前言
作为程序员,应该都对二叉树都不陌生,我们都知道二叉树的变体二叉查找树,非常适合用来进行对一维数列的存储和查找,可以达到 O(logn) 的效率;我们在用二叉查找树进行插入数据时,根据一个数据的值和树结点值的对比,选择二叉树的两个叉之一向下,直到叶子结点,查找时使用二分法也可以迅速找到需要的数据。
但二叉树只支持一维数据,如一个标量数值,对地图上的位置点这种有xy两个方向上的信息却无能为力,那么是否有一种树能够支持二维数据的快速查询呢?
四叉树
介绍
四元树又称四叉树是一种树状数据结构,在每一个节点上会有四个子区块。四元树常应用于二维空间数据的分析与分类。它将数据区分成为四个象限。
今天要介绍的四叉树可以认为是二叉查找树的高维变体,它适合对有二维属性的数据进行存储和查询,当然四叉树存储的也不一定是二维数据,而是有着二维属性的数据,如有着 x,y 信息的点,用它还可以用来存储线和面数据。它有四个叉,在数据插入时,我们通过其二维属性(一般是 x,y)选择四个叉之一继续向下,直至叶子结点,同样使用“四分法”来迅速查找数据。四叉树的一般图形结构如下:

聪明的小伙伴一定想到了适合存储和查询三维数据的八叉树,它们原理是一致的,不过我们暂不讨论。
分类
四叉树常见的应用有图像处理、空间数据索引、2D中的快速碰撞检测、稀疏数据等,今天我们很纯粹地只介绍它在空间索引方面的应用。
根据其存储内容,四叉树可以分为点四叉树、边四叉树和块四叉树,今天我们实现的是点四叉树。
根据其结构,四叉树分为满四叉树和非满四叉树。
对于满四叉树,每个节点都有四个子结点,它有着固定的深度,数据全都存在最底层的子结点中,进行数据插入时不需要分裂。
满四叉树在确定好深度后,进行插入操作很快,可是如果用它来存储下图所示数据,我们会发现,四叉树的好多叉都是空的,当然它们会造成内存空间的大量浪费。

非满四叉树解决了此问题,它为每个结点添加一个“容量”的属性,在四叉树初始化时只有一个根结点,在插入数据时,如果一个结点内的数据量大于了结点“容量”,再将结点进行分裂。如此,可以保证每个结点内都存储着数据,避免了内存空间的浪费。
在查询时,只有找到了位置对应的结点,那么结点下的所有点都会是此位置的附近点,更小的“容量”意味着每个结点内点越少,也就意味着查询的精度会越高。
代码实现
首先是数据结构的定义:
树结点:
struct QuadTreeNode {
int depth; // 结点深度
int is_leaf; // 是否是叶子结点
struct Region region; // 区域范围
struct QuadTreeNode *LU; // 左上子结点指针
struct QuadTreeNode *LB; // 左下子结点指针
struct QuadTreeNode *RU; // 右上子结点指针
struct QuadTreeNode *RB; // 右下子结点指针
int ele_num; // 位置点数
struct ElePoint *ele_list[MAX_ELE_NUM]; // 位置点列表
};
为了加快插入和查询速度,数据结构设计稍微冗余了一些;
四叉树位置点的插入流程如下图所示:
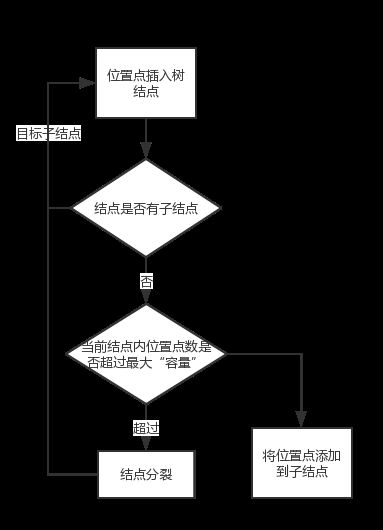
结点的分裂是重点,这里介绍一下:
void splitNode(struct QuadTreeNode *node) {
// 获取xy方向上的中间点,用来初始化子结点的范围
double mid_vertical = (node->region.up + node->region.bottom) / 2;
double mid_horizontal = (node->region.left + node->region.right) / 2;
node->is_leaf = 0; // 将是否为叶子结点置为否
// 填充四个子结点
node->RU = createChildNode(node, mid_vertical, node->region.up, mid_horizontal, node->region.right);
