谋而后动:解读数仓计划生成中行数估算和路径生成的奥秘
摘要: 孙子兵法云:“谋定而后动,知止而有得”,做任何事一定要进行谋划部署,做好准备,这样才能利于这件事的成功,切不可莽撞而行。同样,GaussDB(DWS)执行查询语句也会按照预定的计划来执行,给定硬件环境的情况下,执行的快慢全凭计划的好坏,那么一条查询语句的计划是如何制定的呢,本文将为大家解读计划生成中行数估算和路径生成的奥秘。
本文分享自华为云社区《GaussDB(DWS)计划生成原理揭秘(一)》,原文作者:Jugg 。
GaussDB(DWS)优化器的计划生成方法有两种,一是动态规划,二是遗传算法,前者是使用最多的方法,也是本系列文章重点介绍对象。一般来说,一条SQL语句经语法树(ParseTree)生成特定结构的查询树(QueryTree)后,从QueryTree开始,才进入计划生成的核心部分,其中有一些关键步骤:
- 设置初始并行度(Dop)
- 查询重写
- 估算基表行数
- 估算关联表(JoinRel)
- 路径生成,生成最优Path
- 由最优Path创建用于执行的Plan节点
- 调整最优并行度
本文主要关注3、4、5,这些步骤对一个计划生成影响比较大,其中主要涉及行数估算、路径选择方法和代价估算(或称Cost估算),Cost估算是路径选择的依据,每个算子对应一套模型,属于较为独立的部分,后续文章再讲解。Plan Hint会在3、4、5等诸多步骤中穿插干扰计划生成,其详细的介绍读者可参阅博文:GaussDB(DWS)性能调优系列实现篇六:十八般武艺Plan hint运用。
先看一个简单的查询语句:
select count(*) from t1 join t2 on t1.c2 = t2.c2 and t1.c1 > 100 and (t1.c3 is not null or t2.c3 is not null);GaussDB(DWS)优化器给出的执行计划如下:
postgres=# explain verbose select count(*) from t1 join t2 on t1.c2 = t2.c2 and t1.c1 > 100 and (t1.c3 is not null or t2.c3 is not null);
QUERY PLAN
--------------------------------------------------------------------------------------------------------------
id | operation | E-rows | E-distinct | E-memory | E-width | E-costs
----+--------------------------------------------------+--------+------------+----------+---------+---------
1 | -> Aggregate | 1 | | | 8 | 111.23
2 | -> Streaming (type: GATHER) | 4 | | | 8 | 111.23
3 | -> Aggregate | 4 | | 1MB | 8 | 101.23
4 | -> Hash Join (5,7) | 3838 | | 1MB | 0 | 98.82
5 | -> Streaming(type: REDISTRIBUTE) | 1799 | 112 | 2MB | 10 | 46.38
6 | -> Seq Scan on test.t1 | 1799 | | 1MB | 10 | 9.25
7 | -> Hash | 1001 | 25 | 16MB | 8 | 32.95
8 | -> Streaming(type: REDISTRIBUTE) | 1001 | | 2MB | 8 | 32.95
9 | -> Seq Scan on test.t2 | 1001 | | 1MB | 8 | 4.50
Predicate Information (identified by plan id)
-----------------------------------------------------------------
4 --Hash Join (5,7)
Hash Cond: (t1.c2 = t2.c2)
Join Filter: ((t1.c3 IS NOT NULL) OR (t2.c3 IS NOT NULL))
6 --Seq Scan on test.t1
Filter: (t1.c1 > 100)通常一条查询语句的Plan都是从基表开始,本例中基表t1有多个过滤条件,从计划上看,部分条件下推到基表上了,部分条件没有下推,那么它的行数如何估出来的呢?我们首先从基表的行数估算开始。
一、基表行数估算
