外卖商品的标准化建设与应用
外卖菜品命名个性化程度高,为运营分析、召回排序、后台管理等业务带来一定的困难。本文系外卖美食知识图谱系列的第二篇文章,介绍了外卖从零到一建设菜品标准化体系的过程及方案,涉及的主要技术包括NLP领域的实体抽取、文本匹配、关系分类,以及CV领域的图像匹配等。最后,通过标准名在外卖业务中的应用实践,验证了标准名体系建设的价值和意义。
1. 背景及目标
商品作为外卖交易过程中的核心要素,决定了供需匹配的精准度,直接影响交易行为是否可以达成。外卖平台美食、甜点、饮品类在线商品有亿级之多,其中很多是属性信息一致的相同商品。建立对商品的标准化描述、聚合相同商品,是很多业务场景的诉求。
供销分析场景:想分析一下望京的商家都售卖哪些菜品,有多少商家卖“西红柿炒鸡蛋”?
遇到的问题:由于菜品是非标品,并且商家对菜品命名的个性化程度也较高,因此在外卖平台,同一个菜品名出现不同的命名方式;例如“西红柿炒鸡蛋”有西红柿炒蛋、小番茄炒蛋、西红柿鸡蛋、京城三绝~番茄炒蛋【正价小份菜】等,没有办法简单通过关键字进行聚合。
主题推荐场景:想出一个菜品粒度的主题,快速筛选“小龙虾”、“烤鱼”、“鸡公煲”、“黄焖鸡”等热门菜品?
遇到的问题:商品分类的颗粒度不够精细,无法快速找到适合颗粒度的菜品。
商家上单场景:像“鱼香肉丝”这样普遍的菜品,每个商家上单都需要录入食材、口味、做法、菜系、荤素等标签,录入成本较高,能不能像淘宝一样,选择“iPhone 12”,它的属性就能够自动关联。
遇到的问题:没有将菜品的属性标准化,菜品和属性之间没有关联关系。
基于上述业务应用的痛点,启动外卖商品的标准化建设。目标是建立商品的标准化名称,实现对相同商品的聚合,从而为业务提供合理粒度的概念划分,赋能运营端供销分析、用户端个性化召回排序、商家端标签生产。
2. 业界调研
对于业界的参考,主要参考淘宝标准化SPU建设。SPU在淘宝体系中决定了商品是什么,是商品信息聚合的最小单位,由关键属性+绑定属性来构成。
- 关键属性:用来约束和定义一个商品的,比如iPhone X,决定他的就是“苹果”这个品牌和“X”这个系列。
- 绑定属性:是关键属性的补充和细化,比如当iPhone X已经明确了这个产品后,其他的属性也确定,比如网络模型,屏幕尺寸等,进一步补充这些属性内容,逐步明确了一个产品。
可见淘宝对于SPU的建设,实际上是对属性的建设,例如格力空调S1240,通过“格力”品牌、“空调”类目、“S1240”型号来标准化、唯一化。
但对于餐饮行业,对于核心属性食材“牛肉”、做法“炒”、口味“辣”,都无法确定是什么菜,更谈不上唯一化;但如果通过“小炒黄牛肉”来标准化,行业/用户对其有普遍的认知,较固定的食材口味做法,适合用来进行标准化。因此淘宝是标准化属性,而餐饮是标准化菜品名称,所以我们称之为标准菜品名。
3. 问题分析及挑战
淘宝的标准化主要针对标品,而餐饮标准化都是针对非标品,难度较大,面临着个性化问题、录入不规范、粒度无行业标准、认知局限性等挑战。
3.1 个性化问题
