
各模型的网络源码:
GLAD:网址
TRADE:网址
COMER:网址
SUMBT:网址