如果基表上没有过滤条件或者过滤条件无法下推到基表上,那么基表的行数估算就是统计信息中显示的行数,不需要特殊处理。本节考虑下推到基表上的过滤条件,分单列和多列两种情况。
1、单列过滤条件估算思想
基表行数估算目前主要依赖于统计信息,统计信息是先于计划生成由Analyze触发收集的关于表的样本数据的一些统计平均信息,如t1表的部分统计信息如下:
postgres=# select tablename, attname, null_frac, n_distinct, n_dndistinct, avg_width, most_common_vals, most_common_freqs from pg_stats where tablename = 't1';
tablename | attname | null_frac | n_distinct | n_dndistinct | avg_width | most_common_vals | most_common_freqs
-----------+---------+-----------+------------+--------------+-----------+------------------+-------------------
t1 | c1 | 0 | -.5 | -.5 | 4 | |
t1 | c2 | 0 | -.25 | -.431535 | 4 | |
t1 | c3 | .5 | 1 | 1 | 6 | {gauss} | {.5}
t1 | c4 | .5 | 1 | 1 | 8 | {gaussdb} | {.5}
(4 rows)各字段含义如下:
- null_frac:空值比例
- n_distinct:全局distinct值,取值规则:正数时代表distinct值,负数时其绝对值代表distinct值与行数的比
- n_dndistinct:DN1上的distinct值,取值规则与n_distinct类似
- avg_width:该字段的平均宽度
- most_common_vals:高频值列表
- most_common_freqs:高频值的占比列表,与most_common_vals对应
从上面的统计信息可大致判断出具体的数据分布,如t1.c1列,平均宽度是4,每个数据的平均重复度是2,且没有空值,也没有哪个值占比明显高于其他值,即most_common_vals(简称MCV)为空,这个也可以理解为数据基本分布均匀,对于这些分布均匀的数据,则分配一定量的桶,按等高方式划分了这些数据,并记录了每个桶的边界,俗称直方图(Histogram),即每个桶中有等量的数据。
有了这些基本信息后,基表的行数大致就可以估算了。如t1表上的过滤条件"t1.c1>100",结合t1.c1列的均匀分布特性和数据分布的具体情况:
postgres=# select histogram_bounds from pg_stats where tablename = 't1' and attname = 'c1';
histogram_bounds
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------------------------------------------------------------------------------------------------------------------
{1,10,20,30,40,50,60,70,80,90,100,110,120,130,140,150,160,170,180,190,200,210,220,230,240,250,260,270,280,290,300,310,320,330,340,350,360,370,380,390,400,410,420,430,440,450,460,470,480,490,500,510,520,530,540,550,560,570,580,590,600,610,62
0,630,640,650,660,670,680,690,700,710,720,730,740,750,760,770,780,790,800,810,820,830,840,850,860,870,880,890,900,910,920,930,940,950,960,970,980,990,1000}
(1 row)可知,t1.c1列的数据分布在1~1000之间,而每两个边界中含有的数据量是大致相同的(这里是根据样本统计的统计边界),先找到100在这个直方图中的大概位置,在这里它是某个桶的边界(有时在桶的内部),那么t1.c1>100的数据占比大约就是边界100之后的那些桶的数量的占比,这里的占比也称为选择率,即经过这个条件后,被选中的数据占比多少,因此由“t1.c >100“过滤之后的行数就可以估算出来了。