餐饮商家可以较低成本的自定义生产,个性化程度较高,同一个菜品在不同商家的命名可能不同,需要大量的同义词聚合,而同义词的召回是最大的难点(如何将潜在的同义词挖掘出来进行标注)。例如,京城三绝-番茄炒蛋【正价小份菜】、西红柿炒蛋(小份)、小番茄炒蛋、西红柿炒土鸡蛋(小份),都表示“西红柿炒蛋”这个商品。
3.2 录入不规范
商家在录入商品名称时,存在缺失关键信息的问题,例如“缤纷水果”是水果拼盘、饮品还是披萨,“韭菜鸡蛋”是包子还是饺子。除商品名称外,需要借助商家分类,商品左侧栏tag等相关信息,对名称进行推理和补全。
3.3 粒度无行业标准
在进行标准化处理时,没有统一的标准,粒度难以把控:过粗容易产生非菜品错误(例如:“香辣鸡腿”->“鸡腿”),过细则标准名内聚性偏弱(例如:“传统黄焖鸡【大碗】”本身粒度过细,需要提炼到“黄焖鸡”)。
3.4 认知局限性
中华美食文化博大精深,对于一些不为大众所熟知的小众或者地方特色菜品,需要具有一定的专业背景知识,例如“炒鸡”也是一个标准的名称,还并非商家没有填写完整。
4. 方案
商品标准化的整体方案如图所示:首先,基于美食、甜点饮品类商家全量在线的亿级商品,通过名称清洗、置信度判别、人工检验,获得近菜名主干;通过同义词挖掘,对主干名进一步聚合压缩,映射到标准名主词上;对于单个商品,进行名称纠错、清洗,通过模型匹配,建立商品-标准名的映射;为了满足不同业务场景的聚合粒度要求,通过上下级关系挖掘、深度遍历,进一步构建标准名层级树。分别对名称聚合、匹配映射、层级构建三个模块,涉及的算法模型进行介绍。

4.1 名称聚合
清洗后的主干名仍然存在很多同义说法,比如土豆烧牛肉、牛肉烧土豆、洋芋烧牛肉、小土豆烧牛肉,表示相同的商品。目标通过挖掘这种潜在的同义关系,进一步提升名称的内聚性。在迭代过程中,先后采用了规则匹配和语义匹配的方法,挖掘潜在同义词;聚合后,根据流行度判别其中的主词,并将原始主干词映射至标准名主词上。分别对两种同义词挖掘方法介绍如下。
4.1.1 规则匹配
一期首先采用了规则匹配的方法,利用NER模型对主干名进行成份识别,结合知识图谱构建的属性同义词表,判别两个主干名是否是同义关系。

如图所示,其中“牛肉烧土豆”通过名称解析得到牛肉-食材,烧-做法,土豆-食材;“洋芋烧牛肉”通过名称解析得到洋芋-食材,烧-做法,牛肉-食材。对比两个主干名的成份词,其中土豆和洋芋是一对同义词,其余成份相同,进而获得二者之间是同义关系。
通过这种方式,挖掘了十万级同义词。根据标准名覆盖的商品供给数计算流行度值,将更流行度高的作为主词;人工校验后补充到标准名体系,提升了名称的聚合度。
4.1.2 语意匹配
由于规则匹配挖掘到的同义词有限,比如“担担面”和“担担汤面”,根据NER模型,担担面和汤面都会被识别成类目。如此,两个主干名是无法建立同义关系的。
我们二期调研了一些匹配模型,借鉴搜索算法组的经验,采用BERT+DSSM的语义匹配模型进行同义关系的扩覆盖。如图所示,首先基于一期积累的同义词,通过组内生成正例、跨组交叉生成负例的方式,构造百万级样本,训练了一版基础模型;为了进一步优化模型性能,通过主动学习和数据增强两种方式,对样本数据进行了迭代。

