Java=JDK8新特性,Lambda表达式,Stream流
Lanbda表达式
Stream流
一。Lambda表达式
也可以成为闭包,推动jdk8发布的最重要的特性
Lambda允许把函数作为一个方法的参数-函数作为参数传递进方法中
使用Lambda 表达式可以使代码变的更加简洁紧凑
格式:
Lambda的标准格式:
(参数列表)->{方法体;return 返回值;}
详情介绍:
(参数列表) 相当于方法的参数,如果没有参数,那么只写小括号即可(小括号不能省略)
->: 固定用法,代码拿着前面的参数,去做什么事情
{}: 大括号中先写计算过程,如果有返回值return 返回值;,如果没有返回值return语句可以省略
//面向对象的格式
new Thread(new Runnable() {
public void run() {
System.out.println("执行了...");
}
}).start();
//Lambda的格式
new Thread(()->{System.out.println("执行了...");}).start();Lambda的参数和返回值
public static void arraySort1(){
//1.数组
Integer[] nums = {4,5,61,7,8,9,34,56,345};
//2.对数组排序(默认升序)
//Arrays.sort(nums);
// Arrays.sort(nums, new Comparator() {
// @Override
// public int compare(Integer o1, Integer o2) {
// //降序
// return o2-o1;
// }
// });
//使用Lambda表达式修改上面冗余的代码
Arrays.sort(nums,(Integer o1, Integer o2)->{return o2-o1;});
//3.输出
System.out.println(Arrays.toString(nums));
}
public static void main(String[] args) {
//1.数组
Dog[] dogs = new Dog[4];
dogs[0] = new Dog(4,"jack",4);
dogs[1] = new Dog(3,"mary",5);
dogs[2] = new Dog(2,"ady",6);
dogs[3] = new Dog(5,"hanmeimei",3);
//2.排序
// Arrays.sort(dogs, new Comparator() {
// @Override
// public int compare(Dog o1, Dog o2) {
// //按照狗的年龄降序
// return o2.age-o1.age;
// }
// });
//使用Lambda表达式修改上面冗余的代码
Arrays.sort(dogs,(Dog o1, Dog o2)->{return o2.age-o1.age;});
//3.打印
for (Dog dog : dogs) {
System.out.println(dog);
}
}
Lambda的省略格式
a.参数类型可以省略
b.如果参数只有一个,那么小括号可以省略
c.如果{}中的代码可以写成一句代码.那么{},return关键字和分号可以同时省略(不能省略某个)
//体验一下Lambda表达式(函数式编程)优雅的写法
new Thread(()->{System.out.println("执行了...");}).start();
//省略格式
new Thread(()->System.out.println("执行了...")).start();
//使用Lambda表达式修改上面冗余的代码
Arrays.sort(nums,(Integer o1, Integer o2)->{return o2-o1;});
//省略格式
Arrays.sort(nums,(o1,o2)-> o2-o1);
//使用Lambda表达式修改上面冗余的代码
Arrays.sort(dogs,(Dog o1, Dog o2)->{return o2.age-o1.age;});
//省略格式
Arrays.sort(dogs,(o1,o2)->o2.age-o1.age);注意事项:
a.Lambda只能用于替换 有且仅有一个抽象方法的接口的匿名内部类对象,这种接口称为函数式接口
b.Lambda具有上下文推断的功能, 所以我们才会出现Lambda的省略格式
二。Stream流
唯一缺点是:代码可读性不高
流Api的接口定义在java.util.stream包下。BaseStream是最基础的接口,但是最常用的是BaseStream的一个子接口--Stream,基本上绝大多数的流式处理都是在Stream接口上定义的
count() 返回流中的元素个数 终端操作
distinct() 去除流中的重复元素, 中间操作
filter() 返回一个满足指定条件的流 中间操作
forEach() 遍历流中的每一个元素,执行action操作 终端操作
limit() 获取流中前maxsize元素 中间操作
map() 对流中的元素调用mapper方法,产生包中含这些元素的新的流
skip()
max()终端操作
min() 终端操作
sorted() 排序,按指定规则 终端操作
sorted()终端操作
