esp8266 sdk入门指南_Apache Beam实战指南 | 手把手教你玩转大数据存储HdfsIO
 策划编辑 | Natalie作者 | 张海涛审校 | Natalie编辑 | Vincent
AI 前线导读:本文是
Apache Beam 实战指南系列文章的第三篇内容,将对 Beam 框架中的 HDFSIO 和 MySQLIO 源码进行剖析,并结合应用示例和代码解读带你进一步了解如何结合 Beam 玩转大数据存储重要组件 HDFS。系列文章第一篇回顾Apache Beam 实战指南 | 基础入门、第二篇回顾Apache Beam 实战指南 | 手把手教你玩转 KafkaIO 与 Flink。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
策划编辑 | Natalie作者 | 张海涛审校 | Natalie编辑 | Vincent
AI 前线导读:本文是
Apache Beam 实战指南系列文章的第三篇内容,将对 Beam 框架中的 HDFSIO 和 MySQLIO 源码进行剖析,并结合应用示例和代码解读带你进一步了解如何结合 Beam 玩转大数据存储重要组件 HDFS。系列文章第一篇回顾Apache Beam 实战指南 | 基础入门、第二篇回顾Apache Beam 实战指南 | 手把手教你玩转 KafkaIO 与 Flink。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
关于 Apache Beam 实战指南系列文章
随着大数据 2.0 时代悄然到来,大数据从简单的批处理扩展到了实时处理、流处理、交互式查询和机器学习应用。近年来涌现出诸多大数据应用组件,如 HBase、Hive、Kafka、Spark、Flink 等。开发者经常要用到不同的技术、框架、API、开发语言和 SDK 来应对复杂应用的开发,这大大增加了选择合适工具和框架的难度,开发者想要将所有的大数据组件熟练运用几乎是一项不可能完成的任务。
面对这种情况,Google 在 2016 年 2 月宣布将大数据流水线产品(Google DataFlow)贡献给 Apache 基金会孵化,2017 年 1 月 Apache 对外宣布开源 Apache Beam,2017 年 5 月迎来了它的第一个稳定版本 2.0.0。在国内,大部分开发者对于 Beam 还缺乏了解,社区中文资料也比较少。InfoQ 期望通过Apache Beam 实战指南系列文章推动 Apache Beam 在国内的普及。
一.概述随着 2018 年 10 月 2 日欧洲 Beam 首届峰会结束后,Beam 的使用者越来越多,关注度越来越高。不光外国公司 Google、Spotify、亚马逊、Data Artisans 等用上了 Beam,TensorFlow 机器学习框架也跟 Beam 结合使用做机器学习的预处理工作,背靠谷歌巨头,Beam 不光在大数据一统上做强有力的部署,在云计算、大数据、机器学习、人工智能的集成和运用也越来越广泛。
Beam 在发布第一个版本后,不断完善模型和运行平台。SDKs 也添加了许多 IO,例如消息中间件又新增了 ActiveMQ 和 RabbitMQ ,缓存新增 Redis ,大数据分析神器 Kudu,大数据存储格式 Parquet 等等。Runner 新增了实时流处理 Samza 和 JStorm、MapReduce 和加速 Hadoop 查询 Tez,此外新增了 Beam 部署 Docker 的 DockerCommand 接口 ,以及 Metrics 监控的引入和集成。其他 SDK 和 Runner 也在不断更新中,Beam 每 6 周发布一个小版本,及时完善了一些一次性未集成完善的功能。
在科技日新月异的浪潮中,不管是人工智能的机器学习、还是 AI 的人脸识别、以及物联网的工业互联、互联网的深度挖掘等都必须有一定的数据积累,恰恰这些早期的数据很多公司都存到不同的数据库中,很多公司在早期没有其他大数据存储情况下,基本都存在 Hadoop 的 HDFS 中。对于 HDFS 这个被公认的大数据存储基石,Beam 是怎样简单的操作的呢?底层源码是怎样跟 Beam 结合使用的?我们今天就重点看一下。
二.Apache Beam 中 HdfsIO 源码剖析由于 Beam 在发布稳定版本 2.0 之前的源码,Beam 操作 HdfsIO 都比较不稳定,并且 API 都比较 Low。在 2.0 版本之后 HdfsIO 的变化很大,2.0 版本之前命名为 HDFSFileSink 读写等操作,2.0 之后都是命名为 HadoopFileSystem 来操作 Hadoop 的 HDFS 。本文按照 Beam 2.4 版本源码进行剖析,2.4 之后的版本基本没有很大变化,直到最新的 2.9 版本才有一个小优化,2.4 版本的 HdfsIO 还是比较稳定的。
2.1 Hdfs 的配置类 Configuration 源码部分HadoopFileSystem(Configuration configuration) throws IOException { this.fileSystem = org.apache.hadoop.fs.FileSystem.newInstance(configuration);
}在源码中 HadoopFileSystem 把 Hadoop Hdfs 的配置类当参数,在构造函数外面配置好传参到内部。 Configuration 类其实有三个配置,一个是 HdfsConfiguration 类,另外是 map-reduce Job 任务和 YarnConfiguration 资源调度器用到的配置,今天我们主要看 HdfsConfiguration 类,因为 Map-Reduce 去年集成到 Beam 之后基本很少人使用。