主动学习的方式是先利用基础模型,圈定一批待标注的相似样本,交与外包标注,将标注正确的样本补充至已有同义词中,标注错误的样本作为负例加入训练集,用于模型的优化迭代。通过主动学习的方式,补充了万级样本,模型准确率取得了明显提升。
进一步分析结果,我们发现了一批很有特点的Bad Case,比如红烧狮子头和红烧狮子头盖饭、香椿拌豆腐和拌豆腐等,它们都属于字面相似度很高,但核心成份不同的匹配错误。基于这个特点,先根据字面距离圈定了一批字面相似度高的样本,再利用名称解析模型对它们进行成份识别,找出其中的负例。通过这种方式,在不增加标注成本的情况下,自动补充了十万级样本,进一步提升了模型准确率。
利用语义匹配模型,新增了十万级同义词,进一步提升了标准名的内聚性。
4.2 匹配映射
在挖掘到的标准名词表和同义词基础上,为亿级在线商品建立“商品-标准名”映射(如“招牌蛋炒小番茄(大份)”映射到“西红柿炒鸡蛋”),以实现对相同商品的标准化描述与聚合。采用“文本+图像”相结合的匹配模型,覆盖了绝大部分的美食、甜点饮品类商家的在线商品。
4.2.1 文本匹配
文本匹配流程如图4所示,整体上包括召回、排序两个阶段。首先,对商品名称中的规格、分量等描述信息进行清洗,将清洗后的商品名和标准名进行2-Gram切片,通过关联相同切片的方式召回待匹配的标准名;基于召回的标准名,通过计算Jaccard距离,保留其中Top 20的标准名;在此基础上,利用BERT向量化模型,生成商品名和标准名的向量表示,通过计算Jaccard字面距离以及Cosine向量相似度,获取其中综合得分最高的标准名。
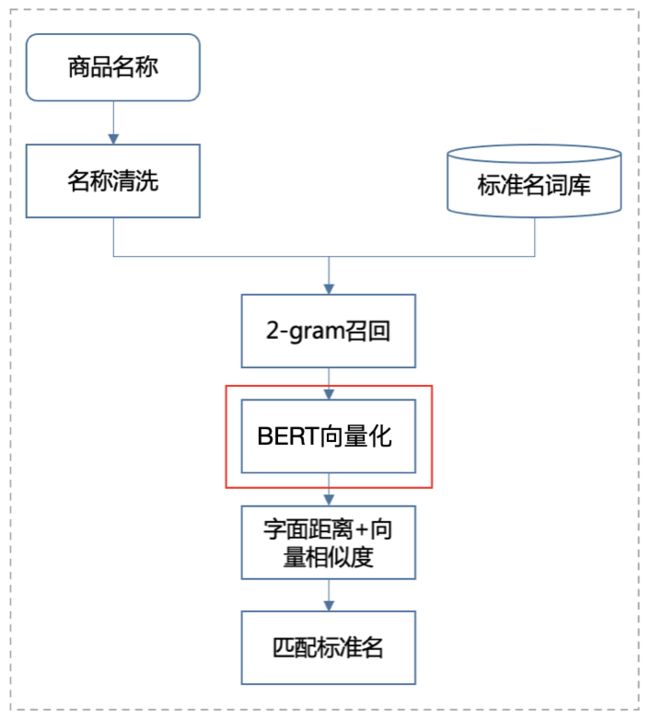
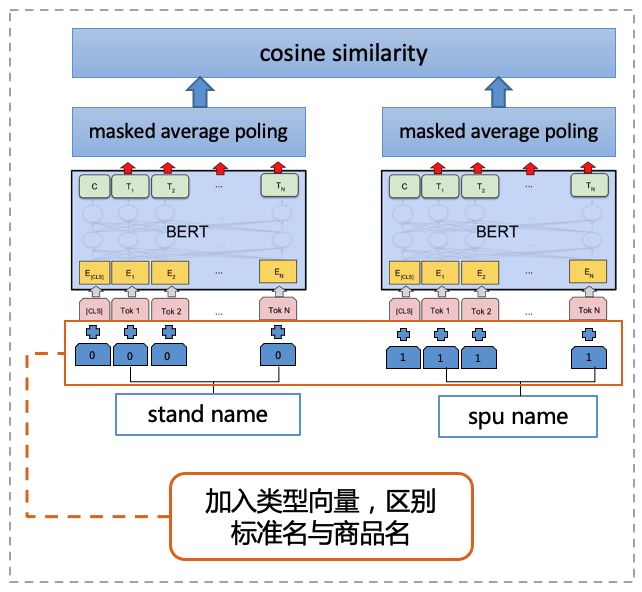
其中,BERT向量化模型是基于上文提到的同义语义匹配模型,通过级联一维类型编码的方式,对标准名和商品名加以区分,改造成非对称的标准名匹配模型。之所以进行这一改造,是因为与同义匹配不同,标准名匹配是非对称的,如应该将“香锅盔”匹配上相对抽象的标准名“锅盔”,而不是匹配上一个更加具体的标准名“五香锅盔”。改造后,匹配准确率提升显著。
4.2.2 图像匹配
由于菜品名称长度有限及商家命名不规范,会导致仅从菜品名称中获取的信息有限,而无法建立到标准名的匹配。通过引入商品图片信息,提升对文本信息不全商品的匹配准确和覆盖。
图像匹配采用的是多分类模型,根据标准名层级聚合(详见3层级构建)后的顶级、二级,选择待匹配的标准名标签,并根据文本匹配结果构造样本集。由于采用大规模非人工标注样本,不可避免地要解决样本噪声问题。在本场景下,噪声主要有两个主要来源:一是文本信息不全,导致样本标签错误;二是由于顶级、二级聚合程度高,导致分类粒度过粗,需要细分多个标签。针对这些问题,采用样本和模型迭代优化的方式,根据基础样本集训练初版模型,利用模型挖掘噪声数据,人工校验后进行模型微调。如此迭代,实现低标注成本的模型优化。
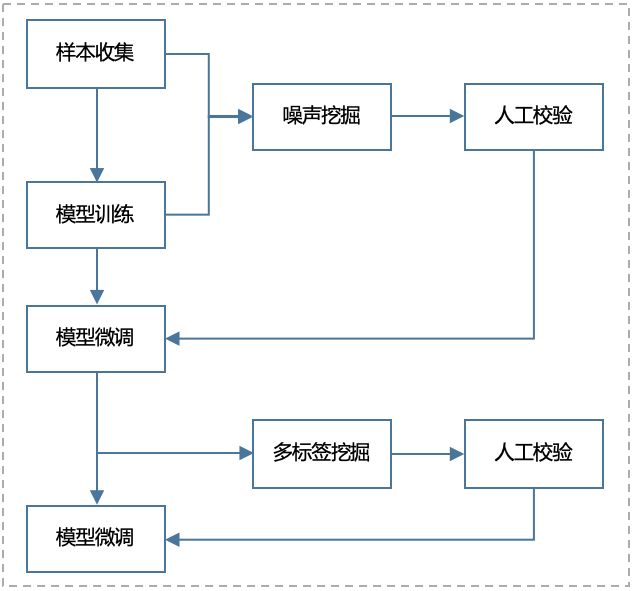
