Apache DolphinScheduler 大数据工作流调度系统
Apache DolphinScheduler 大数据工作流调度系统
-
- 一、背景
- 二、介绍下DolphinScheduler
- 三、DolphinScheduler一些优势
-
- 1、丰富的业务类型
- 2、可视化的DAG图
- 3、资源文件的上传管理
- 4、活跃的社区和用户群
- 5、开发语言和框架
- 6、对dokcer和K8S的支持
- 与其他开源调度系统对比
- 四、实用过程中遇见的一些问题
-
- 1、业务场景适配的一些问题
- 2、在线业务使用的一些准备
- 五、基于docker-compose和MySQL搭建DolphinScheduler
-
- 1、下载源码包并拉取相应的镜像
- 2、下载 MySQL 驱动包
- 3、修改项目的配置文件
- 4、启动服务
- 5、登录系统
- 六、常见问题
-
- 如何通过 docker-compose 管理 DolphinScheduler?
- 如何通过 docker-compose 扩缩容 master 和 worker?
一、背景
在调研DolphinScheduler之前,我们公司其实有用了一些开源的调度系统,像hera(赫拉)、xxl-job,前者是在我们的大数据平台上作为任务调度的平台,当然我们做了一些二次开发的改造,使得它更贴合我们的业务场景,也利于使用,目前还在持续使用;后者定位为业务平台的调度平台,业务本身的一些定时任务统一接入到该平台,统一管理(旧业务还有不少使用Spring @Scheduler或者quartz实现),然而它对大数据领域相关的调度支持比较弱,所以未做考虑。
关于hera调度系统,它是根据前阿里开源调度系统(zeus)进行的二次开发,zeus本身也已经不维护,作者对其进行了重写,从项目的start和fork上看目前国内应用得并不多,最近提交记录也比较少,最近得一次版本也是在去年(2020)10月份的,社区和活跃都相对一般。但是从可用性和易用性方面我个人还是比较推崇的,中小型公司在数据体系不多、任务量较少的情况下完全可以开箱即用。
当然,业内还有其他一些开源的调度系统,如Azkaban、Airflow等,在国内也有一定的应用,本人未亲身体验过,只在网上了解过相关理论知识,这里也不详细说明。
二、介绍下DolphinScheduler
Apache DolphinScheduler(前身是EasyScheduler) 于 17 年成立于易观数科, 19 年 3 月开源,8 月进入 Apache 孵化器,今年4月份,apache官方渠道宣布DolphinScheduler完成毕业成为顶级项目(国内成为apache顶级项目的不多,如阿里的分布式消息中间件RockMQ、Java 服务框架Dubbo、腾讯的分部署对象存储Ozone、分布式数据库中间件shardingsphere、分布式OLAP分析引擎kylin)。
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。DolphinScheduler致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。通过平台降低数据的ETL的开发成本、提升效率。
什么是去中心化?
区块链就是一个很好的去中心化的案例,所谓去中心化,就是把隶属于中心的权力分散,将数据和服务打散,好比是由中央集权转为共产主义制度。这么做有什么好处呢?第一,避免数据垄断的出现,数据垄断往往事用户的隐私信息得不到保障;第二,降低中心异常或安全问题,提升容错能力

MasterServer采用分布式无中心设计理念,MasterServer主要负责 DAG 任务切分、任务提交监控,并同时监听其它MasterServer和WorkerServer的健康状态。 MasterServer服务启动时向Zookeeper注册临时节点,通过监听Zookeeper临时节点变化来进行容错处理。
WorkerServer也采用分布式无中心设计理念,WorkerServer主要负责任务的执行和提供日志服务。 WorkerServer服务启动时向Zookeeper注册临时节点,并维持心跳。
关于
WorkerServer负载均衡的一些问题,DolphinScheduler提供了三种算法,加权随机(random默认)、平滑轮询(roundrobin)、线性负载(lowerweight),线性负载均衡是用过节点的CPU、内存的配置和负载情况来实现的,详细配置可参考官方文档
核心特性