在 HdfsConfiguration 类中支持很多配置,最主要的“fs.default.name’”是配置我们 Hadoop 集群。
2.2 HDFS 的读写都是基于 ByteBuffer 的@Override
public int read(ByteBuffer dst) throws IOException {
if (closed) {
throw new IOException("Channel is closed");
}
// O length read must be supported
int read = 0;
// We avoid using the ByteBuffer based read for Hadoop because some FSDataInputStream
// implementations are not ByteBufferReadable,
// See https://issues.apache.org/jira/browse/HADOOP-14603
if (dst.hasArray()) {
// does the same as inputStream.read(dst):
// stores up to dst.remaining() bytes into dst.array() starting at dst.position().
// But dst can have an offset with its backing array hence the + dst.arrayOffset()
read = inputStream.read(dst.array(), dst.position() + dst.arrayOffset(), dst.remaining());
} else {
// TODO: Add support for off heap ByteBuffers in case the underlying FSDataInputStream
// does not support reading from a ByteBuffer.
read = inputStream.read(dst);
}
if (read > 0) {
dst.position(dst.position() + read);
}
return read;
}现在支持的外部数据量访问:
1.HarFsInputStream
2.S3InputStream
3.DFSInputStream
4.SwiftNativeInputStream
5.NativeS3FsInputStream
6.LocalFSFileInputStream
7.NativeAzureFsInputStream
8.S3AInputStream
不支持的有:
FTPInputStream
三.Apache Beam 中 MySQLIO 源码剖析MySQL 是一款经典的关系型数据库,随着互联网和移动互联网的发展而大放异彩。基本上大大小小公司都在用。本章通过 Beam MySQLIO 的源码给大家解读一下如何通过 Beam 来操作 MySQL。
MySQL 的集成源码非常简单,就是一个 JdbcIO.java 类,为了统一,这里还是看一下 Beam 2.4 的源码。
3.1 Beam 从 MySQL 读取全部表数据。示例:
pipeline.apply(JdbcIO.String>>read()// 数据库 JDBCIO 的配置
.withDataSourceConfiguration(JdbcIO.DataSourceConfiguration.create(//mysql 的驱动"com.mysql.jdbc.Driver", "jdbc:mysql://hostname:3306/mydb")//MySQL 的用户名
.withUsername("username")//MySQL 的密码
.withPassword("password"))// 查询 SQL 语句
.withQuery("select id,name from Person")// 返回数据的编码
.withCoder(KvCoder.of(BigEndianIntegerCoder.of(), StringUtf8Coder.of()))// 映射返回数据
.withRowMapper(new JdbcIO.RowMapperString>>() {
public KVString> mapRow(ResultSet resultSet) throws Exception {
return KV.of(resultSet.getInt(1), resultSet.getString(2));
}
})
);MySQL 我之前是手工从底层封装过操作类,写法可能跟之前我们之前多少有些区别。实际用的时候大家可以把数据源换成数据库连接池 c3p0 或阿里巴巴的 Druid,其实在 Beam JdbcIO.java 源码中,DataSourceConfiguration.create () 方法中有三个重载方法,其中 DataSourceConfiguration create(DataSource dataSource) 方法就可以用数据库连接池操作。
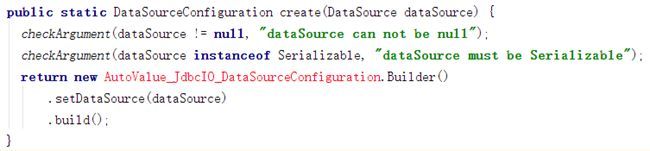
大多数操作数据库现在基本是用实体对象通过映射操作的。在源码示例中 JdbcIO.RowMapper>() 的 KV 类型在实际应用中可以换成大家最熟悉的实体对象,因为 Beam 底层源码中 RowMapper 类型是 自定义泛型类型 T,可以直接定义成实体类型。
// 添加带条件的 SQL 读取
.withQuery("select id,name from Person where name = ?")