图像分类模型选取了对MBConv模块的参数进行精细化调整的Basebone网络Efficientnet,通过调整网络的分辨率、深度、宽度,确定最优组合。噪声挖掘方法首先通过Metric-Learn的方法,学习获得每个类别的聚类中心,及类内样本与聚类中心距离的均值、方差、中位数,对其进行排序挖掘出类内离散度较大的类别;再借助分类模型在验证集上的预测、O2U-Net和Forgetting Event 挖掘样本噪声。通过上述方法优化模型,提升对噪声样本的鲁棒性。

4.3 层级构建
推荐场景下,为了保证用户的个性化和多样性体验,需要对商品进行合理粒度的聚合。对于商品列表排序场景,现有的类目过粗会导致多样性不足,标准名过细又会导致结果重复。目标是建立一个层级化商品体系,为业务提供合理的聚合粒度。通过关系挖掘、层级遍历,构造万级顶点的层级树,支持了商品列表、美食排行榜、交互式推荐等业务的上线和优化。构建方法包括规则匹配和模型判别,分别对这两类方法进行介绍。
4.3.1 规则匹配
规则匹配方法是基于已有的NER模型和属性词表,通过结构化匹配的方法,挖掘到十万级上下级关系,进一步遍历生成万级顶点的标准名层级树。这种方法比较简单且基于已有工作,开发周期短,在项目初期快速支持上线,并取得了明显的业务收益。

4.3.2 模型判别
规则匹配方法由于NER模型错误和属性词关系缺少,导致挖掘到的关系有限,需要通过判别模型进一步提升泛化性。基于BERT的关系分类模型如图8所示,对待分类一对标准名用[SEP]进行拼接,并在开头增加[CLS]标识符;将拼接结果编码后,传入BERT模型,取出[CLS]位的Embedding;再接一个全联接层和Softmax层,输出关系分类结果。标准名关系包括:同义、上级、下级、无关系,一共四个类别。
样本数据包括简单例和难例两部分,其中:简单例基于已有同义词、上下级,以及同义词组间交叉生成无关系,一共构造百万级样本;在此基础上,进一步利用已有的向量化模型,召回相似度较高的标准名对,交与外包标注其类别。第二类样本更加贴近实际分类场景,且属于混淆度较高的分类难例。
利用第一类样本预训练初版模型,并在此基础上,利用第二类样本对模型进行微调,进一步提升了分类模型准确率。经人工校验,进一步补充了万级词关系。

5. 在外卖业务中的应用
标准名作为品类和商品的中间层,为业务提供了更加丰富、合理的聚合粒度,支持了流量转化的策略优化,以及系列产品形态的开发上线。商品列表通过接入标准名层级,实现对商品合理粒度的聚合,解决了线上商品重复的问题;标准名作为基础数据,支持了美食排行榜的开发和上线,帮助提升用户的决策效率;针对用户当前访问的商品,利用标准名召回相关商品,实现交互式推荐。标准名作为重要的基础数据,支持了产品形态多元化、推荐策略优化,对于提升用户粘性、流量转化,搭建商家用户友好的平台生态,具有重要的价值和意义。

6. 总结与展望
目前已完成基本的体系建设,并成功应用于不同的场景、取得业务收益。已经建成的标准名层级体系,覆盖了外卖绝大多数的在线商品。标准名作为基础和特征数据,应用到用户端的商品列表、美食排行榜等业务场景,支持策略优化、带来流量收益;同时,也通过服务接口的形式,跨部门支持SaaS点餐推荐的模型优化,以提升用户体验和业务收益。