其他的一些设计目标和能力:
- 以
DAG图的方式将Task按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态 - 支持
丰富的任务类型:Shell、MR、Spark、Flink、SQL(mysql、postgresql、hive、sparksql、clickhouse),Python、HTTP、Sub_Process、Procedure等 - 支持工作流
定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill任务等操作 - 支持
工作流优先级、任务优先级及任务的故障转移及任务超时告警/失败 - 支持工作流
全局参数及节点自定义参数设置 - 支持
资源文件的在线上传/下载,管理等,支持在线文件创建、编辑 - 支持任务日志在线查看及滚动、在线下载日志等
- 实现
集群HA,通过Zookeeper实现Master集群和Worker集群去中心化 - 支持对Master/Worker cpu load,memory,cpu在线查看
- 支持工作流运行历史
树形/甘特图展示、支持任务状态统计、流程状态统计 - 支持
补数 - 支持
多租户 - 支持国际化
还有更多等待伙伴们探索,参考地址
三、DolphinScheduler一些优势
1、丰富的业务类型
为更好的应对大数据的使用场景,在任务方面支撑更多的数据调度,如:Shell、MR、Spark、Flink、SQL(mysql、postgresql、hive、sparksql、clickhouse),Python、HTTP、Sub_Process、Procedure等
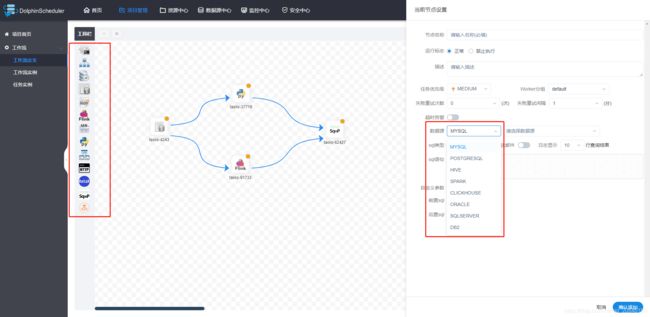
2、可视化的DAG图



3、资源文件的上传管理
支持对各种资源文件的管理,包括创建基本的txt/log/sh/conf/py/java等文件、上传jar包等各种类型文件,可进行编辑、重命名、下载、删除等操作

4、活跃的社区和用户群
DolphinScheduler在会内也获得了大量的用户,据不完全统计,目前已经有 400 多家公司在生产上使用 DolphinScheduler 作为大数据任务调度,高度得到市场的认可。图片整理来源于dolphinscheduler开源社区,更详细的资料或者你们公司也在使用的话可以通过github查看和提交。

5、开发语言和框架
DolphinScheduler的技术栈也是一方面为什么关注它的原因,基本上符合后台开发的一些主流的框架,如果需要进行二次改造的话基本没有门槛,我们看下DolphinScheduler的技术栈:
- 后端: SpringBoot (2.X,目前是2.1.18)、Quartz(2.3.0)
- 前端: VUE
- 编译: Maven(3.3+) ,
- 元数据存储: Mysql5.5+
- 分布式无中心化设计: ZooKeeper(3.4.6+)
- 统一资源管理 : 共享存储[HDFS、S3A、MinIO]
6、对dokcer和K8S的支持
目前已经推出了多种安装方式,包括单机、集群的部署,对与原生的支持,支持Docker部署、Kubernetes 部署、SkyWalking Agent 部署等,做到弹性的伸缩、资源隔离。我们在第五章也会详细介绍如何基于docker-compose和mysql搭建dolphinscheduler