以上就是估算基表行数的基本思想。一般地,
有统计信息:
- 等值条件
1)对比MCV,如果满足过滤条件,则选择率(即most_common_freqs)累加;
2)对Histogram数据,按distinct值个数粗略估算选择率; - 范围条件
1)对比MCV数据,如果满足过滤条件,则选择率累加;
2)对Histogram数据,按边界位置估算选择率; - 不等值条件:可转化为等值条件估算
无统计信息:
- 等值条件:比如过滤条件是:“substr(c3, 1, 5) = 'gauss'”,c3列有统计信息,但substr(c3, 1, 5)没有统计信息。那如何估算这个条件选择率呢?一个简单的思路是,如果substr(c3, 1, 5) 的distinct值已知的话,则可粗略假设每个distinct值的重复度一致,于是选择率也可以估算出来;在GaussDB(DWS)中,可通过设置cost_model_version=1开启表达式distinct值估算功能;
- 范围条件:此时仅仅知道substr(c3, 1, 5)的distinct值是无法预估选择率的,对于无法估算的表达式,可通过qual_num_distinct进行设置指定相应distinct值;
- 不等值条件:可转化为等值条件估算
2. 多列过滤条件估算思想
比如t1表有两个过滤条件:t1.c1 = 100 and t1.c3 = 'gauss',那么如何估算该两列的综合选择率?在GaussDB(DWS)中,一般性方法有两个:
仅有单列统计信息
该情况下,首先按单列统计信息计算每个过滤条件的选择率,然后选择一种方式来组合这些选择率,选择的方式可通过设置cost_param来指定。为何需要选择组合方式呢?因为实际模型中,列与列之间是有一定相关性的,有的场景中相关性比较强,有的场景则比较弱,相关性的强弱决定了最后的行数。
该参数的意义和使用介绍可参考:GaussDB(DWS)性能调优系列实战篇五:十八般武艺之路径干预。
有多列组合统计信息
如果过滤的组合列的组合统计信息已经收集,则优化器会优先使用组合统计信息来估算行数,估算的基本思想与单列一致,即将多列组合形式上看成“单列”,然后再拿多列的统计信息来估算。
比如,多列统计信息有:((c1, c2, c4)),((c1, c2)),双括号表示一组多列统计信息:
- 若条件是:c1 = 7 and c2 = 3 and c4 = 5,则使用((c1, c2, c4))
- 若条件是:c1 = 7 and c2 = 3,则使用((c1, c2))
- 若条件是:c1 = 7 and c2 = 3 and c5 = 6,则使用((c1, c2))
多列条件匹配多列统计信息的总体原则是:
- 多列统计信息的列组合需要被过滤条件的列组合包含;
- 所有满足“条件1”的多列统计信息中,选取“与过滤条件的列组合的交集最大“的那个多列统计信息。
对于无法匹配多列统计信息列的过滤条件,则使用单列统计信息进行估算。
3. 值得注意的地方
- 目前使用多列统计信息时,不支持范围类条件;如果有多组多列条件,则每组多列条件的选择率相乘作为整体的选择率。
- 上面说的单列条件估算和多列条件估算,适用范围是每个过滤条件中仅有表的一列,如果一个过滤条件是多列的组合,比如 “t1.c1 < t1.c2”,那么一般而言单列统计信息是无法估算的,因为单列统计信息是相互独立的,无法确定两个独立的统计数据是否来自一行。目前多列统计信息机制也不支持基表上的过滤条件涉及多列的场景。
- 无法下推到基表的过滤条件,则不纳入基表行数估算的考虑范畴,如上述:t1.c3 is not null or t2.c3 is not null,该条件一般称为JoinFilter,会在创建JoinRel时进行估算。
- 如果没有统计信息可用,那就给默认选择率了。
二、JoinRel行数估算
基表行数估算完,就可以进入表关联阶段的处理了。那么要关联两个表,就需要一些信息,如基表行数、关联之后的行数、关联的方式选择(也叫Path的选择,请看下一节),然后在这些方式中选择代价最小的,也称之为最佳路径。对于关联条件的估算,也有单个条件和多个条件之分,优化器需要算出所有Join条件和JoinFilter的综合选择率,然后给出估算行数,先看单个关联条件的选择率如何估算。
1. 一组Join条件估算思想
与基表过滤条件估算行数类似,也是利用统计信息来估算。比如上述SQL示例中的关联条件:t1.c2 = t2.c2,先看t1.c2的统计信息:
postgres=# select tablename, attname, null_frac, n_distinct, n_dndistinct, avg_width, most_common_vals, most_common_freqs
from pg_stats where tablename = 't1' and attname = 'c2';
