折腾了几个算法的奇技淫巧,我把面试官戏弄了一波,哈哈哈
来了,算法装逼骚技巧 ,大家先做好心理准备啊,待我教你们一步步装逼。
1、2 的幂次方
问题描述:判断一个整数 n 是否为 2 的幂次方
对于这道题,常规操作是不断这把这个数除以 2,然后判断是否有余数,直到 n 被整除成 1 。
我们可以把 n 拆成二进制看待处理的,如果 n 是 2 的幂次方的话,那么 n 的二进制数的最高位是 1,后面的都是 0,例如对于 16 这个数,它的二进制表示为 10000。
如果我们把它减 1,则会导致最高位变成 0,其余全部变成 1,例如 10000 - 1 = 01111。
然后我们把 n 和 (n - 1)进行与操作,结果就会是 0,例如(假设 n 是 16)
n & (n-1) = 10000 & (10000 - 1) = 10000 & 01111 = 0
也就是说,n 如果是 2 的幂次方,则 n & (n-1) 的结果是 0,否则就不是,所以代码如下
int isPow(n){
return (n & (n - 1)) == 0;
}
一行代码搞定,在装逼的路上越走越远
2、n 的阶乘
问题描述:给定一个整数 N,那么 N 的阶乘 N! 末尾有多少个 0?例如: N = 10,则 N!= 3628800,那么 N! 的末尾有两个0。
我先给出个代码让大家品尝一下,在细细讲解
int f(n){
return n == 0 ? 0 : n / 5 + f(n / 5);
}
对于这道题,常规操作是直接算 N!的值再来除以 10 判断多少个 0 ,然而这样肯定会出现溢出问题,并且时间复杂度还大,我们不妨从另一个思路下手:一个数乘以 10 就一定会在末尾产生一个零,那么,我们是否可以从哪些数相乘能够得到 10 入手呢?
答是可以的,并且只有 2 * 5 才会产生 10。
注意,4 * 5 = 20 也能产生 0 啊,不过我们也可以把 20 进行分解啊,20 = 10 * 2。
于是,问题转化为 N! 种能够分解成多少对 2*5,再一步分析会发现,在 N!中能够被 2 整除的数一定比能够被 5 整除的数多,于是问题近似转化为求 1…n 这 n 个数中能够被 5 整除的数有多少个,
注意,像 25 能够被 5整除两次,所以25是能够产生 2 对 2 * 5滴。有了这个思路,代码如下:
int f(int n){
int sum = 0;
for(int i = 1; i <= n; i++){
int j = i;
while(j % 5 == 0){
sum++;
j = j / 5;
}
}
return sum;
}
然而进一步拆解,我们发现
当 N = 20 时,1~20 可以产生几个 5 ?答是 4 个,此时有 N / 5 = 4。
当 N = 24 时,1~24 可以产生几个 5 ?答是 4 个,此时有 N / 5 = 4。
当 N = 25 时,1~25 可以产生几个 5?答是 6 个,主要是因为 25 贡献了两个 5,此时有 N / 5 + N / 5^2 = 6。
…
可以发现 产生 5 的个数为 sum = N/5 + N/5^2 + N/5^3+….
于是,一行代码就可以搞定它了
int f(n){
return n == 0 ? 0 : n / 5 + f(n / 5);
}
别问,问就是一行代码的事。
3、找出一个没有重复的数
给你一组整型数据,这些数据中,其中有一个数只出现了一次,其他的数都出现了两次,让你来找出一个数 。
这道题可能很多人会用一个哈希表来存储,每次存储的时候,记录 某个数出现的次数,最后再遍历哈希表,看看哪个数只出现了一次。这种方法的时间复杂度为 O(n),空间复杂度也为 O(n)了。
然而我想告诉你的是,采用位运算来做,绝对高逼格!