与其他开源调度系统对比
| 维度\平台 | DolphinScheduler | Hera | Akazkaba | AirFlow |
|---|---|---|---|---|
| 背景 | 前身是EasyScheduler,于 17 年成立于易观数科, 19 年 3 月开源,8 月进入 Apache 孵化器,今年4月成为顶级项目 | 根据前阿里开源调度系统(zeus)进行的二次开发 | Azkaban是由Linkedin开源的一个批量工作流任务调度器。Azkaban定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。 | airflow是Airbnb开源出托管于托管在Apache基金会的,通过python定义作业 |
| 可视化 | 任务状态、任务类型、重试次数、任务运行机器、可视化变量等关键信息一目了然 | 任务DAG图展示、支持实时运行的任务,失败任务,成功任务,任务耗时,机器的负载,内存,进程,cpu信息的可视化 | 部分任务相关信息 | 有直观的DAG依赖,有良好的UI对任务进行查看 |
| 作业配置 | shell 、python、 MR、Spark、Flink、SQL、DataX、Sqoop等等 | shell、python、SQL、Spark、Hive | command、shell、hadoop、java | python脚本 |
| 过载处理 | 任务队列+多种任务分配策略+自我保护机制 | 无 | 任务过多服务器卡顿 | 任务过多服务器卡顿 |
| 监控审计 | ✔ | ✔ | ✔ | ✔ |
| 开发语言 | Java | Java | Java | Python |
| 作业告警 | ✔ | ✔ | ✔ | ✔ |
| 是否支持暂停和恢复 | ✔ | ❌ | ❌ | ❌ |
| 是否支持多租户 | ✔ | ✔ | ❌ | ❌ |
| 权限管控 | ✔ | ✔ | ✔ | ❌ |
| 易用性 | 好 | 较好 | 较好 | 较好 |
| 社区活跃 | 活跃 | 低 | 中 | 活跃 |
| 高可用 | ✔ | ✔ | ✔ | ✔ |
| 可扩展性 | 高 | 一般 | 高 | 一般 |
| 维护成本 | 低 | 低 | 中 | 中 |
| 缺陷 | hera整体使用还是比较容易方便,但是从目前来看社区太小,还有一点就是支撑的数据类型较少 | 集群化中的部署相对繁琐,且可扩展性也不高,功能相对较为单一 | 性能相对较弱,并发支持得不是很好,对实时性要求较高的话可能无法支撑,通过Python定义作业,如果不了解Python的话门槛相对高一点 |
引用其倡导的一句标语“工具选得好,下班回家早;调度用的对,半夜安心睡”。