tablename | attname | null_frac | n_distinct | n_dndistinct | avg_width | most_common_vals | most_common_freqs
-----------+---------+-----------+------------+--------------+-----------+------------------+-------------------
t1 | c2 | 0 | -.25 | -.431535 | 4 | |
(1 row)t1.c2列没有MCV值,平均每个distinct值大约重复4次且是均匀分布,由于Histogram中保留的数据只是桶的边界,并不是实际有哪些数据(重复收集统计信息,这些边界可能会有变化),那么实际拿边界值来与t2.c2进行比较不太实际,可能会产生比较大的误差。此时我们坚信一点:“能关联的列与列是有相同含义的,且数据是尽可能有重叠的”,也就是说,如果t1.c2列有500个distinct值,t2.c2列有100个distinct值,那么这100个与500个会重叠100个,即distinct值小的会全部在distinct值大的那个表中出现。虽然这样的假设有些苛刻,但很多时候与实际情况是较吻合的。回到本例,根据统计信息,n_distinct显示负值代表占比,而t1表的估算行数是2000:
postgres=# select reltuples from pg_class where relname = 't1';
reltuples
-----------
2000
(1 row)于是,t1.c2的distinct是0.25 * 2000 = 500,类似地,根据统计信息,t2.c2的distinct是100:
postgres=# select tablename, attname, null_frac, n_distinct, n_dndistinct from pg_stats where tablename = 't2' and attname = 'c2';
tablename | attname | null_frac | n_distinct | n_dndistinct
-----------+---------+-----------+------------+--------------
t2 | c2 | 0 | 100 | -.39834
(1 row)那么,t1.c2的distinct值是否可以直接用500呢?答案是不能。因为基表t1上还有个过滤条件"t1.c1 > 100",当前关联是发生在基表过滤条件之后的,估算的distinct应该是过滤条件之后的distinct有多少,不应是原始表上有多少。那么此时可以采用各种假设模型来进行估算,比如几个简单模型:Poisson模型(假设t1.c1与t1.c2相关性很弱)或完全相关模型(假设t1.c1与t1.c2完全相关),不同模型得到的值会有差异,在本例中,"t1.c1 > 100"的选择率是 8.995000e-01,则用不同模型得到的distinct值会有差异,如下:
- Poisson模型(相关性弱模型):500 * (1.0 - exp(-2000 * 8.995000e-01 / 500)) = 486
- 完全相关模型:500 * 8.995000e-01 = 450
- 完全不相关模型:500 * (1.0 - pow(1.0 - 8.995000e-01, 2000 / 500)) = 499.9,该模型可由概率方法得到,感兴趣读者可自行尝试推导
- 实际过滤后的distinct:500,即c2与c1列是不相关的
postgres=# select count(distinct c2) from t1 where c1 > 100;
count
-------
500
(1 row)估算过滤后t1.c2的distinct值,那么"t1.c2 = t2.c2"的选择率就可以估算出来了: 1 / distinct。
以上是任一表没有MCV的情况,如果t1.c2和t2.c2都有MCV,那么就先比较它们的MCV,因为MCV中的值都是有明确占比的,直接累计匹配结果即可,然后再对Histogram中的值进行匹配。
2. 多组Join条件估算思想
表关联含有多个Join条件时,与基表过滤条件估算类似,也有两种思路,优先尝试多列统计信息进行选择率估算。当无法使用多列统计信息时,则使用单列统计信息按照上述方法分别计算出每个Join条件的选择率。那么组合选择率的方式也由参数cost_param控制,详细参考GaussDB(DWS)性能调优系列实战篇五:十八般武艺之路径干预。
另外,以下是特殊情况的选择率估算方式:
- 如果Join列是表达式,没有统计信息的话,则优化器会尝试估算出distinct值,然后按没有MCV的方式来进行估算;