我们刚才说过,两个相同的数异或的结果是 0,一个数和 0 异或的结果是它本身,所以我们把这一组整型全部异或一下,例如这组数据是:1, 2, 3, 4, 5, 1, 2, 3, 4。其中 5 只出现了一次,其他都出现了两次,把他们全部异或一下,结果如下:
由于异或支持交换律和结合律,所以:
123451234 = (11)(22)(33)(44)5= 00005 = 5。
也就是说,那些出现了两次的数异或之后会变成0,那个出现一次的数,和 0 异或之后就等于它本身。就问这个解法牛不牛逼?所以代码如下
int find(int[] arr){
int tmp = arr[0];
for(int i = 1;i < arr.length; i++){
tmp = tmp ^ arr[i];
}
return tmp;
}
时间复杂度为 O(n),空间复杂度为 O(1),而且看起来很牛逼,就问这波操作稳不稳?
这里说明一下,这个方式适合一个数出现了奇数次,其他数都出现了偶数次
不行,我还要继续装!
?一行代码解决方案如下:
// 例如使用这个函数的时候,我们最开始传给 i 的值是 1,传给 result 的是 arr[0]
//例如 find(arr, 1, arr[0])
int find(int[] arr,int i, int result){
return arr.length <= i ? result : find(arr, i + 1, result ^ arr[i]);
}
实不相瞒,这道题用了一行代码之后,更加复杂 + 难懂了,,,,,,不好意思,我错了,不该把简单的问题搞复杂了再扔给面试题的。
4、m的n次方
如果让你求解 m 的 n 次方,并且不能使用系统自带的 pow 函数,你会怎么做呢?这还不简单,连续让 n 个 m 相乘就行了,代码如下:
int pow(int n){
int tmp = 1;
for(int i = 1; i <= n; i++) {
tmp = tmp * m;
}
return tmp;
}
不过你要是这样做的话,我只能呵呵,时间复杂度为 O(n) 了,怕是小学生都会!如果让你用位运算来做,你会怎么做呢?
我举个例子吧,例如 n = 13,则 n 的二进制表示为 1101, 那么 m 的 13 次方可以拆解为:
m^1101 = m^0001 * m^0100 * m^1000。
我们可以通过 & 1和 >>1 来逐位读取 1101,为1时将该位代表的乘数累乘到最终结果。直接看代码吧,反而容易理解:
int pow(int n){
int sum = 1;
int tmp = m;
while(n != 0){
if(n & 1 == 1){
sum *= tmp;
}
tmp *= tmp;
n = n >> 1;
}
return sum;
}
时间复杂度近为 O(logn),而且看起来很牛逼。
5、交换两个数
交换两个数相信很多人天天写过,我也相信你每次都会使用一个额外来变量来辅助交换,例如,我们要交换 x 与 y 值,传统代码如下:
int tmp = x;
x = y;
y = tmp;
这样写有问题吗?没问题,通俗易懂,万一哪天有人要为难你,**不允许你使用额外的辅助变量来完成交换呢?**你还别说,有人面试确实被问过,这个时候,位运算装逼大法就来了。代码如下:
x = x ^ y // (1)
y = x ^ y // (2)
x = x ^ y // (3)
我靠,牛逼!三个都是 x ^ y,就莫名交换成功了。在此我解释下吧,我们知道,两个相同的数异或之后结果会等于 0,即 n ^ n = 0。并且任何数与 0 异或等于它本身,即 n ^ 0 = n。所以,解释如下:
把(1)中的 x 带入 (2)中的 x,有
y = x^y = (xy)y = x(yy) = x^0 = x。 x 的值成功赋给了 y。
对于(3),推导如下:
x = x^y = (xy)x = (xx)y = 0^y = y。
这里解释一下,异或运算支持运算的交换律和结合律哦。
怎么样?有木觉得很多牛逼?以后代码可以这样写,然后看看接管你代码的人是如何骂你的?