node->LU = createChildNode(node, mid_vertical, node->region.up, node->region.left, mid_horizontal);
node->RB = createChildNode(node, node->region.bottom, mid_vertical, mid_horizontal, node->region.right);
node->LB = createChildNode(node, node->region.bottom, mid_vertical, node->region.left, mid_horizontal);
// 遍历结点下的位置点,将其插入到子结点中
for (int i = 0; i < node->ele_num; i++) {
insertEle(node, *node->ele_list[i]);
free(node->ele_list[i]);
node->ele_num--;
}
}
问题和优化
边界点问题
四叉树还是面临着边界点问题,每个结点内的点必然是相邻的,但相邻的点越不一定在同一个结点内,如下图,A点和B点相邻的很近,如果A点是我们查找的目标点,那么仅仅取出A点所在结点内的所有位置点是不够的,我们还需要查找它的周边结点。
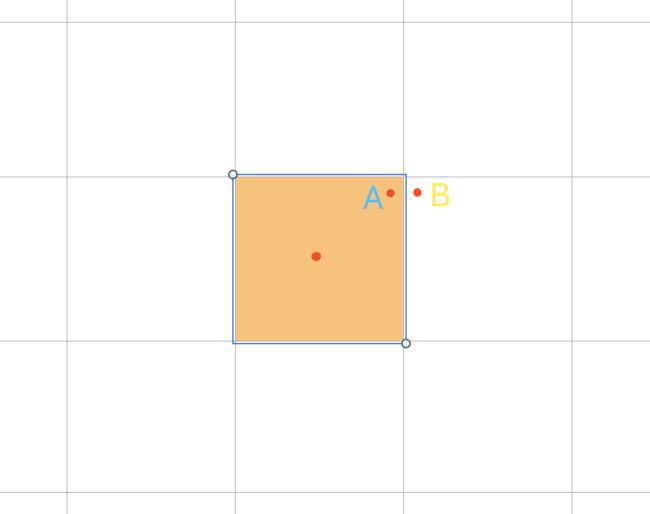
这里我们要介绍四叉树的另一个特性。
字典树
字典树,又称前缀树或trie树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。
我们可以类比字典的特性:我们在字典里通过拼音查找晃(huang)这个字的时候,我们会发现它的附近都是读音为huang的,可能是声调有区别,再往前翻,我们会看到读音前缀为huan的字,再往前,是读音前缀为hua的字... 取它们的读音前缀分别为 h qu hua huan huang。我们在查找时,根据 abc...xyz 的顺序找到h前缀的部分,再根据 ha he hu 找到 hu 前缀的部分...最后找到 huang,我们会发现,越往后其读音前缀越长,查找也越精确,这种类似于字典的树结构就是字典树,也是前缀树。
四叉树也有此特性,我们给每一个子结点都编号,那么每个子结点会继承父结点的编号为前缀,并在此基础上有相对其兄弟结点的独特编号。
与 GeoHash 的相似之处
如果我们给右上、左上、左下、右下四个子结点分别编号为00 01 10 11,那么生成的四叉树就会像:
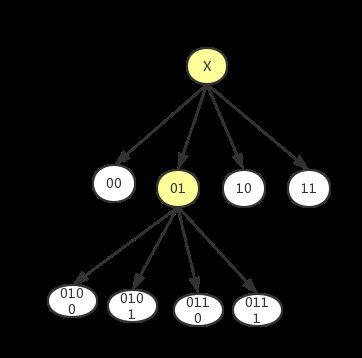
我们在查找到目标结点时,根据其编码获取到其周边八个结点的编码,再获取各个周边结点内的位置点。
嗯,这种通过编码来确定周边格子的方式确实跟 GeoHash 是相同的,但不要混淆了他们查找原理上的截然不同:
- GeoHash 本质上是通过格子编码将二维信息用一维来表示,其查找原理从根本上来说是二叉树(B树),在查找时会根据格子编码选择两个方向之一继续精确,查询效率准确来说是 log2N;
- 四叉树保留了其二维查找的特性,其查找会根据其 x,y 选择四个方向之一继续查找,忽略方向选择时的计算,其查询效率应该是 log4N;
我们可以使用此方法来继续优化四叉树,给结点添加一个“编号”属性即可,由于时(bo)间(zhu)关(fan)系(lan),这里不再实现了。
小结
由于 C 语言的高效率,由它实现的四叉树效率极高。 进行十万数据的插入和一次查询总操作为 7毫秒。在数据量更大的插入时,因为要进行结点的多次分裂,效率会有所下降,进行了8百万数据的测试插入需要两分钟多一些(16年的 mac pro),至于查询,都是一些内存寻址操作,时间可以忽略不计了。 更大量级的测试就不跑了,跑的时候散热风扇速转系统温度迅速上升
不过这么高的效率是因为这些都是内存操作,真正的数据库中数据肯定是要落地的,那时候更多的就是些磁盘和 IO 操作了,效率也会有所下降,但最终的效率和结点数据的扩展能力,与 GeoHash 相比,还是四叉树更好一些。
以上就是详解C语言实现空间索引四叉树的详细内容,更多关于C语言实现空间索引四叉树的资料请关注脚本之家其它相关文章!