四、实用过程中遇见的一些问题
1、业务场景适配的一些问题
1、Sqoop使用的一些问题,Sqoop是DolphinScheduler在1.3的版本为了提升全流程ETL 工作流的能力上增加的,不过export貌似只能支持全表或者分区表的导出,比较不方便,如果能够直接支持SQL的话就相当方便。
2、权限管控问题,每个人都只能看到自己建的项目,有一些公共的任务其实想参考的话就比较麻烦(也可能是为了安全考虑才这么设计的),如果权限这块能控制得更细的话就比较方便了。
2、在线业务使用的一些准备
1、性能的压力测试,网传在线业务已经能够支撑到10W级别的并发,但是这个跟集群规模配置和业务的复杂程度都是相关的,自己的业务需要经过一定的验证。
2、业务场景的适配,技术、平台的选型更多的是适配业务场景,再牛逼的技术如果没有适合的业务场景可能也一无是处,我们还需要拿更多的案例来验证其适用性。
3、平台使用的易用性,个人来看DolphinScheduler从操作成本上来看相比Hera可能会复杂些,交互场景会多一些步骤,会产生一些学习转换的成本。
4、告警配置的一些改造,邮件告警可能不适合我司,想接入如企业微信需要做一些调整改造,希望未来能够就自动支持。
五、基于docker-compose和MySQL搭建DolphinScheduler
根据官网推荐的方式按照docker-compose配置还是非常方便,未安装docker-compose的请自行安装。下面的安装步骤增加了一步:使用MySQL 替代 PostgreSQL 作为 DolphinScheduler的数据库,并且使数据源中心支持MySQL数据源,因为官方提供的版本因为MySQL许可证的原因并未把MySQL的驱动包放进去,所以需要使用MySQL的话需要自己打包。
1、下载源码包并拉取相应的镜像
到apache官网下载已release的源码,目前稳定的版本是1.3.6
$ tar -zxvf apache-dolphinscheduler-1.3.6-src.tar.gz
$ cd apache-dolphinscheduler-1.3.6-src/docker/docker-swarm
$ docker pull apache/dolphinscheduler:1.3.6
$ docker tag apache/dolphinscheduler:1.3.6 apache/dolphinscheduler:latest
2、下载 MySQL 驱动包
mysql-connector-java-5.1.49.jar (要求 >=5.1.47)创建一个新的 Dockerfile,用于添加 MySQL 的驱动包:
FROM apache/dolphinscheduler:1.3.6
COPY mysql-connector-java-5.1.49.jar /opt/dolphinscheduler/lib
构建一个包含 MySQL 驱动包的新镜像:
docker build -t apache/dolphinscheduler:mysql-driver .
也可以直接拉本人已经制作好的,在个人Docker Hub仓库
3、修改项目的配置文件
修改 docker-compose.yml 文件中的所有 image 字段为 apache/dolphinscheduler:mysql-driver
如果你想在 Docker Swarm 上部署 dolphinscheduler,你需要修改 docker-stack.yml
注释 docker-compose.yml 文件中的 dolphinscheduler-postgresql 块
在 docker-compose.yml 文件中添加 dolphinscheduler-mysql 服务(可选,你可以直接使用一个外部的 MySQL 数据库),详细配置如下:
version: "3.1"
services:
dolphinscheduler-mysql:
image: bitnami/mysql:latest
environment:
TZ: Asia/Shanghai
MYSQL_USERNAME: root
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: dolphinscheduler
volumes:
- dolphinscheduler-mysql:/bitnami/mysql
restart: unless-stopped
networks:
- dolphinscheduler
dolphinscheduler-zookeeper:
image: bitnami/zookeeper:latest
environment:
TZ: Asia/Shanghai
ALLOW_ANONYMOUS_LOGIN: "yes"
ZOO_4LW_COMMANDS_WHITELIST: srvr,ruok,wchs,cons
volumes:
- dolphinscheduler-zookeeper:/bitnami/zookeeper
restart: unless-stopped
networks:
- dolphinscheduler
dolphinscheduler-api:
image: apache/dolphinscheduler:mysql-driver
command: api-server
ports:
- 12345:12345
environment:
TZ: Asia/Shanghai
env_file: config.env.sh
healthcheck:
test: ["CMD", "/root/checkpoint.sh", "ApiApplicationServer"]
interval: 30s
timeout: 5s
retries: 3
depends_on:
- dolphinscheduler-mysql
- dolphinscheduler-zookeeper
volumes:
- dolphinscheduler-logs:/opt/dolphinscheduler/logs
- dolphinscheduler-shared-local:/opt/soft
- dolphinscheduler-resource-local:/dolphinscheduler
restart: unless-stopped
networks:
- dolphinscheduler
dolphinscheduler-alert:
image: apache/dolphinscheduler:mysql-driver
command: alert-server
environment:
TZ: Asia/Shanghai
env_file: config.env.sh
healthcheck:
test: ["CMD", "/root/checkpoint.sh", "AlertServer"]
interval: 30s
timeout: 5s
retries: 3
depends_on:
- dolphinscheduler-mysql
volumes:
- dolphinscheduler-logs:/opt/dolphinscheduler/logs
restart: unless-stopped
networks:
- dolphinscheduler
dolphinscheduler-master:
image: apache/dolphinscheduler:mysql-driver
command: master-server
environment:
TZ: Asia/Shanghai
env_file: config.env.sh
healthcheck:
test: ["CMD", "/root/checkpoint.sh", "MasterServer"]
interval: 30s
timeout: 5s
retries: 3
depends_on:
- dolphinscheduler-mysql
- dolphinscheduler-zookeeper
volumes:
- dolphinscheduler-logs:/opt/dolphinscheduler/logs
- dolphinscheduler-shared-local:/opt/soft
restart: unless-stopped
networks:
- dolphinscheduler
dolphinscheduler-worker:
image: apache/dolphinscheduler:mysql-driver
command: worker-server
environment:
TZ: Asia/Shanghai
env_file: config.env.sh
healthcheck:
test: ["CMD", "/root/checkpoint.sh", "WorkerServer"]
interval: 30s
timeout: 5s
retries: 3
depends_on:
- dolphinscheduler-mysql
- dolphinscheduler-zookeeper
volumes:
- dolphinscheduler-worker-data:/tmp/dolphinscheduler
- dolphinscheduler-logs:/opt/dolphinscheduler/logs
- dolphinscheduler-shared-local:/opt/soft
- dolphinscheduler-resource-local:/dolphinscheduler
restart: unless-stopped
networks:
- dolphinscheduler
networks:
dolphinscheduler:
driver: bridge
volumes:
dolphinscheduler-mysql:
dolphinscheduler-zookeeper:
dolphinscheduler-worker-data:
dolphinscheduler-logs:
dolphinscheduler-shared-local:
dolphinscheduler-resource-local:
修改 config.env.sh 文件中的 DATABASE 环境变量指向MySQL
DATABASE_TYPE=mysql
DATABASE_DRIVER=com.mysql.jdbc.Driver
DATABASE_HOST=dolphinscheduler-mysql
DATABASE_PORT=3306
DATABASE_USERNAME=root
DATABASE_PASSWORD=root
DATABASE_DATABASE=dolphinscheduler
DATABASE_PARAMS=useUnicode=true&characterEncoding=UTF-8
如果你已经添加了 dolphinscheduler-mysql 服务,设置 DATABASE_HOST 为 dolphinscheduler-mysql 即可
4、启动服务
到这里,你就可以启动整个dolphinscheduler服务了,执行:
docker-compose up -d