大家可以关注帅地微信公众号「帅地玩编程」,然后回复「002」和「003」,送你一本清华大佬的刷题模版 + BAT经典刷题笔记哦。
好了,我们来点是实用的算法技巧吧
6. 巧用数组下标
数组的下标是一个隐含的很有用的数组,特别是在统计一些数字,或者判断一些整型数是否出现过的时候。例如,给你一串字母,让你判断这些字母出现的次数时,我们就可以把这些字母作为下标,在遍历的时候,如果字母a遍历到,则arr[a]就可以加1了,即 arr[a]++;
通过这种巧用下标的方法,我们不需要逐个字母去判断。
我再举个例子:
问题:给你n个无序的int整型数组arr,并且这些整数的取值范围都在0-20之间,要你在 O(n) 的时间复杂度中把这 n 个数按照从小到大的顺序打印出来。
对于这道题,如果你是先把这 n 个数先排序,再打印,是不可能O(n)的时间打印出来的。但是数值范围在 0-20。我们就可以巧用数组下标了。把对应的数值作为数组下标,如果这个数出现过,则对应的数组加1。
代码如下:
public void f(int arr[]) {
int[] temp = new int[21];
for (int i = 0; i < arr.length; i++) {
temp[arr[i]]++;
}
//顺序打印
for (int i = 0; i < 21; i++) {
for (int j = 0; j < temp[i]; j++) {
System.out.println(i);
}
}
}
利用数组下标的应用还有很多,大家以后在遇到某些题的时候可以考虑是否可以巧用数组下标来优化。
7. 巧用取余
有时候我们在遍历数组的时候,会进行越界判断,如果下标差不多要越界了,我们就把它置为0重新遍历。特别是在一些环形的数组中,例如用数组实现的队列。往往会写出这样的代码:
for (int i = 0; i < N; i++) {
if (pos < N) {
//没有越界
// 使用数组arr[pos]
else {
pos = 0;//置为0再使用数组
//使用arr[pos]
}
pos++;
}
实际上我们可以通过取余的方法来简化代码
for (int i = 0; i < N; i++) {
//使用数组arr[pos] (我们假设刚开始的时候pos < N)
pos = (pos + 1) % N;
}
8. 巧用双指针
对于双指针,在做关于单链表的题是特别有用,比如“判断单链表是否有环”、“如何一次遍历就找到链表中间位置节点”、“单链表中倒数第 k 个节点”等问题。对于这种问题,我们就可以使用双指针了,会方便很多。我顺便说下这三个问题怎么用双指针解决吧。
例如对于第一个问题
我们就可以设置一个慢指针和一个快指针来遍历这个链表。慢指针一次移动一个节点,而快指针一次移动两个节点,如果该链表没有环,则快指针会先遍历完这个表,如果有环,则快指针会在第二次遍历时和慢指针相遇。
对于第二个问题
一样是设置一个快指针和慢指针。慢的一次移动一个节点,而快的两个。在遍历链表的时候,当快指针遍历完成时,慢指针刚好达到中点。
对于第三个问题
设置两个指针,其中一个指针先移动k个节点。之后两个指针以相同速度移动。当那个先移动的指针遍历完成的时候,第二个指针正好处于倒数第k个节点。
你看,采用双指针方便多了吧。所以以后在处理与链表相关的一些问题的时候,可以考虑双指针哦。
9. 设置哨兵位
在链表的相关问题中,我们经常会设置一个头指针,而且这个头指针是不存任何有效数据的,只是为了操作方便,这个头指针我们就可以称之为哨兵位了。
例如我们要删除头第一个节点是时候,如果没有设置一个哨兵位,那么在操作上,它会与删除第二个节点的操作有所不同。但是我们设置了哨兵,那么删除第一个节点和删除第二个节点那么在操作上就一样了,不用做额外的判断。当然,插入节点的时候也一样。
有时候我们在操作数组的时候,也是可以设置一个哨兵的,把arr[0]作为哨兵。例如,要判断两个相邻的元素是否相等时,设置了哨兵就不怕越界等问题了,可以直接arr[i] == arr[i-1]?了。不用怕i = 0时出现越界。
当然我这只是举一个例子,具体的应用还有很多,例如插入排序,环形链表等。
10. 与递归有关的一些优化
(1).对于可以递归的问题考虑状态保存
当我们使用递归来解决一个问题的时候,容易产生重复去算同一个子问题,这个时候我们要考虑状态保存以防止重复计算。例如我随便举一个之前举过的问题
问题:一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法?
