
作者:AISHWARYA SINGH
翻译:张玲
校对:张一豪
本文约3500字,建议阅读10+分钟。
本文简单介绍聚类的基础知识,包括快速回顾K-means算法,然后深入研究高斯混合模型的概念,并用Python实现。
概述
简介
我真的很喜欢研究无监督的学习问题,因为它们提供了一个完全不同于监督学习问题的挑战:提供更大的空间来试验我的数据。这也不难理解机器学习领域的大多数发展和突破都发生在无监督学习这一块。
无监督学习中最流行的技术之一是聚类,这通常我们在早期学习机器学习时学习的概念,而且很容易掌握。我相信你已经遇到过,甚至参与过用户分层、市场购物篮分析等项目。

但问题是,聚类有很多种,不只局限于我们之前学过的基本算法。它是一种我们可以在现实世界中准确无误地使用的强大的无监督学习技术。
“高斯混合模型是我在本文中即将要讨论的一种聚类算法。”
想要预测你最喜欢的产品销售量吗?或者你想要通过不同客户群体的视角来剖析客户流失。不管是什么应用场景,你都会发现高斯混合模型是非常有用的。
本文将采用自下而上的方法。首先,我们学习聚类的基础知识,包括快速回顾K-means算法,然后,我们将深入研究高斯混合模型的概念,并用Python实现它们。
如果你对聚类和数据科学还不熟悉,我建议你先学习以下综合课程:
应用机器学习相关课程链接:
https://courses.analyticsvidhya.com/courses/applied-machine-learning-beginner-to-professional?utm_source=blog&utm_medium=gaussian-mixture-models-clustering
目录
一、聚类简介
二、K-means聚类简介
三、K-means聚类缺点
四、高斯混合模型简介
五、高斯分布
六、什么是期望最大化
七、高斯混合模型中的期望最大化
八、用Python实现高斯混合聚类模型
一、聚类简介
在我们开始讨论高斯混合模型的本质之前,让我们快速回顾一些基本概念。
请注意: 如果您已经熟悉了聚类背后的思想以及K-means聚类算法的工作原理,可以直接跳到第4节“高斯混合模型简介”。
让我们先从核心思想的正式定义开始:
“聚类指根据数据的属性或特征将相似数据点分成一组”
例如,我们有一组人的收入和支出,我们可以将他们分为以下几类:
高收入高消费
高收入低消费
低收入低消费
低收入高消费

上面的每一组都是一个具有相似特征的群体,因此针对性地向这些群体投放相关方案/产品非常有效。类似信用卡、汽车/房产贷款等的投放。简单来说:
“聚类背后的思想是将数据点分组在一起,这样每个单独的聚类都有着最为相似的点。”
目前有各种各样的聚类算法,最流行的聚类算法之一是K-means。让我们了解K-means算法是如何工作的,以及该算法可能达不到预期的情况。
二、K-means聚类简介
“K-means聚类是一种基于距离的聚类算法,这意味着它将试图将最近的点分组以形成一个簇”。
让我们仔细看看这个算法是如何工作的,这将为后续了解高斯混合模型打下基础。
首先,我们先确定目标分组数量,这是K的数值,根据需要划分的族或分组的数量,随机初始化k个质心。
然后将数据点指定给最近的质心,形成一个簇,接着更新质心,重新分配数据点。这个过程不断重复,直到质心的位置不再改变。
查看下面的gif,它代表初始化和更新簇的整个过程,假设簇数量为10:
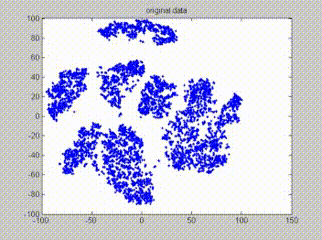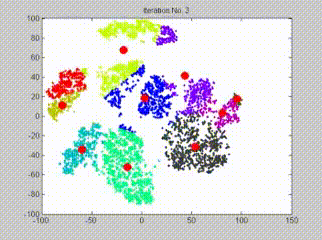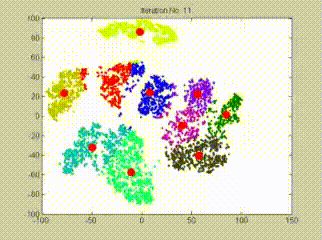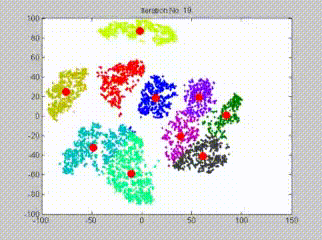
请注意: 这是K-means聚类的简单概述,对于本文来说已经足够了。如果你想深入研究k-means算法的工作原理,这里有一个详细指南:
最全面的K-mans指南,你永远都需要:
https://www.analyticsvidhya.com/blog/2019/08/comprehensive-guide-k-means-clustering/?utm_source=blog&utm_medium=gaussian-mixture-models-clustering
三、K-means聚类缺点
K-means聚类概念听起来不错,对吧?它易于理解,实现起来相对容易,并且可以应用在很多场景中,但有一些缺点和局限性需要我们注意。
让我们以上面提及的收支数据为例,K-means算法似乎运行得很好,对吧?等等,如果你仔细观察,将会发现所有创建的簇都是圆形的,这是因为分类的质心都是使用平均值迭代更新的。
现在,考虑下面的例子,其中点的分布不是圆形的,如果我们对这些数据使用K-means聚类,您认为会发生什么?它仍然试图以循环方式对数据点进行分组,那不太好!K-means会无法识别正确的分簇:
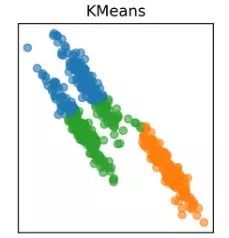
因此,我们需要一种不同的方法来将类分配给数据点。
不再使用基于距离的模型,而是使用基于分布的模型,这就是高斯混合模型出现在本文的意义!
四、高斯混合模型简介
“高斯混合模型(Gaussian Mixture Models ,GMMs)假设存在一定数量的高斯分布,并且每个分布代表一个簇。高斯混合模型倾向于将属于同一分布的数据点分组在一起。”
假设我们有三个高斯分布(在下一节中有更多内容)——GD1、GD2和GD3,它们分别具有给定的均值(μ1,μ2,μ3)和方差(σ1,σ2,σ3)。对于给定的一组数据点,我们的GMMs将计算这些数据点分别服从这些分布的概率。
等等,概率?
没错!高斯混合模型是一种概率模型,采用软聚类方法将数据点归入不同的簇中。
在这里,我们有三个簇,用三种颜色表示-蓝色、绿色和青色。我们用红色突出显示一个数据点,这个点划分进蓝色簇的概率为1,而划分进绿色簇或者青色簇的概率为0。
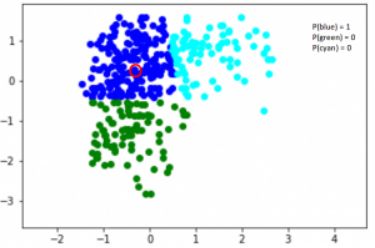
现在,考虑另一个点-介于蓝色和青色簇之间(在下图中突出显示),这个点划分进绿色簇的概率为0,对吧?而划分进蓝色、青色簇的概率分别是0.2,0.8。