这里的 filter 、 map 、 skip 都是在对函数模型进行操作,集合元素并没有真正被处理。只有当终结方法count 执行的时候,整个模型才会按照指定策略执行操作。而这得益于 Lambda 的延迟执行特性。备注: “Stream 流 ” 其实是一个集合元素的函数模型,它并不是集合,也不是数据结构,其本身并不存储任何元素(或其地址值)。
引入:传统的集合操作
public class TestDemo01 {
public static void main(String[] args) {
List list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
//1. 首先筛选所有姓张的人;
ArrayList zhangs = new ArrayList();
for (String name : list) {
if (name.startsWith("张")){
zhangs.add(name);
}
}
//2. 然后筛选名字有三个字的人;
ArrayList threes = new ArrayList();
for (String zhang : zhangs) {
if (zhang.length() == 3) {
threes.add(zhang);
}
}
//3. 最后进行对结果进行打印输出。
for (String three : threes) {
System.out.println(three);
}
}
} 循环遍历的弊端分析
Lambda注重于做什么,传统的面向对象注重于怎么做??
for (String three : threes) { //这就是传统的面向对象注重怎么做,就是形式
System.out.println(three);//这里才是我们注重做什么
}
为了解决面向对象语法复杂形式,我们引入一种新的技术:Stream 流式思想体验Stream的优雅写法
体验一下Stream流的优雅代码
list.stream().filter(s->s.startsWith("张")).filter(s->s.length()==3).forEach(s-> System.out.println(s));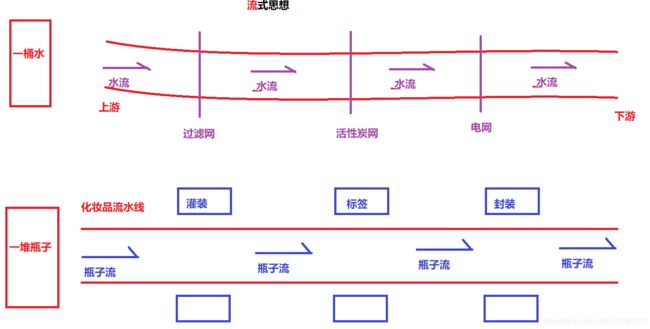
1、获取流的方式
a.Collection集合获取流
Stream s = 集合对象.stream();
b.Map集合不能直接获取流,但是可以间接获取流
map.keySet().stream(); 获取map的键流
map.values().stream(); 获取map的值流
map.entrySet().stream(); 获取Map的键值对流
c.数组获取流
Stream<数据中元素的类型> s = Stream.of(数据类型... 变量名);
public class StreamDemo01 {
public static void main(String[] args) {
//获取各种容器的流
//1.单列集合
ArrayList arr = new ArrayList();
//....添加数据
Stream s1 = arr.stream();
//2.双列集合
HashMap map = new HashMap();
Stream keyStream = map.keySet().stream(); //键流
Stream valueStream = map.values().stream();//值流
Stream> entryStream = map.entrySet().stream();//键值对流
//3.数组
Integer[] nums = {10,20,30,40};
Stream s2 = Stream.of(nums);
Stream s3 = Stream.of(11,22,33,44);
}
} Stream流中的常用方法
逐个处理:forEach
//1.获取到一个流
Stream s1 = Stream.of("jack", "tom", "rose", "lilei", "jerry");
//2.foreach 逐一处理
//使用匿名内部类
// s1.forEach(new Consumer() { //
// @Override
// public void accept(String s) {
// System.out.println(s);
// }
// });
//使用Lambda
// s1.forEach((String s)->{System.out.println(s);});
//使用Lambda的省略格式
s1.forEach(s -> System.out.println(s)); 统计个数:count
//3.count 统计个数
long count = s1.count();
System.out.println("流中有多少个元素:"+count);过滤filter
//4.filte 过滤方法
//匿名内部类
// Stream s2 = s1.filter(new Predicate() {
// @Override
// public boolean test(String s) {
// //我们只想要 长度大于4的字符串
// return s.length() > 4;
// }
// });
//Lambda
Stream s2 = s1.filter(s -> s.length() > 4);
System.out.println(s2.count()); 取前几个:limit
//5.limit 取前几个
Stream s3 = s1.limit(3);
s3.forEach(s-> System.out.println(s)); 跳过前几个:skip