这个问题用递归很好解决。假设 f(n) 表示n级台阶的总跳数法,则有
f(n) = f(n-1) + f(n - 2)。
递归的结束条件是当0 <= n <= 2时, f(n) = n。因此我们可以很容易写出递归的代码
public int f(int n) {
if (n <= 2) {
return n;
} else {
return f(n - 1) + f(n - 2);
}
}
不过对于可以使用递归解决的问题,我们一定要考虑是否有很多重复计算。显然对于 f(n) = f(n-1) + f(n-2) 的递归,是有很多重复计算的。如
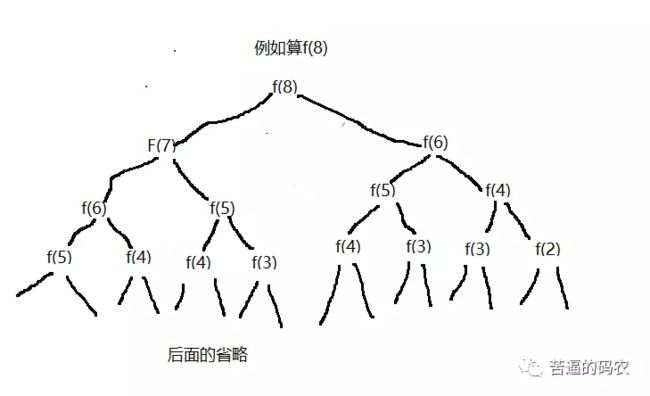
就有很多重复计算了。这个时候我们要考虑状态保存。例如用hashMap来进行保存,当然用一个数组也是可以的,这个时候就像我们上面说的巧用数组下标了。可以当arr[n] = 0时,表示n还没计算过,当arr[n] != 0时,表示f(n)已经计算过,这时就可以把计算过的值直接返回回去了。因此我们考虑用状态保存的做法代码如下:
//数组的大小根据具体情况来,由于int数组元素的的默认值是0
//因此我们不用初始化
int[] arr = new int[1000];
public int f(int n) {
if (n <= 2) {
return n;
} else {
if (arr[n] != 0) {
return arr[n];//已经计算过,直接返回
} else {
arr[n] = f(n-1) + f(n-2);
return arr[n];
}
}
}
这样,可以极大着提高算法的效率。也有人把这种状态保存称之为备忘录法。
(2).考虑自底向上
对于递归的问题,我们一般都是从上往下递归的,直到递归到最底,再一层一层着把值返回。
不过,有时候当n比较大的时候,例如当 n = 10000时,那么必须要往下递归10000层直到 n <=2 才将结果慢慢返回,如果n太大的话,可能栈空间会不够用。
对于这种情况,其实我们是可以考虑自底向上的做法的。例如我知道
f(1) = 1;
f(2) = 2;
那么我们就可以推出 f(3) = f(2) + f(1) = 3。从而可以推出f(4),f(5)等直到f(n)。因此,我们可以考虑使用自底向上的方法来做。
代码如下:
public int f(int n) {
if(n <= 2)
return n;
int f1 = 1;
int f2 = 2;
int sum = 0;
for (int i = 3; i <= n; i++) {
sum = f1 + f2;
f1 = f2;
f2 = sum;
}
return sum;
}
我们也把这种自底向上的做法称之为递推。
总结一下
当你在使用递归解决问题的时候,要考虑以下两个问题
(1). 是否有状态重复计算的,可不可以使用备忘录法来优化。
(2). 是否可以采取递推的方法来自底向上做,减少一味递归的开销。
另外,算法的学习也是必经之路,这里给大家推荐一个大佬的刷题笔记
下载链接:BAT大佬的刷题笔记太经典
把这份笔记突击学习一下,很多算法考察,基本都稳了
另外,再给大家推荐一份某大佬的 leetcode 刷题笔记,汇聚了上千道 leetcode 题解,并且代码都是 beat 100%:
下载链接:leetcode 分类题解(最优解)
就算你现在不学算法,那么这份笔记也值得你收藏,万一有人问你 Leetcode 某道题解,或者有大神在讨论题解,咱打开这份笔记,不管三七二十一,直接把最优解扔给他,然后退出群聊
作者简洁
作者:大家好,我是帅地,从大学、自学一路走来,深知算法,计算机基础知识的重要性,公众号「帅地玩编程」10万粉丝作者,专业于写这些底层知识,提升我们的内功,帅地期待你的关注,和我一起学习,点击了解我四年大学学 习之路 转载说明:未获得授权,禁止转载