// 数据编码
.withCoder(KvCoder.of(BigEndianIntegerCoder.of(), StringUtf8Coder.of()))
// 实例化 JdbcIO 参数类
.withStatementPreparator(new JdbcIO.StatementPreparator() {
// 传入执行 Statement
public void setParameters(PreparedStatement preparedStatement)throws Exception {
// 传递条件参数
preparedStatement.setString(1, "Darwin");
}
})
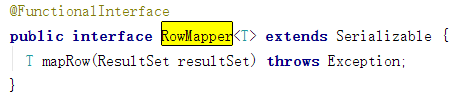
.withRowMapper(new JdbcIO.RowMapper>() {
Batch 的处理条数默认是 1000 条,这个可以利用 withBatchSize() 方法进行配置。
/**
* Provide a maximum size in number of SQL statenebt for the batch. Default is 1000.
*
* @param batchSize maximum batch size in number of statements
*/
public WritewithBatchSize(long batchSize) {
checkArgument(batchSize > 0, "batchSize must be > 0, but was %d", batchSize);
return toBuilder().setBatchSize(batchSize).build();
}具体的执行跟其他读取写入返回一样,不过在这里传递的也是一个自定义泛型类型。可以传递我们的 SQL List 类型的数据。
private void processRecord(T record, PreparedStatement preparedStatement) {
try {
preparedStatement.clearParameters();
spec.getPreparedStatementSetter().setParameters(record, preparedStatement);
preparedStatement.addBatch();
} catch (Exception e) {
throw new RuntimeException(e);
}
}MySQL 写入在以下示例中已经运用,不再做具体剖析。
四.Apache Beam HdfsIO 实战很多时候我们要把 HDFS 批量计算或其他处理到前台展示。我们就写一个从 HDFS 读取数据,进行分析统计,最后输出到 MySQL 数据库的实战示例。
4.1 设计思路图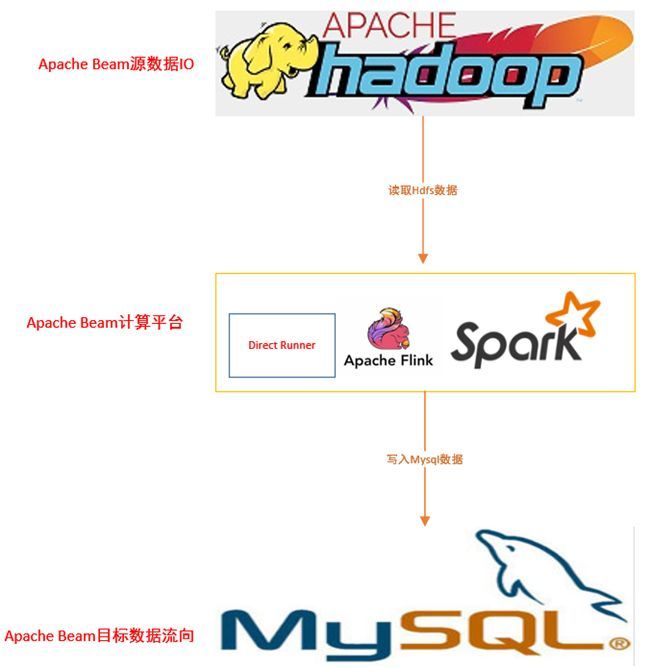
系统版本 centos 7
hadoop-2.7.2.tar.gz
mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz
Jdk 1.8
Maven 3.3.3
Spring Tool Suite
spark-2.2.0-bin-hadoop2.7.tgz
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`keystr` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`count` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;1) 新建一个 Maven 项目
2) 引入 pom.xml 必要的 jar 包。
org.apache.beamgroupId>
beam-runners-core-javaartifactId>
2.4.0version>
dependency>
log4jgroupId>
log4jartifactId>
1.2.17version>
dependency>
org.apache.beamgroupId>
beam-runners-direct-javaartifactId>
2.4.0version>
dependency>
org.apache.beamgroupId>
beam-sdks-java-io-jdbcartifactId>
2.4.0version>
dependency>
org.apache.beamgroupId>
beam-sdks-java-coreartifactId>
2.4.0version>
dependency>
org.apache.beamgroupId>
beam-sdks-java-io-hadoop-file-systemartifactId>
2.4.0version>
dependency>
org.apache.beamgroupId>
beam-sdks-java-io-hdfsartifactId>
0.6.0version>
dependency>
org.apache.beamgroupId>
beam-sdks-java-io-hadoop-commonartifactId>
2.4.0version>
dependency>
jdk.toolsgroupId>
jdk.toolsartifactId>
1.8version>
systemscope>
${JAVA_HOME}/lib/tools.jarsystemPath>
dependency>
