学习笔记之《python数据分析与挖掘实战》第三章数据探索
文章目录
- 欢迎购买正版书籍
- 数据探索
-
- 数据质量分析
-
- 缺失值分析
- 异常值分析
- 一致性分析
- 数据特征分析
-
- 分布分析
- 对比分析
- 统计量分析
- 周期性分析
- 贡献度分析
- 相关性分析
- python 主要数据探索函数
-
- 基本统计特征函数
- 拓展统计特征函数
- 统计作图函数

欢迎购买正版书籍
豆瓣评价:Python数据分析与挖掘实战
作者: 张良均 / 王路 / 谭立云 / 苏剑林
出版社: 机械工业出版社
数据探索
数据探索有助于选择合适的数据预处理和建模方法,甚至可以完成一些通常有数据挖掘解决的问题
数据质量分析
数据预处理的前提
数据质量分析的主要任务是检察院数据是否有脏数据:
脏数据内容:
- 缺失值
- 异常值
- 不一致的值
- 重复数据及含有特殊符号的数据
缺失值分析
缺失值主要包括记录的确实和记录中某个字段信息的缺失
缺失值产生的原因
缺失值的影响
缺失值的分析
异常值分析
异常值分析师检验数据是否有录入错误以及含有不合理的数据。
异常值是指样本中的个别值,其数据明显偏离其他的观测值。异常值也称为离散点,异常值的分析也称为离散点分析。
- 简单统计量分析
常见统计量分析:最大值,最小值 - 3δ原则
如果数据服从正态分布,在3δ原则下,异常值被定义为一组测定值中与平均值的偏差超过3倍标准差的值 - 箱形图分析
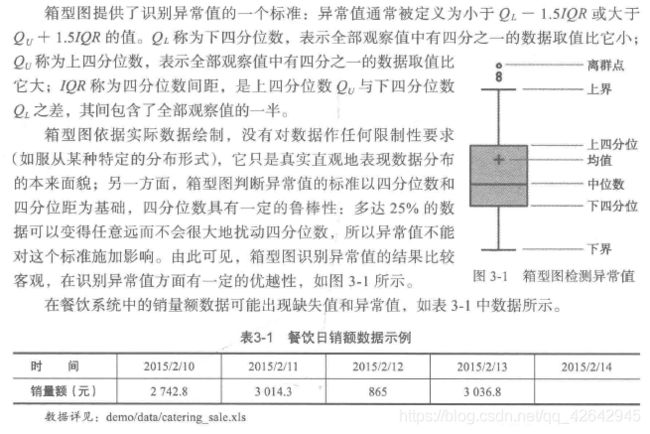
所谓“鲁棒性”,是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。
所谓“稳定性”,是指控制系统在使它偏离平衡状态的扰动作用消失后,返回原来平衡状态的能力。
稳定性是指系统受到瞬时扰动,扰动消失后系统回到原来状态的能力,而鲁棒性是指系统受到持续扰动能保持原来状态的能力。
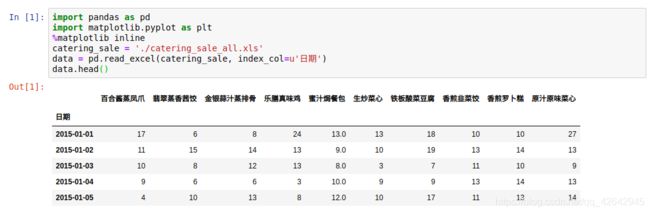
pandas中只需要读入数据后,使用describe()函数就可以查看数据的基本情况
例如:
import pandas as pd
catering_sale = 'catering_sale.xls' # 销售数据
# 读取数据,制定‘日期'列为索引列
data = pd.read_excel(catering_sale,index_col = u'日期')
data.head()
#describe()函数自动计算的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)
data.describe()



使用箱线图,检测餐饮销售额数据异常值,代码如下:
# 制作箱线图
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
catering_sale = './catering_sale.xls'
data = pd.read_excel(catering_sale, index_col=u'日期')
print(data.describe())
# 使用盒图来展示数据
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置
plt.rcParams['axes.unicode_minus'] = False #负号显示
# 画箱线图
plt.figure(figsize=(10,5))
p = data.boxplot(return_type='dict') # 数据转为箱线图的字典格式
x = p['fliers'][0].get_xdata()
y = p['fliers'][0].get_ydata()
y.sort()
# 添加注释, xy指定标注数据,xytext指定标注的位置(所以需要特殊处理)
for i in range(len(x)):
if i >0:
plt.annotate(y[i], xy=(x[i], y[i]), xytext=(x[i]+0.05 -0.8/(y[i] -y[i-1]), y[i]))
else:
plt.annotate(y[i], xy=(x[i], y[i]), xytext=(x[i]+0.08, y[i]))
plt.show()