- Left Join/Right Join需特殊考虑以下一边补空另一边全输出的特点,以上模型进行适当的修改即可;
- 如果关联条件是范围类的比较,比如"t1.c2 < t2.c2",则目前给默认选择率:1 / 3;
3. JoinFilter的估算思想
两表关联时,如果基表上有一些无法下推的过滤条件,则一般会变成JoinFilter,即这些条件是在Join过程中进行过滤的,因此JoinFilter会影响到JoinRel的行数,但不会影响基表扫描上来的行数。严格来说,如果把JoinRel看成一个中间表的话,那么这些JoinFilter是这个中间表的过滤条件,但JoinRel还没有产生,也没有行数和统计信息,因此无法准确估算。然而一种简单近似的方法是,仍然利用基表,粗略估算出这个JoinFilter的选择率,然后放到JoinRel最终行数估算中去。
三、路径生成
有了前面两节的行数估算的铺垫,就可以进入路径生成的流程了。何为路径生成?已知表关联的方式有多种(比如 NestLoop、HashJoin)、且GaussDB(DWS)的表是分布式的存储在集群中,那么两个表的关联方式可能就有多种了,而我们的目标就是,从这些给定的基表出发,按要求经过一些操作(过滤条件、关联方式和条件、聚集等等),相互组合,层层递进,最后得到我们想要的结果。这就好比从基表出发,寻求一条最佳路径,使得我们能最快得到结果,这就是我们的目的。本节我们介绍Join Path和Aggregate Path的生成。
1. Join Path的生成
GaussDB(DWS)优化器选择的基本思路是动态规划,顾名思义,从某个开始状态,通过求解中间状态最优解,逐步往前演进,最后得到全局的最优计划。那么在动态规划中,总有一个变量,驱动着过程演进。在这里,这个变量就是表的个数。本节,我们以如下SQL为例进行讲解:
select count(*) from t1, t2 where t1.c2 = t2.c2 and t1.c1 < 800 and exists (select c1 from t3 where t1.c1 = t3.c2 and t3.c1 > 100);该SQL语句中,有三个基表t1, t2, t3,三个表的分布键都是c1列,共有两个关联条件:
- t1.c2 = t2.c2, t1与t2关联
- t1.c1 = t3.c2, t1与t3关联
为了配合分析,我们结合日志来帮助大家理解,设置如下参数,然后在执行语句:
set logging_module='on(opt_join)';
set log_min_messages=debug2;第一步,如何获取t1和t2的数据
首先,如何获取t1和t2的数据,比如 Seq Scan、Index Scan等,由于本例中,我们没有创建Index,那选择只有Seq Scan了。日志片段显示:

我们先记住这三组Path名称:path_list,cheapest_startup_path,cheapest_total_path,后面两个就对应了动态规划的局部最优解,在这里是一组集合,统称为最优路径,也是下一步的搜索空间。path_list里面存放了当前Rel集合上的有价值的一组候选Path(被剪枝调的Path不会放在这里),cheapest_startup_path代表path_list中启动代价最小的那个Path,cheapest_total_path代表path_list里一组总代价最小的Path(这里用一组主要是可能存在多个维度分别对应的最优Path)。t2表和t3表类似,最优路径都是一条Seq Scan。有了所有基表的Scan最优路径,下面就可以选择关联路径了。
第二步,求解(t1, t2)关联的最优路径
t1和t2两个表的分布键都是c1列,但Join列都是c2列,那么理论上的路径就有:(放在右边表示作为内表)
- Broadcast(t1) join t2
- t1 join Broadcast(t2)
- Broadcast(t2) join t1
- t2 join Broadcast(t1)
- Redistribute(t1) join Redistribute(t2)
- Redistribute(t2) join Redistribute(t1)
然后每一种路径又可以搭配不同的Join方法(NestLoop、HashJoin、MergeJoin),总计18种关联路径,优化器需要在这些路径中选择最优路径,筛选的依据就是路径的代价(Cost)。优化器会给每个算子赋予代价,比如 Seq Scan,Redistribute,HashJoin都有代价,代价与数据规模、数据特征、系统资源等等都有关系,关于代价如何估算,后续文章再分析,本节只关注由这些代价怎么选路径。由于代价与执行时间成正比,优化器的目标是选择代价最小的计划,因此路径选择也是一样。路径代价的比较思路大致是这样,对于产生的一个新Path,逐个比较该新Path与path_list中的path,若total_cost很相近,则比较startup cost,如果也差不多,则保留该Path到path_list中去;如果新路径的total_cost比较大,但是startup_cost小很多,则保留该Path,此处略去具体的比较过程,直接给出Path的比较结果:

由此看出,总代价最小的路径是两边做重分布、t1作为内表的路径。
第三步,求解(t1, t3)关联的最优路径
t1和t3表的关联条件是:t1.c1 = t3.c2,因为t1的Join列是分布键c1列,于是t1表上不需要加Redistribute;由于t1和t3的Join方式是Semi Join,外表不能Broadcast,否者可能会产生重复结果;另外还有一类Unique Path选择(即t3表去重),那么可用的候选路径大致如下:
- t1 semi join Redistribute(t3)
- Redistribute(t3) right semi join t1
- t1 join Unique(Redistribute(t3))
- Unique(Redistribute(t3)) join t1
由于只有一边需要重分布且可以进行重分布,则不选Broadcast,因为相同数据量时Broadcast的代价一般要高于重分布,提前剪枝掉。再把Join方法考虑进去,于是优化器给出了最终选择:
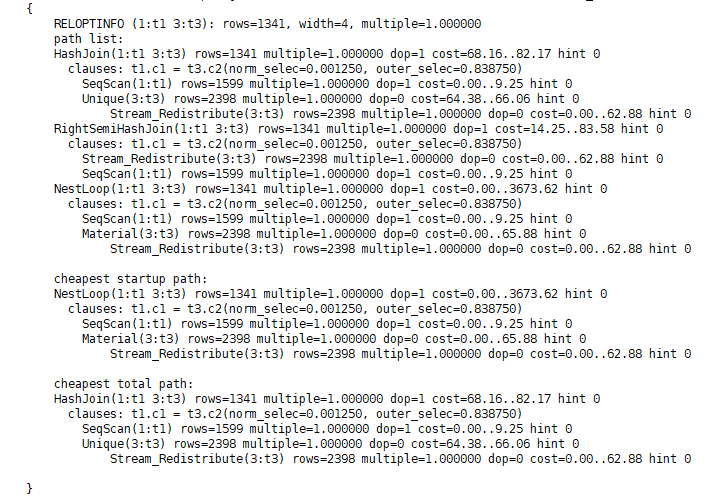
此时的最优计划是选择了内表Unique Path的路径,即t3表先去重,然后在走Inner Join过程。
第四步,求解(t1,t2,t3)关联的最优路径
有了前面两步的铺垫,三个表关联的思路是类似的,形式上是分解成两个表先关联,然候在与第三个表关联,实际操作上是直接取出所有两表关联的JoinRel,然后逐个增加另一个表,尝试关联,选择的方式如下:
- JoinRel(t1, t2) join t3:
(t1, t2)->(cheapest_startup_path + cheapest_total_path) join t3->(cheapest_startup_path + cheapest_total_path) - JoinRel(t1, t3) join t2:
(t1, t3)->(cheapest_startup_path + cheapest_total_path) join t2->(cheapest_startup_path + cheapest_total_path) - JoinRel(t2, t3) join t1:由于没有(t2, t3)关联,所以此种情况不存在
每取一对内外表的Path进行Join时,也会判断是否需要重分布、是否可以去重,选择关联方式,比如JoinRel(t1, t2) join t3时,也会尝试对t3表进行去重的Path,因为这个Join本质仍然是Semi Join。下图是选择过程中产生的部分有价值的候选路径(篇幅所限,只截取了一部分):
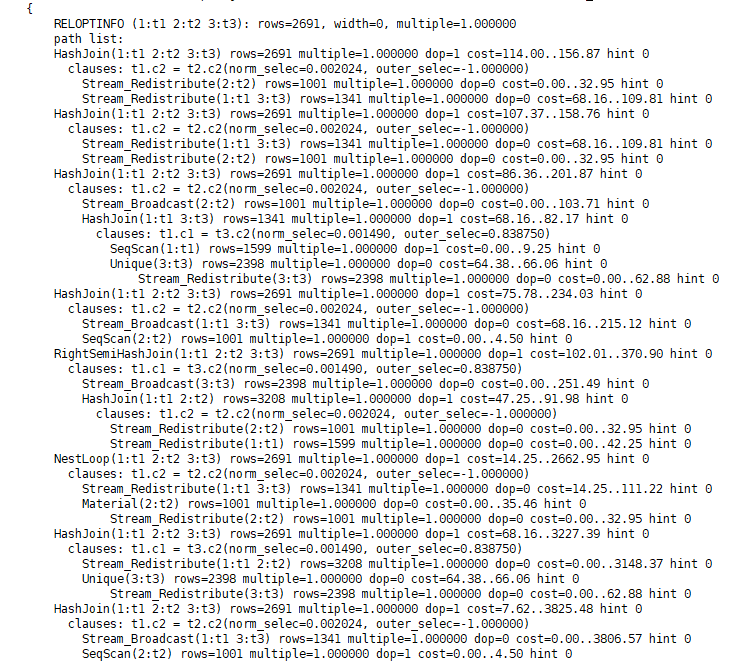
优化器在这些路径中,选出了如下的最优路径:
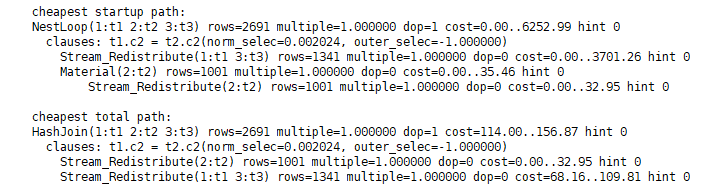
对比实际的执行计划,二者是一样的(对比第4层HashJoin的“E-costs“是一样的):

从这个过程可以大致感受到path_list有可能会发生一些膨胀,如果path_list中路径太多了,则可能会导致cheapest_total_path有多个,那么下一级的搜索空间也就会变的很大,最终会导致计划生成的耗时增加。关于Join Path的生成,作以下几点说明:
- Join路径的选择时,会分两个阶段计算代价,initial和final代价,initial代价快速估算了建hash表、计算hash值以及下盘的代价,当initial代价已经比path_list中某个path大时,就提前剪枝掉该路径;
- cheapest_total_path有多个原因:主要是考虑到多个维度下,代价很相近的路径都有可能是下一层动态规划的最佳选择,只留一个可能得不到整体最优计划;
- cheapest_startup_path记录了启动代价最小的一个,这也是预留了另一个维度,当查询语句需要的结果很少时,有一个启动代价很小的Path,但总代价可能比较大,这个Path有可能会成为首选;
- 由于剪枝的原因,有些情况下,可能会提前剪枝掉某个Path,或者这个Path没有被选为cheapest_total_path或cheapest_startup_path,而这个Path是理论上最优计划的一部分,这样会导致最终的计划不是最优的,这种场景一般概率不大,如果遇到这种情况,可尝试使用Plan Hint进行调优;