org.apache.hadoopgroupId>
hadoop-commonartifactId>
2.7.2version>
providedscope>
dependency>
org.apache.sparkgroupId>
spark-core_2.11artifactId>
2.2.0version>
com.fasterxml.jackson.coregroupId>
*artifactId>
exclusion>
exclusions>
dependency>
org.apache.sparkgroupId>
spark-streaming_2.11artifactId>
2.2.0version>
com.fasterxml.jackson.coregroupId>
*artifactId>
exclusion>
exclusions>
dependency>
com.fasterxml.jackson.coregroupId>
jackson-coreartifactId>
2.6.0version>
dependency>
com.fasterxml.jackson.coregroupId>
jackson-databindartifactId>
2.6.7version>
dependency>
org.apache.hadoopgroupId>
hadoop-hdfsartifactId>
2.7.2version>
dependency>
org.apache.hadoopgroupId>
hadoop-mapreduce-client-coreartifactId>
2.7.2version>
dependency>
org.apache.beamgroupId>
beam-sdks-java-io-jdbcartifactId>
2.4.0version>
dependency>
mysqlgroupId>
mysql-connector-javaartifactId>
5.1.17version>
dependency>
org.apache.beamgroupId>
beam-runners-sparkartifactId>
2.4.0version>
dependency>
org.apache.hadoopgroupId>
hadoop-clientartifactId>
2.7.2version>
dependency> 3)新建 HTM.java 类.
4) 编写以下代码
public static void main(String[] args) {
// 配置 Hdfs 配置
Configuration conf = new Configuration();
// 配置 Hdfs 的地址
conf.set("fs.default.name", "hdfs://192.168.220.140:9000");
// 设置管道
HadoopFileSystemOptions options = PipelineOptionsFactory.fromArgs(a
rgs).withValidation().as(HadoopFileSystemOptions.class);
options.setHdfsConfiguration(ImmutableList.of(conf));
// 这里可以指定 任意平台,我这里本地测试用的本地 Runner
options.setRunner(DirectRunner.class);
// options.setRunner(SparkRunner.class);
// options.setRunner(FlinkRunner.class);
Pipeline pipeline = Pipeline.create(options);
// 读取 Hdfs 的数据跟读取 TextIO 一样的。
PCollection resq = pipeline.apply(TextIO.read().from("hdf
s://192.168.220.140:9000/user/lenovo/testfile/test.txt")).apply
("ExtractWords",ParDo.of(new DoFn()
{
private static final long serialVersionUID = 1L;
@ProcessElementpublic void processElement(ProcessContext c) {
// 根据空格进行读取数据,里面可以用 Luma 表达式写for (String word : c.element().split(" ")) {
if (!word.isEmpty()) {
c.output(word);
System.out.println(word + "\n");
}
}
}
}));
PCollection windowedEvents = resq.apply(Window.
into(FixedWindows.of(Duration.standardSeconds(5))));// 把数据出现频率做个统计
PCollection> wordcount = windowedEvents.apply(Count.perElement());// 写入 mysql, 调用 Beam 的 JdbcIO 进行写入
wordcount.apply(JdbcIO.>write()
.withDataSourceConfiguration(JdbcIO.DataSourceConfiguration//mysql 的驱动和连接
.create("com.mysql.jdbc.Driver", "jdbc:mysql://192.168.220.