//6.skip 跳过前几个
Stream s4 = s1.skip(2);
s4.forEach(s-> System.out.println(s)); 映射方法:map
map方法是将流中每个元素,经过某种算法,变成另外一个元素
//7.map 映射
// Stream s5 = s1.map(new Function() {
// @Override
// public Integer apply(String s) {
// return s.length();
// }
// });
//Lambda改写
Stream s5 = s1.map(s->s.length());
s5.forEach(s-> System.out.println(s)); 静态方法合并流:concat
public static Stream concat(Stream s1,Stream s2);
//8.concat 静态方法,合并两个流
Stream ss1 = Stream.of("jack","rose");
Stream ss2 = Stream.of("tom","lucy");
//静态方法
Stream sss = Stream.concat(ss1,ss2);
sss.forEach(s-> System.out.println(s));
注意:
a.如果是两个以上流的合并,需要多次两两合并
b.如果两个流的泛型不一致也可以合并,合并之后新流的泛型是他们共同的父类(不知道其父类,写Object) 集合元素的处理(Stream方式)
//使用传统集合遍历方式
public class StreamDemo04 {
public static void main(String[] args) {
List one = new ArrayList<>();
one.add("迪丽热巴");
one.add("苏星河");
one.add("老子");
one.add("庄子");
one.add("孙子");
one.add("洪七公");
List two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("赵丽颖");
two.add("张二狗");
two.add("张天爱");
two.add("张三");
//按照求操作集合(使用传统的for循环)
// 1. 第一个队伍只要名字为3个字的成员姓名;
ArrayList one1 = new ArrayList();
for (String name : one) {
if (name.length() == 3) {
one1.add(name);
}
}
// 2. 第一个队伍筛选之后只要前3个人;
ArrayList one2 = new ArrayList();
for (int i = 0; i < 3; i++) {
String name = one1.get(i);
one2.add(name);
}
// 3. 第二个队伍只要姓张的成员姓名;
ArrayList two1 = new ArrayList();
for (String name : two) {
if (name.startsWith("张")){
two1.add(name);
}
}
// 4. 第二个队伍筛选之后不要前2个人;
ArrayList two2 = new ArrayList();
for (int i = 2; i < two1.size(); i++) {
String name = two1.get(i);
two2.add(name);
}
// 5. 将两个队伍合并为一个队伍;
ArrayList all = new ArrayList();
// all.addAll(one2);
// all.addAll(two2);
for (String name : one2) {
all.add(name);
}
for (String name : two2) {
all.add(name);
}
// 6. 根据姓名创建 Person 对象;
ArrayList persons = new ArrayList();
for (String name : all) {
Person p = new Person(name);
persons.add(p);
}
// 7. 打印整个队伍的Person对象信息。
for (Person person : persons) {
System.out.println(person);
}
}
}
使用Stream流的方式
public class StreamDemo05 {
public static void main(String[] args) {
List one = new ArrayList<>();
one.add("迪丽热巴");
one.add("宋远桥");
one.add("老子");
one.add("庄子");
one.add("孙子");
one.add("洪七公");
List two = new ArrayList<>();
two.add("古力娜扎");
two.add("张无忌");
two.add("赵丽颖");
two.add("张二狗");
two.add("张天爱");
two.add("张三");
// 1. 第一个队伍只要名字为3个字的成员姓名;
// 2. 第一个队伍筛选之后只要前3个人;
Stream s1 = one.stream().filter(s -> s.length() == 3).limit(3);