- 路径生成与集群规模大小、系统资源、统计信息、Cost估算都有紧密关系,如集群DN数影响着重分布的倾斜性和单DN的数据量,系统内存影响下盘代价,统计信息是行数和distinct值估算的第一手数据,而Cost估算模型在整个计划生成中,是选择和淘汰的关键因素,每个JoinRel的行数估算不准,都有可能影响着最终计划。因此,相同的SQL语句,在不同集群或者同样的集群不同统计信息,计划都有可能不一样,如果路径发生一些变化可通过分析Performance信息和日志来定位问题,Performance详解可以参考博文:GaussDB(DWS)的explain performance详解。
- 如果设置了Random Plan模式,则动态规划的每一层cheapest_startup_path和cheapest_total_path都是从path_list中随机选取的,这样保证随机性。
2. Aggregate Path的生成
一般而言,Aggregate Path生成是在表关联的Path生成之后,且有三个主要步骤(Unique Path的Aggregate在Join Path生成的时候就已经完成了,但也会有这三个步骤):先估算出聚集结果的行数,然后选择Path的方式,最后创建出最优Aggregate Path。前者依赖于统计信息和Cost估算模型,后者取决于前者的估算结果、集群规模和系统资源。Aggregate行数估算主要根据聚集列的distinct值来组合,我们重点关注Aggregate行数估算和最优Aggregate Path选择。
2.1 Aggregate行数估算
以如下SQL为例进行说明:
select t1.c2, t2.c2, count(*) cnt from t1, t2 where t1.c2 = t2.c2 and t1.c1 < 500 group by t1.c2, t2.c2;该语句先是两表关联,基表上有过滤条件,然后求取两列的GROUP BY结果。这里的聚集列有两个,t1.c2和t2.c2,在看一下系统表中给出的原始信息:
postgres=# select tablename, attname, null_frac, n_distinct, n_dndistinct from pg_stats where (tablename = 't1' or tablename = 't2') and attname = 'c2';
tablename | attname | null_frac | n_distinct | n_dndistinct
-----------+---------+-----------+------------+--------------
t1 | c2 | 0 | -.25 | -.431535
t2 | c2 | 0 | 100 | -.39834
(2 rows)统计信息显示t1.c2和t2.c2的原始distinct值分别是-0.25和100,-0.25转换为绝对值就是0.25 * 2000 = 500,那它们的组合distinct是不是至少应该是500呢?答案不是。因为Aggregate对JoinRel(t1, t2)的结果进行聚集,而系统表中统计信息是原始信息(没有任何过滤)。这时需要把Join条件和过滤条件都考虑进去,如何考虑呢?首先看过滤条件 “t1.c1<500“可能会过滤掉一部分t1.c2,那么就会有个选择率(此时我们称之为FilterRatio),然后Join条件"t1.c2 = t2.c2"也会有一个选择率(此时我们称之为JoinRatio),这两个Ratio都是介于[0, 1]之间的一个数,于是估算t1.c2的distinct时这两个Ratio影响都要考虑。如果不同列之间选择Poisson模型,相同列之间用完全相关模型,则t1.c2的distinct大约是这样:
distinct(t1.c2) = Poisson(d0, ratio1, nRows) * ratio2
其中d0表示基表中原始distinct,ratio1代表使用Poisson模型的Ratio,ratio2代表使用完全相关模型的Ratio,nRows是基表行数。如果需要定位分析问题,这些Ratio可以从日志中查阅,如下设置后在运行SQL语句:
set logging_module='on(opt_card)';
set log_min_messages=debug3;本例中,我们从日志中可以看到t1表上的两个Ratio:

在看t2.c2,这一列原始distinct是100,而从上面日志中可以看出t2表的数据全匹配上了(没有Ratio),那么Join完t2.c2的distinct也是100。此时不能直接组合t1.c2和t2.c2,因为"t1.c2 = t2.c2“暗含了这两个列的值是一样的,那就是说它们等价,于是只需考虑Min(distinct(t1.c2), distinct(t2.c2))即可,下图是Performance给出的实际和估算行数:
