开散列的实现--哈希冲突

哈希冲突-开散列
- 目录:
-
- 一.开散列概念
- 二.开散列原理
- 三.哈希迭代器实现
- 四.功能接口实现
-
- 1.构造函数
- 2.iterator begin()
- 3.iterator end()
- 4.insert
- 5.Capacity
- 五.模拟实现Map
- 六.模拟实现Set
目录:
一.开散列概念
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
二.开散列原理
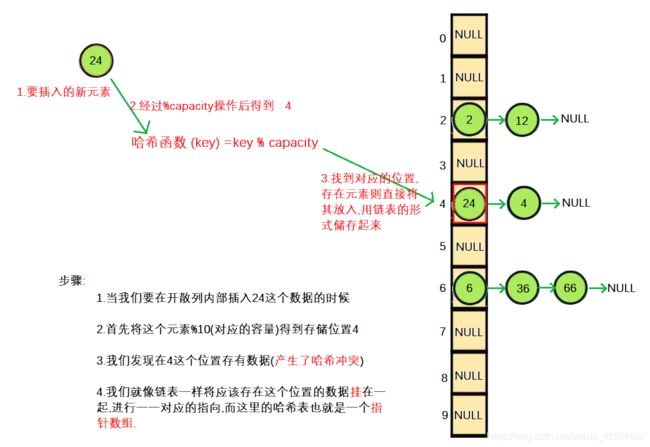
三.哈希迭代器实现
这里我们还是引用第三个模板KeyOfValue来实现迭代器
对于迭代器实现++运算符的时候,会存在从指针数组的前一个链表指向下一个链表的操作,所以我们对于++操作就没有那么简单的操作.

//哈希迭代器实现
template<class K, class V, class KeyOfValue>
struct HashIterator{
typedef HashIterator<K, V, KeyOfValue> Self; //定义别名
typedef HTable<K, V, KeyOfValue> HT;
typedef HashNode<V> Node; //定义别名
HT* _hPtr; //给出所对应哈希表的指针来实现数据的链式存储
Node* _node;
HashIterator(Node* node, HT* hPtr) //迭代器的初始化
:_node(node)
, _hPtr(hPtr)
{
}
V& operator*(){
//初始化*符号
return _node->_val; //直接指向对应的值
}
V* operator->(){
//重定义->
return &_node->_val; //指向对应的值
}
bool operator!=(const Self& it){
//重定义!=符号
return _node != it._node; //直接对内部的node进行判断
}
//如果这里对于这种链式的指向,就需要判断
Self& operator++(){
//对于++遍历到下一个元素
if (_node->_next){
//如果后面还存在元素
_node = _node->_next; //则直接指向即可
}
else{
//如果需要遍历指针数组的下一个指针开始指向的时候,就需要重新来实现
//查找下一个非空链表的头结点
//计算当前节点在哈希表中位置
KeyOfValue kov; //定义对应第三个模板
size_t idx = kov(_node->_val) % _hPtr->_ht.size(); //进行%运算操作,计算出对应的位置
++idx; //进行++操作
for (; idx < _hPtr->_ht.size(); ++idx){
//对整个指针数组进行遍历操作
if (_hPtr->_ht[idx]){
//如果找到对应的下一个非空链表的时候
//找到下一个非空链表
_node = _hPtr->_ht[idx]; //对对应的_node进行指向
break; //退出循环
}
}
//没有有效的节点
if (idx == _hPtr->_ht.size()){
//如果没有找到对应的节点
_node == nullptr; //直接置空就可以
}
}
return *this; //返回对应的位置
}
};
四.功能接口实现
1.构造函数
template<class K, class V, class KeyOfValue>
class HTable{
//哈希对应类的实现
public:
typedef HashNode<V> Node;
typedef HashIterator<K, V, KeyOfValue> iterator; //对应迭代器定义
template<class K, class V, class KeyOfValue> //泛型模板
friend struct HashIterator; //将哈希实现的迭代器设置为有元类
HTable(int n = 10) //对应的构造函数
:_ht(n)
, _size(0) //对应数据的初始化
{
}
2.iterator begin()
iterator begin(){
//第一个非空链表的头结点
for (size_t i = 0; i < _ht.size(); ++i){
//遍历到第一个非空链表的头结点
if (_ht[i]){
//找到对应的数据后
return iterator(_ht[i], this); //指直接将对应的值进行返回
}
}
return iterator(nullptr, this); //如果没有找到则直接返回空
}
3.iterator end()
iterator end(){
return iterator(nullptr, this); //哈希表的end()迭代器指向的是最后一个数据后面的NULL
}
4.insert
pair<iterator, bool> insert(const V& val)
//bool insert(const V& val)
{
//1.检查容量
checkCapacity();
//2.计算hash位置
KeyOfValue kov;
int idx = kov(val) % _ht.size();
//3.查找
Node* cur = _ht[idx];
while (cur){
if (kov(cur->_val) == kov(val)){
//key重复
//return false;
return make_pair(iterator(cur, this), false);
}
cur = cur->_next;
}
//4.插入对应的值是否存在:头插
cur = new Node(val);
cur->_next = _ht[idx];
_ht[idx] = cur;
++_size;
//return true;
return make_pair(iterator(cur, this), true);
}
5.Capacity
内存容量不够开辟的方式:

void checkCapacity(){
//检查容器是否够用
if (_size == _ht.size()){
//如果对应的容器已经被存储满了
int nreC = _size == 0 ? 10 : 2 * _size; //开辟对应的空间
//创建新的指针数组
vector<Node*> newHt(newC);
KeyOfValue kov;
//遍历旧表
for (size_t i = 0; i < _ht.size(); ++i){
Node* cur = _ht[i];
//遍历单链表
while (cur){
Node* next = cur->_next;
//计算新的位置
int idx = kov(cur->_val) % newHt.size();
//头插
cur->_next = newHt[idx];
newHt[idx] = cur;
cur = next;
}
//旧表指针置空
_ht[i] = nullptr;
}
//交换
swap(_ht, newHt);
}
}
五.模拟实现Map
template <class K, class V>
class Map{
struct MapKeyOfValue{
const K& operator()(const pair<K, V>&val){
//重载()运算符
return val.first; //这里的值对应的是kv键值对的key
}
};
public:
//将哈希表中的迭代器进行使用定义
typedef typename HTable<K, pair<K, V>, MapKeyOfValue>::iterator iterator;
pair<iterator, bool> insert(const pair<K, V>& val){
return _ht.insert(val); //直接利用哈希表内部的接口
}
iterator begin(){
return _ht.begin(); //同样直接调用接口
}
iterator end(){
return _ht.end();
}
V& operator[](const K& key){
//重载对应的运算符
pair<iterator, bool> ret = _ht.insert(make_pair(key, V())); //这里是对应的kv键值对中的value
return ret.first->second; //将对应的second也就是对应的值进行返回
}
private:
HTable<K, pair<K, V>, MapKeyOfValue> _ht;
};
六.模拟实现Set
template<class K>
class Set{
struct SetKeyOfValue{
const K& operator()(const K& key){
//对应的()进行重载,因为set是故直接返回对应的key
return key;
}
};
public:
typedef typename HTable<K, K, SetKeyOfValue>::iterator iterator; //迭代器
iterator begin(){
return _ht.begin(); //调用
}
iterator end(){
return _ht.end();
}
bool insert(const K& key){
return _ht.insert(key); //调用对应的插入函数
}
private:
HTable<K, K, SetKeyOfValue> _ht;
};
这就是对于开散列的具体实现,主要理解++运算符重载的过程和存储方式,以及如何开辟空间的.