// 3. 第二个队伍只要姓张的成员姓名;
// 4. 第二个队伍筛选之后不要前2个人;
Stream s2 = two.stream().filter(s -> s.startsWith("张")).skip(2);
// 5. 将两个队伍合并为一个队伍;
Stream ss = Stream.concat(s1, s2);
// 6. 根据姓名创建 Person 对象; string -- person
Stream ps = ss.map(s -> new Person(s));
// 7. 打印整个队伍的Person对象信息
ps.forEach(p-> System.out.println(p));
}
}
函数拼接和终结
函数拼接方法: 由于这种方法返回的还是流对象,故支持链式编程
调用该方法之后,返回还是一个流对象
有:filter,limit,skip,map,concat
终结方法: 由于终结方法没有返回或者返回的不是流,那么不支持链式编程,并且当某个流调用终结方法之后,该流就关闭了,不能继续调用其他任何方法
调用该方法之后,返回值不是流或者无返回值
有:forEach,count收集Stream
可以把流收集到集合中,调用流的collect方法即可
可以把流收集到数组中,调用流的toArray方法即可
public class StreamDemo03 {
public static void main(String[] args) {
//收集流中的结果
Stream s1 = Stream.of(1,2,3,4,5);
//....对流进行各种操作
//1.将流中的结果收集到集合中
List list = s1.collect(Collectors.toList());
System.out.println(list);
Set set = s1.collect(Collectors.toSet());
System.out.println(set);
//2.将流中的结果收集到数组中
Object[] objs = s1.toArray();
for (Object obj : objs) {
System.out.println(obj);
}
}
}
注意:
a.一个流只能收集一次(第二次收集会报错!!!)
b.如果收集到数组中某个收集到Object数组
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
补充:
数据查找:
allMatch()Stream提供的方法,该方法判断流中的元素是否全部符合某一个条件,返回结果为boolean值,如果是,返回true,否则flase
anyMatch()Stream提供的方法,该方法会判断流中的元素是否有符合某一条件,只要有一个元素符合条件就返回true,如果没有符合条件的元素就返回false
noneMathch():stream接口提供的方法》 该方法会判断流中所有的元素是否都不符合某一个条件,这个方法的逻辑和 allmatch正好相反
findFirst()stream接口提供的方法,这个方法会返回符合条件的第一个元素、这个方法返回值不是boolean,而是一个optional对象
Collectors类:
https://www.jianshu.com/p/7eaa0969b424
https://blog.csdn.net/Alice_qixin/article/details/87169586
将流中的数据转成集合类型: toList、toSet、toMap、toCollection
将流中的数据(字符串)使用分隔符拼接在一起:joining
对流中的数据求最大值maxBy、最小值minBy、求和summingInt、求平均值averagingDouble
对流中的数据进行映射处理 mapping
对流中的数据分组:groupingBy、partitioningBy
对流中的数据累计计算:reducing
请使用Lambda表达式调用Collections的sort()方法,可以实现对一个List集合进行:降序排序。
编写main()方法,在main()中按以下步骤编写代码:
1. 定义一个List集合,并存储以下数据:
“cab”
“bac”
“acb”
“cba”
“bca”
“abc”
2. 使用Lambda表达式调用Collections的sort()方法对集合进行降序排序。
3. 排序后向控制台打印集合的所有元素。
public static void main(String[] args) {
List strings = new ArrayList<>();
strings.add("cab");
strings.add("bac");
strings.add("acb");
strings.add("cba");
strings.add("bca");
strings.add("abc");
//
Collections.sort(strings,(o1,o2)->o2.compareToIgnoreCase(o1));
System.out.println(strings);
}
关于其他:
https://blog.csdn.net/Alice_qixin/article/details/87169586
https://www.jianshu.com/p/232fc8acedba
https://blog.csdn.net/qq_20989105/article/details/81234175
https://blog.csdn.net/qq_37415950/article/details/80183654