postgres=# explain performance select t1.c2, t2.c2, count(*) cnt from t1, t2 where t1.c2 = t2.c2 and t1.c1 < 500 group by t1.c2, t2.c2;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------
id | operation | A-time | A-rows | E-rows | E-distinct | Peak Memory | E-memory | A-width | E-width | E-costs
----+-----------------------------------------------+------------------+--------+--------+------------+----------------+----------+---------+---------+---------
1 | -> Streaming (type: GATHER) | 48.500 | 99 | 100 | | 80KB | | | 16 | 89.29
2 | -> HashAggregate | [38.286, 40.353] | 99 | 100 | | [28KB, 31KB] | 16MB | [24,24] | 16 | 79.29
3 | -> Hash Join (4,6) | [37.793, 39.920] | 1980 | 2132 | | [6KB, 6KB] | 1MB | | 8 | 75.04
4 | -> Streaming(type: REDISTRIBUTE) | [0.247, 0.549] | 1001 | 1001 | 25 | [53KB, 53KB] | 2MB | | 4 | 32.95
5 | -> Seq Scan on test.t2 | [0.157, 0.293] | 1001 | 1001 | | [12KB, 12KB] | 1MB | | 4 | 4.50
6 | -> Hash | [36.764, 38.997] | 998 | 1000 | 62 | [291KB, 291KB] | 16MB | [20,20] | 4 | 29.88
7 | -> Streaming(type: REDISTRIBUTE) | [36.220, 38.431] | 998 | 999 | | [53KB, 61KB] | 2MB | | 4 | 29.88
8 | -> Seq Scan on test.t1 | [0.413, 0.433] | 998 | 999 | | [14KB, 14KB] | 1MB | | 4 | 9.25 2.2 Aggregrate Path生成
有了聚集行数,则可以根据资源情况,灵活选择聚集方式。Aggregate方式主要有以下三种:
- Aggregate + Gather (+ Aggregate)
- Redistribute + Aggregate (+Gather)
- Aggregate + Redistribute + Aggregate (+Gather)
括号中的表示可能没有这一步,视具体情况而定。这些聚集方式可以理解成,两表关联时选两边Redistribute还是选一边Broadcast。优化器拿到聚集的最终行数后,会尝试每种聚集方式,并计算相应的代价,选择最优的方式,最终生成路径。这里有两层Aggregate时,最后一层就是最终聚集行数,而第一层聚集行数是根据Poisson模型推算的。Aggregate方式选择默认由优化器根据代价选择,用户也可以通过参数best_agg_plan指定。三类聚集方式大致适用范围如下:
- 第一种,直接聚集后行数不太大,一般是DN聚集,CN收集,有时CN需进行二次聚集
- 第二种,需要重分布且直接聚集后行数未明显减少
- 第三种,需要重分布且直接聚集后行数减少明显,重分布之后,行数又可以减少,一般是DN聚集、重分布、再聚集,俗称双层Aggregate
四、结束语
本文着眼于计划生成的核心步骤,从行数估算、到Join Path的生成、再到Aggregate Path的生成,介绍了其中最简单过程的基本原理。而实际的处理方法远远比描述的要复杂,需要考虑的情况很多,比如多组选择率如何组合最优、分布键怎么选、出现倾斜如何处理、内存用多少等等。权衡整个计划生成过程,有时也不得不有所舍,这样才能有所得,而有时计划的一点劣势也可以忽略或者通过其他能力弥补上来,比如SMP开启后,并行的效果会淡化一些计划上的缺陷。总而言之,计划生成是一项复杂而细致的工作,生成全局最优计划需要持续的发现问题和优化,后续博文我们将继续探讨计划生成的秘密。
点击关注,第一时间了解华为云新鲜技术~