标准名作为重要的商品特征数据,应用的业务场景广泛。在未来的工作中,需要持续迭代优化,保证标准名自身的准确性和质量;同时加深业务理解,根据业务需要优化层级体系,为业务提供更加合理的聚合粒度,提升转化收益;此外,重点建设一批用户感知强、供给覆盖高的标准名,降低业务方的接入成本和提高收益。
6.1 词表及同义词优化
标准名词表体量大、同义关系复杂,词表建设不是一蹴而就的,需要长期的迭代和优化。针对标准名词表中存在的非菜品、不规范等错误,以及同义词聚合不足、过度的问题,采用算法圈定+人工标注的方式,通过模型挖掘潜在同义词、圈定问题词组;人工校验后,进行批量补充和修改,持续优化词表、同义词。
6.2 层级结构合理化
目前标准名层级是通过规则和模型的方式直接生成的,人工参与度较低,与业务场景的结合不够深入。后续会结合业务需要,明确剪枝、聚合粒度准则,合理化层级结构,优化层级的合理性。从而更加灵活、高效地支持不同的业务应用,提升落地效果。
6.3 核心标准名建设
标准名有20万之多,为业务应用造成一定的选择成本、带来不便。结合业务需要,圈定其中用户感知强、供给覆盖高、优质的标准名,作为核心标准名进行重点建设。核心标准名轻量且精炼,更加贴近业务需要,可以帮助业务方降低接入成本、提高收益。
7. 参考文献
- [1] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
- [2] Lample G, Ballesteros M, Subramanian S, et al. Neural architectures for named entity recognition[J]. arXiv preprint arXiv:1603.01360, 2016.
- [3] Chen Q, Zhu X, Ling Z, et al. Enhanced lstm for natural language inference[J]. arXiv preprint arXiv:1609.06038, 2016.
- [4] Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2013: 2333-2338.
- [5]Tan M , Le Q V . EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks[J]. 2019.
8. 作者简介
刘柳、懋地、崇锦、晓星等,均来自美团外卖技术团队。
阅读美团技术团队更多技术文章合集
前端 | 算法 | 后端 | 数据 | 安全 | 运维 | iOS | Android | 测试
| 在公众号菜单栏对话框回复【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。
| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明“内容转载自美团技术团队”。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至[email protected]申请授权。