一致性分析
数据一致性是指数据的矛盾性、不相容性。
数据特征分析
对数据质量分析后,接下来可通过绘制图表、计算特征量等手段对数据进行特征分析
分布分析
分析数据的分布特征和分布类型,主要是通过绘图的方式展现
1.定量数据的分布分析
- 求极差
- 决定组距与组数
- 决定分点
- 列出频率分布表
- 绘制频率分布直方图

2.定性数据的分布分析

对比分析

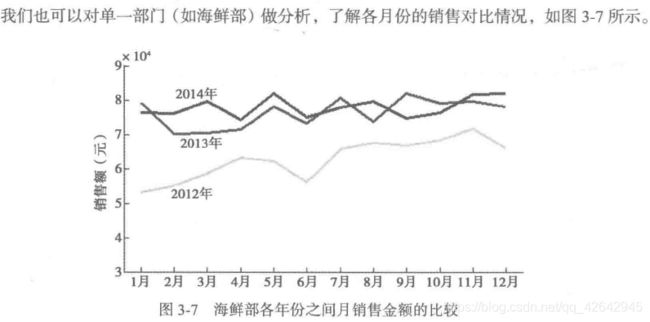
统计量分析
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
catering_sale = './catering_sale.xls'
data = pd.read_excel(catering_sale, index_col=u'日期')
data = data[(data[u'销量'] > 400) & (data[u'销量'] < 5000)] #过滤异常值
statistics = data.describe()[u'销量'] #保存基本统计量
statistics['range'] = statistics['max'] - statistics['min'] #极差
statistics['var'] = statistics['std'] / statistics['mean'] #变异系数
statistics['dis'] = statistics['75%'] - statistics['25%'] #四分位间距
print(statistics)

周期性分析
贡献度分析
贡献度分析又称为帕累托分析


python代码如下:
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
catering_sale = './catering_dish_profit.xls'
data = pd.read_excel(catering_sale, index_col=u'菜品名')
data = data[u'盈利'].copy() #浅拷贝
data.sort_values(ascending=False)
plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')
p = 1.0 * data.cumsum() / data.sum()
p.plot(color='r', secondary_y=True, style='-o', linewidth=2)
plt.annotate(
format(p[6], '.4%'),
xy=(6, p[6]),
xytext=(6 * 0.9, p[6] * 0.9),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))#添加标注,即85%处的标记。这里包括了指定箭头样式
plt.ylabel(u'盈利(比例)')
plt.show()


相关性分析
分析连续型变量之间的线性相关程度的强弱,并用适当的统计指标表示出来的过程称为相关性分析。
1.直接绘制散点图:判断两个变量相关性

2.绘制散点图矩阵:判断多个变量的相关性

3.计算相关系数
- Pearson相关系数

- Spearman秩相关系数也称等级相关系数
- 判断相关系数
餐饮销售数据相关性分析
代码:
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
catering_sale = './catering_sale_all.xls'
data = pd.read_excel(catering_sale, index_col=u'日期')
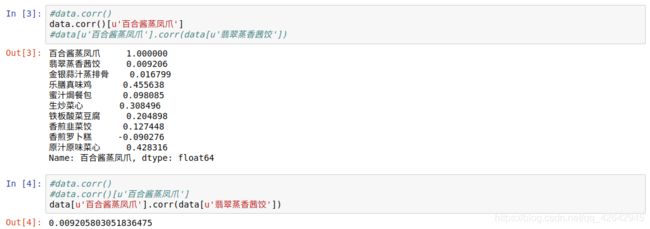
data.corr()
#data.corr()[u'百合酱蒸凤爪']
#data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺'])

python 主要数据探索函数
![]()
基本统计特征函数


拓展统计特征函数

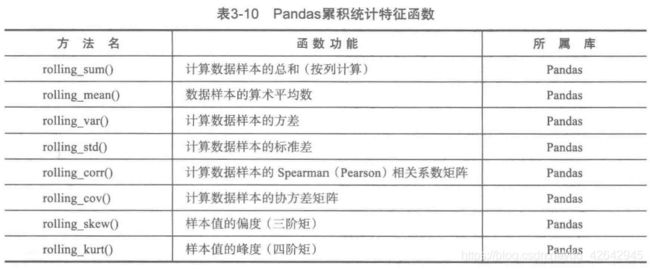

统计作图函数
