某音乐歌曲爬虫
某音乐歌曲爬虫
概况
使用python爬虫自动下载酷gouTop500的歌曲。
目标网址:https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
网站分析:
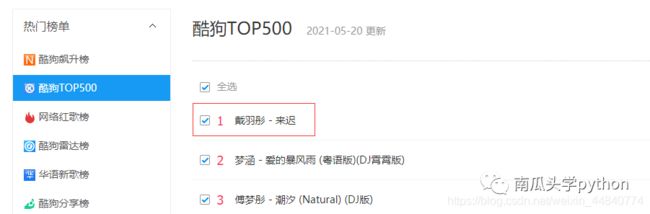
点击歌曲进入播放页面后对网页进行抓包分析,

抓包分析发现歌曲信息出现在上图的地址中,“来迟”这首歌曲的信息api地址是https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery1910045939665475981384_1621500682569&hash=456EA2137B08259DBFCC213FDA3935FD&dfid=&mid=bca91e9de3ab56c29358ab868e534908&platid=4&album_id=43439160&_=1621500682570。具体信息如下图所示:
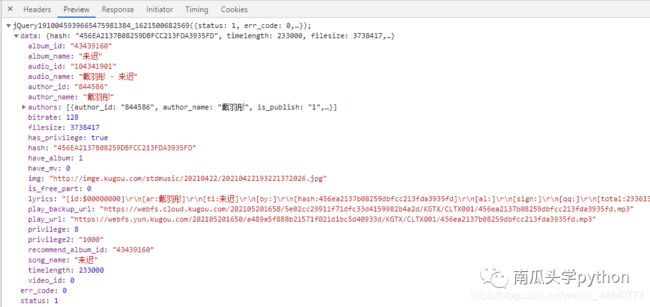
可以看到album_name即是歌名,author_name即是歌手名,play_url即是歌曲地址。
其中api地址包含了两个重要的参数,分别是hash和album_id,
实践发现服务端只检测了这两个参数。
那么这两个参数的出处在哪呢?
通过对目标网页的源码分析,发现这两个参数就存在于源码中。

可以通过使用正则表达式获取。
代码:
def get_hash_album():
url = 'https://www.kugou.com/yy/rank/home/1-8888.html?from=rank'
html = session.get(url, headers=headers, verify=False).text
pat = '{"Hash":"(.*?)",'
pat2 = '"album_id":(.*?),"'
hash_list = re.compile(pat).findall(html)
album_list = re.compile(pat2).findall(html)
return hash_list, album_list
获取到两个参数后就可以构造url地址了,请求并获得json数据了。
代码:
def get_json(h, a):
for i in range(0, len(h)):
url = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={}&album_id={}'.format(h[i], a[i])
data = session.get(url, headers=headers, verify=False).json()
address = data['data']['play_url']
name = data['data']['audio_name']
print(url)
get_music(address, name)
获得信息后,接下来就可以下载音乐啦!
代码:
def get_music(address, name):
res = requests.get(address)
music = res.content
with open('酷狗音乐/{}.mp3'.format(name), 'ab') as file:
file.write(music)
file.flush()
print('下载成功!' + name)
至此我们的音乐就下载完成啦!
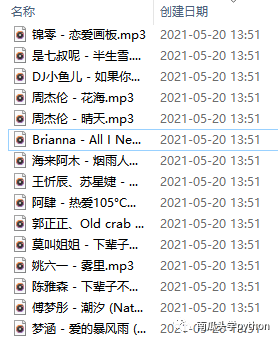
一起来欣赏一下吧!
完整代码公众号回复“音乐”获取。