5、登录系统
访问前端页面: 本地地址为 http://127.0.0.1:12345/dolphinscheduler,默认的用户是admin,默认的密码是dolphinscheduler123

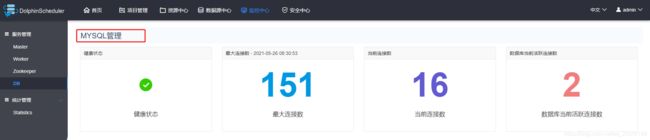
我们可以在监控中心看到,这边的DB已经被替换为了MySQL了
六、常见问题
此部分参考dolphinscheduler官方文档,更多的常见问题可以再上面找到解决方案。
如何通过 docker-compose 管理 DolphinScheduler?
启动、重启、停止或列出所有容器:
docker-compose start
docker-compose restart
docker-compose stop
docker-compose ps
停止所有容器并移除所有容器、网络:
docker-compose down
停止所有容器并移除所有容器、网络和存储卷:
docker-compose down -v
如何通过 docker-compose 扩缩容 master 和 worker?
扩缩容 master 至 2 个实例:
docker-compose up -d --scale dolphinscheduler-master=2 dolphinscheduler-master
扩缩容 worker 至 3 个实例:
docker-compose up -d --scale dolphinscheduler-worker=3 dolphinscheduler-worker
参考资料清单:
https://github.com/apache/incubator-dolphinscheduler
https://dolphinscheduler.apache.org/zh-cn/
https://blog.csdn.net/weixin_36836847/article/details/96379318
https://lidong.blog.csdn.net/article/details/108513690
https://zhangboyi.blog.csdn.net/article/details/114017156
欢迎指导,持续更新…