高斯混合模型使用软分类技术将数据点分配至对应的高斯分布,我肯定你想知道这些分布是什么,我将在下一节解释一下。
五、高斯分布
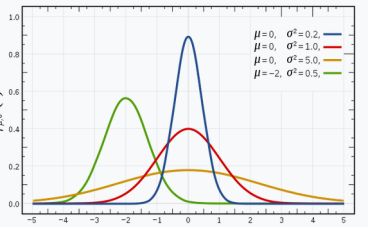
我相信你熟悉高斯分布(或正态分布),它有一个钟形曲线,数据点围绕平均值对称分布。
下图有一些高斯分布,平均值(μ)和方差(σ2)不同。
记住,σ值越大,分布曲线越宽。
在一维空间中,高斯分布的概率密度函数由下式给出:
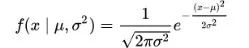
其中μ是平均值,σ2是方差。
但这只适用于单个变量。在两个变量的情况下,我们将得到如下所示的三维钟形曲线,而不是二维钟形曲线:
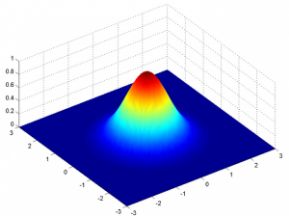
概率密度函数由以下公式给出:
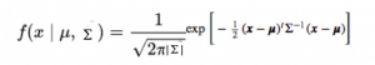
其中,x是输入向量,μ是2维均值向量,∑是2×2协方差矩阵。协方差现在可以决定曲线的形状。d维概率密度函数可以类似进行推广。
“因此,这个多元高斯模型将x和μ作为长度为d的向量,∑是一个d×d协方差矩阵。”
对于具有d个特征的数据集,我们将得到k个高斯分布(其中k相当于簇的数量),每个高斯分布都有一个特定的均值向量和方差矩阵,但是——这些高斯分布的均值和方差值是如何给定的?
这些值可以用一种叫做期望最大化(Expectation-Maximization ,EM)的技术来确定,在深入研究高斯混合模型之前,我们需要了解这项技术。
六、什么是期望最大化
好问题!
“期望最大化就是寻找正确模型参数的统计算法,当数据有缺失值时,或者换句话说,当数据不完整时,我们通常使用EM。”
这些值缺失的变量被称为潜在变量,当我们研究无监督学习问题时,我们认为目标(或簇数)是未知的。
由于这些潜在变量,很难确定正确的模型参数。这样想吧:如果你知道哪个数据点属于哪个簇,那么就很容易确定均值向量和协方差矩阵。
由于我们没有这些潜在变量的值,EM试图利用现有数据来确定这些变量的最优值,然后找到模型参数。 基于这些模型参数,我们返回并更新潜在变量的值等等。
广义上,EM有2个步骤:
EM是很多算法的基础,包括高斯混合模型。那么,GMM如何使用EM概念以及如何将其应用于给定的数据集?让我们看看!
七、高斯模型中的期望最大化
让我们用另一个例子来理解这一点,读的时候需要你发挥下想象力来理解一些概念,这可以帮助你更好地理解我们在说些什么。
假设我们需要做K维聚类,这意味着存在k个高斯分布,平均值和协方差值为μ1、μ2、…、μk和∑1、∑2、…、∑k,此外,还有一个用于决定分布所用数据点数量的参数,换句话说,分布的密度用∏i表示。
现在,我们需要确定这些参数的值来定义高斯分布。我们已经确定簇数量,并随机分配了均值、协方差和密度的值,接下来,我们将执行E步骤和M步骤!
E步骤:
对于每个点Xi,计算它属于簇/分布C1、C2、…、CK的概率。使用以下公式完成此操作:
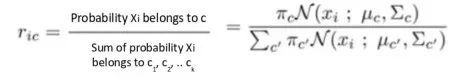
该值高时表示点被分配至正确的簇,反之则低。
M步骤:
完成E步后,我们返回并更新∏,μ和∑值。更新方式如下:
1. 新分布密度由簇中的点数与总点数的比率定义:

