关于url
URL即统一资源定位器用于定位万维网上的文档或其他数据,URL 可以由单词组成,比如 “www.baidu.com”,或者是因特网协议(IP)地址:192.168.x.xxx。大多数人在网上冲浪时,会键入网址的域名,因为名称比数字容易记忆。
通常的网址是这种形式的:scheme://host.domain:port/path/filename
- scheme - 定义因特网服务的类型。最常见的类型是 http,另外还有https及ftp
- host - 定义域主机(http 的默认主机是 www)
- domain - 定义因特网域名
- :port - 定义主机上的端口号(http 的默认端口号是 80)
- path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
- filename - 定义文档/资源的名称
比如我们在百度随意搜索,例如输入“html”,我们看到的网址是“http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=56060048_4_pg&wd=html&rsv_pq=8b388ea00001d60c&rsv_t=eb66yY%2F%2Bi26gFFYMDy%2Fj32oRkFhNPNevYoZc%2BVPhK7rYOfZg1KvGZaOcejzrMdIMre1mDQ&rsv_enter=1&inputT=1116&rsv_sug3=35&rsv_sug1=27&rsv_sug2=0&rsv_sug4=1116”,其中http://www.baidu.com是我们最为熟悉的网址,后面一大堆的字符就是参数,这些参数包括编码,搜索词,分页等等信息。我们在日常工作中也经常能用到这些参数,那么什么是参数?参数是做什么用的?
下面的内容转载自http://www.ps123.net/design/2008/21075.html。
url参数使您将用户提供的信息从浏览器传递到服务器。当服务器收到请求,而且参数被追加到请求的 URL 上时,服务器在将请求的页提供给浏览器之前,向参数提供对请求页的访问。
uRL 参数是追加到 URL 上的一个名称-值对。参数以问号 (?) 开始 并采用 name=value. 如果存在多个 URL 参数,则参数之间用 (&) 符隔开。下例显示带有两个名称-值对的 URL 参数:
http://server/path/document?name1=value1&name2=value2
在此工作流程示例中,应用程序是一家基于 Web 的店面。由于希望招徕最大范围的可能顾客,所以站点的开发人员将站点设计得可以支持多种外币。用户登录到该站点之后,他们可以选择使用哪种货币来查看所列商品的价格。
浏览器向服务器请求 report.cfm 页。该请求包括 URL 参数 Currency="euro"。Currency="euro" 变量指定所有检索到的货币数值都以欧盟的欧元为单位来显示。
服务器将 URL 参数临时存储在内存中。
report.cfm 页使用该参数来检索以欧元为单位的商品价格。这些货币数值既可以存储在反映不同货币的数据库表中,也可以从与每种商品相关联的单一货币形式转换为应用程序支持的任何货币形式。
服务器将 report.cfm 页发送给浏览器,并以请求的货币形式显示商品的价格。此用户结束会话时,服务器将清除 URL 参数的值,释放服务器内存以存放新的用户请求。
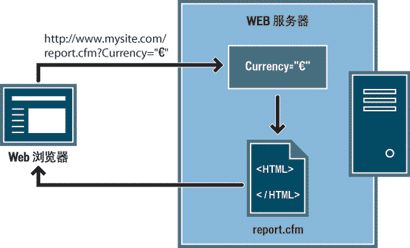
当将 HTTP 的 GET 方法与 HTML 表单一起使用时,将创建 URL 参数。GET 方法指定在提交表单时将参数值追加到 URL 请求上。
URL 参数的典型应用包括根据用户的喜好对 Web 站点进行个性化设置。例如,由用户名和密码组成的 URL 参数可用于验证用户身份,并只显示该用户已经订阅的信息。这种应用的常见示例包括一些金融 Web 站点,这些 Web 站点可根据用户以前所选的股票代码来显示个人的股票价格。Web 应用程序开发人员通常使用 URL 参数将值传递给应用程序内的变量。例如,可以将搜索语句传递给 Web 应用程序中的 SQL 变量以产生搜索结果。
我们可以把url参数通过get或post进行参数传递,但是由于各大浏览器对URL的传输的处理各不相同,浏览器在传输URl时得对URL进行编码,如果不对中文进行处理,那么中文字符经各个浏览器以自己的编码方式传输到服务器后就出现了各种编码方式,而服务器却只能以一种编码方式来对接收到的URL进行解码。这样的话,和服务器使用的编码方式一样的浏览器在使用带中文的URl时不会出现问题,其他的浏览器则会出现问题。
所以解决的办法就是在URL进行传输之前对其中的中文进行编码,使用的编码是和服务器一样的编码,假设服务器使用的编码是UTF-8,则编码语句如下:URLEncoder.encode("中文","UTF-8")。这样对中文进行编码后所有的浏览器都不会再用他们默认的编码方式对中文进行编码,因为此时浏览器看到的已经不是中文了,而是编码后的字节码。这样就避开了浏览器传输URL时编码的差异性问题。
对中文参数问题的解决方式和上面一样。但这里所指的中文参数是指以?name="中文参数"方式附在URL后,以get方法传输到服务器的这种形式,并不是以表单形式提交到服务器的。各浏览器对中文参数的处理方式和各自对URL中中文的处理方式都不相同,各浏览器之间也有差异,有的在传输之前不进行编码,有的在传输之前就已经进行了编码,情形非常复杂。
但是我们以不变应万变,都用URLEncoder.encode("中文","UTF-8")对中文参数进行编码,这样不管各浏览器怎样对中文参数进行处理,此时经过我们编码后的中文对浏览器来说就是字节码,与a、b、c等字母没有什么区别。但是服务器会用UTF-8编码形式来还原中文参数。
javascript对url常见操作:
//设置或获取对象指定的文件名或路径。
alert(window.location.pathname);
//设置或获取整个 URL 为字符串。
alert(window.location.href);
//设置或获取与 URL 关联的端口号码。
alert(window.location.port);
//设置或获取 URL 的协议部分。
alert(window.location.protocol);
//设置或获取 href 属性中在井号“#”后面的分段。
alert(window.location.hash);
//设置或获取 location 或 URL 的 hostname 和 port 号码。
alert(window.location.host);
//设置或获取 href 属性中跟在问号后面的部分。
alert(window.location.search);
获取参数:
1 <Script language="javascript"> 2 3 function GetRequest() { 4 5 6 7 var url = location.search; //获取url中"?"符后的字串 8 9 var theRequest = new Object(); 10 11 if (url.indexOf("?") != -1) { 12 13 var str = url.substr(1); 14 15 strs = str.split("&"); 16 17 for(var i = 0; i < strs.length; i ++) { 18 19 theRequest[strs[i].split("=")[0]]=(strs[i].split("=")[1]); 20 21 } 22 23 } 24 25 return theRequest; 26 27 } 28 29 </Script>
正则表达式:
1 function getQueryString(name) { 2 var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)", "i"); 3 var r = window.location.search.substr(1).match(reg); 4 if (r != null) return unescape(r[2]); return null; 5 }