140:3306/db1?useUnicode=true&characterEncoding=UTF-8&allowM ultiQueries=true")//mysql 的用户名和密码
.withUsername("root").withPassword("123456"))//SQL 语句
.withStatement("insert into test (keystr,count) values(?,?)")
.withPreparedStatementSetter(new JdbcIO.PreparedStatementSe
tter>() {
private static final long serialVersionUID = 1L;public void setParameters(KV element, PreparedSta
tement query) throws SQLException {
// 传递的参数
query.setString(1, element.getKey());
query.setLong(2, element.getValue());
}
}));
pipeline.run().waitUntilFinish();
System.exit(0);
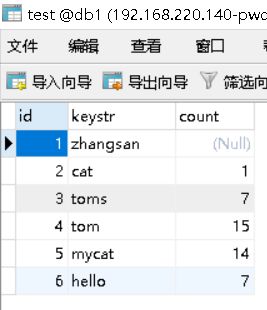
}5)本地程序运行结果

MySQL 数据库执行结果
6)FlinkRunner 执行方式
FlinkRunner 请参照Apache Beam 实战指南 | 手把手教你玩转 KafkaIO 与 Flink。
7)SparkRunner 执行方式
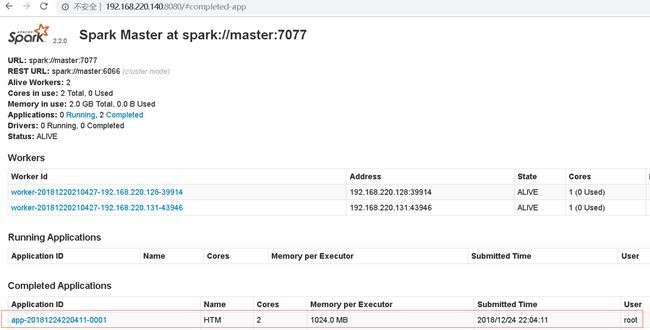
首先导出为 jar 并上传到 Llinux spark master 服务器 上,如果上了 Docker,可以直接用 Jenkins 构建。

进入 spark bin 目录 执行以下命令。
./spark-submit --master spark://master:7077 --class com.BeamHdfsToMySQL.HdfsToMySQL.HTM /home/beamsparkHdfstoMysql.jar命令解读:
--master spark 通讯地址
--class Beam 的 class 执行类路径
--/home/beamsparkHdfstoMysql.jar 执行的 jar 路径
--runner=SparkRunner 这个是执行执行选择管道用的参数,如果程序未指定则要加上。
注意,如果在程序显示指定 SparkRunner 就不要执行参数再指定,否则会报错。
执行效果如下:

不管是人工智能还是物联网,真正大数据的到来才是考验流批计算处理真正的时候的来临。Beam 不光在数据源 IO 上越来越完善,集成越来越多。在计算平台上更新速度也非常快,很多其他社区的开源负责人也在积极封装 SDK 集成给 Beam(例如 ClickHouseIO,Nemo Runner),相信以现在的更新速度,Beam 用不了多久就可以打造自己的生态。而距离程序员只写一套 Beam 代码就能在各种计算处理平台上使用的日子也越来越近了。
作者介绍张海涛,目前就职于海康威视云基础平台,负责云计算大数据的基础架构设计和中间件的开发,专注云计算大数据方向。Apache Beam 中文社区发起人之一,如果想进一步了解最新 Apache Beam 动态和技术研究成果,请加微信 cyrjkj 入群共同研究和运用。
传送门:
系列文章第一篇《Apache Beam 实战指南 | 基础入门》
系列文章第二篇《Apache Beam 实战指南 | 手把手教你玩转 KafkaIO 与 Flink》

喜欢这篇文章吗?记得点一下「好看」再走?