2. 平均值和协方差矩阵根据分配给分布的值进行更新,与数据点的概率值成比例。因此,具有更高概率成为该分布一部分的数据点将贡献更大的比例:

基于此步骤生成的更新值,我们计算每个数据点的新概率值并迭代更新。为了最大化对数似然函数,重复该过程。实际上我们可以说:
K-means只考虑更新质心的均值,而GMMs则考虑更新数据的均值和方差!
八、用Python实现高斯混合模型
是时候深入研究代码了!这是我在任何一篇文章中最喜欢的部分之一,所以我们马上开始吧!
我们将从加载数据开始,这是我创建的临时文件,您可以从以下链接下载数据:
相关链接:
https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2019/10/Clustering_gmm.csv
import pandas as pd
data = pd.read_csv('Clustering_gmm.csv')
plt.figure(figsize=(7,7))
plt.scatter(data["Weight"],data["Height"])
plt.xlabel('Weight')
plt.ylabel('Height')
plt.title('Data Distribution')
plt.show()
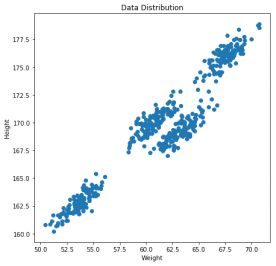
这是我们的数据,现在此数据上建立一个K-means模型:
#training k-means model
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4)
kmeans.fit(data)
#predictions from kmeans
pred = kmeans.predict(data)
frame = pd.DataFrame(data)
frame['cluster'] = pred
frame.columns = ['Weight', 'Height', 'cluster']
#plotting results
color=['blue','green','cyan', 'black']
for k in range(0,4):
data = frame[frame["cluster"]==k]
plt.scatter(data["Weight"],data["Height"],c=color[k])
plt.show()
那不太对,K-means模型无法识别正确的簇。仔细观察簇中心——K-means试图构建一个圆形簇,尽管数据分布都是椭圆形的(还记得我们之前讨论过的缺点吗?)。
现在让我们在相同的数据上建立一个高斯混合模型,看看是否可以改进K-means:
import pandas as pd
data = pd.read_csv('Clustering_gmm.csv')
# training gaussian mixture model
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=4)
gmm.fit(data)
#predictions from gmm
labels = gmm.predict(data)
frame = pd.DataFrame(data)
frame['cluster'] = labels
frame.columns = ['Weight', 'Height', 'cluster']
color=['blue','green','cyan', 'black']
for k in range(0,4):
data = frame[frame["cluster"]==k]
plt.scatter(data["Weight"],data["Height"],c=color[k])
plt.show()
太棒啦!这些正是我们所希望的簇划分!高斯混合模型已经把K-means击败啦!
尾注
这是高斯混合模型的入门指南,在这里主要是向你介绍这种强大的聚类技术,并展示它与传统算法相比是多么有效和高效。
我鼓励你参加一个聚类项目,并尝试使用GMMs。这是学习和理解一个概念的最好方法,相信我,你会意识到这个算法多么有用!
对高斯混合模型有什么问题或想法,可以在下面评论区一起讨论。
原文标题:
Build Better and Accurate Clusters with Gaussian Mixture Models
原文链接:
https://www.analyticsvidhya.com/blog/2019/10/gaussian-mixture-models-clustering/
编辑:黄继彦
校对:林亦霖
张玲,在岗数据分析师,计算机硕士毕业。从事数据工作,需要重塑自我的勇气,也需要终生学习的毅力。但我依旧热爱它的严谨,痴迷它的艺术。数据海洋一望无尽,数据工作充满挑战。感谢数据派THU提供如此专业的平台,希望在这里能和最专业的你们共同进步!
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~

点击“阅读原文”拥抱组织
